3.1 마이크로 서비스 아키텍처 IPC 개요
3.1.1 상호 작용 스타일
- 클라이언트/서비스 상호 작용 스타일은 두 가지 기준으로 분리할 수 있다.
- one-to-one/one-to-many 여부
- one-to-one: 각 클라이언트 요청은 정확히 한 서비스가 처리
- one-to-many: 각 클라이언트 요청을 여러 서비스가 협동하여 처리
- synchronous/asynchronous 여부
- synchronous: 클라이언트는 서비스가 제시간에 응답하리라 기대하고 대기 도중 블로킹함
- asynchronous: 클라이언트는 블로킹하지 않고, 응답은 즉시 전송되지 않아도 된다.
- one-to-one/one-to-many 여부

- 일대일 상호 작용 종류:
- request/response: 클라이언트는 서비스에 요청을 하고 응답을 기다린다. 클라이언트는 응답이 제때 도착하리라 기대하고 대기 도중 블로킹할 수 있다. 결과적으로 서비스가 서로 강하게 결합되는 상호 작용 스타일. 또한 IPC 기술에 직교적 (서로 연관성 없이 독립적)인 스타일. 서비스는 REST나 메시징으로 요청/응답하는 다른 서비스와 소통이 가능하다.
- asynchronous request/response: 클라이언트는 서비스에 요청을 하고 서비스는 비동기적으로 응답한다. *클라이언트는 대기 중에 블로킹하지 않고, 서비스는 오랫동안 응답하지 않을 수 있다.
- 일대다 상호 작용 종류
- publish/subscribe: 클라이언트는 알림 메시지를 발행하고, 여기에 있는 0개 이상의 서비스(관심 없는 서비스도 있을 수 있음)가 메시지를 소비한다.
- publish/asynchronous subscribe: 클라이언트는 요청 메시지를 발행하고 주어진 시간 동안 관련 서비스가 응답하길 기다린다.
3.1.2 마이크로서비스 API 정의
- 애플리케이션은 여러 모듈로 구성되며, 각 모듈마다 자신의 클라이언트가 호출하는 작업이 정의된 인터페이스가 존재한다. 잘 설계된 인터페이스는 유용한 기능은 표출하되 그 구현체는 감추어져 있기 때문에 클라이언트에 영향을 미치지 않고 코드를 고칠 수 있다.
- 마이크로서비스에서의 API는 모놀리틱과 다르게 클라이언트와 함께 컴파일 되지 않는다. 만약에 클라이언트가 서비스가 호환되지 않는 API에 맞물려 배포되어도 컴파일 에러는 안 나고 런타임 에러가 발생한다.
- 어떤 IPC를 선택하든, 서비스 API를 IDL(Interface Definition Language, 인터페이스 정의 언어)로 명확하게 정의해야 한다. 인터페이스 명세서를 작성한 후 클라이언트 개발자와 함께 의논하는 과정을 몇 차례 되풀이하면서 API를 정의한 후 서비스를 구현해야 한다. -> 선 설계 후 구현 방식
3.1.3 API 발전시키기
- API는 새 기능을 추가하거나 기존 기능을 변경/삭제하는 과정을 거치며 계속 변한다. 마이크로서비스 어플리케이션은 모놀리틱과는 다르게 서비스 API를 변경하기가 어렵다. 서비스를 사용하는 클라이언트를 모두 찾아 강제로 변경할 수도 없다.
- 이러한 문제를 해결하려면 전략을 잘 세워야 한다. API를 변경하는 방법도 어떤 성격의 변경인지에 따라 달라진다.
시맨틱 버저닝
- 시맨틱 버저닝 명세 (Semantic Versioning Specification)은 API 버저닝에 관한 유용한 지침서 여기에는 버전 번호를 사용하고 증가시키는 규칙들이 명시되어 있다.
- 원래 소프트웨어 패키지의 버저닝 용도로 쓰였으나, 분산 시스템의 API 버저닝에도 사용할 수 있다.
