Kafka
- 아파치 소프트웨어 재단에서 관리하는 오픈 소스 메시지 스트리밍 플랫폼
- 링크드인이 개발해서 2011년 오픈 소스화
특징
- 발행/구독 (Pub/Sub) 모델 기반: 프로듀서는 메시지를 발행하고 컨슈머는 구독하여 메시지를 소비
- Reactive Systems의 Message Driven (메시지 기반)을 지원
- 고성능: 메시지를 빠르게 처리할 수 있는 고성능 설계
- Reactive Systems의 Responsive (응답성)을 지원
- 확장성: 클러스터를 통해 요청 처리량을 늘리거나 데이터 볼륨을 증가
- Reactive Systems의 Elastic (유연성)을 지원
- 고가용성: 데이터의 복제본을 여러 서버에 분산 저장. 서버 하나가 실패해도 데이터 손실을 방지
- Reactive Systems의 Resilient (복원력)을 지원
Kafka 만들기
토픽
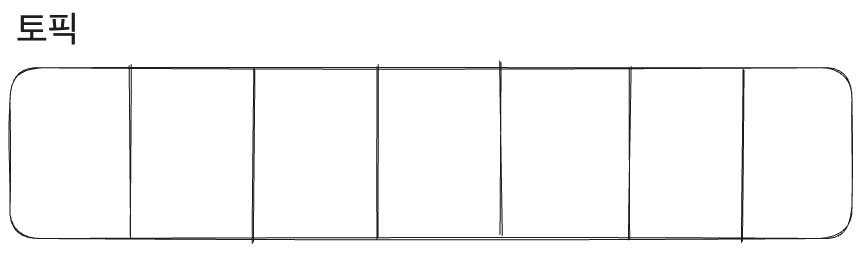
- 데이터를 생성하고 읽을 때, 메시지 큐에 데이터를 분류하기 위한 카테고리가 필요한데 이 카테고리를 토픽이라고 한다.
메시지와 프로듀서
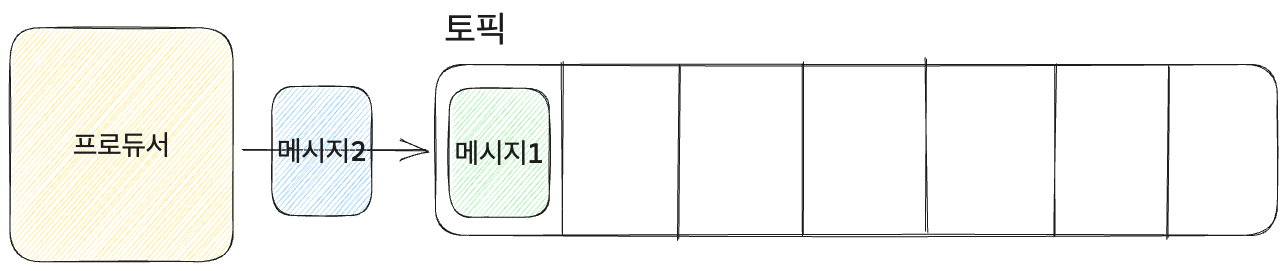
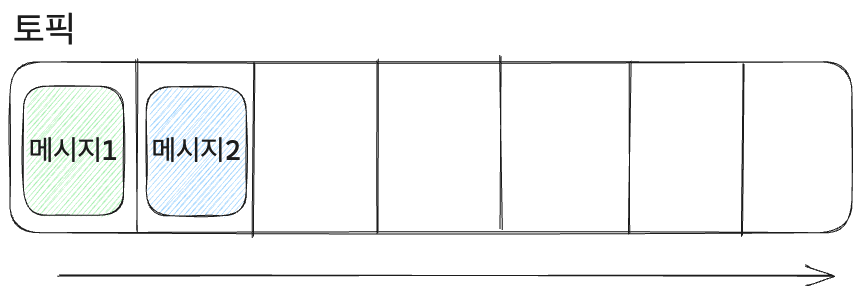
- 메시지: 토픽에 포함되는 데이터.
- 메시지는 key와 value, timestamp로 구성
- 프로듀서: 토픽에 메시지를 추가하는 주체
컨슈머
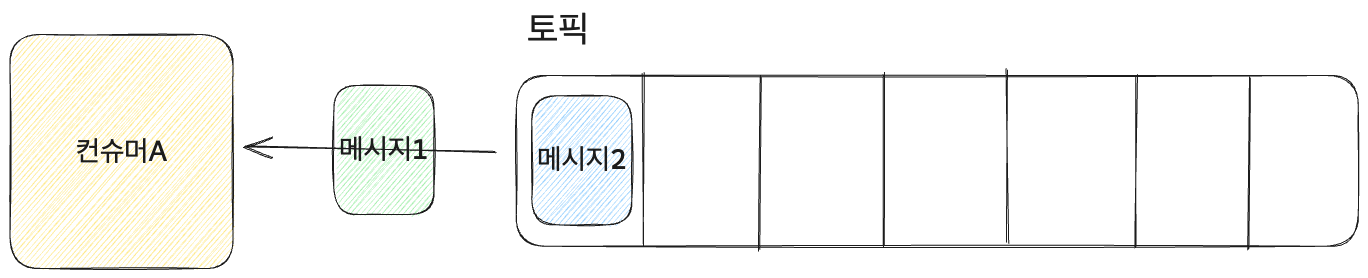
- 컨슈머: 토픽을 구독하여 메시지를 읽는 주체.
