01 기초
1 intro
강의의 목적
- 기본 개념과 이론에 대한 이해
- Tablau, EDA, 머신러닝수업 등에 대한 기초 마련
- 데이터 분석 업무를 하기 위한 기초 통계에 대한 이해
통계학 (statistics)
: 산술적 방법을 기초로 하여, 주로 다량의 데이터를 관찰하고 정리 및 분석하는 방법을 연구하는 수학의 한 분야
-
근대 : 국상학 (staatenkunde, 넓은 의미의 국가학) + 정치산술(political arithmetic, 정치 사회에 대한 수량적 연구 방법) + 확률 이론
-
기술 통계학 (descriptive statistics)
: 데이터를 수집하고 수집된 데이터를 쉽게 이해하고 설명할 수 있도록 정리 요약 설명하는 방법론 -
추론 통계학 (inferential statistics)
: 모집단으로 부터 추출한 표본 데이터를 분석하여 모집단의 여러가지 특성을 추측하는 방법론

2 데이터의 이해
: 데이터에 대한 이해와 기초적인 통계량에 대한 설명
2-1 데이터와 그래프
변수 (variable)
- 수학 : 어떤 정해지지 않은 임의의 값을 표현하기 위해 사용된 '기호'. 변하는 숫자.
- 통계학 : 조사 목적에 따라 관측된 자료값. 해당 변수에 대하여 관측된 값들: 자료(data).
질적 자료
: 관측된 데이터가 몇 개의 범주로 구분하여 표현될 수 있는 데이터
- 성별, 주소지(시군구), 업종 등
- 명목형 변수 : 데이터 입력시 1은 남자, 2는 여자로 표현 가능하나 여기서 숫자의 의미는 없음
- 순서형 변수 : 교육수준, 건강상태
양적 자료
: 관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있음
- 이산형 데이터
- 연속형 데이터
EDA (Exploratory Data Ananlysis)
: 데이터를 탐색하는 분석 방법으로 도표, 그래프, 요약 통계 등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법
: 가장 많이 사용하는 분석 방법
목적
- 분석 프로젝트 초기, 가설을 수립하기 위해 사용
- 분석 프로젝트 초기, 적절한 모델 및 기법의 선정
- 변수간 트렌드, 패턴, 관계 등을 찾고 통계적 추론을 기반으로 가정을 평가
- 분석 데이터에 적절한가 평가, 추가 수집, 이상치 발견 등에 활용
데이터 시각화 (data visualization)
: 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정
목적
- 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달하는 것
2-2 데이터의 기초 통계량
기초 통계량
- 통계량 (statistic): 기술 통계량. 표본으로 산출한 값.
- 통계량을 통해 데이터(표본)가 갖는 특성을 이해 할 수 있음.
중심 경향치
: 표본(데이터)를 이해하기 위해 표본의 중심에 대해서 관심을 갖는 것.
- 대표값 : 표본의 중심을 설명하는 값.
- ex/ 평균, 중앙값, 최빈값, 절사 평균 등
평균 (mean)
- 표본 평균(sample mean) : 표본으로 추출된 평균
- 모평균 : 모집단의 평균
중앙값 (median)
: 표본으로 부터 관측치를 크기순으로 나열 했을 때, 가운데 위치하는 값
- 관측치가 홀수일 경우 중앙에 취하는 값이고, 짝수일 경우 가운데 두개의 값을 산술 평균한 값
- 이상치가 포함된 데이터에 대해서 사용함
최빈값 (mode)
: 관측치 중서 가장 많이 관측되는 값
- 명목형 데이터(ex/ 옷 사이즈)의 경우 사용
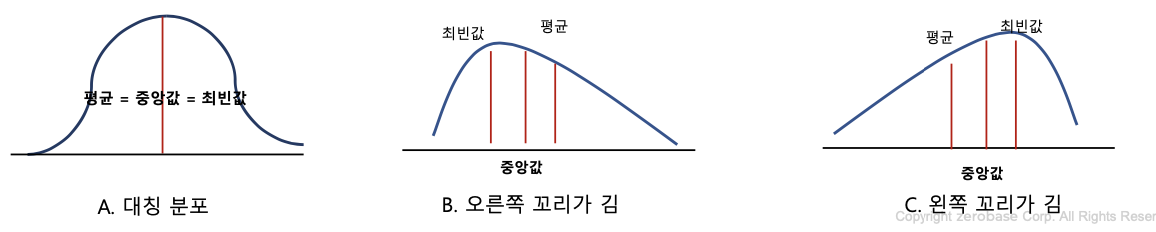
산포도
- 데이터가 어떻게 흩어져 있는지 확인하기 위해서는 중심경향치와 함께 산포에 대한 측도를 같이 고려해야 함
- 데이터의 산포도를 나타내는 측도: 범위, 사분위수, 분산, 표준편차, 변동 계수 등
범위 (range)
: 데이터의 최대값과 최소값의 차이
사분위수 (quarile)
- 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫 번째를 제1사분위수(Q1), 두 번째를 제2사분위수(Q2), 세 번째를 제3사분위수(Q3)라고 함.