- 이 명세에 따르면 버전 번호를 MAJOR, MINOR, PATCH 새 파트로 구성하고 다음 규칙에 따라 각각 증가시킨다.
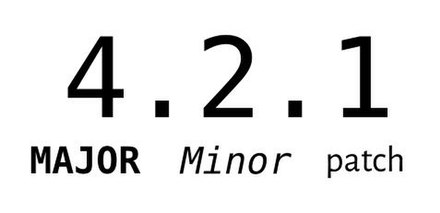
- MAJOR: 하위 호환되지 않는 변경분을 API에 적용 시
- MINOR: 하위 호환되는 변경분을 API에 적용 시
- PATCH: 하위 호환되는 오류 수정 시
- REST API라면 메이저 버전을 URL 경로의 첫 번째 엘리먼트로 쓸 수 있고, 메시징 기반의 서비스라면 이 서비스가 발행한 메시지에 버전 정보를 넣을 수 있다. 어쩄든 API를 올바르게 버저닝해서 일정한 규칙에 맞게 발전시키는 것이 중요하다.
하위 호환되는 소규모 변경
- 변경을 하더라도 가급적 하위 호환성을 보장하는 방향으로 해야 한다. 보통 API에 추가하는 변경은 대부분 하위 호환된다.
- 옵션 속성을 요청에 추가
- 속성을 응답에 추가
- 새 작업을 추가
- 이런 종류의 변경은 새 서비스에 적용해도 기존 클라이언트 역시 별 문제없이 동작한다. 다만 Robustness Principe을 지켜야 한다.
Robustness Principe
- '견고함 원칙'이라고 불리기도 하는 포스텔의 법칙이란 서비스는 자기가 만들어내는 것에는 보수적이어야 하지만 다른 서비스로부터 받는 것에는 관대해야 함을 의미한다. 어떤 서비스가 외부에서 받은 데이터의 일부만 사용한다고 하더라도, 나머지 데이터를 지금 사용할 필요가 없다고 해서 거부하거나 배제해서는 안된다.
- 실제로, 포스텔의 법칙 (견고함 원칙)은 정밀하고 구체적으로 명시된 부품들로 시스템을 구축한다는 관행과 완전히 어긋난다. 포스텔의 법칙을 따르려면, 우리는 각 부품을 특정한 응용에 꼭 필요한 것보다 더 일반적으로 적용할 수 있게 만들어야 한다.
중대한 대규모 변경
- 경우에 따라서는 기존 버전과 호환이 안되는 변경을 API에 적용해야 할 때가 있다. 클라이언트를 강제로 업그레이드 하는 것은 불가하므로 일정 기간 동안 서비스는 신구버전 API를 모두 지원해야 한다. HTTP 기반의 REST API라면 URL에 메이저 버전 번호를 삽입할 수 있다. (예 버전 1 경로는 앞에 v1, 버전 2 경로는 v2를 붙임)
- HTTP 컨텐츠 협상 (content negotiation)을 이용해서 MINE 타입 내부에 버전 정보를 끼워 넣는 방법도 있다. 가령 버전 1.X의 주문은 아래와 같이 요청할 수 있다.
GET /orders/xyz HTTP 1.1
Accept: application/vnd.example.resource+json; version=1- 클라이언트가 버전 1.X 응답을 기대한다고 주문 서비스에 지시한 것이다.
- 여러 버전의 API를 지원하려면 API가 구현된 서비스 어댑터에 신구 버전을 올바르게 중계하는 로직이 있어야 한다. API 게이트웨이는 거의 반드시 버저닝된 API를 사용하며, 심지어는 구 버전 API도 여러 버전을 지원해야 하는 경우도 있다.
3.1.4 메시지 포맷
- IPC 핵심은 메시지 교환이다. 대부분의 메시지는 데이터를 담고 있기 때문에 데이터 포맷은 중요한 설계 결정 항목이다. 또 IPC 효율, API 사용성, 발전성에도 영향을 미친다.
- 메시지 포맷은 크게 텍스트와 이진 포맷으로 분류된다.