- 토픽은 기본적으로 FIFO라 컨슈머는 가장 처음 추가되었던 메시지를 읽는다.
컨슈머 경쟁
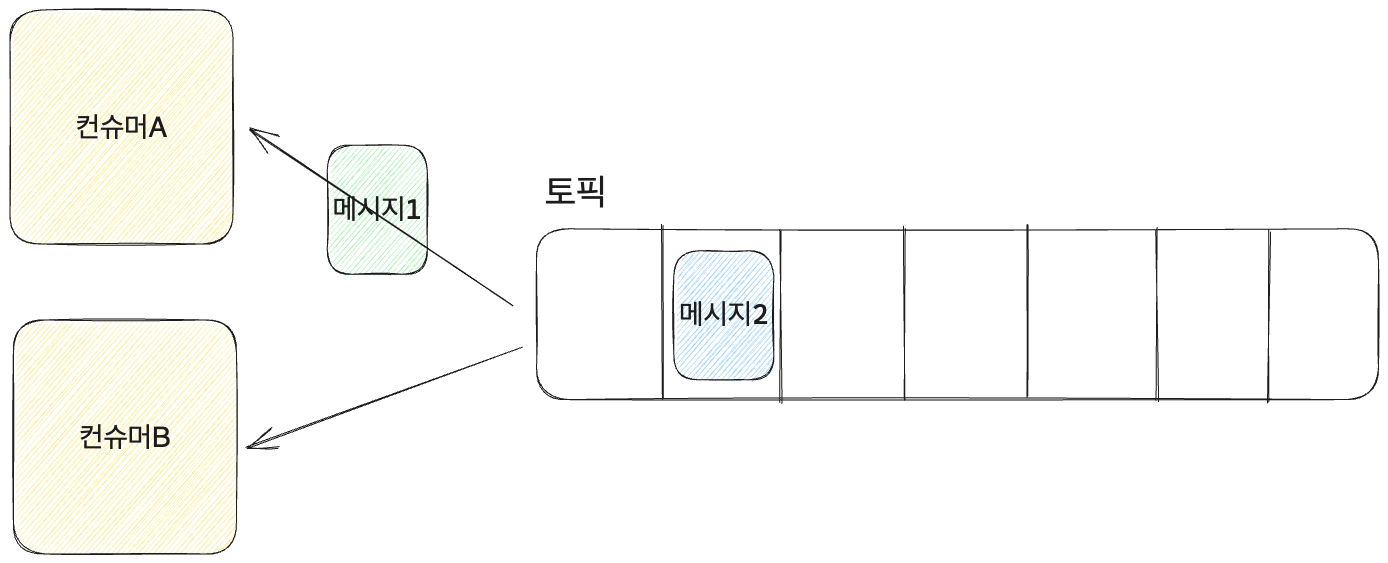
- 컨슈머A와 컨슈머B가 메시지1, 메시지2를 모두 읽어야 한다면? 현재 상황에서는 물리적으로 가져가기 때문에 컨슈머A와 컨슈머B는 서로 메시지를 가져가기 위해 경쟁한다.
- 이를 해결하기 위해 논리적인 방법으로 메시지를 가져가는 오프셋 개념이 나온다.
오프셋
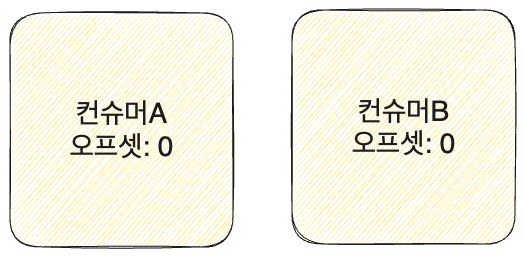
- 각각의 컨슈머는 오프셋을 갖는다. 각각의 컨슈머는 오프셋을 통해서 컨슈머가 가장 마지막으로 읽은 메시지를 기록한다.
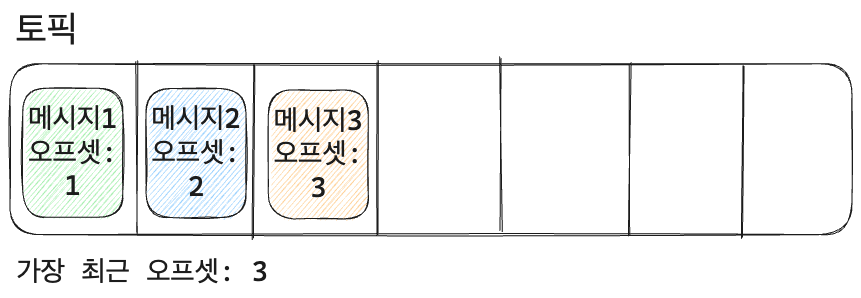
- 각각의 메시지도 오프셋을 가지고, 토픽 내에서의 오프셋은 고유하고 오름차순으로 정의된다.
