08 UNION
실습 환경
use zerobase;
select * from celeb;
create table test1(
no int
);
create table test2(
no int
);
insert into test1 values (1);
insert into test1 values (2);
insert into test1 values (3);
insert into test2 values (5);
insert into test2 values (6);
insert into test2 values (3);
select * from test1;
select * from test2;UNION
: 여러개의 SQL문을 합쳐서 하나의 SQL문으로 만들어주는 방법
( *주의 : 칼럼의 개수가 같아야함 )
UNION
: 중복된 값을 제거하여 알려준다
UNION ALL
: 중복된 값도 모두 보여준다
select col1, col2, ... from tableA
UNION | UNION ALL
select col1, col2, ... from tableB;select * from test1
UNION
select * from test2;
# 결과
no
1
2
3
5
6select * from test1
UNION ALL
select * from test2;
# 결과
no
1
2
3
5
6
309 JOIN
: 두 개 이상의 테이블을 결합하는 것
INNER JOIN
: 두 개의 테이블에서 공통된 요소들을 통해 결합하는 조인방식
select col1, col2, ...
from tableA
INNER JOIN tableB
ON tableA.col = tableB.col
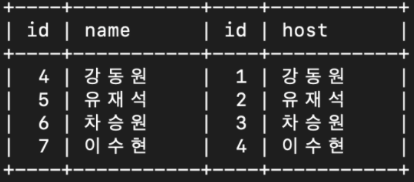
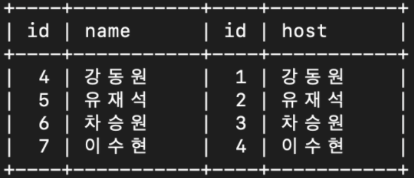
where condition;select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb
INNER JOIN snl_show
ON celeb.name = snl_show.host;: snl_show 에 호스트로 출연한 celeb 을 기준으로 celeb 테이블과 snl_show 테이블을 inner join
- 컬럼명이 같을 경우 꼭 테이블명을 함께 명시해주어야하고, 다를 경우 명시해주지 않아도 된다. (해줘도 된다.)
LEFT JOIN
: 두 개의 테이블에서 공통 영역을 포함해 왼쪽 테이블의 다른 데이터를 포함하는 조인방식
select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb
LEFT JOIN snl_show
ON celeb.name = snl_show.host;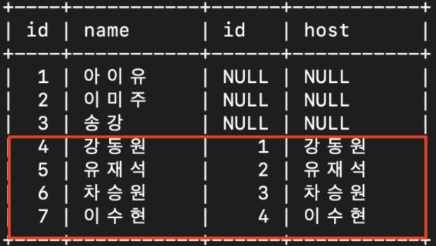
RIGHT JOIN
: 두 개의 테이블에서 공통 영역을 포함해 오른쪽 테이블의 다른 데이터를 포함하는 조인방식
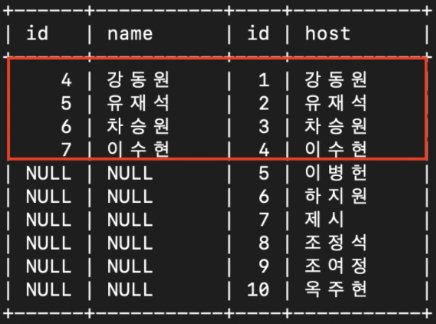
select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb
RIGHT JOIN snl_show
ON celeb.name = snl_show.host;: snl_show 에 호스트로 출연한 celeb 을 기준으로 celeb 테이블과 snl_show 테이블을 RIGHT JOIN
FULL OUTER JOIN
: 두 개의 테이블에서 공통 영역을 포함해 양쪽 테이블의 다른 영역를 모두 포함하는 조인방식
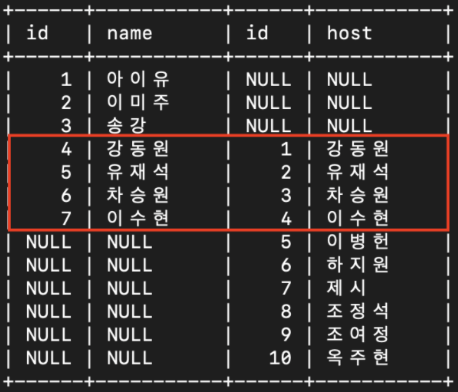
select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb
FULL OUTER JOIN snl_show
ON celeb.name = snl_show.host;
- MYSQL 에서는 FULL JOIN을 지원하지 않으므로 다음의 쿼리로 같은 결과를 만들 수 있다.
select col1, col2, ...
from tableA
LEFT JOIN tableB ON tableA.column = tableB.column
UNION
select col1, col2, ...
from tableA
RIGHT JOIN tableB ON tableA.column = tableB.column
WHERE condition;select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb
LEFT JOIN snl_show
ON celeb.name = snl_show.host
UNION
select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb
RIGHT JOIN snl_show
ON celeb.name = snl_show.host: snl_show 에 호스트로 출연한 celeb 을 기준으로 celeb 테이블과 snl_show 테이블을 FULL OUTER JOIN
SELF JOIN
: 가장 많이 사용되는 조인방식. inner join과 같은 결과를 가지고 온다.
select col1, col2, ...
from tableA, tableB, ...
