[MySQL] Index
- 인덱스는 테이블의 조회를 높여주는 자료구조이다
인덱스를 쓰는 이유
- 조건을 만족하는 튜플을 빠르게 조회하기 위해
- 빠르게 정렬하거나 그룹핑 하기 위해
SELECT * FROM customer WHERE first_name = 'Daehoon'
DELETE FROM logs where log_datetime < '2023-12-31'
SELECT * FROM employee E join department D on E.dept_id = D.id- 즉, 특정 조건을 만족하는 컬럼을 찾기 위해 인덱스를 사용한다
테이블의 인덱스 확인하기
show index from table_name- show index 키워드를 앞에 붙이면 해당 테이블의 인덱스 정보를 확인할 수 있다.

Table: Table 이름Non_unique: Index의 Unique 여부, 0이면 유니크, 1이면 논 유니크key_name: 키 이름Seq_in_index: 인덱스의 순서, 복합 인덱스의 경우 이 순서를 기준으로 데이터를 조회함Column_name: 인덱스 대상 컬럼Coliation: 인덱스의 기본적인 정렬 형태. A:오름차순, NULL:정렬구분 없음Cardinality: 해당 인덱스 값의 Unique 값의 수.index_type: 인덱스 모드(BTREE, FULLTEXT, HASH, RTREE) / FULLTEXT 는 5.7 이상에서 유효
B-Tree 기반 인덱스 조회 방식
CREATE INDEX (a)

- 인덱스는 a에 대한 값과 포인터를 가지고 있다.
- a의 값은 정렬되어 있는 상태고, 포인터는 실제의 MEMBERS의 테이블에 있는 튜플과 맵핑하는 값이 들어있다.
WHERE a = 9
- 키가 정렬이 되어 있어 기본적으로 Binary Search를 통해 찾는다.
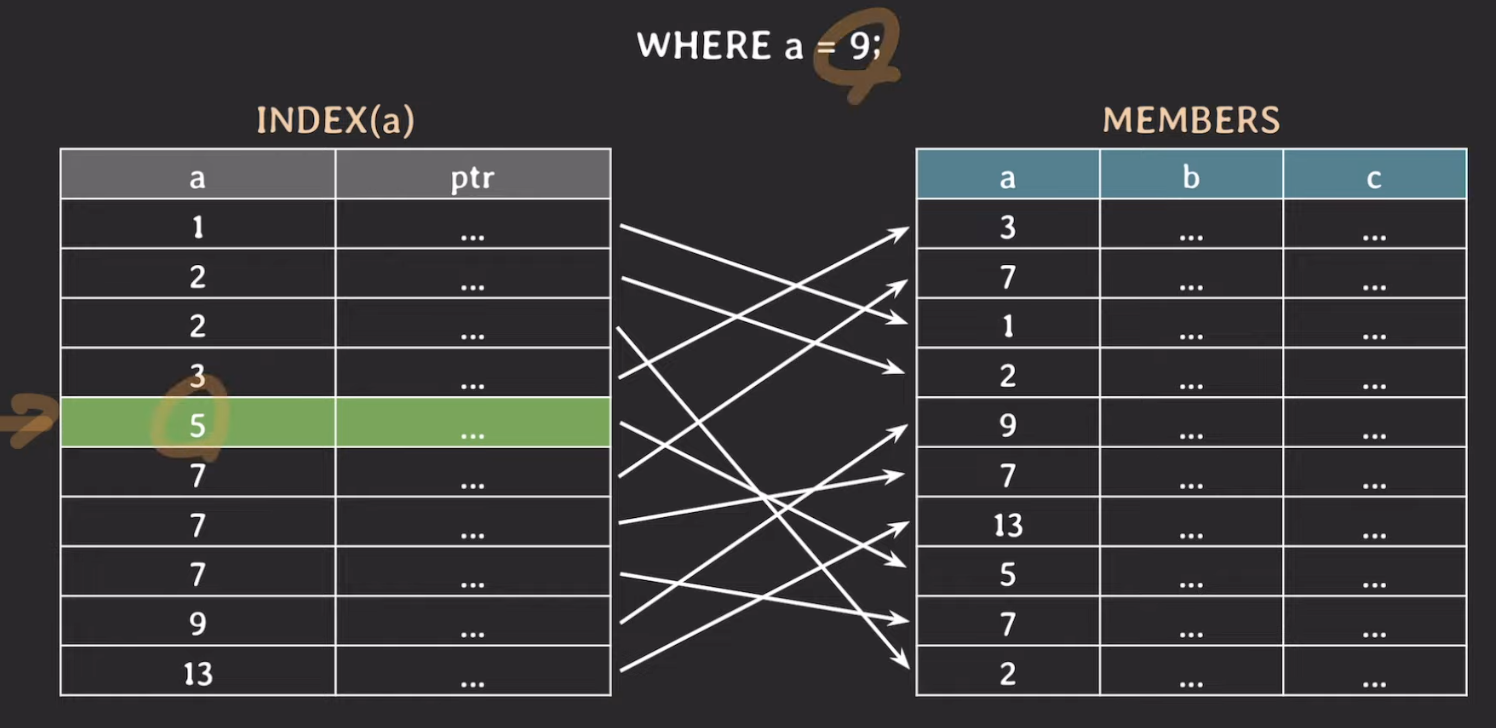
- 5는 9보다 작아서, 5보다 작은 인덱스 값은 조회하지 않고 5-13 사이에서 다시 Binary Search를 진행한다.