컨슈머 읽기
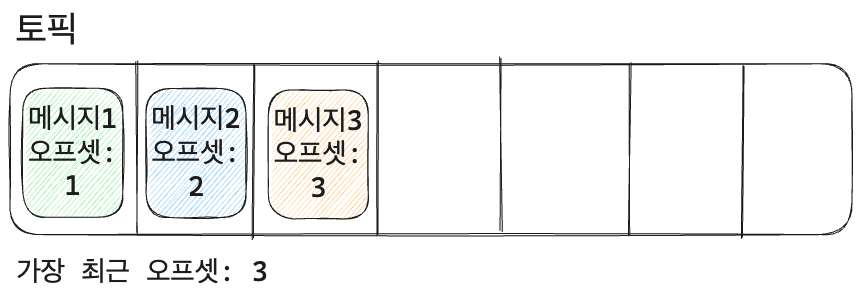
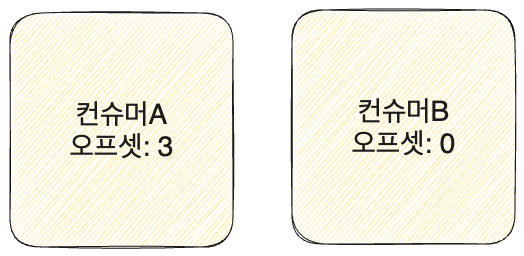
- 컨슈머 A
- 오프셋을 증가시키면서 범위 안에 포함된 메시지를 전달한다. 메시지3에 도달하면 컨슈머 A는 본인의 오프셋을 3으로 바꾸고 중단한다. 이후 추가적인 메시지가 들어오면 다시 오프셋을 갱신하며 읽는다.
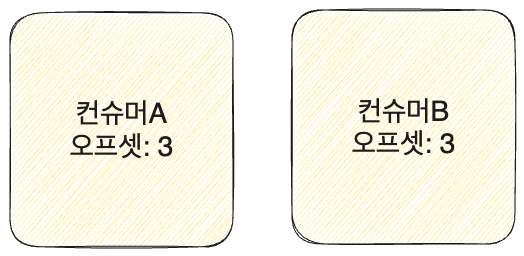
- 컨슈머 B
- B도 마찬가지로 메시지 1,2,3을 읽고 오프셋을 3으로 변경
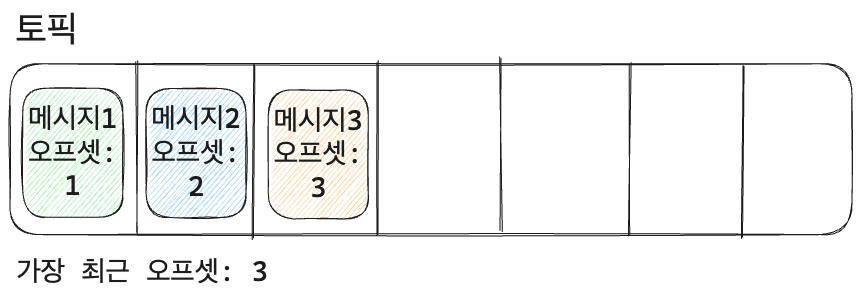
- 모든 과정이 끝났지만 토픽에는 메시지가 유지되고 컨슈머 A,B는 오프셋 3까지 데이터를 읽었다.
- 만약 여기서 컨슈머 C가 추가 되면 다시 처음부터 메시지를 읽을 수 있다.
랙 (lag)
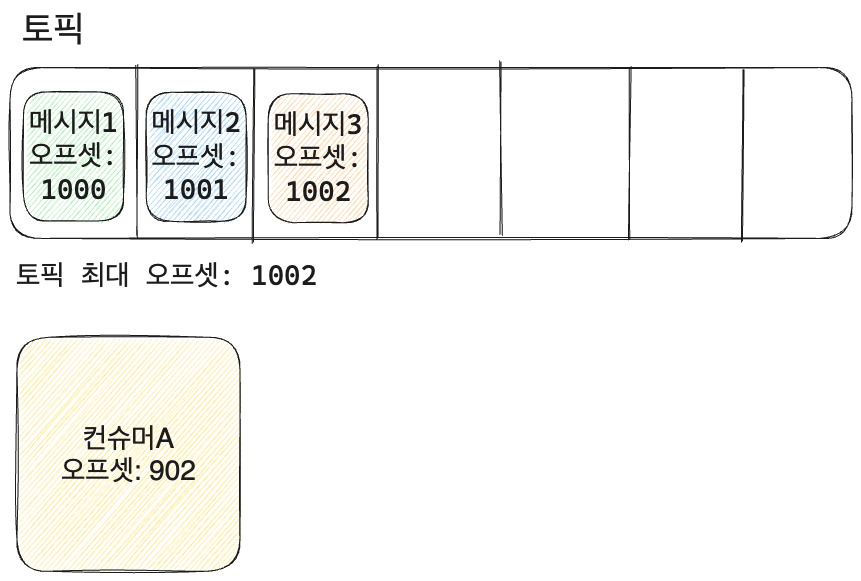
- 컨슈머가 메시지를 가져가서 읽는 속도와 토픽에 메시지가 쌓이는 부분에서 속도 차이가 발생하는데 이를 랙이라고 한다.
- 이상적인 랙은 0과 가까운 값을 유지하는 것
- 간혹 랙이 커지는 경우가 있는데, 이는 메시지가 쌓이는 속도가 처리하는 속도보다 빠르다는 뜻. 보통 대시보드에 이를 감지할 수 있는 기능이 있음.
오프셋 공유?