where condition;select celeb.id, celeb.name, snl_show.id, snl_show.host
from celeb, snl_show
where celeb.name = snl_show.host;: snl_show 에 호스트로 출연한 celeb 을 기준으로 celeb 테이블과 snl_show 테이블을 self join
select celeb.name, celeb.age, celeb.job_title, celeb.agency, snl_show.season, snl_show.episode
from celeb, snl_show
where (celeb.name = snl_show.host)
and ((celeb.job_title != '%영화배우%' and celeb.agency = 'YG엔터테인먼트')
or (celeb.age >= 40 and celeb.agency != 'YG엔터테인먼트'));: celeb 테이블의 연예인 중, snl_show 에 host 로 출연했고,
영화배우는 아니면서 YG 엔터테이먼트 소속이거나 40세 이상이면서 YG 엔터테이먼트 소속이 아닌 연예인의 이름과 나이, 직업, 소속사, 시즌, 에피소드 정보를 검색

select snl_show.id, season, episode, name, job_title
from snl_show, celeb
where name = host;: snl_show 에 출연한 연예인의 snl_show 아이디, 시즌, 에피소드, 이름, 직업 정보를 검색
(동일한 칼럼명이 존재하는 경우에만 테이블명을 암시)
select name, season, episode, broadcast_date, agency
from snl_show, celeb
where name = host
and (episode in (7, 8, 9) or agency like 'YG______')
and broadcast_date > '2020-09-15';: snl_show 에 출연한 celeb 중, 에피소드 7, 9, 10 중에 출연했거나
소속사가 YG로 시작하고 뒤에 6글자로 끝나는 사람 중 작년 9월 15일 이후에 출연했던 사람을 검색
10 CONCAT, ALIAS, DISTINCT, LIMIT
CONCAT
: 여러 문자열을 하나로 합치거나 연결해주는 함수
select CONCAT('string1', 'string2', ..);select concat('이름:', name) from celeb;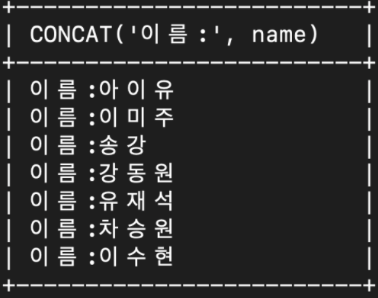
ALIAS
: 칼럼이나 테이블 이름에 별칭 생성
select column as alias
from tablenameselect col1, col2, ...
from tablename as alias;select name as '이름', agency as '소속사' from celeb;: name 은 이름으로, agency 는 소속사로 별칭을 만들어서 검색

select concat(name, ' : ', job_title) as profile from celeb;: name 과 job_title 을 합쳐서 profile 이라는 별칭을 만들어서 검색

select season, episode, name, job_title
from celeb as c, snl_show as s
where name = host;select concat (season, episode, broadcast_date) as '방송정보',
concat(name, job_title) as '출연자정보'
from celeb, snl_show
where name = host;: snl_korea 에 출연한 celeb 을 기준으로 두 테이블을 조인하여 다음과 같이 각 데이터의 별칭을 사용하여 검색
• 시즌, 에피소드, 방송일을 합쳐서 ‘방송정보’
• 이름, 직업을 합쳐서 ‘출연자정보’
( as는 생략도 가능 )
DINSTINCT
: 검색한 결과의 중복 제거
select DISTINCT col1, col2, ...
from tablename;LIMIT
: 검색결과를 정렬된 순으로 주어진 숫자만큼만 조회
select col1, col2, ...
from tablename
where condition
limit number;select * from celeb
order by age
limit 4;: 나이가 가장 적은 연예인 4명을 검색
11 AWS RDS
AWS RDS (Amazon Relational Database Service)
: Amazon Web Service에서 제공하는 관계형 데이터베이스 서비스
: Cloud 상에 pc나 database를 제공해준다.
원격으로 mysql에 접근하는 방법
% mysql -h <엔드포인트> -P <포트> -u <마스터 사용자 이름> -p- 이전까지는 local으로 접근했기 때문에 host와 port 정보를 생략하고 '% mysql -u root -p'로 간단히 접근했다.
- 원격으로 접근하기 위해서는, -h 뒤에 host ip 나 host name과 같이 원격으로 접근하기 위한 주소 정보를 주어야 한다
12 SQL File
실습환경
- sql_ws 폴더를 만들고 그 하위에서 실습하기
Documents % mkdir sql_ws
Document % cd sql_ws
sql_ws %SQL File 생성 방법
# 현재 폴더를 VSCode 로 열라는 뜻
sql_ws % code .- VSCode 의 sql_ws 폴더에서 새파일을 선택한다
- 생성할 파일 이름을 정하고, 파일 확장자를 sql 로 입력하면 비어있는 SQL 파일이 생성됩니다.
SQL File
: SQL 쿼리를 모아놓은 파일
파일 안에 실행할 여러개의 쿼리를 모아 작성한 다음 SQL 파일을 실행함으로써 작성해놓은 쿼리를 한꺼번에 실행할 수 있게 된다.