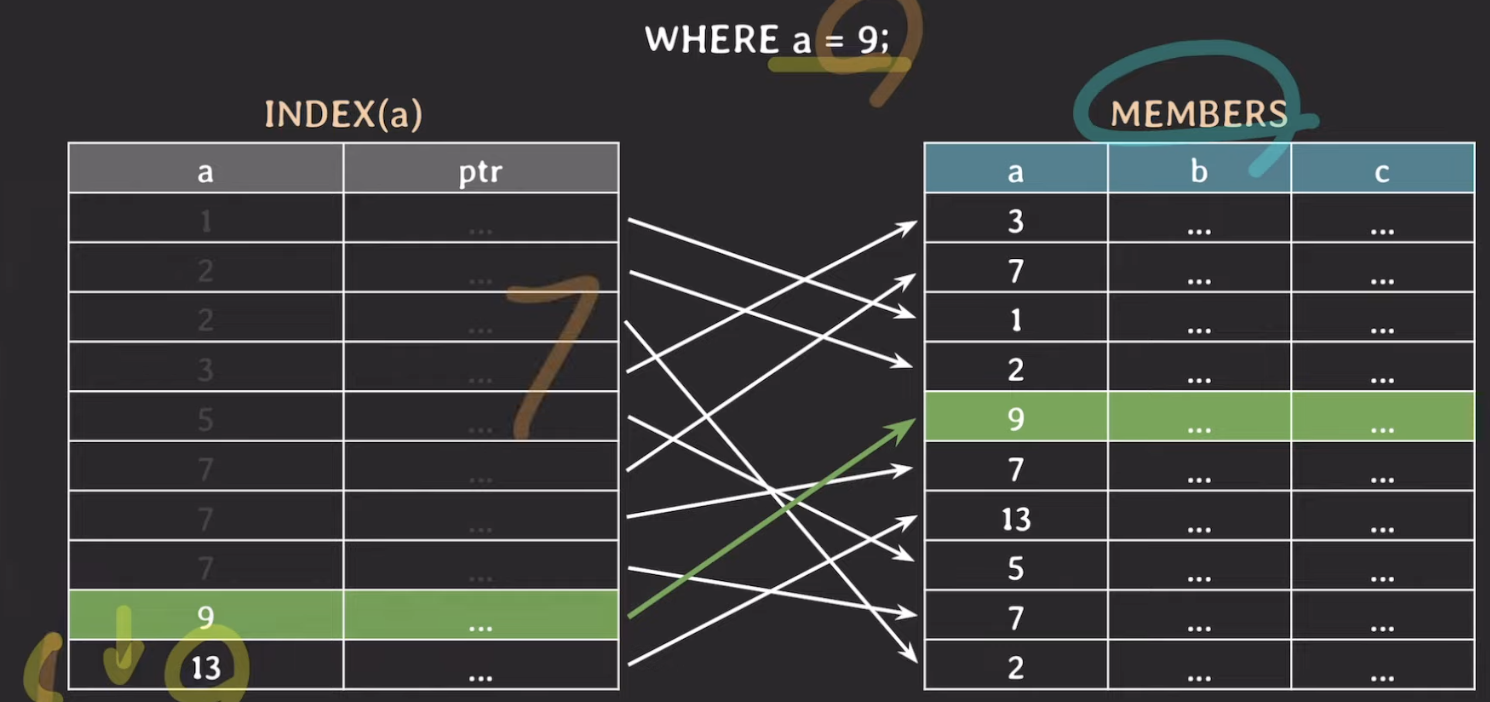
- Binary Search를 통해 해당 값을 찾으면 ptr의 값으로 테이블과 맵핑하여 실제 값을 찾는다.