- 사분위수 범위(interquartile range, IQR) = 제 3사분위수(Q3) – 제1사분위수(Q1)
백분위수 (percentile)
: 전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값
- 제p백분위수: p%에 위치한 자료 값
- 데이터를 오름차순으로 배열하고 자료가 n개가 있을 때, 제(100*p) 백분위수는 아래와 같음
: 1) np가 정수이면, np번째와 (np + 1)번째 자료의 평균
: 2) np가 정수가 아니면, np보다 큰 최소의 정수를 m이라고 할 때 m번째 자료
분산 (variance)
: 데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도
- 데이터의 각각의 값들의 편차 제곱합
- 크기가 N인 모집단의 평균을 M라고 할 때
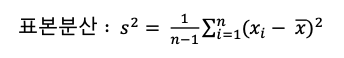
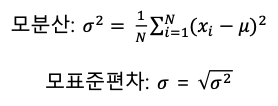
표준편차 (standard deviation)
- 분산의 제곱근

변동계수 (Coefficient of Variation: CV)
- 평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용
- 표준편차를 평균으로 나누어서 산출하며, 단위나 조건에 상관 없이 서로 다른 그룹의 산포를 비교하며 실제 분석에서 자주 사용함.
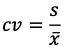
- 분산이 크면 분포가 넓어지고 작으면 좁아짐. 평균과 분산에 따라 모양이 달라짐.
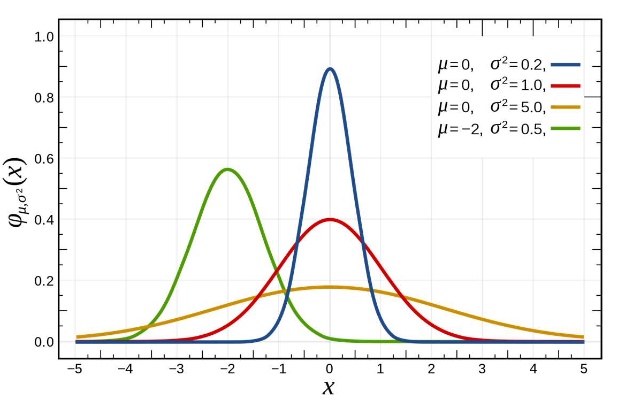
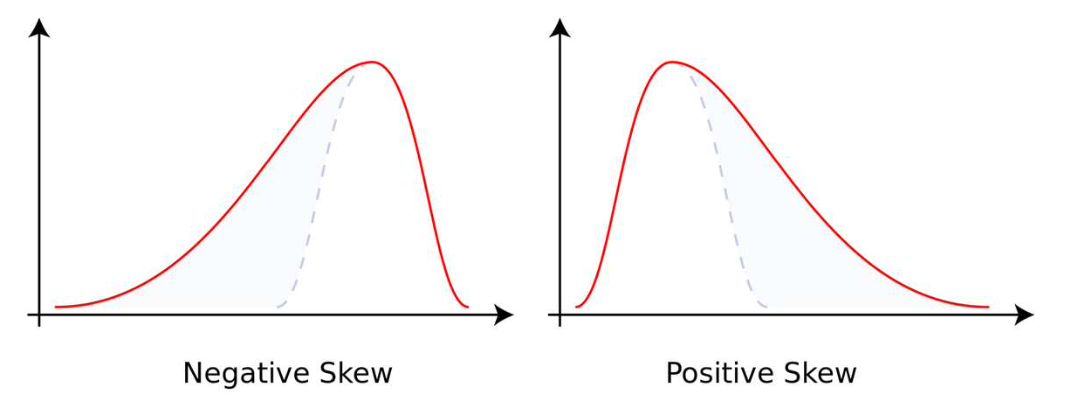
왜도 (skew)
: 자료의 분포가 얼마나 비대칭적인지 표현하는 지표
- 왜도가 0이면 좌우가 대칭이고, 0에서 클수록 우측 꼬리가 길고 0에서 작을수록 좌측 꼬리가 김
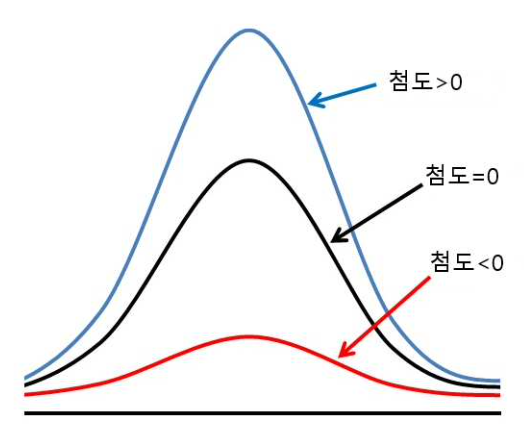
첨도 (kurtosis)
: 확률분포의 꼬리가 두꺼운 정도를 나타내는 척도
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가까움.