텍스트 메시지 포맷
- JSON, XML 등 텍스트 기반 포맷은 사람이 읽을 수 있고 self describing한 장점이 있다.
- JSON 메시지는 네임드 프로퍼티, XML 메시지는 네임드 엘리먼트와 그 값을 모아놓은 구조.
- 메시지 컨슈머는 자신이 관심 있는 값만 골라 쓰고 나머지는 그냥 무시하면 되므로 메시지 스키마가 자주 바뀌어도 하위 호환성은 쉽게 보장된다.
- 단점은 메시지가 길다는 것. 모든 메시지에 속성값 이외에 속성명이 추가되는 오버헤드가 있고, 큰 메시지는 파싱할 때 들어가는 오버헤드도 존재한다.
이진 메시지 포맷
- 효율/성능이 중요한 경우에는 이 메시지 포맷 방식을 고려할 만 하다
- 프로토콜 버퍼와 아브로가 유명하고, 두 포맷은 메시지 구조 정의에 필요한 타입 IDL을 제공하며, 컴파일러는 메시지를 직렬화/역직렬화하는 코드를 생성한다. 즉 서비스를 API 우선 접근 방식으로 설계할 수 없다. 또한 정적 타입 언어로 클라이언트를 작성할 경우, 클라이언트가 API를 올바르게 사용하는지 컴파일러로 확인할 수 있다.
- 하지만 아브로 컨슈머는 스키마를 알고 있어야 메시지를 해석할 수 있기 때문에 API 발전 측면에서는 프로토콜 버퍼가 더 용이하다.
3.2 동기 RPI 패턴 응용 통신
- 원격 프로시져 호출 (Remote Procedure Call): 클라이언트는 REST 같은 동기식 RPI 프로토콜로 서비스를 호출한다.
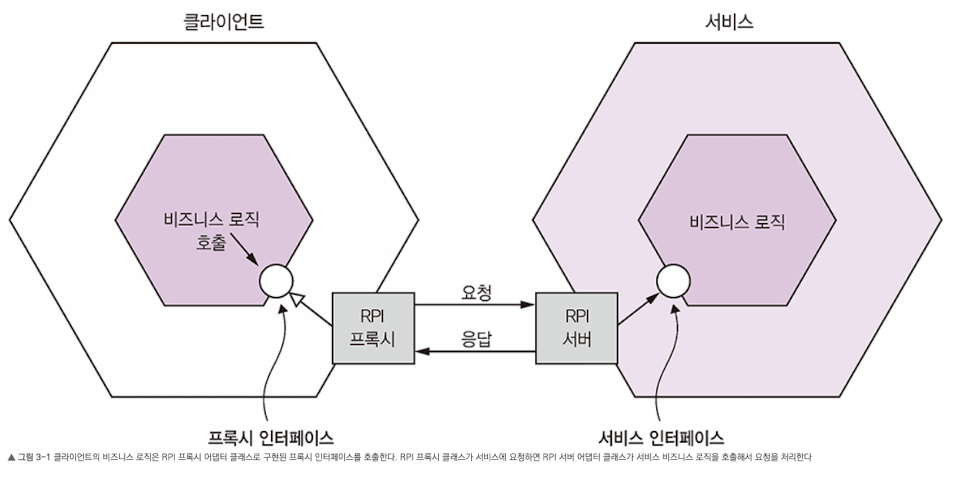
3.2.1 동기 RPI 패턴
- REST: HTTP로 소통하는 IPC.
- REST는 컴포넌트 상호 작용의 확장성, 인터페이스의 일반화, 컴포넌트의 독립적 배포, 상호 작용 지연을 줄이기 위해 중간 컴포넌트 보안 강화, 레거시 시스템의 캡슐화에 역점을 둔 아키텍처 제약 조건 세트를 제공한다.
- 리소스는 REST의 핵심 개념. Customer나 Product 같은 비즈니스 객체를 의미
- REST는 HTTP 동사를 사용해서 URL로 참조되는 리소스를 가공(조작)한다.