WHERE a = 7 AND B = 95
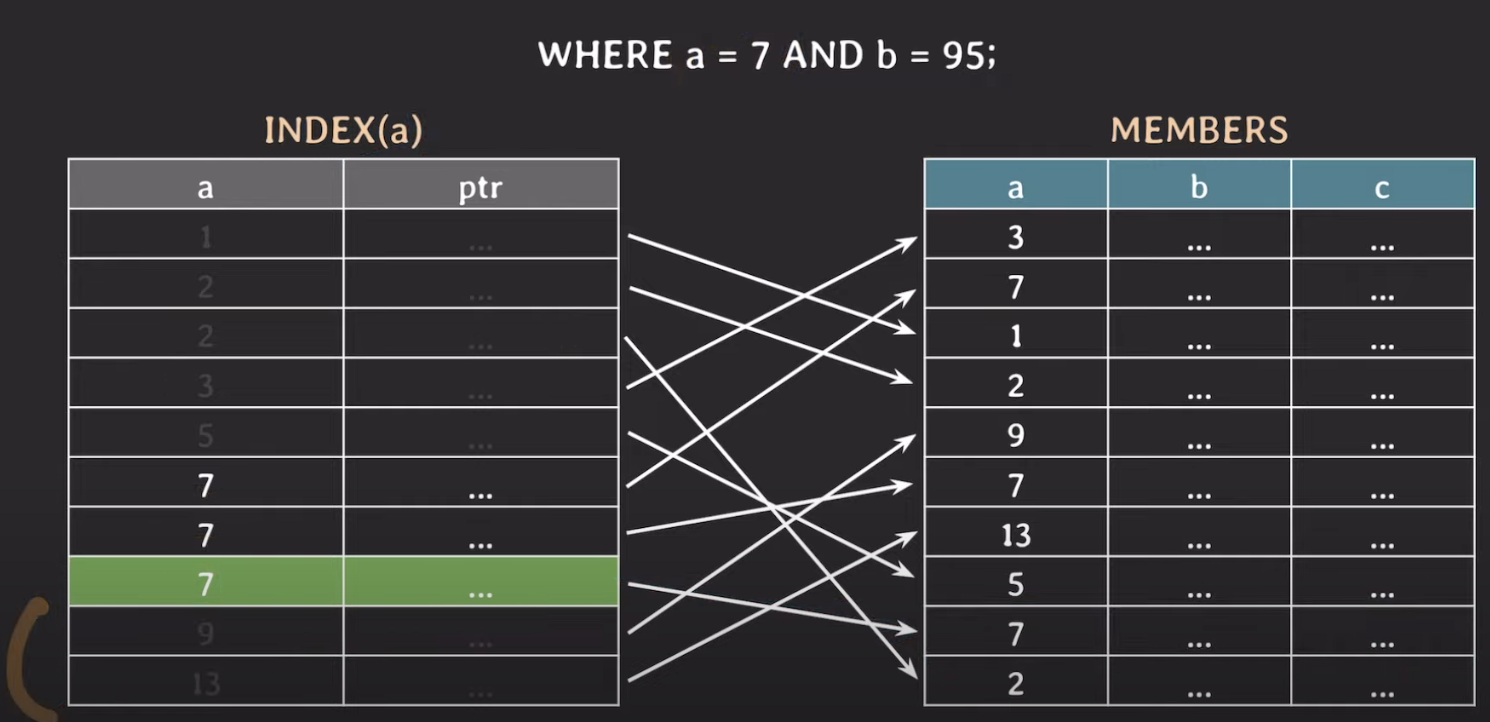
- 마찬가지로 Binary Search를 이용해 값을 찾지만, b라는 값을 찾기 위해서는 a가 7에 해당하는 모든 값을 scan 해야한다. (카디널리티가 낮은 컬럼에 인덱스를 걸면 안되는 이유 중 하나)
CREATE INDEX (a, b)
