chap1. orientation
서울시 CCTV 분석 현황 데이터 분석
02 분석 데이터 읽기
- import MODULE
: 모듈을 사용하겠다.
MODULE.function - import MODULE as md
: MODULE을 사용할 건데, 앞으로 md라는 이름으로 부르겠다.
md.function - from MODULE import function
: MODULE에 포함된 function이라는 함수만 사용하겠다.
function
- csv: comma separated value (','로 구분되어 있는 데이터)
(* 앞으로 대부분 노트 필기는 jupyter로 가정하고 작성됨)
- 통상 csv는 띄어쓰기로 구분되니 그냥 read_csv 명령으로 읽기만 해도 된다
- 긴 파일명은 끝까지 입력하지 말고 적당한 곳에서 TAB키를 눌러보자.(colab은 해당되지 않음)
- 한글은 encoding 설정이 필수
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")head()
자료 중 앞부분 5개만 볼 수 있도록 하는 명령어
ex/ CCTV_Seoul.head()
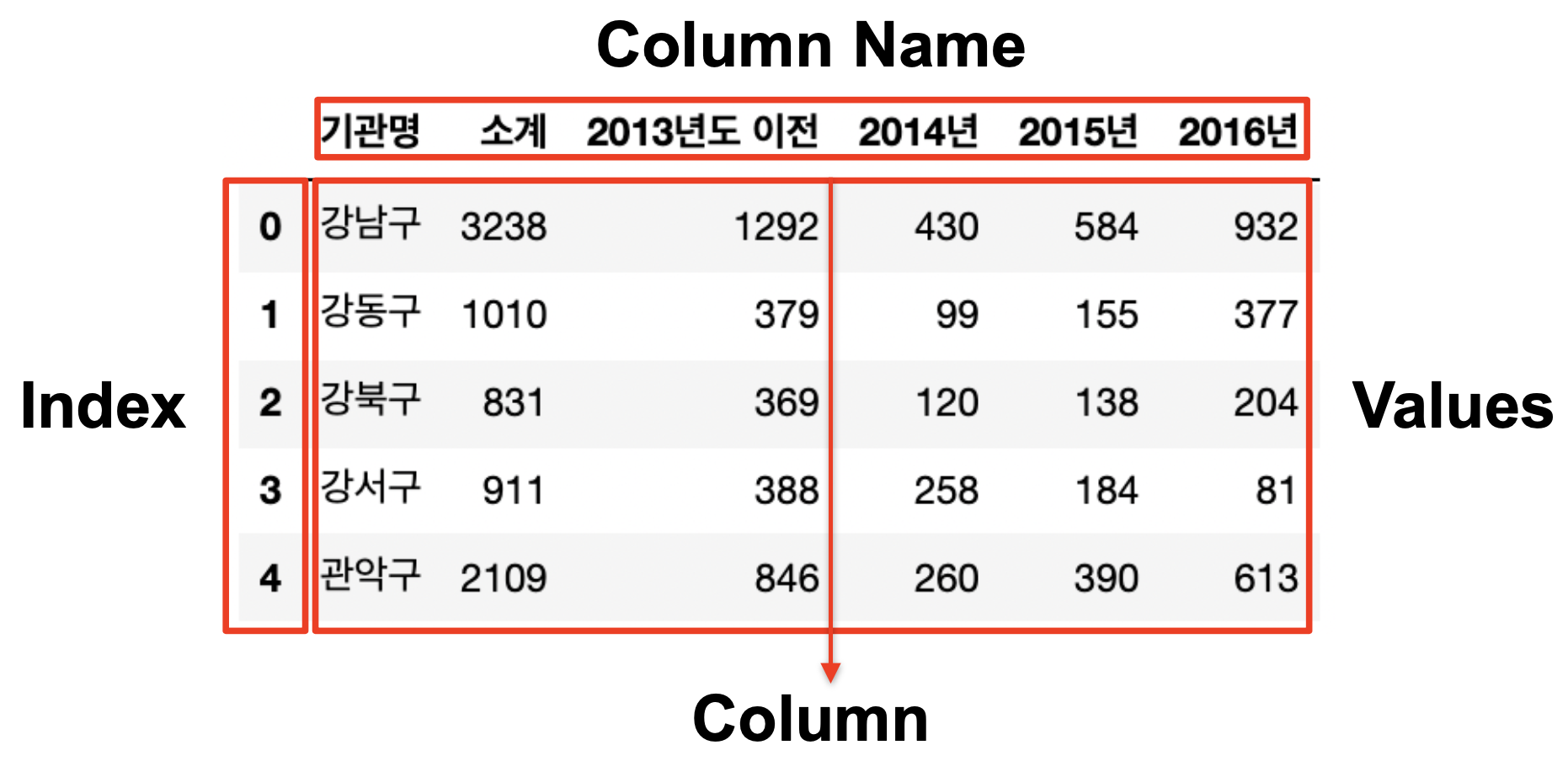
데이터명.columns
: column 내의 이름 모두 조회
(ex/ 데이터명.column[0] : 0번째 column명 조회)