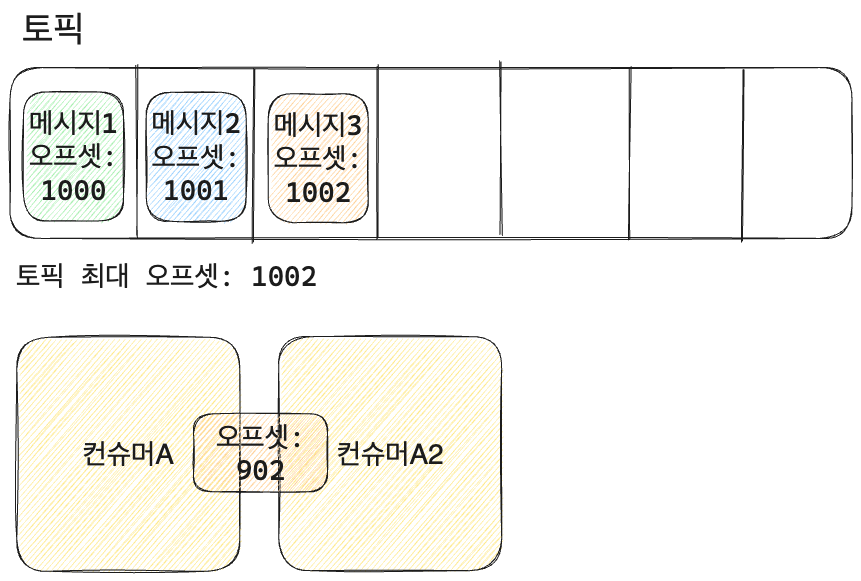
- 오프셋을 공유하는 컨슈머A2를 만들어서 토픽에서 메시지를 같이 처리할 수는 없을까? -> 불가능
- 오프셋을 공유하는 것부터가 문제가 된다.
- 컨슈머는 다른 서버에 뜨는 경우 (다른 프로세스) 이를 연결해줄 데이터베이스를 둬야하고, 각각의 컨슈머는 읽고 커밋 단계를 동시에 한다. 또한 메시지를 읽는 도중에 에러가 발생해 롤백이 발생하는 경우도 존재하는데 로직이 너무 복잡해진다.
- 독립적이지 않더라해도 (다른 스레드) 토픽의 메시지를 읽고 오프셋을 갱신하는 작업이 반복되기 때문에 싱크 문제가 발생하게 된다.
- 하나를 바라보는 정책을 유지하되 토픽을 여러 개를 두는 방법으로 두면 어떨까?
파티션
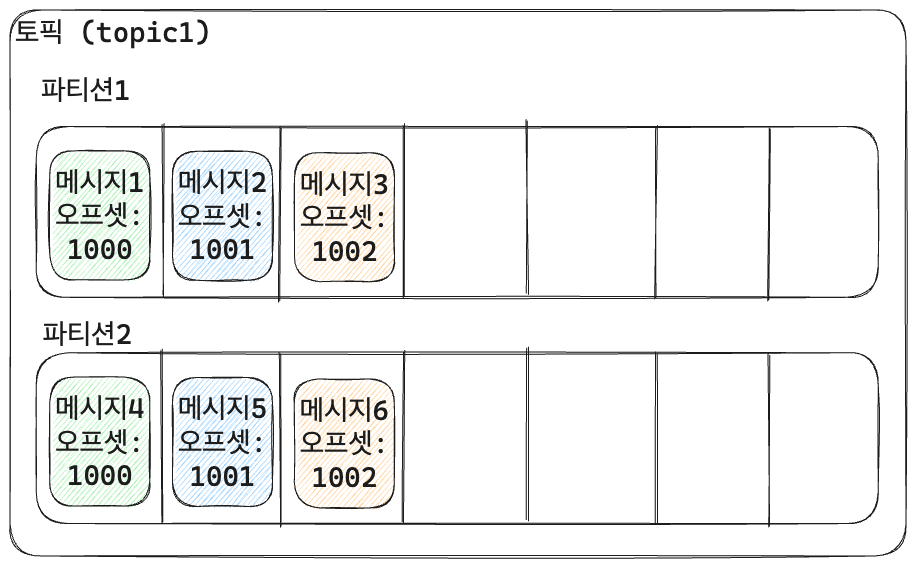
- 파티션: 토픽을 세분화하여 병렬처리를 지원하는 단위
- 토픽 내부를 여러 개로 나누고 나눈 부분을 파티션이라고 한다.
- 하나의 토픽은 1개 이상의 파티션으로 구성되어 있고 독립적이다.
- 독립적이기 때문에 파티션1과 파티션2는 각각 다른 컨슈머가 붙을 수 있다.