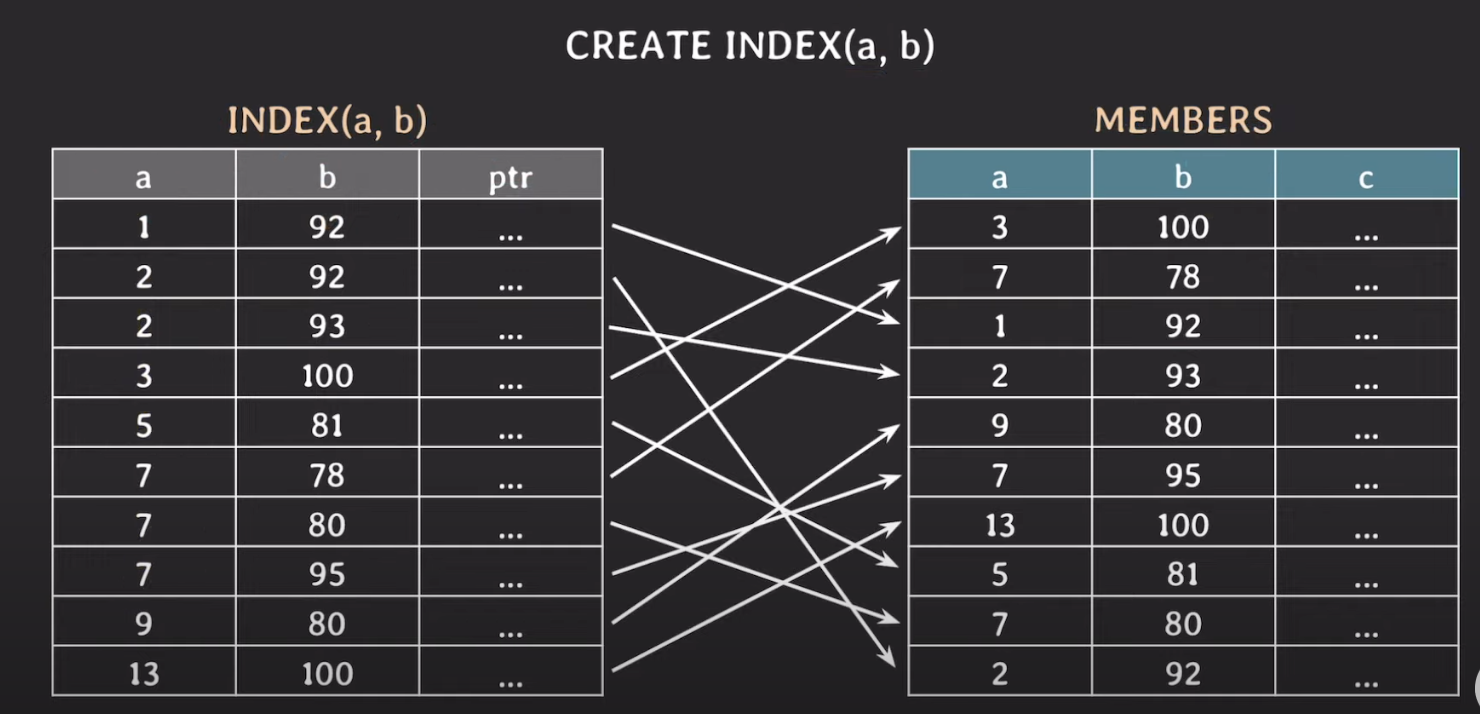
- 위의 상황을 해결하기 위해서는 복합 인덱스를 만들어주면 된다.
- 복합 인덱스는 a를 기준으로 정렬된다.
WHERE a = 7 AND B = 95
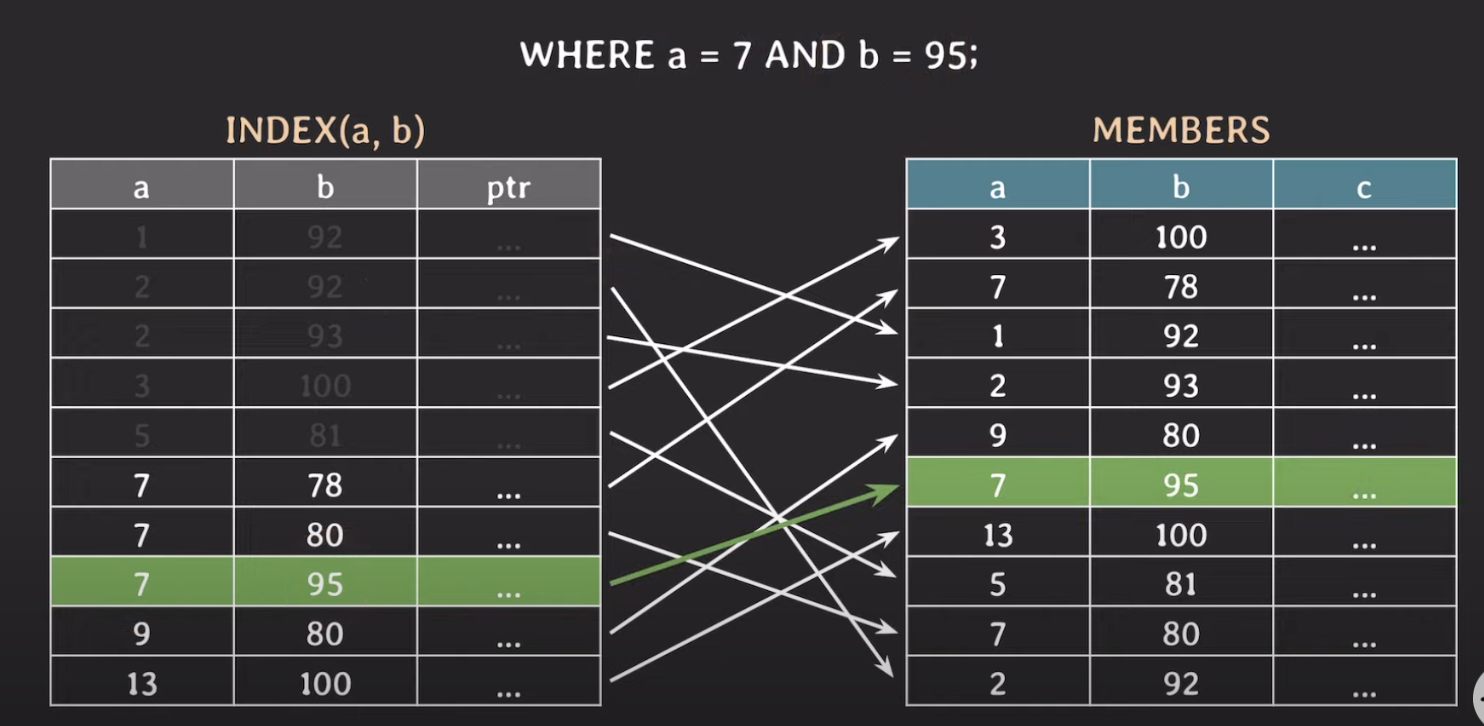
- 먼저 a를 Binary Search를 이용해 값을 찾고, b의 값도 마찬가지로 Binary Search를 이용해 찾는다.