rename
: 컬럼 이름 바꾸기
inplace = True
: 바꾸고 나서 데이터를 업데이터 해 주어야 반영이 된다. 그때의 명령어. (디폴트 값은 False)
CCTV_Seoul.rename(colums={CCTV_Seoul.columns[0]: "구별"}, inplace=True)엑셀 파일 읽기
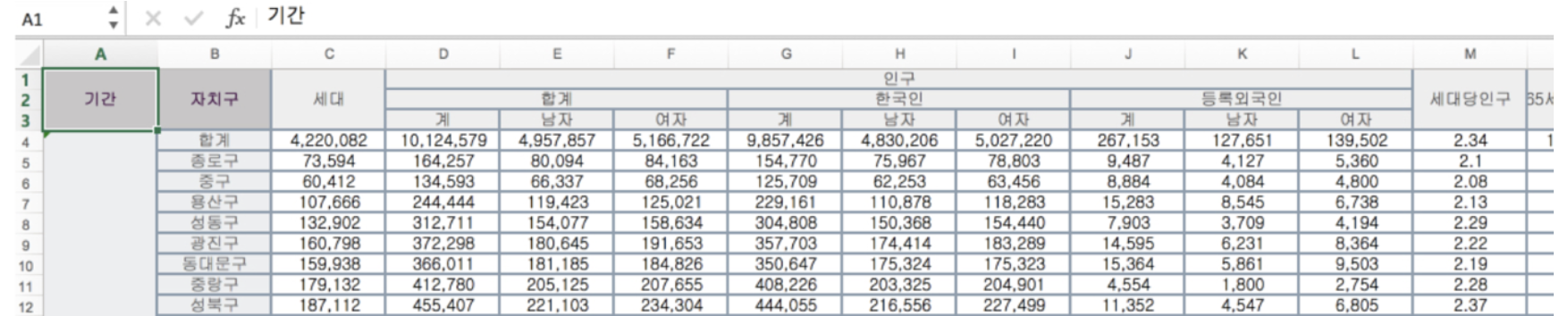
pop_Seoul = pd.read_excel("../data/01. Seoul_Popoluation.xls"): 하지만 엑셀파일에서 병합되어 있던 셀이 pandas에서는 병합 기능이 없어 깨끗하지 못한 모양으로 읽혀지게 된다.

pop_Seoul = pd.read_excel("../data/01. Seoul_Popoluation.xls", header=2, usecols="B, D, G, J, N"): 자료를 읽기 시작할 행(header) 지정
: 읽어올 엑셀의 컬럼 지정(usecols)
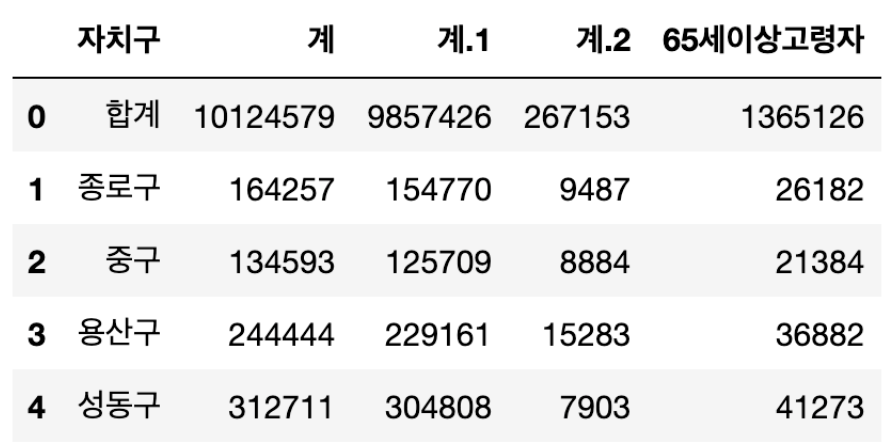
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True,
)
pop_Seoul.head(): 컬럼 이름 바꾸기
03 분석 데이터 읽기
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")..