SQL File 실행 - 1. 로그인 이후
mysql> source </path/filename.sql>
mysql> \. </path/filename.sql> # source 대신 \. 사용 가능
mysql> \. <filename.sql> # 현재 폴더에 파일이 있으면 path 생략 가능- sql_ws 폴더 위치로 이동하여 zerobase 에 접속
% cd sql_ws
sql_ws % mysql -u root -p zerobase- SQL File 실행, 결과 확인
mysql> source test01.sql
mysql> desc police_station;SQL File 실행 - 2. 외부에서 바로 실행
% mysql -u username -p <database> < </path/filename.sql>- zerobase Database 에 접속하면서 SQL File 을 실행, 결과 확인
sql_ws % mysql -u root -p zerobase < test02.sql
mysql> desc crime_status;Database Backup
% mysqldump -u username -p dbname > backup.sql # 특정 Database Backup
% mysqldump -u username -p --all-databases > backup.sql # 모든 Database Backup- zerobase Database Backup
% mysqldump -u root -p zerobase > zerobase.sqlAWS RDS 서비스 시작
Database Restore
- 백업한 Database를 복구하는 방법
- 데이터베이스를 백업한 SQL File 을 실행하여 그 시점으로 복구하거나 이전 할 수 있다. (복구 명령이 따로 있는 것이 아니라 SQL File 을 실행하는 것이 복구하는 것이다.)
% mysql -h <엔드포인트> -P 3306 -u admin -p
mysql> show databases;
use zerobase;
source zerobase.sql # AWS RDS (database-1) 의 zerobase Database 를 복원
show tables; # 결과 확인: AWS RDS (database-1) 서비스가 사용 가능한 상태에서 접속
: show tables의 결과에 그동안 zerobase에 생성했던 목록들이 보이게 된다.
(local에 있는 zerobase 내용들이 remote에 있는 zerobase에 모두 카피가 된 것.)
Table Backup
- Table 단위로도 백업할 수 있다.
sql_ws % mysqldump -u usernamem -p dbname tablename > backup.sql- Local Database 에서 celeb Table을 백업한다.
sql_ws % mysqldump -u root -p zerobase celeb > celeb.sqlTable Restore
- Table을 백업한 SQL File 을 실행하여 해당 테이블을 복구하거나 이전 할 수 있다. (SQL File 을 실행하는 방법과 동일.)
% mysql -h <엔드포인트> -P 3306 -u admin -p
mysql> drop table celeb; # zerobase에서 celeb 테이블 삭제
source celeb.sql # zerobase에서 celeb 테이블 복구
select * from celeb; # 결과 확인Table Schema Backup
- 데이터를 제외하고 테이블 생성 쿼리만 백업할 수 있다.
% mysqldump -d -u username -p dbname tablename > backup.sql # 특정 table schema backup
% mysqldump -d -u username -p dbname > backup.sql # 모든 table schema backup13 Python with MySQL
python으로 MySQL 접속 후 사용하는 방법
- MySQL Driver 설치, 확인
pip install mysql-connecor-python
import mysql.connectorMySQL에 접속하기 위한 코드
mydb = mysql.connector.connect(
host = "<hostname>",
user = "<username>",
password = "<password>"
)- Local Database 연결
import mysql.connector
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "<password>"
)- AWS RDS (database-1) 연결
remote = mysql.connector.connect(
host = "<엔드포인트>",
port = 3306,
user = "admin",
password = "<password>"
)close database
mydb.close()local.close()
remote.close()특정 database에 접속하기 위한 코드
import mysql.connector
mydb = mysql.connector.connect(
host = "<hostname>",
port = <port>,
user = "<username>",
password = "<password>",
database = "<databasename>"
)- local MySQL 의 zerobase 연결
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "<password>",
database = "zerobase"
) # 터미널에서 mysql -u root -p<pswd> zerobase 와 동일한 것
local.close()- AWS RDS (database-1) 의 zerobase 에 연결
remote = mysql.connector.connect(
host = "<엔드포인트>",
port = 3306,
user = "admin",
password = "<password>",
database = "zerobase"
)
remote.close()SQL Query 실행
import mysql.connector
mydb = mysql.connector.connect(
host = "<hostname>",
user = "<username>",
password = "<password>",
database = "<databasename>"
)
mycursor = mydb.cursor()
mycursor.execute(<query>);- 테이블 생성
remote = mysql.connector.connect(
host = "<엔드포인트>",
port = 3306,
user = "admin",
password = "<password>",
database = "zerobase"
)
cur = remote.cursor()
# zerobase 안에서 sql_file이라는 테이블을 만든다.
cur.execute("CREATE TABLE sql_file (id int, filename varchar(16))")
remote.close()- 테이블 삭제
remote = mysql.connector.connect(
host = "<엔드포인트>",
port = 3306,
user = "admin",
password = "<password>",
database = "zerobase"
)
cur = remote.cursor()
cur.execute("DROP TABLE sql_file")
remote.close()- SQL File 을 실행하는 코드
mydb = mysql.connector.connect(
host = "<hostname>",
user = "<username>",
password = "<password>",
database = "<databasename>"
)
mycursor = mydb.cursor()
sql = open("<filename>.sql").read()
mycursor.execute(sql)- SQL file 내에 Query가 여러개 존재하는 경우
mydb = mysql.connector.connect(
host = "<hostname>",
user = "<username>",
password = "<password>",
database = "<databasename>"
)
mycursor = mydb.cursor()
sql = open("<filename>.sql").read()
result = mycursor.execute(sql, multi=True)Fetch All
mycursor.execute(<query>)
result = mycursor.fetchall()
for data in result:
print(data): 쿼리를 실행한 다음에 결과값이 row를 포함하고 있으면 fetchall 해서 프린트를 했었다. 실행하는 쿼리가 아니라 조회하는 select문을 실행한 경우에는 데이터를 가지고 온다. 데이터가 있는 경우에 fetchall을 써서 데이터를 담을 수 있다. 그래서 변수에 담은 데이터를 바로 출력하면 한꺼번에 찍히고, for문을 쓰면 row만 찍히게 된다.