- 예를 들어 주문 서비스에서 POST /orders는 Order를 생성하는 엔드포인트, orders/{orderId}는 Order를 조회하는 엔드포인트이 된다.
REST 성숙도 모델
- 레벨 0: 클라이언트는 서비스별로 유일한 URL 끝점에 HTTP POST 요청을 하여 서비스를 호출한다. 요청을 할 때마다 어떤 액션을 수행할지, 그 대상(예: 비즈니스 객체)은 무엇인지 지정하고, 필요한 매개변수도 함께 전달한다.
- 레벨 1: 서비스는 리소스 개념을 지원하고 클라이언트는 수행할 액션과 매개변수가 지정된 POST 요청을 한다.
- 레벨 2: 서비스는 HTTP 동사를 이용해서 액션을 수행하고(예: GET은 조회, POST는 생성, PUT은 수정), 요청 쿼리 매개변수 및 본문, 필요 시 매개변수를 지정한다. 덕분에 서비스는 GET 요청을 캐싱하는 등 웹 인프라를 활용할 수 있다.
- 레벨 3: 서비스를 HATEOAS(Hypertext As The Engine Of Application State, 애플리케이션 상태 엔진으로서의 하이퍼미디어) 원칙에 기반하여 설계한다. HATEOAS는 GET 요청으로 반환된 리소스 표현형에 그 리소스에 대한 액션의 링크도 함께 태워 보내자는 생각. 가령 클라이언트는 GET 요청으로 주문 데이터를 조회하고 이때 반환된 표현형 내부 링크를 이용해서 해당 주문을 취소할 수도 있다. HATEOAS를 사용하면 하드 코딩한 URL을 클라이언트 코드에 욱여넣지 않아도 된다.
Swagger
- REST API의 IDL로서 가장 유명한 오픈 API 명세
- 스웨거는 REST API를 개발/문서화하는 도구 세트. 인터페이스 정의를 기반으로 클라이언트 스텁, 서버 스켈레톤을 생성하는 툴이 포함되어 있다.
요청 한 번으로 많은 리소스를 가져오기 어렵다.
- 특정 주문과 구매자를 REST로 조회하는 클라이언트가 있다고 가정하자. 순수 REST API라면 클라이언트는 적어도 2회 요청을 해야 한다. 시나리오가 복잡해지면 왕복 횟수가 증가하고 지연 시간이 급증함.
- 이 문제를 해결하는 방법은 클라이언트가 리소스를 획득할 때 연관도니 리소스도 함께 조회하도록 API를 설계하는 것이다. 예를 들어
GET / orders/order-id-1345?expand=consumer처럼 쿼리 매개변수로 주문과 함께 반환된 연관 리소스를 지정하면 주문, 판매자를 한꺼번에 조회할 수 있다. 그러나 시나리오가 복잡해지면 효율이 떨어지고 구현 시간이 많이 소요된다. 이러한 문제 때문에 데이터를 효율적으로 조회할 수 있게 설계된 GraphQL이나 넷플릭스 팔코 등 대체 API 기술이 각광받기 시작했다.
작업을 http 동사에 매핑하기 어렵다.
- REST는 데이터를 수정할 때 대게 PUT을 사용하지만, 주문 데이터만 하더라도 이 데이터를 업데이트하는 경로는 주문 취소/변경 등 다양할 수 있다.
- 또한 PUT 사용 시 필수조건인 멱등성이 보장되지 않는 업데이트도 존재한다.
- 해결 방법은 리소스의 특정 부위를 업데이트하는 하위 리소스를 정의하는 것이다. 주문 서비스에 주문 취소 엔드포인트
POST /orders/{orderId}/cancel와 주문 변경 엔드포인트POST /orders/{orderId}/revise와 를 작성한다.
REST의 장단점
Pron
- 단순하고 익숙하다.
- Postman 같은 브라우저 플러그인이나 curl 등의 CLI 도구를 사용해서 HTTP API를 간편하게 테스트 ㅏㄹ 수 있다.
- request / response 스타일의 통신을 직접 지원
- HTTP는 방화벽 친화적이다.