: 터미널에서 폴더를 이동할 떄 쓰는 명령어. (의미: 현재 폴더에서 상위 폴더로 이동하라. 현재 속한 source_code 폴더에서 한 단계 위로 올라가서 data~ 위치로 이동하여 열어라.)
jupyter notebook에서 작업하기
Last login: ~~
(base) da~@Da~ui-MacBook-Pro ~ % conda activate ds_study
(ds_study) da~@Da~ui-MacBook-Pro ~ % cd Documents
(ds_study) da~@Da~ui-MacBook-Pro ~/Documents % ls
# 이 자리에 Document 내 파일 리스트가 나온다.
(ds_study) da~@Da~ui-MacBook-Pro ~/Documents % cd ds_study
(ds_study) da~@Da~ui-MacBook-Pro ~/Documents/ds_study % jupyter notebook
visual studio code를 통해 작업하기
jupyter가 아닌 visual studio code를 통해 작업하기
1) terminal을 연다
2) 아래 입력
Last login: ~~
(base) da~@Da~ui-MacBook-Pro ~ % cd Documents/ds_study
(base) da~@Da~ui-MacBook-Pro ds_study % cd ..
(base) da~@Da~ui-MacBook-Pro Documents % cd ds_study
(base) da~@Da~ui-MacBook-Pro ds_study % code .
(base) da~@Da~ui-MacBook-Pro ds_study % 04 pandas 기초
- pandas는 일반적으로 pd로 import 한다.
- numpy는 일반적으로 np로 import 한다.
- pandas의 데이터형을 구성하는 기본은 series이다.
date_range
dates = pd.date_range("20130101", periods=6)
dates: 2013.01.01부터 6일간
- pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다
- index와 columns를 지정하면 된다
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=["A", "B", "C", "D"])
df: numpy가 제공하는 random함수를 이용해 6행 4열의 랜덤 변수를 생성하고, index는 아까 설정했던 6일의 dates로, columns는 ABCD로 이름을 지정하라.
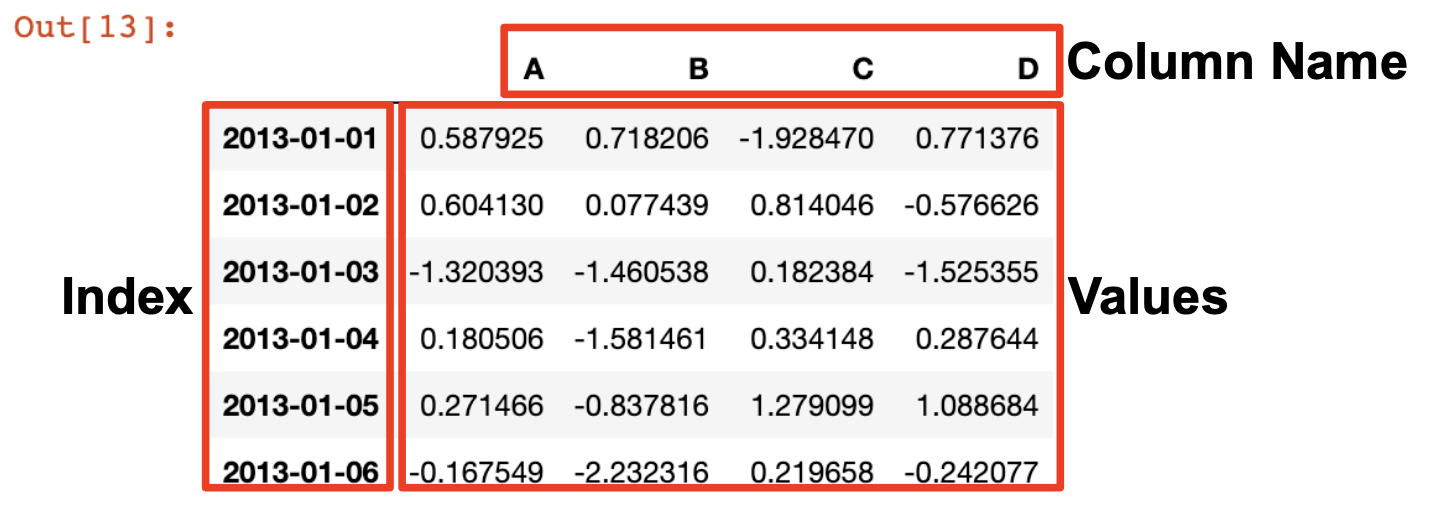
df. head() # 데이터 앞부분 5개만 조회
df.index # index만 조회
df. columns # columns만 조회
df.values # values만 조회df.info()
: pandas DataFrame의 요약 정리를 보여준다. columns와 index는 뭐가 있고, 데이터는 몇개가 있으며 데이터의 타입은 어떤 것이다.