- K<3: 산포는 정규분포보다 꼬리가 얇은 분포 / K>3: 정규분포보다 꼬리가 두꺼운 분포
3 확률
3-1 확률
확률 (probability)
: 모든 경우의 수에 대한 특정 사건이 발생하는 비율
a) 고전적 정의
: 어떤 사건이 일어날 수 있는 경우의 수 대 가능한 모든 경우의 수의 비. 단, 이는 모든 사건이 동일하게 일어날 수 있다고 할 때 성립한다.
b) 통계적 정의
- 사건 A가 일어날 상대도수: 어떤 시행을 n번 반복했을 때, 사건 A에 해당하는 결과가 r번 일어난 경우가 r/N
- 사건 A의 통계적 확률 / 경험적 확률: N이 무한히 커지면 상대도수는 일정한 수로 수렴하는데, 이 극한값.
- ex/ 타자가 타석에서 안타를 칠 확률 / 공정에서 제품이 정상일 확률(수율)
표본 공간 (sample space)
: 어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합
- ex/ 동전 던지기: S = {앞면, 뒷면} , 주사위던지기: S = {1,2,3,4,5,6}
- 사건 A가 일어날 확률을 P(A)라고 하고, 표본 공간(S)가 유한집합일 때 표본 공간의 모든 원소들이 일어날 확률이 같으면
- ex/ 주사위를 던져서 6이 나올 확률 / 트럼프 카드 52장 중 A가 나올 확률 / 로또 1등에 당첨될 확률

확률의 성질
-
합사건 (union): 사건 A 또는 사건 B가 일어날 확률 A ∪ B
-
곱사건 (intersection): 사건 A와 사건 B가 동시에 일어날 확률 A ∩ B
-
배반사건 (mutually exclusive event): 사건 A와 사건 B가 동시에 일어날 수 없을 경우 A ∩ B = ∮
-
여사건 (complement): 사건 A가 일어나지 않을 확률 Ac
-
확률의 덧셈법칙: P(A ∪ B) = P(A) + P(B) = P(A ∩ B)
-
A와 B가 배반사건: P(A ∩ B) = P(∮) = 0
-
A의 여사건이 Ac: P(A) + P(Ac) = 1
조합과 순열
- ! (factorial) : n개를 일렬로 늘여 놓은 경우의 수. n! = n(n-1)(n-2)...2*1
- 순열 (permutation) : 순서를 고려하여 n개 중 r개를 뽑아서 배열하는 경우의 수
