kotlin in action 책의 8장을 정리한 내용 입니다.
inline function
내부적으로 함수가 호출되는 곳에 내용을 모두 복사, 붙여놓기 하여 처리합니다.
이에 함수의 분기 없이 처리가 가능하여 성능이 증가 됩니다.
일반 함수와 인라인 함수의 차이를 먼저 알아 봅시다.
일반함수
fun main(...) {
...
sub() // sub 함수로 점프
...
sub() // sub 함수로 점프
}
fun sub() {
abc
}sub를 따로 함수로 만들어 두었으니 재사용은 가능하지만
sub가 호출될 때 마다 sub로 분기가 이루어 집니다.
분기가 일어난다는 것은 새로운 스택 프레임으로 만들어지고 관리, 문맥을 관리 해야 한다는 의미 이지요.
인라인 함수
fun main(...) {
...
sub() // 본문 abc가 복사됨
...
sub() // 본문 abc가 복사됨
}
inline fun sub() {
abc
}분기가 일어나지 않고 abc 내용이 복사 됩니다.
성능 증가의 장점이 있으나 재사용이 많은 경우 코드 사이즈가 커질 수 있습니다.
인라인이 작동하는 방식
함수를 호출하는 모든 문장을 함수 본문에 해당하는 바이트 코드로 바꾸는 것을 볼 수 있습니다.
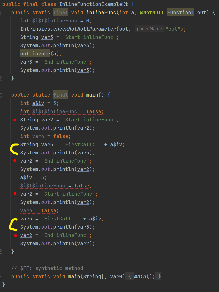
inline fun inlineFunc(a: Int, out:(Int) -> Unit) {
println("Start inlineFunc")
out(a)
println("End inlineFunc")
}
fun main() {
inlineFunc(3) { println("FirstCall: $it") }
inlineFunc(5) { println("FirstCall: $it") }
}인라인 함수의 한계
람다를 변수에 저장하고, 나중에 그 변수를 사용하는 방식은 람다를 표현하는 객체가 어딘가에 저장되어 있어야 하기 때문에 람다를 인라이닝 할 수 없습니다.
인라인 함수의 본문에서 람다 식을 바로 호출하거나 람다식을 인자로 전달 받아 바로 호출하는 경우에는 인라인이 가능합니다.
noinline 키워드를 사용하면 일부 람다식 함수를 인라인 되지 않게도 가능 합니다.
inline fun inlineFunc(a: Int, noinline out:(Int) -> Unit) {
println("Start inlineFunc")
out(a)
println("End inlineFunc")
}
fun main() {
inlineFunc(3) { println("FirstCall: $it") }
inlineFunc(5) { println("FirstCall: $it") }
}컬레션 연산 인라이닝
코틀린의 표준 라이브러리 컬렉션 함수는 대부분 람다를 인자로 받고, 내부적으로 inline 함수로 되어 있습니다.
그런데 컬렉션의 크기가 클 때만 asSequence()를 이용하라고 권장 합니다.
그 이유가 무엇일까요?
컬렉션의 filter와 asSequence의 filter의 컴파일 된 내용을 보고 확인해 봅시다.
1) 컬렉션의 filter
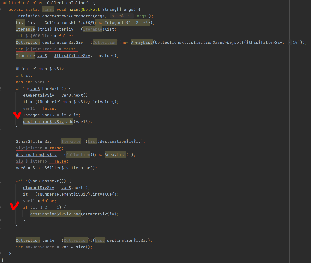
fun main(args: Array<String>) {
val list = listOf(1, 2, -3) // [1, 2, -3] 생성
val maxOddSquare = list
.map { it * it }
.filter { it % 2 == 1 }
.count()
}
컬렉션의 filter는 내부적으로 inline 함수로 구현되어 있습니다.
2) asSequence의 filter
fun main(args: Array<String>) {
val list = listOf(1, 2, -3) // [1, 2, -3] 생성
val maxOddSquare = list
.asSequence()
.map { it * it }
.filter { it % 2 == 1 }
.count()
}
 asSequence는 내부적으로 inline 함수로 되어 있지 않고 새로운 클래스에 저장하게 됨을 알 수 있습니다.
asSequence는 내부적으로 inline 함수로 되어 있지 않고 새로운 클래스에 저장하게 됨을 알 수 있습니다.