: 각 칼럼의 크기와 데이터 형태를 확인하는 경우가 많다.
df.describe()
: DataFrame의 통계적 기본 정보를 확인할 수 있다.
df.sort_values()
df.sort_values(by="B", ascending=False): 데이터 정렬. (B컬럼을 기준으로 내림차순 정렬을 보여준다.)
slice : 특정 부분만 읽기
- df["A"] : A 컬럼만 읽기
- df[n:m] : n부터 m-1까지의 컬럼 읽기
- df["20130102":"20130104"] : 인덱스나 컬럼의 이름으로 범위를 slice하는 경우는 끝을 포함한다.
- df.loc[:, ["A", "B"]] : location의 약자. [행, 열]을 지정할 수 있다. 모든 컬럼의(:) 열 A, B를(["A", "B"]) 선택해라.
ex/ df.loc["20130102":"20130104", ["A", "B"]] : 20130102부터 20130104까지의 행에서 A, B열을 선택해라 - df.iloc[] : 이름이 아니라 번호로 지정.
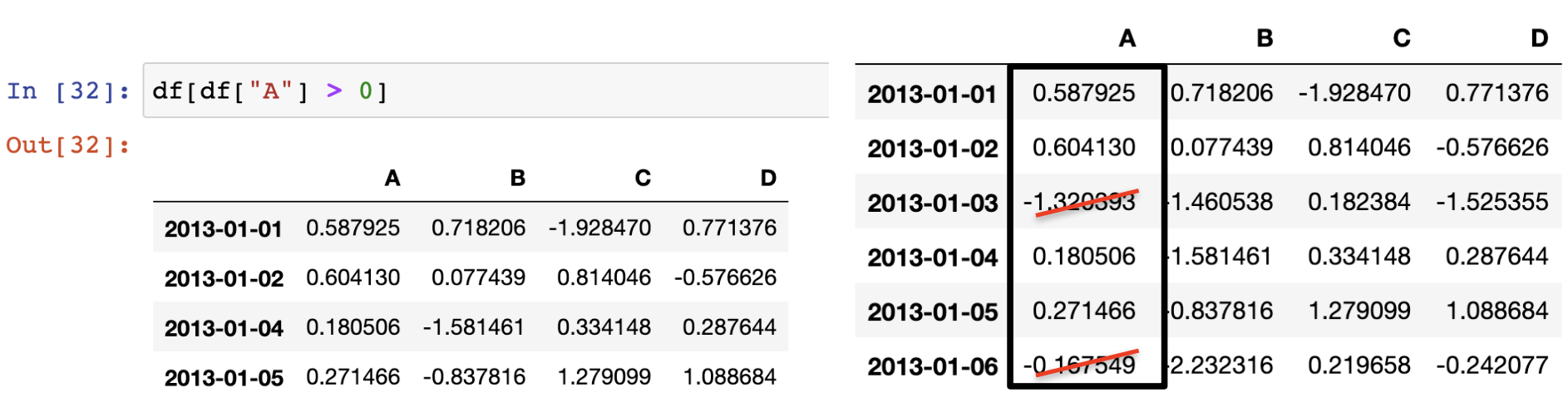
ex/ df.iloc[3:5, 0:2] : 3, 4행에서 0,1열을 선택해라. - df[df["A"] > 0] : df의 A컬럼 데이터 중 0보다 큰 데이터만 표현해라.