- 복합 인덱스를 만들 경우에는 컬럼의 카디널리티가 높은 순서대로 순서를 정하는 것이 성능에 좋다.
WHERE b = 95
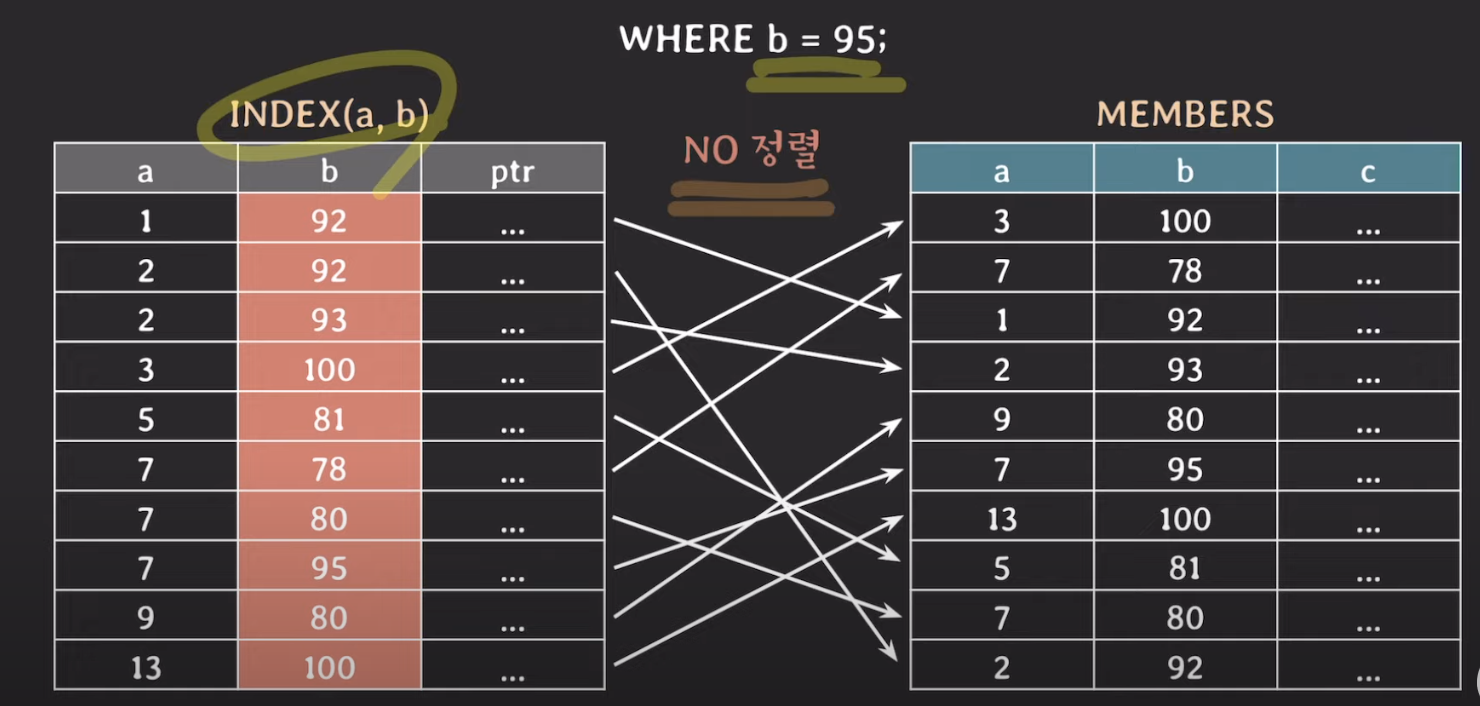
- 복합 인덱스를 사용할 경우 정렬이 되어 있지 않아 옵티마이저가 성능을 쓰지 않거나 쓰더라도 성능이 나오지 않는다.
- 이런 경우에는 b를 단일 인덱스로 만들어서 사용한다.
쿼리가 어떤 인덱스를 사용하는지 알고 싶다면 쿼리 앞에 EXPLAIN 키워드를 붙여보자
B+Tree 기반 인덱스 조회 방식
- 맨 밑에 데이터를 제공하고 위에서는 일종의 가이드 라인 같은 것을 제공한다.
- 범위 스캔에 매우 좋다.