- 중간 브로커가 필요하지 않기 때문에 시스템 아키텍처가 단순해진다.
Cons
- request / response 스타일만 지원
- 가용성이 떨어짐. 중간에서 메시지를 버퍼링하는 매개자 없이 클라이언트/서비스가 직접 통신하기 때문에 메시지를 교환하려면 양쪽 다 실행 중이어야 한다.
- 서비스 인스턴스의 위치 (EndPoint URL)을 클라이언트가 알고 있어야 한다. 요즘 애플리케이션은 서비스 디스커버리 메커니즘을 이용해 클라이언트가 서비스 인스턴스의 위치를 찾을 수 있으므로 큰 단점은 아니다.
- 요청 한 번으로 여러 리소스를 가져오기 어렵다.
- 다중 업데이트 작업을 HTTP 동사에 매핑하기 어려울 때가 있다.
3.2 동기 RPI 패턴: gRPC
- HTTP는 한정된 동사만 지원하기 때문에 다양한 업데이트 작업을 지원하는 REST API를 설계하기 쉽지 않다. 그래서 등장한 기술이 gRPC다.
gRPC 특징
- gRPC는 다양한 언어로 클라이언트/서버를 작성할 수 있는 프레임워크.
- 이진 메시지 기반의 프로토콜이므로 서비스를 API 우선 방식으로 설계할 수 밖에 없다.
- gRPC API는 프로토콜 버퍼 (구조화 데이터를 직렬화하는 구글의 언어 중립적 메커니즘) 기반의 IDL로 정의하며, 프로토콜 버퍼 컴파일러로 클라이언트 쪽 스텁 및 서버 쪽 스켈레톤을 생성할 수 있다. 이 컴파일러를 이용하면 자바, C#, Node, Go 등 다양한 언어의 코드를 생성할 수 있다. 클라이언트/서버는 프로토콜 버퍼 포맷의 이진 메시지를 HTTP/2를 통해 교환한다.
- gRPC API는 하나 이상의 서비스와 Request/Response 메시지 데피니션로 구성된다. 단순 Request/Response는 물론 스트리밍 RPC도 지원하므로 서버가 클라이언트에 메시지 스트림을 응답하는 것도 가능하다. 반대로 클라이언트가 서버로 메시지 스트림을 보낼수도 있다.
// 예제 3-1. 주문 서비스의 gRPC API
service OrderService{
rpc createOrder(CreateOrderRequest) returns (CreateOrderReply) {}
rpc cancelOrder(CancelOrderRequest) returns (CancelOrderReply) {}
...
}
message CreateOrderRequest {
int64 restaurantId = 1;
int64 consumerId = 2;
repeated LineItem lineItems = 3;
...
}
message LineItem{
string menuItemId = 1;
int32 quantity = 2;
}
message CreateOrderReply{
int64 = orderId = 1;
}
CreateOrderRequest,CreateOrderReply는 타입이 정해진 메시지.- 이 메시지 안에 타입과 아이디가 지정되어 있음.
gRPC의 장단점
Pron
- 다양한 업데이트 작업이 포함된 API를 설계하기 쉽다.
- 큰 메시지를 교환할 때 콤팩트하고 효율적임.
- 양방향 스트리밍 덕분에 RPI, 메시징 두 가지 통신 방식 모두 가능
- 다양한 언어로 작성된 클라이언트/서버 간 연동 가능
Cons
- 자바스크립트 클라이언트가 하는 일이 REST/JSON 기반 API보다 더 많다.
- 구형 방화벽은 HTTP/2를 지원하지 않는다.
gRPC는 REST를 대체할 유력한 방안이나, 동기 통신하는 메커니즘은 여전해 부분 실패 문제는 여전히 존재한다.