파티션과 컨슈머 그룹
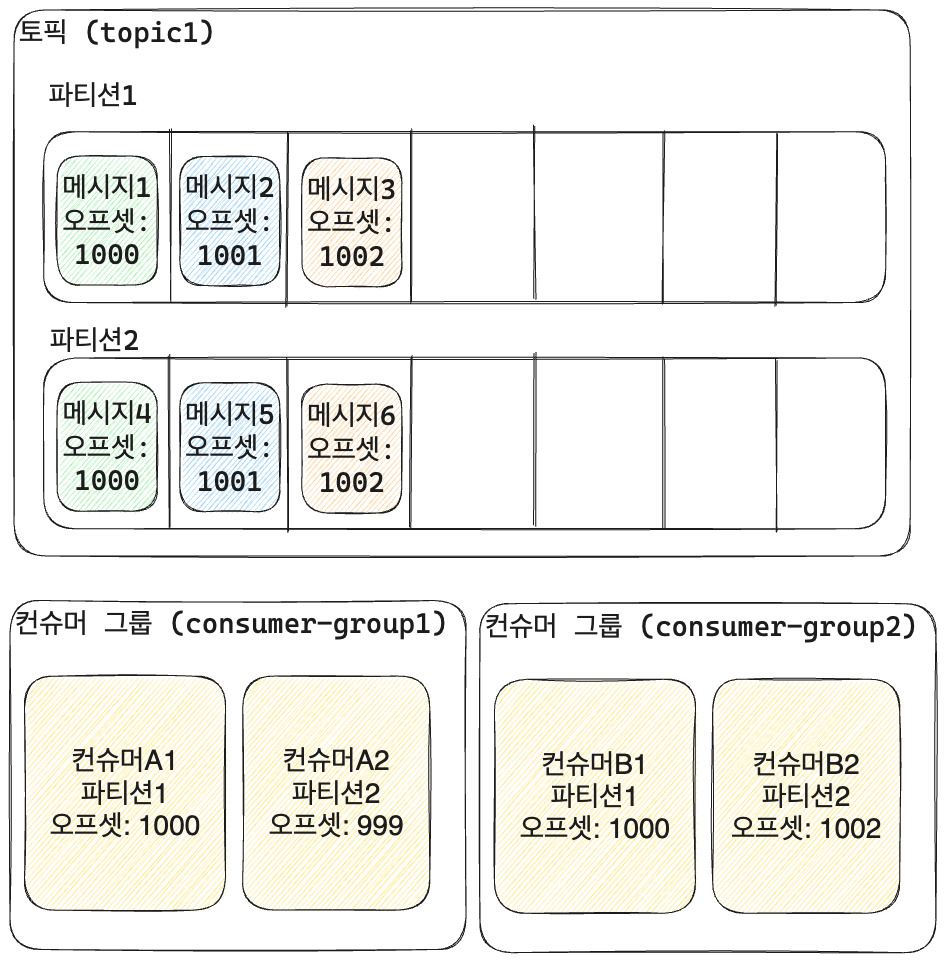
- 컨슈머 그룹: 하나의 토픽을 바라보고 다른 파티션을 담당하는 컨슈머들의 그룹
- 만약 컨슈머 그룹 내의 컨슈머 숫자가 파티션보다 크다면?
- 하나의 컨슈머 당 하나의 파티션을 담당하므로 성능 차이는 없다.
- 다만 파티션을 담당하는 컨슈머가 장애가 났을 경우 다른 컨슈머가 대신 파티션을 담당할 수는 있다.
파티션과 프로듀서
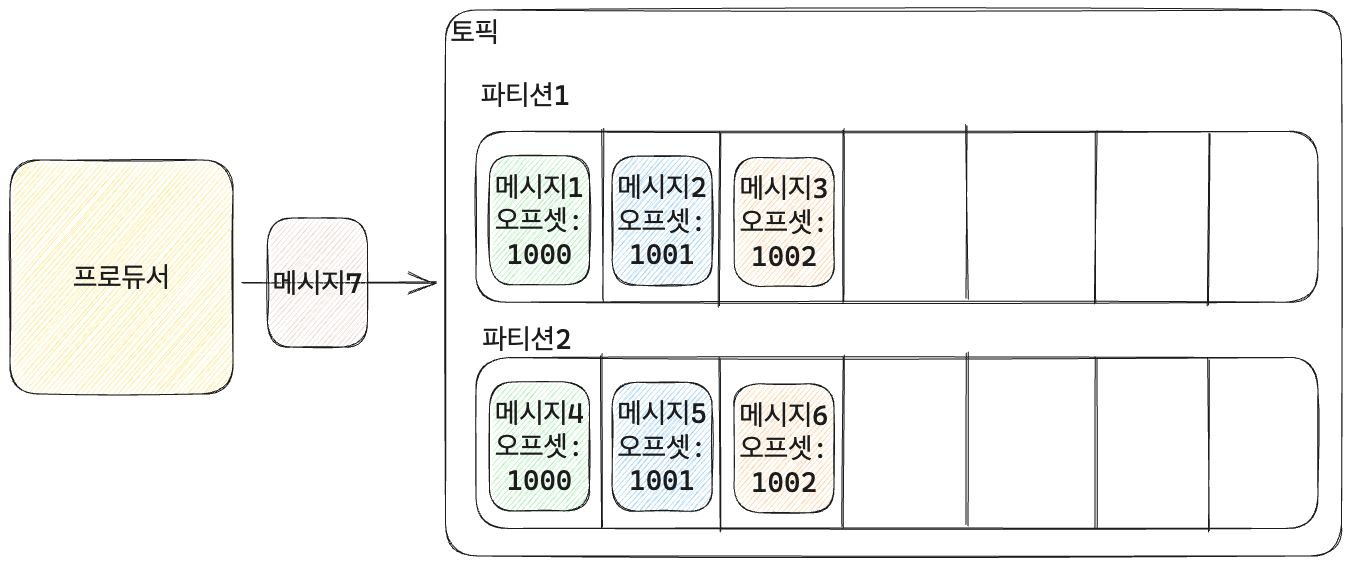
- 여러 파티션으로 구성된 토픽을 컨슈머 그룹이 담당한다.
- 프로듀서는 기본적으로 라운드 로빈 방식으로 파티션에 메시지를 넣는다.