sql_file 테이블 조회 (읽어올 데이터 양이 많은 경우)
cur = remote.cursor(buffered=True)
cur.execute("SELECT * FROM sql_file")
result = cur.fetchall()
for result_iterator in result:
print(result_iterator)
remote.close(): 커서를 통해 쿼리를 실행한 다음에 가지고 오는 결과값이 데이터인 경우 사이즈가 너무 크다. 이 때 기본으로 커서를 생성했을 때 실행이 안될 수 있다. 이렇게 읽어올 데이터의 양이 많은 경우 buffered=True 옵션을 주어야 한다.
- 쿼리로 가지고온 결과를 pandas로 읽기
import pandas as pd
df = pd.DataFrame(result)
df.head()Python with CSV
큰 데이터들이 엑셀이나 csv파일에 저장되어 있는 경우가 많다. 이런 것들을 db에 넣고 쿼리해보고 싶을 때, 한꺼번에 넣는 방법이 있으면 좋은데, mysql에서는 그 방법을 제공한다. 워크벤치나 명령어로 mysql 테이블에 바로 넣을 수 있다. 그런데 encoding이 맞지 않는 경우, mysql이 제공하는 인터페이스를 그대로 사용하면 fail이 많이 일어난다. 한번에 잘 들어가지 않는 경우가 많고, 특히 우리나라 사이트에서 다운받은 데이터 encoding은 utf8이 아닌 경우가 많아서 더 fail이 많이 일어난다. 하지만 python을 사용하면 간단히 해결할 수 있다.
(1) 제공받은 police_station.csv 를 Pandas 로 읽어와서 데이터를 확인
import pandas as pd
df = pd.read_csv("police_station.csv")
df.head()(2) zerobase 에 연결
import mysql.connector
conn = mysql.connector.connect(
host = "엔드포인트"
port = 3306,
user = "zero",
password = "<pswd>",
database = "zerobase"
)(3) 읽어올 양이 많은 경우 cursor 생성 시 buffer 설정
cursor = conn.cursor(buffered=True)(4) insert문 만들기
sql = "INSERT INTO police_station VALUES (%s, %s)"(5) 데이터 입력
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()commit()
실행한 것이 database에 바로 적용이 되는 것이 아니라 commit한 순간 적용이 된다. 만일 for문을 실행하다가 10번을 돌아야하는데 6번쨰에서 fail이 난 경우, commit이 for문 바깥에 있다면 commit까지 도달하지 못하기 때문에 db에 들어가지 않는다. 반대로 commit이 for문 안에 있다면 다섯번째까지는 db에 들어가게 된다. 그러니까 commit한 순간 db에 저장된다.
(6) 결과 확인
cursor.execute("SELECT * FROM police_station")
result = cursor.fetchall()
for row in result:
print(row)(7) 검색 결과를 pandas로 읽기
df = pd.DataFrame(result)
dfcsv 한글이 깨지는 경우
: encoding 값을 'euc-kr' 로 설정 (특히 우리나라 사이트에서 제공받은 csv 파일들.)
import pandas as pd
df = pd.read_csv('2020_crime.csv', encoding='euc-kr')
df.head()14 PRIMARY KEY, FOREIGN KEY
PRIMARY KEY (기본키)
- 테이블의 각 레코드를 식별
- 중복되지 않은 고유값을 포함
- NULL값을포함할수없음
- 테이블 당 하나의 기본키를 가짐
primary key 생성 문법 1
CREATE TABLE tablename
(
col1 datatype not null,
col2 datatype not null,
...
CONSTRAINT constraint_name # 이 부분 생략 가능
PRIMARY KEY (col1, col2, ...)
);constraint
: 모든 제약 조건은 이름을 가지게 되는데, 위와 같이 UserID 열에 대해 기본 키를 설정하고 나면,
"PKUserTable3214EC27060DEAE8" 등과 같이 알아볼 수 없는 이름을 가지게 된다.
이는 SQLServer가 제약 조건의 이름을 나름의 규칙을 가지고 알아서 설정해 버리기 때문이다.
: UserTable에 PK가 설정되었다는 것까지는 알겠는데, 위와 같은 네이밍이면 어느 열이 PK인지 알아보기 쉽지 않다. 기본 키를 설정할 때 이름을 지정하려면 위 예문과 같이 작성하면 된다.