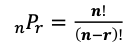
- 조합 (combination) : 순서를 고려하지 않고 n개중 r개를 뽑아서 배열하는 경우의 수
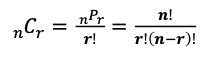
- ex/ 로또 1등과 2등 각각의 확률 : 1등 = 45C6 / 2등 = 45C6 * 6
조건부 확률 (conditional probability)
: 어떤 사건 A가 발생한 상황에서(주어졌을때) 또 하나의 사건 B가 발생할 확률
- 확률의 곱셈 법칙
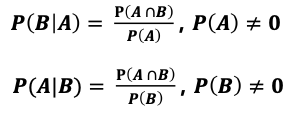
- 확률의 곱셈 법칙: 사건 A와 B가 독립인 경우
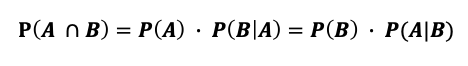
베이즈 정리 (Bayes' Theorem)
: 표본공간 S에서 서로 배반인 사건 B1, B2, ..., Bk 에 의하여 분할되어 있을 때, 임의의 사건 A에 대하여 다음이 성림함
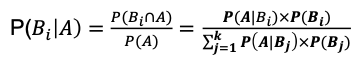

3-2 확률 변수 (random variable)
: 표본공간에서 각 사건에 실수를 대응시키는 함수
- 하나의 사건에 대하여 하나의 값을 가지며, 실험의 결과에 의하여 변함
- 일반적으로 확률 변수는 대문자로 표현하며, 확률변수의 특정값을 소문자로 표현함
이산 확률 변수 (discrete random variable)
: 셀 수 있는 값들로 구성되거나 일정 범위로 나타나는 경우
연속 확률 변수 (continuous random variable)
: 연속형 또는 무한대와 같이 셀 수 없는 경우
예시
- 반도체 1000개의 wafer중 불량품의 수 X
- 공장에서 생산하는 전구의 수명 T
- 주사위를 던질 때 나오는 눈의 수 V
확률 변수의 평균 : 기대값
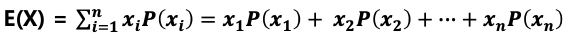
- 주사위를 던졌을 때 기대값:
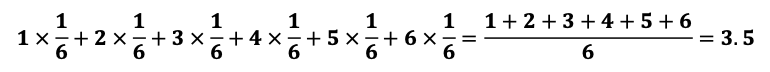
확률 변수의 분산
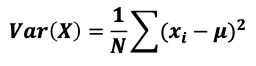
기대값의 성질
: a, b가 상수이고, X,Y를 임의의 확률변수라고 할 때 다음이 성립한다.