- 하지만 메시지의 순서가 중요한 경우에는 라운드 로빈 방식으로 메시지를 넣으면 안되는데 이러한 경우에는 어떻게 메시지를 넣어야 할까?
메시지의 순서
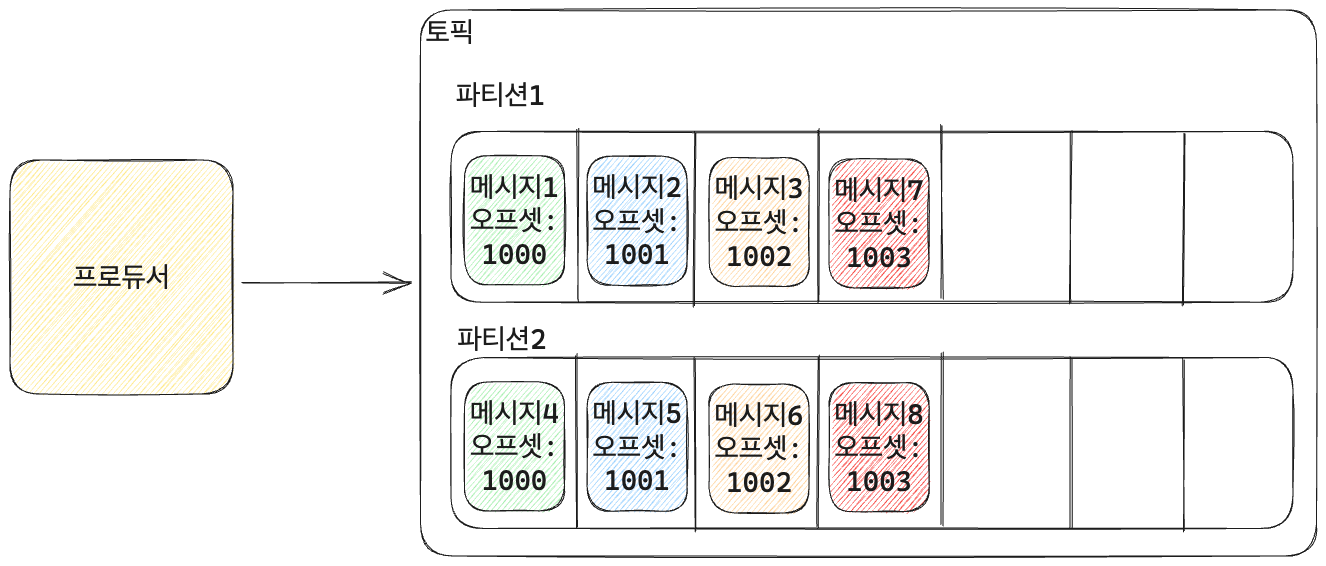
- 만약 메시지의 순서가 중요한 상황이라면?
- 예를 들어 메시지에 주문의 이벤트를 넣는 경우라고 가정해보자
- 1000번이라는 주문의 이벤트들를 모두 토픽에 넣는 경우에 주문 완료가 되면 데이터베이스에 값을 저장하고, 결제 완료가 될 경우에 값을 가져와서 처리하게 하는 이벤트를 하나의 같은 파티션에 넣어야 한다.
- 라운드 로빈 방식대로라면 주문 완료와 결제 완료 이벤트가 다른 파티션에 들어갈 수 있다. 이 경우 결제 완료 이벤트가 주문 완료 이벤트보다 먼저 처리될 수도 있다.
- 그렇다고 파티션을 하나만 두면 성능이 저하가 될 것이다.
메시지 키
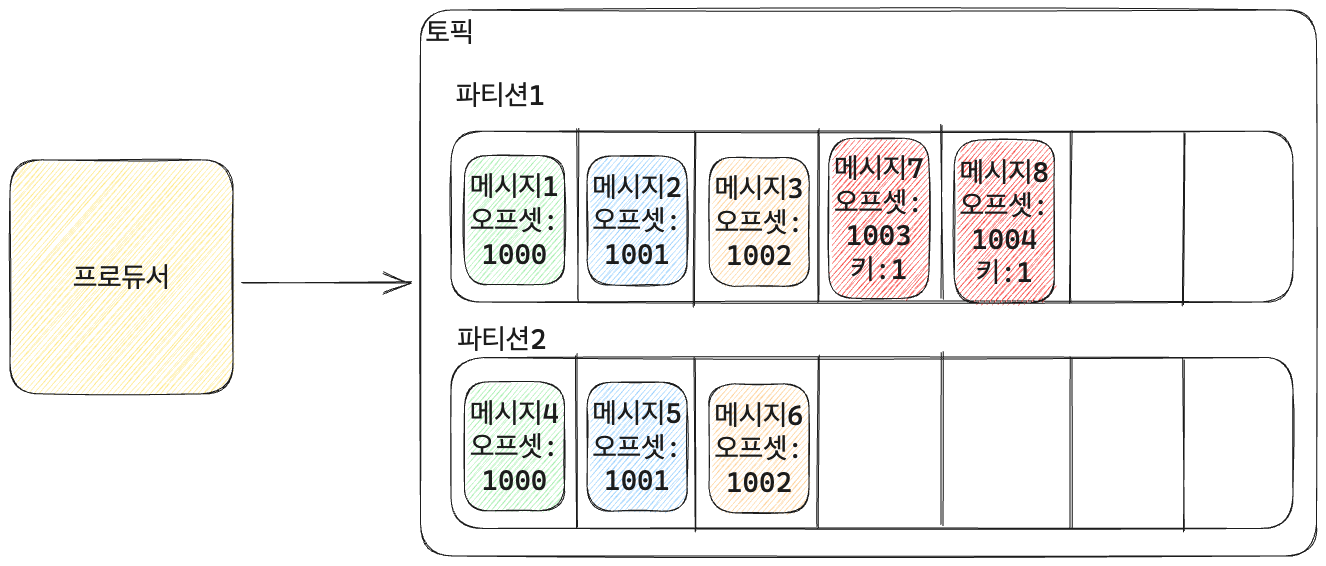
- 메시지는 key, value, timestamp로 구성.