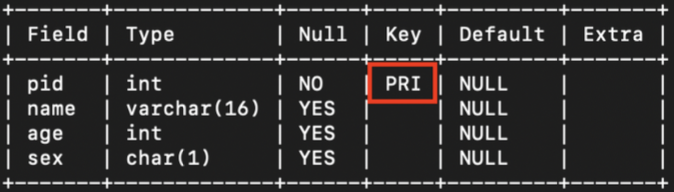
- 하나의 칼럼을 기본키로 설정하는 경우
create table person
(
pid int not null,
name varchar(16),
age int,
sex char,
primary key (pid)
);
- 여러개의 칼럼을 기본키로 설정하는 경우
create table animal
(
name varchar(16) not null,
type varchar(16) not null,
age int,
primary key (name, type)
);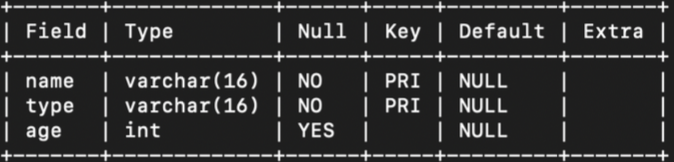
: table 당 기본키는 하나만 설정할 수 있기 때문에, PRI가 2개 명시되어 있다고 해서 key가 2개라는 뜻이 아니라, name과 type이 두개가 하나의 primary key라는 뜻이다.
primary key 삭제 문법
ALTER TABLE tablename
DROP PRIMARY KEY;: 이름을 별도로 기입할 필요가 없는 이유는, table당 하나의 primary key만 있기 때문.
- 하나 혹은 여러개의 칼럼이 기본키로 설정된 경우 (삭제 방법 동일)
alter table person (or animal)
drop primary key;primary key 생성 문법 2
: 이미 만들어져 있는 table에 primary key 속성을 추가하는 방법
ALTER TABLE tablename
ADD PRIMARY KEY (col1, col2, ...);- 하나의 칼럼을 기본키로 설정하는 경우
alter table person
add primary key (pid);- 여러개의 칼럼을 기본키로 설정하는 경우
alter table animal
add constraint PK_animal primary key (name, type);
# constraint를 생략했을 경우, 자동생성된다.FOREIGN KEY (외래키)
- 한 테이블을 다른 테이블과 연결해주는 역할
- 참조되는 테이블의 항목은 그 테이블의 기본키 (혹은 단일값)
- 외래키는 여러개 생성될 수 있다.
foreign key 생성 문법 1
create table tablename
(
col1 datatype not null,
col2 datatype not null,
col3 datatype,
col4 datatype,
...
constraint constraint_name
primary key (col1, col2, ...)
constraint constraint_name
FOREIGN KEY (col3, col4, ...) REFERENCES REF_tablename(REF_column)
);
# constraint 생략 가능: foreign key로 지정된 컬럼은 참조를 하는 칼럼이기 때문에 연결되는 다른 테이블이 있어야 한다. 그래서 레퍼런스를 줘야 하고, tablename과 REF_tablename이 연결되고, foreign key로 지정된 칼럼(col3, col4, ...)과 연결된 테이블(REF_tablename)에 지정된 칼럼(REF_column)이 연결되는 것이다.
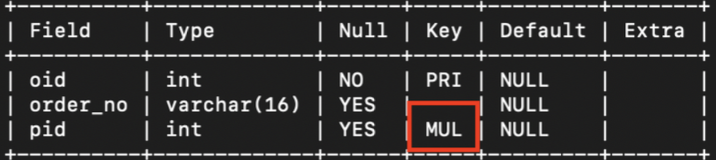
create table orders
(
oid int not null,
order_no varchar(16),
pid int,
primary key (oid),
constraint FK_person foreign key (pid) references person(pid)
);
constraint 확인 문법
- 자동 생성된 constraint를 확인하는 방법
SHOW CREATE TABLE tablename;foreign key 삭제 문법
alter table tablename
DROP FOREIGN KEY FK_constraint;alter table orders
drop foreign key FK_person;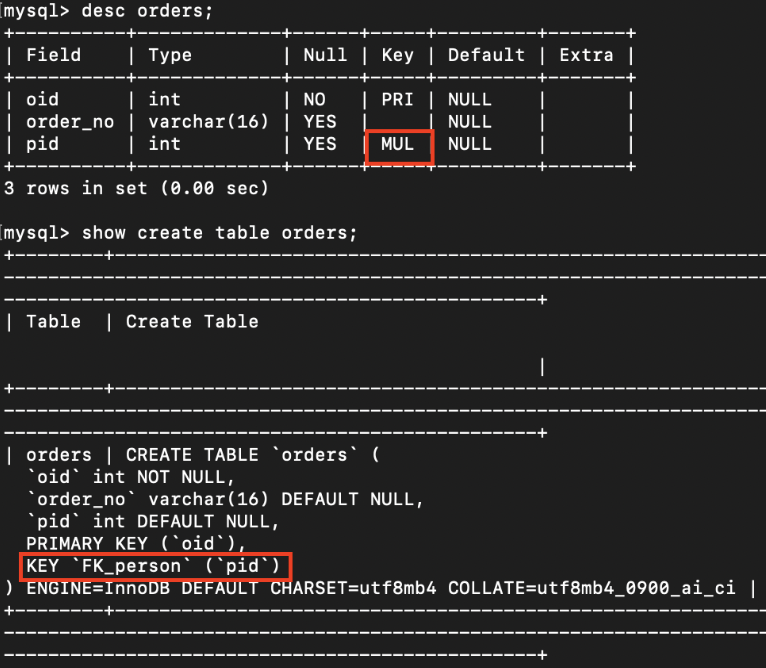
foreign key 생성 문법 2
: table이 생성된 이후에도 지정할 수 있다.