- (a) E(a) = a
- (b) E(aX) = aE(X)
- (c) E(aX + b) = aE(X) + b
- (d) E(aX ± bY) = aE(X) ± bE(Y)
- (e) X, Y가 독립 일 때 E(XY) = E(X) E(Y)
분산의 성질
: a,b가 상수이고, X,Y를 임의의 확률변수라고 할 때 다음이 성립한다
(a) Var(a) = 0
(b) Var(aX) = a^2Var(X)
(c) Var(X + Y) = Var(X) + Var(Y) + 2Cov(X,Y)
(d) Var(aX ± bY) = a^2Var(X) ± b^2*Var(Y) + 2Cov(X,Y)
(e) X,Y가 독립일 때 Var(XY) = 0
(f) Var(X) = E(X^2) −[E(X)]^2
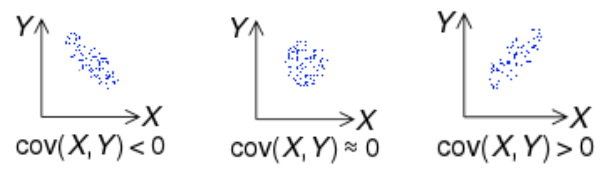
공분산
: 2개의 확률변수의 선형 관계를 나타내는 값
- 하나의 값이 상승할 때 다른 값도 상승한다면, 양의 공분산을 가지고 반대로 하나의 값이 상승할 때 하락한다면 음의 공분산을 가짐
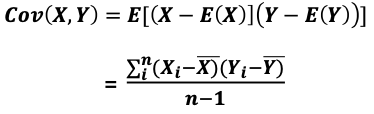

4 확률변수
- 통계학에서 자주 사용하는 분포에 대해서
확률 분포 (probability distribution)
: 확률 변수 X가 취할 수 있는 모든 값과 그 값을 나타날 확률을 표현한 함수
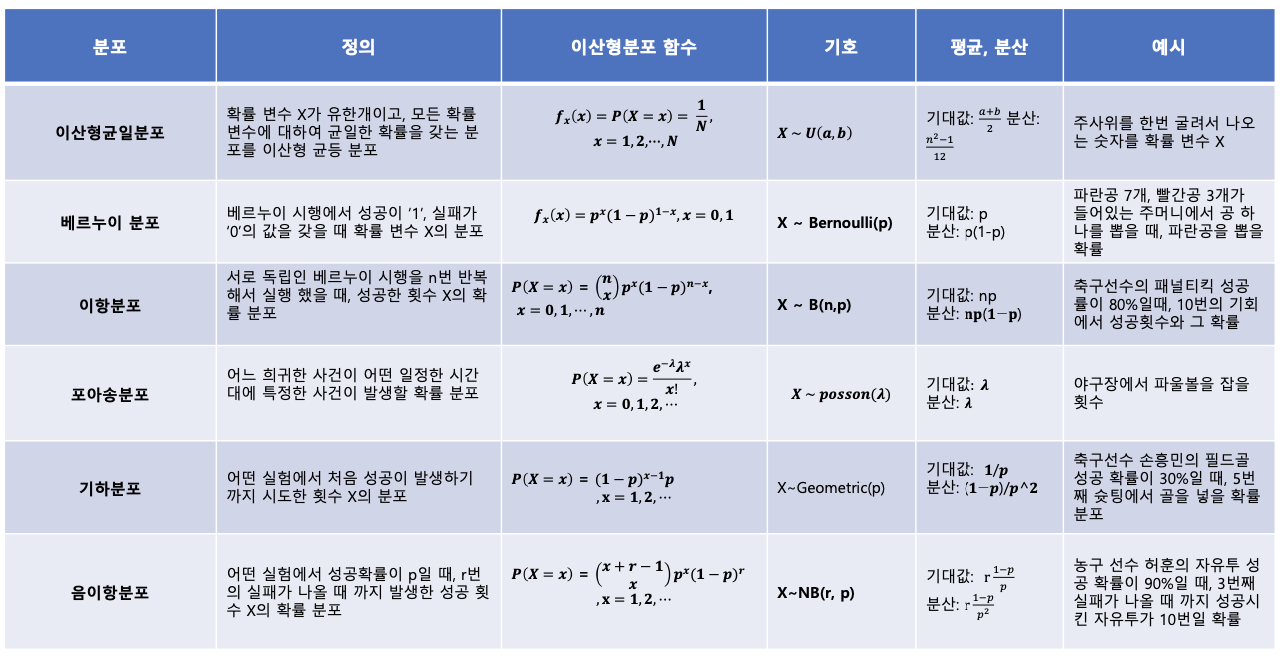
4-1 이산형 확률 분포
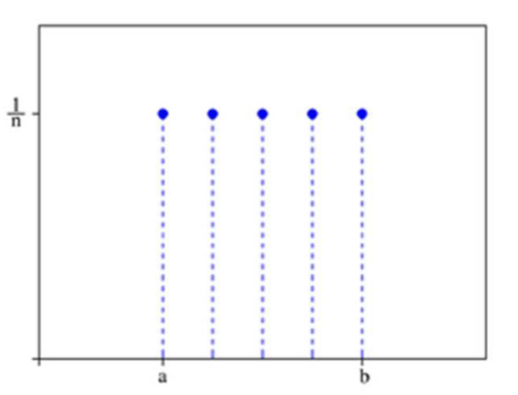
이산형 균등 분포 (discrete uniform distribution)
: 확률 변수 X가 유한개이고, 모든 확률 변수에 대하여 균일한 확률을 갖는 분포
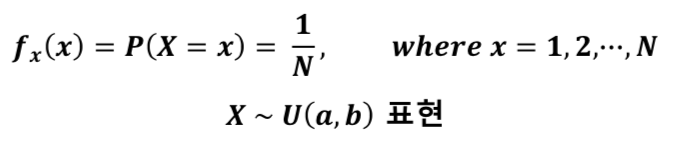
베르누이 시행 (Bernoulli trial)
: 각 시행의 결과가 성공, 실패 두가지 결과만 존재하는 시행