- key를 지정하여 같은 파티션에 들어가야 하는 메시지를 지정 가능.
- 프로듀서는 key만 지정하고 key를 기반으로 어떤 파티션에 메시지를 넣어야 할지는 카프카가 담당한다.
- 앞선 예를 다시 적용해보면 프로듀서가 1000번이라는 주문 정보를 1번이라는 key로 지정한 다음 주문 완료, 결제 완료 이벤트를 토픽에 추가하면 카프카는 같은 파티션에 이 메시지들을 추가한다.
브로커
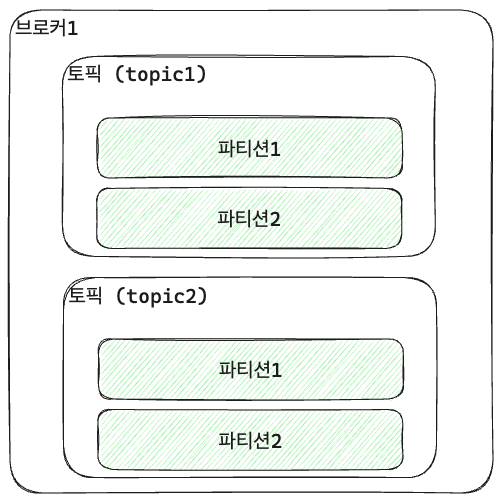
- 브로커: 카프카 클라이언트와 데이터를 주고받기 위해 사용되는 주체로, 하나의 물리서버이다.
- 하나의 브로커는 여러 토픽을 제공한다.
- 만약 하나의 브로커만 바라보는 상황에서 브로커에 장애가 발생한다면?
클러스터
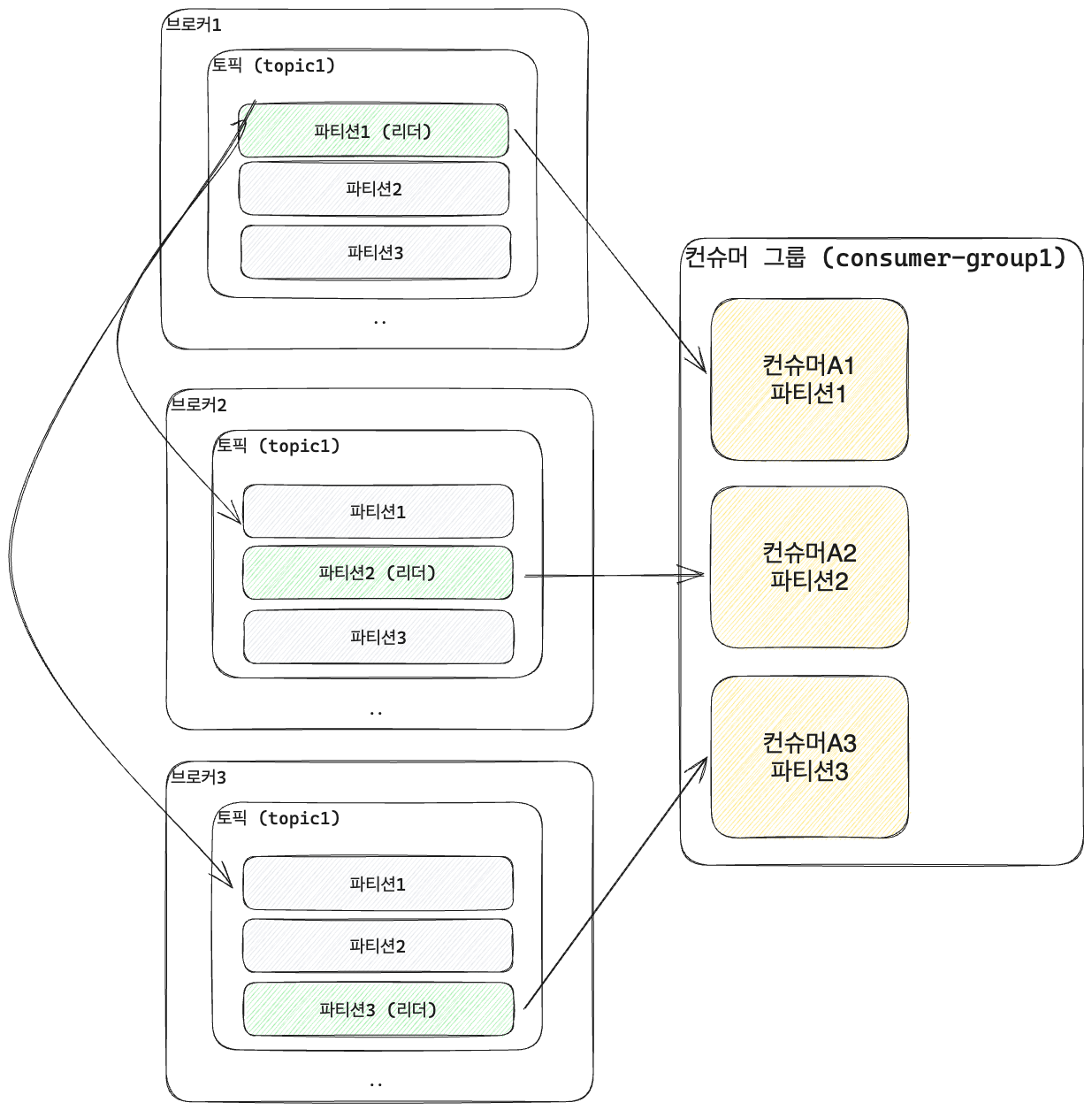
- 클러스터: 브로커들의 집합체
- 브로커 1,2,3은 모두 같은 Topic1을 포함한다.