alter table tablename
ADD FOREIGN KEY (column) REFERENCES REF_tablename(REF_column);alter table orders
add foreignkey (pid) references person(pid);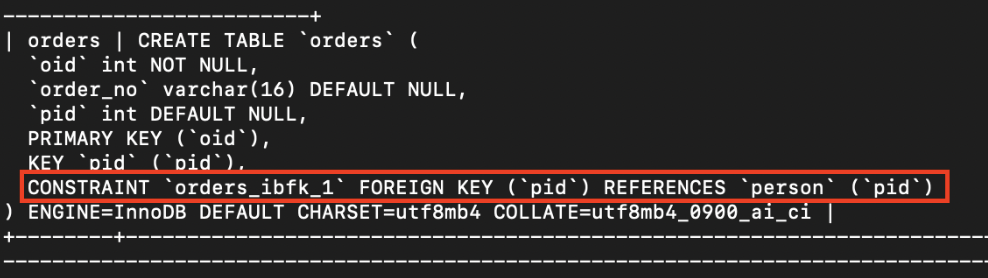
FOREIGN KEY 예제
: police_station 과 crime_status 테이블 사이에 관계 (Foreign Key)를 설정해 봅시다.
(AWS RDS(database-1) 의 zerobase 에서 작업합니다.)
- police_station.name 과 crime_status.police_station 을 매칭하여 관계를 맺도록하고 갯수 확인.
select count(distinct name) from police_station;
select count(distinct police_station) from crime_station;- 경찰서 이름이 각 테이블에서 표시되는 형식이 다릅니다.
select distinct name from police_station limit 3;
select distinct police_station from crime_station limit 3;- crime_status.police_station 을 police_station.name 과 같이 만들어서 비교하도록 합니다.
select c.police_station, p.name
from crime_status c, police_station p
where p.name like concat('서울', c.police_station, '경찰서')
group by c.police_station, p.name;- police_station.name 을 Primary Key 로 설정합니다.
alter table police_station
add primary key (name);
desc police_station;- crime_status 테이블에 Foreign Key 로 사용할 Column 추가
alter table crime_status
add column reference varchar(16);
desc crime_status;- Foreign Key 생성
alter table crime_status
add foreign key (reference) references police_station(name);
desc crime_status;- Foreign Key 값 Update
update crime_status c, police_station p
set c.reference = p.name
where p.name like concat('서울', c.police_station, '경찰서');
select distinct police_station, reference from crime_status;distinct
: 중복을 제거하고
JOIN
- Foreign Key 를 기준으로 두 테이블을 연관시켜 검색할 수 있다.
select c.police_station, p.address
from crime_status c, police_station p
where c.reference = p.name
group by c.police_station;15 Aggregate Function (집계함수)
: 여러 칼럼 혹은 테이블 전체 칼럼으로부터 하나의 결과값을 반환하는 함수
- count : 총 갯수를 계산해주는 함수
- sum : 합계
- avg : 평균
- min : 가장 작은 값
- max : 가장 큰 값
- first : 첫번째 결과값을 리턴하는 함수
- last : 마지막 결과값을 리턴하는 함수
COUNT
: 총 갯수를 계산해주는 함수
select COUNT(column)
from tablename
where condition;- police_station 테이블에서 데이터는 모두 몇개?
select count(*) from police_station;- crime_status 테이블에서 경찰서는 모두 몇군데?
select count(DISTINCT police_station) from crime_status;SUM
select SUM(column)
from tablename
where condition;- 범죄 총 발생건수는?
select sum(case_number) from crime_status
where status_type='발생';- 중부 경찰서에서 검거된 총 범죄 건수는?
select sum(case_number)
from crime_status
where status_type='검거' and police_station='중부';AVG
select AVG(column)
from tablename
where condition;- 평균 폭력 검거 건수는?
select avg(case_number)
from crime_status
where crime_type like '폭력' and status_type='검거';MIN
select MIN(column)
from tablename
where condition;- 중부경찰서에서 가장 낮은 검거 건수는?
select min(case_number)
from crime_status
where police_station like '중부' and status_type like '검거';MAX
select MAX(column)
from tablename
where condition;- 강남 경찰서에서 가장 많이 발생한 범죄 건수는?
select max(case_number)
from crime_status
where police_station like '강남' and status_type like '발생';GROUP BY
: 그룹화하여 데이터를 조회
select col1, col2, ...
from table
where condition
GROUP BY col1, col2, ...