Example (4 ~ 8 범위 스캔)
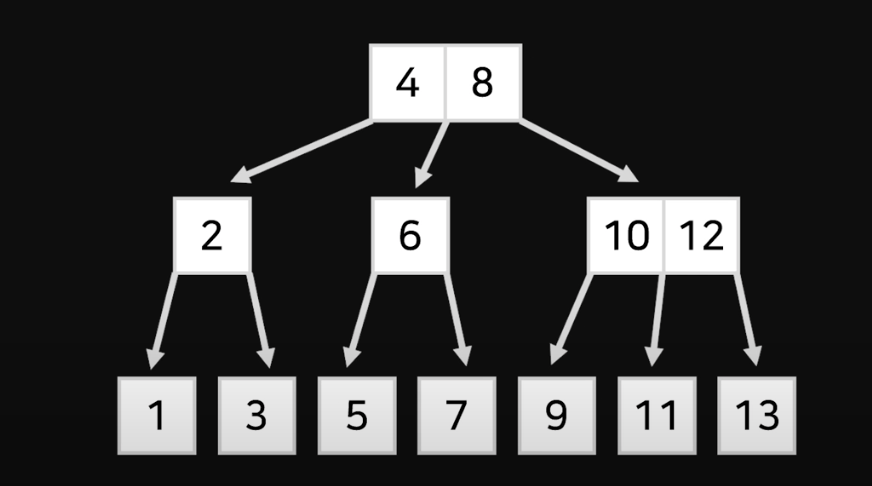
- B-Tree 같은 경우에는 4 ~ 8의 값을 찾기 위해 트리의 노드를 계속 왔다 갔다 할 것이다.
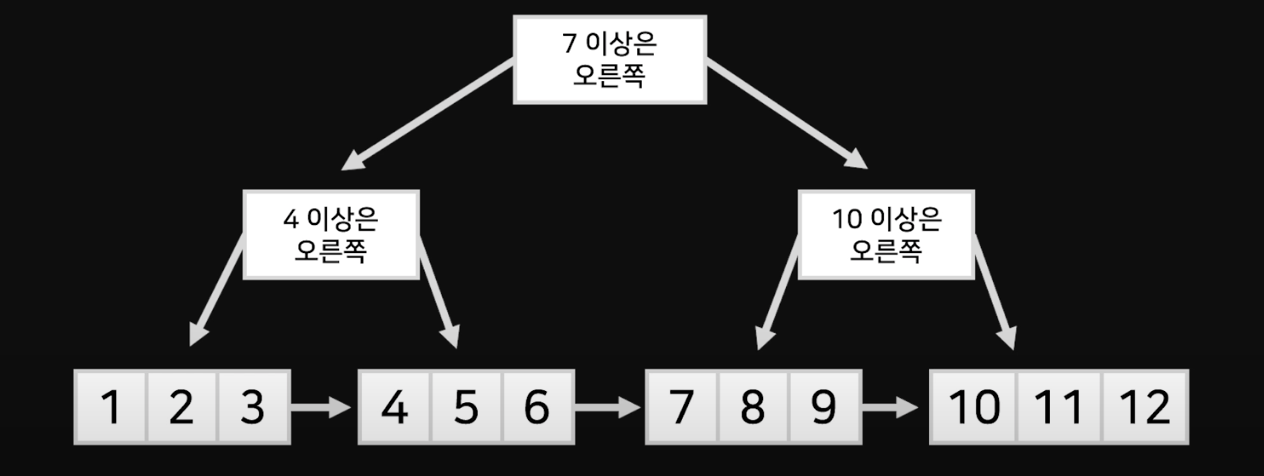
- 반면에 B+Tree는 가이드를 통해 맨 밑으로 가서 4를 찾은 다음 8까지를 스캔하면 된다.
B+Tree를 조금만 더 깊게 알아보자
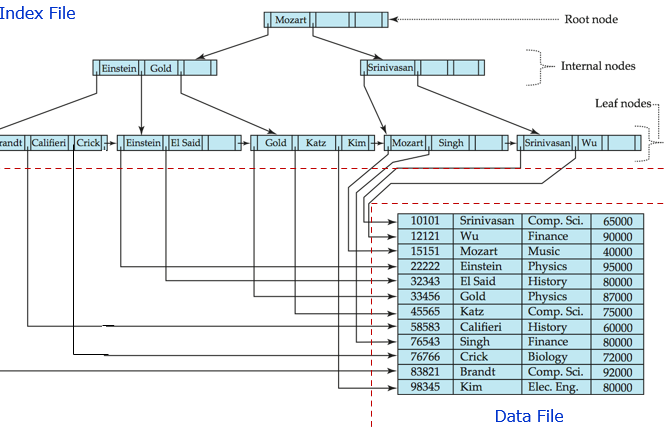
- BST와 비슷하게 동작한다. Root 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽으로 탐색한다.
- 먼저
Root Node는 항상 child node의 포인터를 가지고 있어야 한다. Internal node의 Pointer는 Child node의 위치를 저장한다.- 맨 밑에 있는
Leaf Node의 포인터는 인덱스 값과 table과 맵핑하는 포인터 값을 갖는다. (P1, K1), (P2, K2) ...
Leaf Node의 자료구조

- Ki 는 search key 값
- P1, P2, ... Pn-1은 search key ki 의 포인터 값
- Pn은 search key 순서로 leaf node를 체인화 하는데 사용 (linked List 같음)
그러면 인덱스를 막 만들어도 될까?