- 같은 파티션을 가지고 있지만 각각의 브로커에서 하나의 파티션을 리더로 선정하고, 리더 파티션의 브로커와 컨슈머 그룹이 매핑이 되는 구조다.
- 또한 같은 이름을 갖는 파티션들은 사용하지 않는다 하더라도 데이터를 서로 싱크한다.
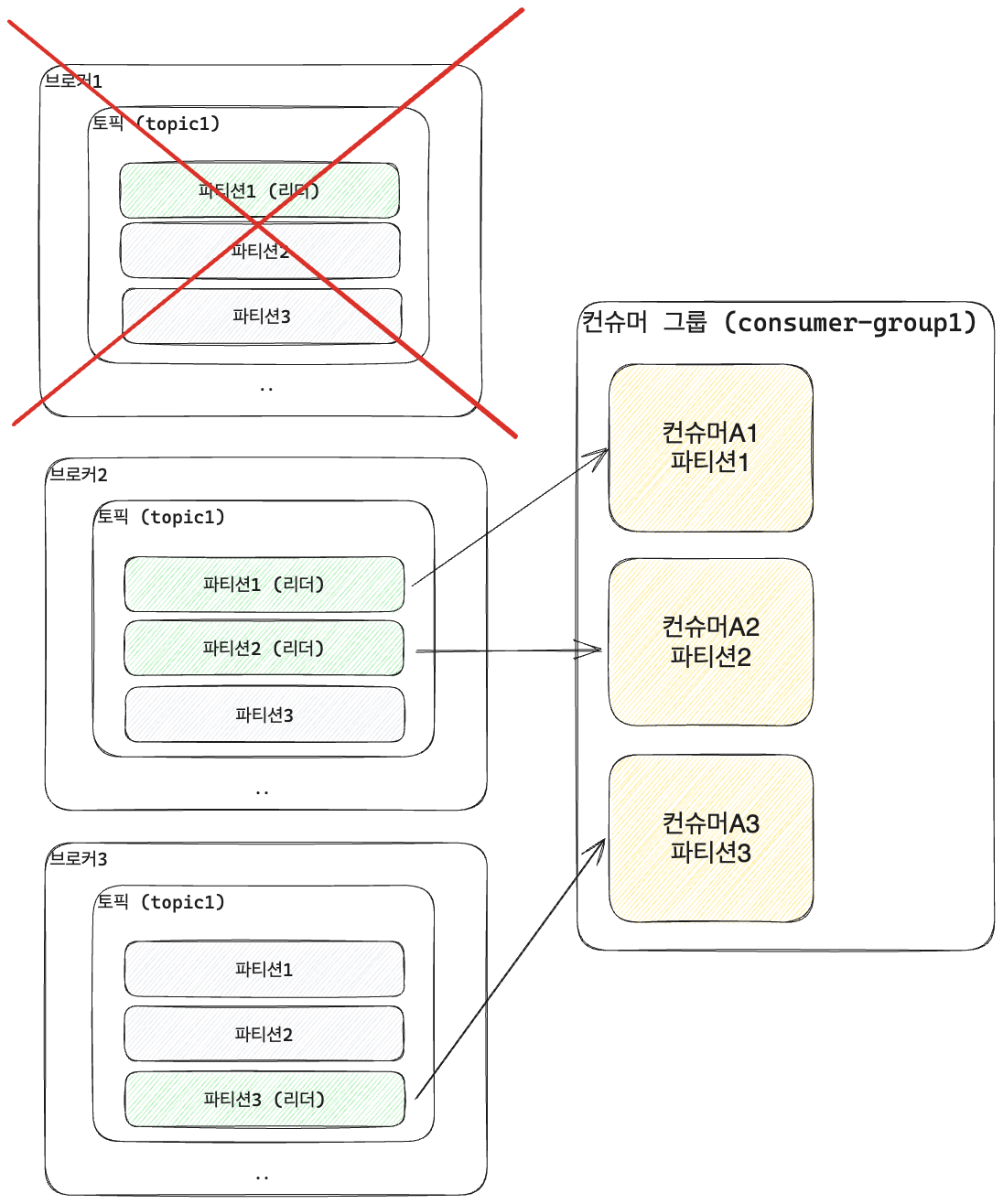
- 만약 브로커 1이 문제가 발생하면 다른 브로커의 파티션이 리더로 선정되어, 컨슈머와 데이터를 주고 받는다.
Reference: https://fastcampus.co.kr/dev_online_webflux

평범한 백엔드 개발자