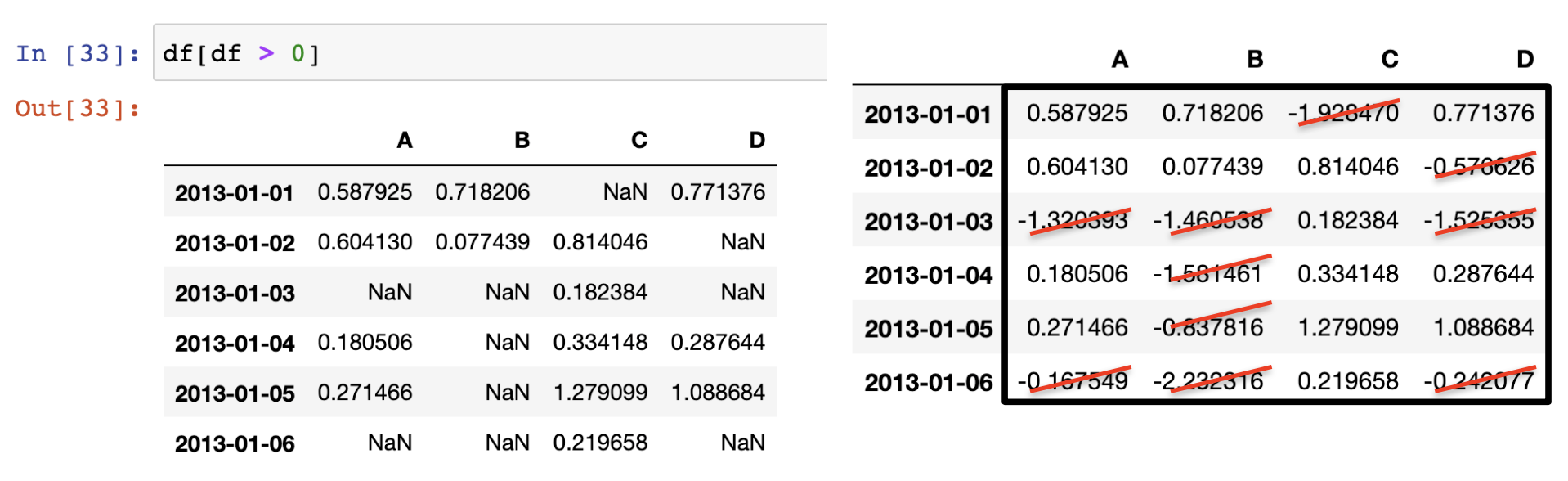
- df[df > 0] : 전체 데이터에서 0보다 큰 값만 취해라.
- df["E"] = ["one", "one", "two", "three", "four", "three"] : E 컬럼을 새로 만들어서 데이터를 집어넣어라.
- df["E"].isin(["two", "four"]) : E 컬럼 내에 two와 four라는 데이터가 있는지 확인.
- df[df["E"].isin(["two", "four"])] : 특정 요소가 있는 행만 선택
- del df["E"] : 특정 컬럼 제거
- df.apply(np.cumsum) : 뒤에 지정된 함수를 적용해라.(numpy가 제공하는 열 데이터의 누적 합계)
05, 06
jupyter에서 코멘트 기록하기
- #를 사용하면 실행관련 적용이 안됨
- 기록한 칸에서 esc를 누르면 칸 테두리가 파란색으로 변하고, m을 누른 후 shift+enter를 누르면 기록 완료
- 특정 칸 위에 기록을 하고싶다면, 특정 칸에서 esc를 누른 후 a를 다시 누른다.
기능 살펴보기
보고싶은 메서드의 괄호 안에서 shift+tab을 누르면 관련 설명이 나온다.
실선 긋기
'---' 기입 + esc + m + (shift+enter)
칸 위 아래 추가
파란테두리 + a : 위
파란테두리 + b : 아래
이거 대체 정리를 어떻게 해야하는거냐?
matplotlib
: 파이썬의 대표 시각화 도구
- matplotlib.pyplot(2D 그래픽을 담당)을 plt로 많이 naming하여 사용한다.