- 당연히 안된다. 아래와 같은 이유가 있다.
- table에 값이 write 할 때 마다 index에도 변경이 발생함. 즉 Write, Delete의 오버헤드만 증가하게 될 수도 있다. (DML시 정렬된 구조인 인덱스에도 값이 수정 또는 추가되어야 하므로 DML 속도가 저하됨)
- 옵티마이저가 쿼리의 실행계획을 만들 때, 여러 실행계획중 최적의 실행계획을 찾아야 하지만, 인덱스가 많다면 검토해야 할 실행계획이 너무 많아져 최적화된 실행계획을 찾지 못함
- 또한 디스크에 추가적인 저장 공간을 차지한다.
- 불필요한 인덱스를 만들지 말자
Covering index
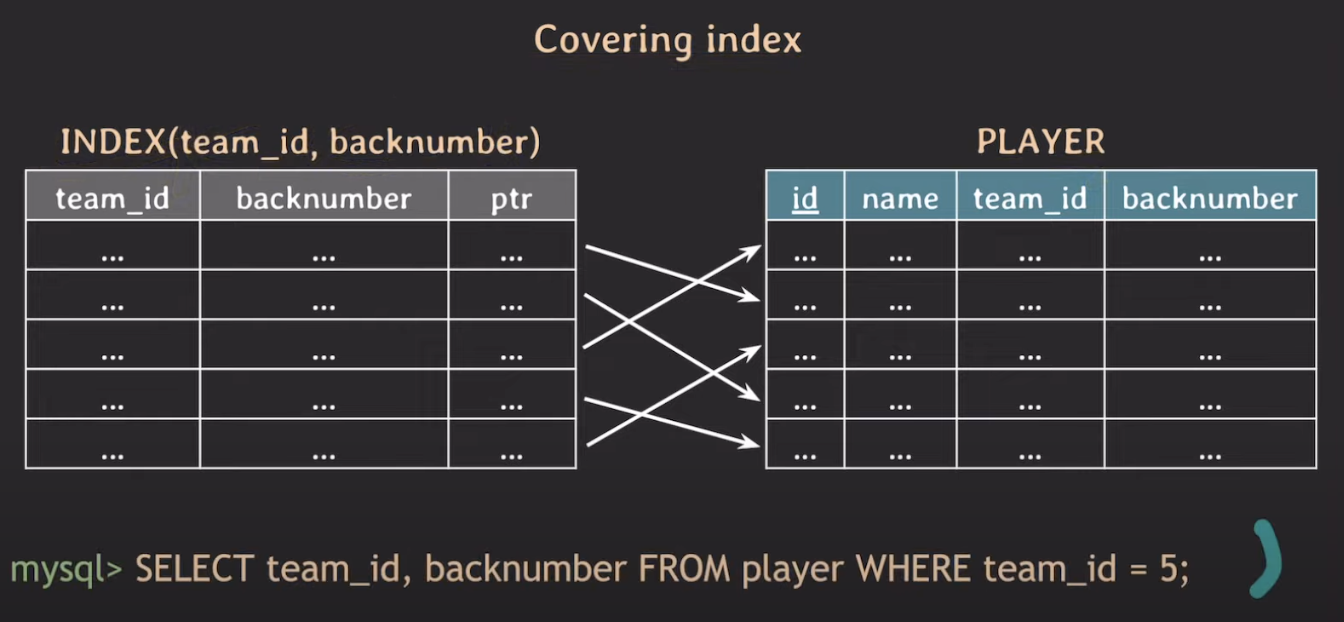
team_id와backnumber는 인덱스 안에 값이 저장되어 있으므로 굳이 TABLE을 Scan할 필요가 없음.- 조회하려는 속성들이 index에서 모두 Cover가 가능할 때 이 인덱스들을 Covering index라고 한다.
- 당연히 조회 성능이 기존 인덱스 방식보다 빠르다.
Full Scan이 더 좋은 경우
- 테이블에 데이터가 조금 있을 때 (몇 십, 몇백건 정도?)
- 조회하려는 데이터가 테이블의 상당 부분을 차지할 때 (데이터의 카디널리티가 너무 낮을 때)
- full scan할지 인덱스를 사용할 지는 옵티마이저가 판단한다.
- 대략적으로 전체 값 중 20% 이하를 검색 할 때 인덱스의 성능이 좋음
분포도(Selectivity)와 인덱스의 관계
- 속성의 분포도를 이용해 어떤 식으로 인덱스를 구현할 수 있을지 판단할 수 있다.
- 분포도가 좋으면 (1에 가까우면) 해당 인덱스를 탈 때 선택되는 rows의 범위가 작으므로 검색 범위가 작아 빠르게 검색이 된다. 즉 잘 구현된 인덱스.
Example (MySQL 기준)
1. 카디널리티 계산
- 먼저 인덱스를 걸고 싶은 속성에 대해 아래와 같이 카디널리티를 계산해준다.