order by col1, col2, ...;- (1) crime_status 에서 경찰서별로 그룹화 하여 경찰서 이름을 조회
select police_station
from crime_status
group by police_station
order by police_station
limit 5;- (1-1) 경찰서 종류를 검색 - DISTINCT 를 사용하는 경우 (ORDER BY 를 사용할 수 없음)
select distinct police_station from crime_status limit 5;- 경찰서 별로 총 발생 범죄 건수를 검색
select police_station, sum(case_number) 발생건수
from crime_status
where status_type like '발생'
group by police_station
order by 발생건수 desc
limit 5;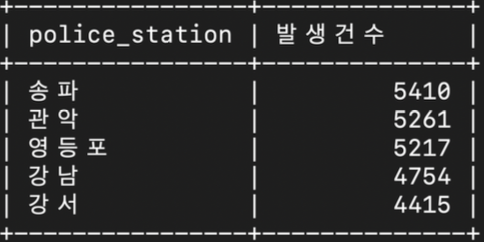
- 경찰서 별 평균 범죄 발생건수와 평균 범죄 검거 건수를 검색
select police_station, status_type, avg(case_number)
from crime_status
group by police_station, status_type
limit 6;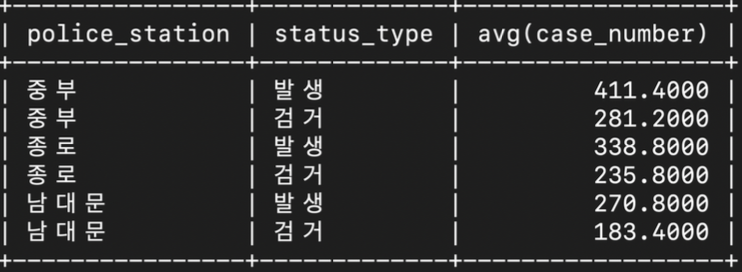
HAVING
: 조건에 집계함수가 포함되는 경우 where 대신 having 사용
select col1, col2, ...
from table
where condition
group by col1, col2, ...
HAVING condition (Aggregate Fucntion)
order by col1, col2, ...- 경찰서 별로 발생한 범죄 건수의 합이 4000 건보다 보다 큰 경우를 검색
select police_station, sum(case_number) count
from crime_status
where status_type = '발생'
group by police_station
having count > 4000;16 Scalar Functions
: 입력값을 기준으로 단일 값을 반환하는 함수
- UCASE : 영문을 대문자로 변환하는 함수
- LCASE : 영문을 소문자로 변환하는 함수
- MID : 문자열 부분을 반환하는 함수
- LENGTH : 문자열의 길이를 반환하는 함수
- ROUND : 지정한 자리에서 숫자를 반올림하는 함수 (0이 소숫점 첫째 자리)
- NOW : 현재 날짜 및 시간을 반환하는 함수
- FORMAT : 숫자를 천단위 콤마가 있는 형식으로 반환하는 함수
UCASE
: 영문을 대문자로 변환하는 함수
select UCASE(string);- $15 가 넘는 메뉴를 대문자로 조회
select ucase(menu), price
from sandwich
where price > 15;LCASE
: 영문을 소문자로 변환하는 함수
select LCASE(string);MID
: 문자열 부분을 반환하는 함수
select MID(string, start_position, length);- string : 원본 문자열
- start : 문자열 반환 시작 위치. (첫글자는 1, 마지막글자는 -1)
- length : 반환할 문자열 길이
- -8번 위치 (뒤에서 8번째 위치) 에서 3글자를 조회
select mid('This is mid test', -8, 3);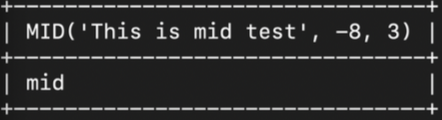
- 11위 카페이름 중 두번째 단어만 조회 - -4번 위치 (뒤에서 4번째) 에서 4글자
select mid(cafe, -4, 4) from sandwich where ranking = 11;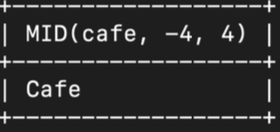
LENGTH
: 문자열의 길이를 반환하는 함수
select length(string);- 문자가 없는 경우 길이도 0
- 공백의 경우에도 문자이므로 길이가 1
- NULL 의 경우 길이가 없으므로 NULL
select length(null);- sandwich 테이블에서 Top 3의 주소 길이를 검색
select length(address), address from sandwich
where ranking <= 3;ROUND
: 지정한 자리에서 숫자를 반올림하는 함수 (0이 소숫점 첫째 자리)
select round(number, decimals_place);- number : 반올림할 대상
- decimals : 반올림할 소수점 위치 (Option)
- 반올림할 위치를 지정하지 않을 경우, 소수점 자리 (0) 에서 반올림
- 소수점 첫번째 위치는 0
- 일단위 위치는 -1, 십단위 위치는 -2
- sandwich 테이블에서 소수점 자리는 반올림해서 1달러 단위까지만 표시 (최하위 3개만 표시)
select ranking, price, round(price) from sandwich
order by ranking desc
limit 3;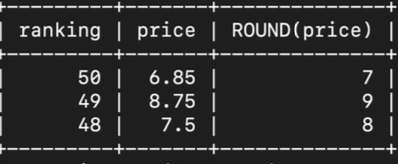
NOW
: 현재 날짜 및 시간을 반환하는 함수
select NOW();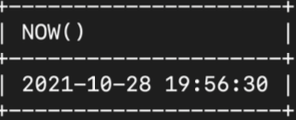
FORMAT
: 숫자를 천단위 콤마가 있는 형식으로 반환하는 함수
select FORMAT(number, decimal_place);- number : 포맷을 적용할 문자 혹은 숫자
- decimals : 표시할 소수점 위치, 소수점을 표시하지 않을 경우 0
- oil_price 테이블에서 가격이 백원단위에서 반올림 했을 때 2000원 이상인 경우 천원단위에 콤마를 넣어서 조회
select format(가격, 0) from oil_price
where round(가격, -3) >= 2000;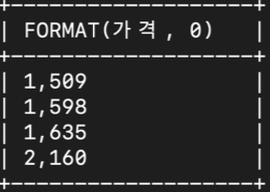
17 SQL Subquery
Subquery
: 하나의 SQL 문 안에 포함되어 있는 또 다른 SQL 문. 메인쿼리가 서브쿼리를 포함하는 종속적인 관계이다.