2.3.2 부분 실패 처리: 회로 차단기 패턴 (Circuit Breaker)
- 회로 차단기 패턴 (Circuit Breaker Pattern): 연속 실패 횟수가 주어진 임계치를 초과하면 일정 시간 동안 호출을 즉시 거부하는 RPI 프록시
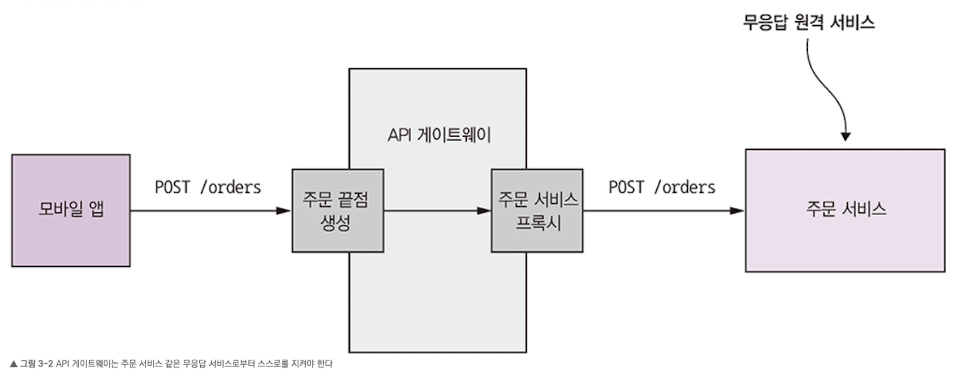
- API 클라이언트가 애플리케이션에 진입하는 관문인 API 게이트웨이에 모바일 클라이언트가 REST 요청을 하지만 API 게이트웨이가 요청을 위임한 주문 서비스는 묵묵부답인 상태다.
OrderServiceProxy를 곧이 곧대로 구현하면 응답을 무한정 블로킹 할 것이다. UX 측면에서도 좋지 않고, 스레드 같은 주요 리소스가 고갈되어 결국 API 게이트웨이가 요청을 처리할 수 없다. -> 즉 부분 실패가 애플리케이션 전체에 전파되지 않도록 서비스를 설계해야 한다.- 무응답 원격 서비스를 처리하기 위해
OrderServiceProxy같은 견고한 RPI 프록시를 설계한다. - 원격 서비스가 실패하면 어떻게 조치해야 할지 결정한다.
- 무응답 원격 서비스를 처리하기 위해
견고한 RPI 프록시 설계
- 넷플릭스 기술 블로그를 보면 서비스가 다른 서비스를 동기 호출할 때 자기 스스로를 방어하는 방법이 기술되어 있다.
- 네트워크 타임아웃: 응답 대기 중에 무한정 블로킹하면 안 되고 항상 타임아웃을 걸어둔다.
- 미처리 요청 개수 제한: 클라이언트가 특정 서비스에 요청 가능한 미처리 요청의 최대 개수를 설정한다. 이 개수에 이르면 더 이상의 요청은 무의미하므로 즉시 실패 처리하는 것이 좋다.
- 회로 차단기 패턴: 성공/실패 요청 개수를 지켜보다가 에러율이 주어진 임계치를 초과하면 그 이후 시도는 바로 실패 처리한다. 실패된 요청이 많다는 것은 서비스가 불능 상태고 더 이상의 요청은 무의미하다는 것을 의미. 타임아웃 시간 이후 클라이언트가 재시도해서 성공하면 서킷 브레이커는 닫힌다.
- 넷플릭스 히스트릭스는 이와 같이 다양한 패턴이 구현된 오픈 소스 라이브러리다. JVM 환경이라면 히스트릭스를 이용하여 RPI 프록시를 구현해 볼 만 하다.
불능 서비스 복구
- 히스트릭스 같은 라이브러리는 부분적인 솔루션. 무응답 원격 서비스를 어떻게 복구하면 좋을지는 그때그때 상황에 맞게 판단해야 한다.
- 위의 그림에서처럼 주문 생성 요청이 실패하는 상황에서는 그냥 알기 쉽게 서비스가 클라이언트에 에러를 반환하는 것이 낫다.
- 부분 실패 시 미리 정해진 기본 값이나 캐시된 응답 값 등 대체 값 (feedback value)를 반환하는 방법도 있다.