- 베르누이 분포 (Bernoulli distribution) : 베르누이 시행에서 성공이 ‘1’, 실패가 ‘0’의 값을 갖을 때 확률 변수 X의 분포
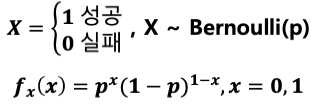
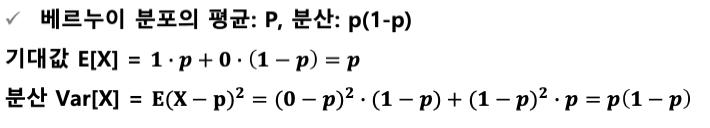

이항 분포 (binomial distribution)
: 연속적인 베르누이 시행을 거처 나타나는 확률 분포
: 서로 독립인 베르누이 시행을 n번 반복해서 실행 했을 때, 성공한 횟수 X의 확률 분포
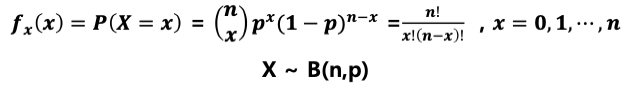


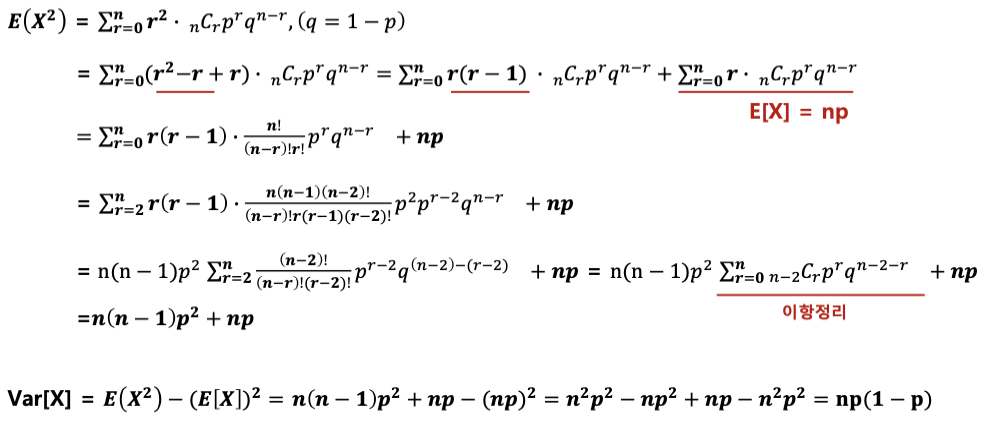
포아송 분포(Poisson distribution)
: 어느 희귀한 사건이 어떤 일정한 시간대에 특정한 사건이 발생할 확률 분포
- ex/ 야구장에서 파울볼을 잡을 횟수 / 버스 정류장에서 특정 버스가 5분 이내에 도착한 횟수 / 1년간 지구에 1미터 이상의 운석이 떨어지는 수 등
포아송 분포의 조건
- 어떤 단위 구간(ex/1일) 동안 이를 더 짧은 작은 단위의 구간(ex/1시간)로 나눌 수 있고 이러한 더 짧은 단위 구간 중에 어떤 사건이 발생할 확률은 전체 척도 중에서 항상 일정
- 두 개 이상의 사건이 동시에 발생할 확률은 0에 가까움
- 어떤 단위구간의 사건의 발생은 다른 단위구간의 발생으로부터 독립적임
- 특정 구간에서의 사건 발생확률은 그 구간의 크기에 비례함
- 포아송 분포 확률 변수의 기댓값과 분산은 모두 λ임
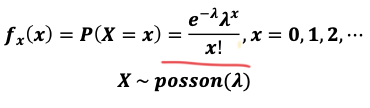
- 예제: 야구장에서 경기당 홈런볼을 잡는 관객이 평균 3명 이고 가정하자
- 오늘 경기에서 2명 이상이 홈런볼을 잡을 확률을 구하시오
- 오늘과 내일 동안 경기에서 홈런볼을 잡지 못할 확률을 구하시오

이항 분포의 포아송 근사