SELECT id, count(*) -- count는 제외해도 상관은 없음--
FROM MEMBER
GROUP BY id- 위의 쿼리의 row의 수가 카디널리티가 된다.
- 복합 인덱스의 경우 SELECT와 GROUP BY에 추가로 속성을 기입해준다.
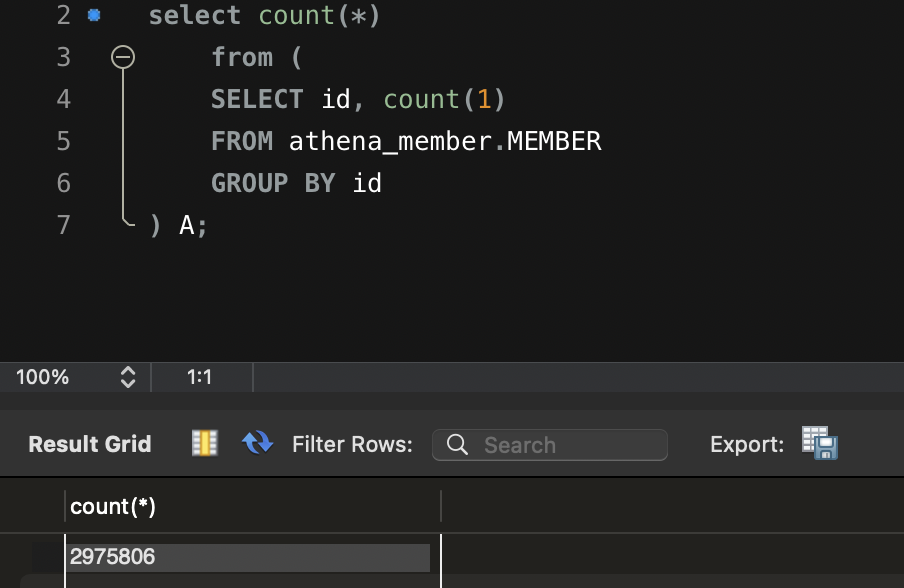
- 위의 쿼리의 카디널리티는 2975806이다.
2. 분포도 계산
분포도 = 카디널리티 / 테이블 전체 row 개수
SELECT count(1)
FROM MEMBER;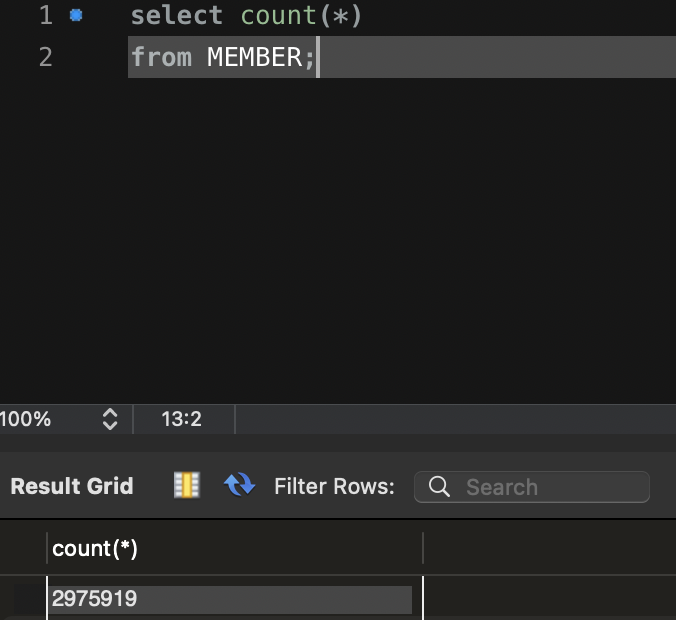
- 위의 쿼리를 실행했을 경우 2975919 rows가 나오고 구한 값들을 위의 식에 대입해보면 2975806/2975919 = 0.99가 나오고 매우 좋은 인덱스 후보다.
번외
SELECT *
FROM 회원정보
WHERE 성별 = '남'
AND 우편번호 = 123123
AND 수신동의여부 = 'Y'
;- 위의 경우 성별 컬럼의 카디널리티는 2으로 매우 낮다. 2/2975919로 계산하면 매우 낮은 분포도가 나오므로 단독으로 인덱스를 생성하면 매우 비효울적이다.
- 이럴 경우 (우편번호', '성별', '수신동의여부')의 카디널리티를 계산하여 분포도를 높여야 한다.
- 복합 인덱스의 최선두 컬럼은 자주 사용하며 분포도가 좋은 컬럼을 선택해야 한다. 위의 경우 우편번호가 가장 유니크한 값이 많으므로 우편번호를 맨 앞에 두었다.
- 대부분 cardinality가 낮은 컬럼 + 다른 컬럼들의 조건으로 쿼리가 들어오므로, 선택도가 1에 가까운 컬럼의 인덱스를 사용하거나 복합 인덱스로 생성하여 카디널리티를 높여야 한다.
Reference

평범한 백엔드 개발자