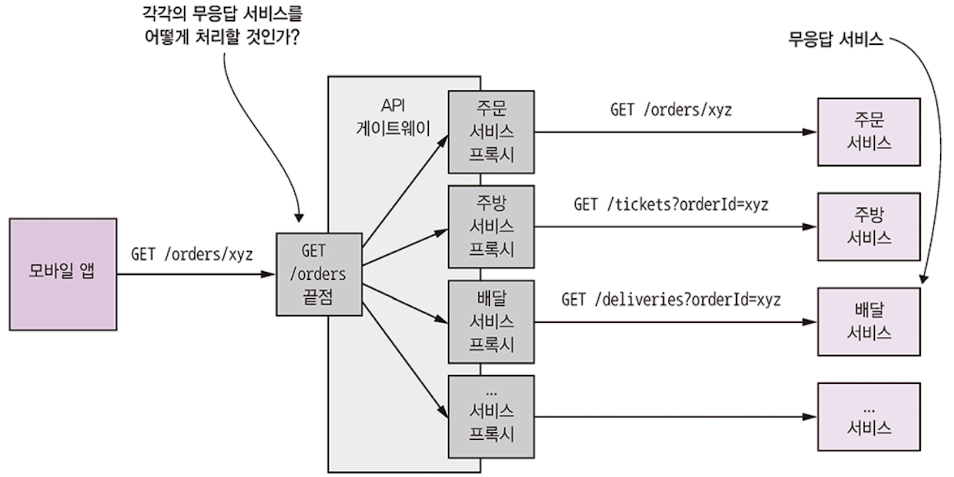
- 모든 서비스의 데이터가 클라이언트에 똑같이 중요하지는 않다. 주문 데이터가 가장 중요하다. 서비스가 불능 상태가 되더라도 다른 서비스 데이터는 상대적으로 덜 중요하기 때문에 API 게이트웨이는 캐시된 버전의 데이터 또는 에러를 반환한다.
- 예를 들어 배달 서비스가 불능 상태일 경우, API 게이트웨이가 캐시된 버전의 데이터를 반환하거나 아예 해당 데이터를 응답에서 제거해도 클라이언트는 유용한 정보를 사용자에게 표시할 수 있다.
3.2.4 서비스 디스커버리
- REST API가 있는 어떤 서비스를 호출하는 코드를 개발한다고 할 때, 이 서비스를 호출하는 코드는 서비스 인스턴스의 IP 주소와 포트번호를 알고 있어야 요청을 한다. 물리적인 서버를 기반으로 실행되는 기존 애플리케이션은 서비스 인스턴스의 네트워크가 대부분 정적이다. 하지만 요즘은 클라우드 기반의 마이크로서비스 애플리케이션은 네트워크 위치가 훨씬 동적이라서 이를 식별하는 것이 쉽지 않다.
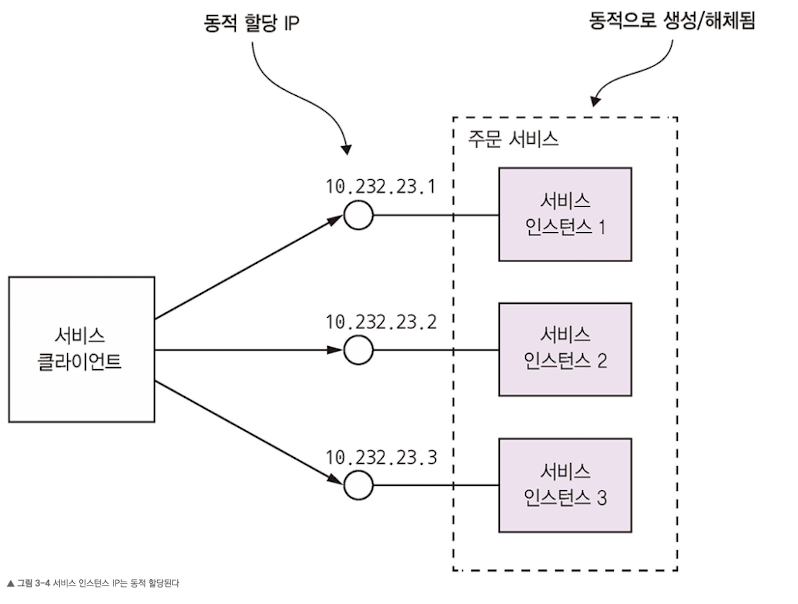
서비스 디스커버리 개요
- 핵심은 애플리케이션 서비스 인스턴스의 네트워크 위치를 DB화한 서비스 레지스트리다. 인스턴스가 시작/종료할 떄 마다 서비스 레지스트리가 업데이트된다. 클라이언트가 서비스를 호출하면 우선 서비스 디스커버리가 서비스 레지스트리에서 가용 서비스 인스턴스 목록을 가져오고, 그중 한 서비스로 요청을 라우팅한다.