: 확률변수X가 X~B(n,p)이고, n이 충분히 크고, p가 아주 작을 때, X의 분포는 평균이 λ = np인 포아송 분포로 근사 시킬 수 있음. 보통 n이 클때, np < 5를 만족하게 p가 작으면 근사 정도가 좋다고 함
X ~ Poisson(np)
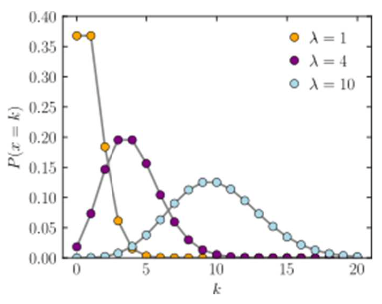
이항분포 vs 포아송분포
- 아래의 표는 엑셀로 가능하며 분포를 표현하는 함수식으로 작성해 보시오
n = 100, p = 0.01인 이항 분포 X~B(100, 0.01) 를 포아송 근사 하면 X ~ Poisson(1)이 된다. (λ = 100 * 0.01 = 1) - 엑셀 함수
이항분포 : BINOM.DIST(X, N, P, 누적 여부)
포아송분포 : POISSON.DIST(X, Ö, 누적 여부) (1이면 누적)
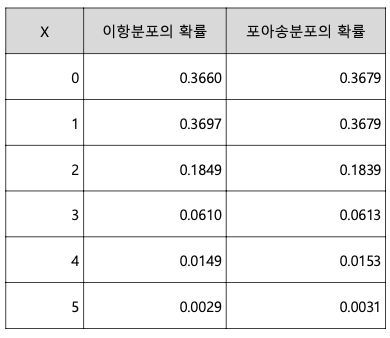
기하 분포 (geometric distribution)
: 어떤 실험에서 처음 성공이 발생하기 까지 시도한 횟수 X의 분포 (이때 각 시도는 베르누이 시행을
따름)

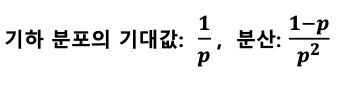
- 예제: 축구선수 손흥민의 필드골 성공 확률이 30%일 때, 5번째 슛팅에서 골을 넣을 확률 분포
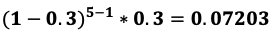
음이항 분포 (negative binomial distribution)
: 어떤 실험에서 성공확률이 p일 때, r번의 실패가 나올 때 까지 발생한 성공 횟수 X의 확률 분포
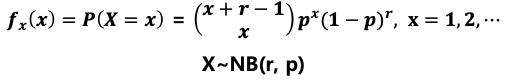
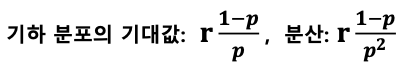
- 예제: 농구 선수 허훈의 자유투 성공 확률이 90%일 때, 3번째 실패가 나올 때 까지 성공시킨 자유투가 10번일 확률
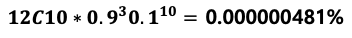
이산형 확률 분포 요약