• 서브쿼리는 메인쿼리의 칼럼 사용 가능
• 메인쿼리는 서브쿼리의 칼럼 사용 불가
Subquery 사용시 주의
- Subquery 는 괄호로 묶어서 사용
- 단일행혹은복수행비교연산자와함께사용가능
- subquery 에서는 order by 를 사용X
Subquery 종류
- 스카라 서브쿼리 (Scalar Subquery) - SELECT 절에 사용
- 인라인 뷰 (Inline View) - FROM 절에 사용
- 중첩 서브쿼리 (Nested Subquery) - WHERE 절에 사용
스칼라 서브쿼리 (Scalar Subquery)
: SELECT 절에서 사용하는 서브쿼리. 결과는 하나의 Column 이어야 한다.
select col1, (select col2 from table2 where condition)
from table1
where condition;- 서울은평경찰서의 강도 검거 건수와 서울시 경찰서 전체의 평균 강도 검거 건수를 조회
select case_number,
(select avg(case_number)
from crime_status
where crime_type like '강도' and status_type like '검거') avg
from crime_status
where police_station like '은평' and crime_type like '강도' and status_type like '검거';인라인 뷰 (Inline View)
: FROM 절에 사용하는 서브쿼리. 메인쿼리에서는 인라인 뷰에서 조회한 Column 만 사용가능하다.
select a.column, b.column
from table1 a, (select col1, col2 from talbe2) b
where condition;- 경찰서 별로 가장 많이 발생한 범죄 건수와 범죄 유형을 조회
select c.police_station, c.crime_type, c.case_number
from crime_status c,
(select police_station, max(case_number) count
from crime_status
where status_type like '발생'
group by police_station) m
where c.police_station = m.police_station
and c.case_number = m.count;중첩 서브쿼리 (Nested Subquery)
: WHERE 절에서 사용하는 서브쿼리.
- Single Row - 하나의 열을 검색하는 서브쿼리
- Multiple Row - 하나 이상의 열을 검색하는 서브쿼리
- Multiple Column - 하나 이상의 행을 검색하는 서브쿼리
Single Row Subquery
: 하나의 열을 검색하는 서브쿼리.
서브쿼리가 비교연산자( =, >, >=, <, <=, <>, !=)와 사용되는 경우,
서브쿼리의 검색 결과는 한 개의 결과값을 가져야 한다. (두개 이상인 경우 에러)
select column_names
from table_name
where column_name = (select column_name
from table_name
where condition)
order by column_name;- <에러> 1 : 괄호 없이
select name from celeb
where name = select host from snl_show;- <에러> 2 : 한 개 이상의 결과
select name from celeb
where name = (select host from snl_show);- 올바른 예
select name from celeb
where name = (select host from snl_show
where id = 1);Multiple Row - IN
: 하나 이상의 열을 검색하는 서브쿼리
: 서브쿼리 결과 중에 포함 될때
select column_names
from table_name
where column_name in (select column_name
from table_name
where condition)
order by column_names;- SNL에 출연한 영화배우 조회
select host
from snl_show
where host in (select name
from celeb
where job_title like '%영화배우%');Multiple Row - EXISTS
: 하나 이상의 열을 검색하는 서브쿼리
: 서브쿼리 결과에 값이 있으면 반환
select column_names
from talbe_name
where exists (select column_name
from table)name
where condition)
order by column_names;- 범죄 검거 혹은 발생 건수가 2000건 보다 큰 경찰서 조회
select name
from police_station p
where exists (select police_station
from crime_status c
where p.name = c.reference and case_number > 2000);Multiple Row - ANY
: 하나 이상의 열을 검색하는 서브쿼리
: 서브쿼리 결과 중에 최소한 하나라도 만족하면 (비교연산자 사용)
select column_names
from table_name
where column_name any (select column_name
from table_name
where condition)
order by column_names;- SNL 에 출연한 적이 있는 연예인 이름 조회
select name
from celeb
where name = any (select host
from snl_show);Multiple Row - ALL
: 하나 이상의 열을 검색하는 서브쿼리
: 서브쿼리 결과를 모두 만족하면 (비교 연산자 사용)
select column_names
from table_name
where column_name = all (select column_name
from table_name
where condition)
order by column_names;- 예제
select name
from celeb
where name = all (select host
from snl_show
where id = 1);Multi Column Subquery - 연관 서브쿼리
: 하나 이상의 행을 검색하는 서브쿼리
: 서브쿼리 내에 메인쿼리 컬럼이 같이 사용되는 경우.
select column_names
from tablename a
where (a.col1, a.col2, ...) in (select (b.col1, b.col2, ...)
from tablename b
where a.column_name = b.column_name)
order by column_names;- 강동원과 성별, 소속사가 같은 연예인의 이름, 성별, 소속사를 조회
select name, sex, agency
from celeb
where (sex, agency) in (select sex, agency
from celeb
where name = '강동원');