즉 새로운 클래스에 저장을 하게 되기 때문에 인라인 함수로 구현할 수 없습니다.
Collection Stream API 와 Sequence Stream API의 명세 비교
Collection Stream API 와 Sequence Stream API의 내부 구현을 비교해보면 더 확실히 알 수 있습니다.
Collection Stream API
// _Collections.map
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
// _Collections.mapTo
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}
// 인라인 함수이고, 람다를 바로 실행
// 람다를 받으므로 인라인 함수로 구현
// 람다 실행 후 스트림을 생성하는 오버헤드Sequence Stream API
// _Sequences.map
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
// Sequences.TransformingSequence
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}
// 일반 함수이고 람다를 실행하지 않고 저장한다는 특징
// 람다를 실행하지 않고 새로운 클래스에 저장하게 되므로 인라인 함수로 구현할 수 없음
// 람다를 실행할 때마다 새로운 (익명) 객체가 생성되는 오버헤드이에 객체를 생성하는 것의 오버헤드가 큰지 매번 스트림을 생성하는 오버헤드가 큰지를 따져서 무엇을 사용 할지를 고려 해야 합니다.
보통 원소의 수가 적을 때는 람다 객체를 만드는 것이 오버헤드가 더 크고
원소의 수가 많을 때는 스트림을 매번 생성하는 것이 오버헤드가 더 크기 때문에 컬렉션의 크기가 클 때만 asSequence()를 이용하라고 권장하는것 입니다.
함수를 인라인으로 선언해야 하는 경우
람다를 인자로 받는 함수를 인라이닝 하면 이득 입니다.
함수 호출 비용을 줄이고, 람다를 표현하는 클래스와 람다 인스턴스에 해당하는 객체를 만들 필요가 없어지니까요.
그러나 너무 많이 쓰면 코드 길이가 길어지니 주의가 필요합니다.
자원 관리를 위해 인라인 된 람다 사용
람다로 중복을 없앨 수 있는 일반적인 패턴 중에 하나는 어떤 작업 전에 자원을 획득하고, 작업을 마친 후 자원을 해제하는 자원 관리 등이 있습니다.
( 자원 : 파일, 락, 데이터베이스 트랜잭션 등 )
코틀린 표준 라이브러리에서는 자바의 try-with-resource와 같은 use라는 함수를 제공 합니다.
use 함수는 Closeable을 구현한 객체에 한하여 사용할 수 있고, 람다를 호출한 다음에 자원을 닫아주는데 바로 이 use 함수도 인라인 함수로 되어 있습니다.
fun readFirstLineFromFile(path: String): String {
BufferedReader(FileReader(path)).use { br -> // use 함수
return br.readLine()
}
}
// 자바로 컴파일 된 소스
public final class UsingInlinedLambdasForResourceManagementKt {
@NotNull
public static final String readFirstLineFromFile(@NotNull String path) {
Intrinsics.checkNotNullParameter(path, "path");
Closeable var1 = (Closeable)(new BufferedReader((Reader)(new FileReader(path))));
Throwable var2 = (Throwable)null;
String var5;
try {
BufferedReader br = (BufferedReader)var1;
int var4 = false;
String var10000 = br.readLine();
Intrinsics.checkNotNullExpressionValue(var10000, "br.readLine()");
var5 = var10000;
} catch (Throwable var8) {
var2 = var8;
throw var8;
} finally {
CloseableKt.closeFinally(var1, var2);
}
return var5;
}
}
// user의 명세서
// 결국 try, catch, finally 구문이 복붙 되어서 들어갔음(★)
@InlineOnly
@RequireKotlin("1.2", versionKind = RequireKotlinVersionKind.COMPILER_VERSION, message = "Requires newer compiler version to be inlined correctly.")
public inline fun <T : Closeable?, R> T.use(block: (T) -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
var exception: Throwable? = null
try {
return block(this)
} catch (e: Throwable) {
exception = e
throw e
} finally {
when {
apiVersionIsAtLeast(1, 1, 0) -> this.closeFinally(exception)
this == null -> {}
exception == null -> close()
else ->
try {
close()
} catch (closeException: Throwable) {
// cause.addSuppressed(closeException) // ignored here
}
}
}
}