- 서비스 디스커버리는 주로 두 가지 방법로 구현한다.
- 클라이언트/서비스가 직접 서비스 레지스트리와 상호 작용한다.
- 배포 인프라로 서비스 디스커버리를 처리한다. (12장에 자세히 다룬다.)
애플리케이션 수준의 서비스 디스커버리 패턴 적용
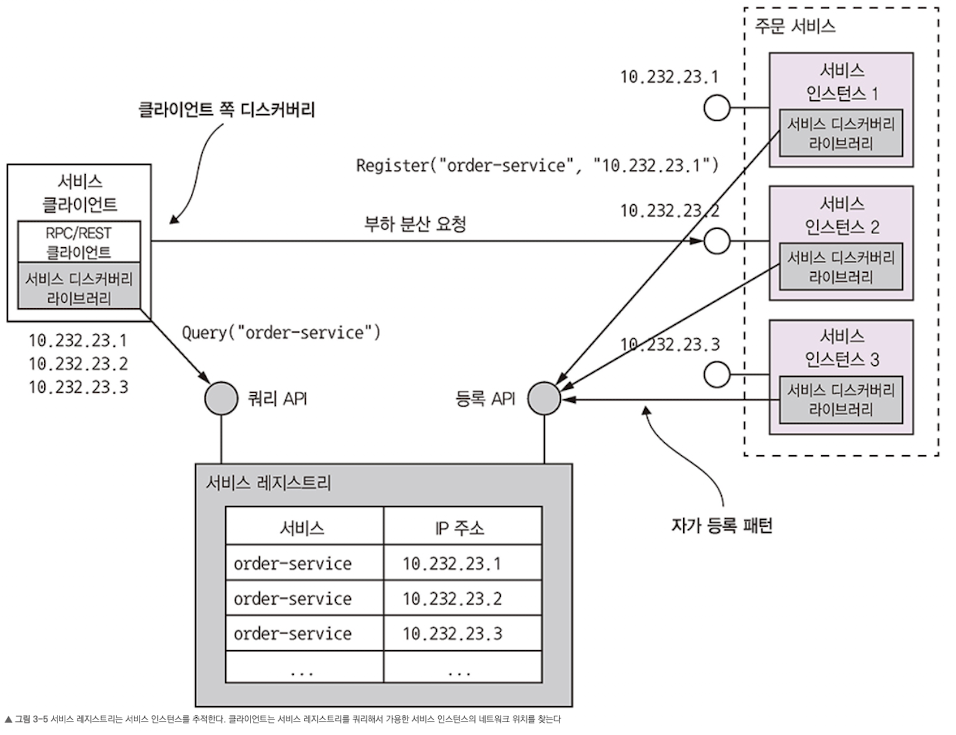
- 애플리케이션 클라이언트/서비스가 서비스 레지스트리와 직접 통신하는 방법 서비스 인스턴스는 자신의 네트워크 위치를 서비스 레지스트리에 등록하고, 서비스 클라이언트는 이 서비스 레지스트리로부터 전체 서비스 인스턴스 목록을 가져와 그중 한 인스턴스로 요청을 라우팅한다.
- 위의 그림은 두 가지 패턴을 조합한 방식이다.
- 자가 등록 (self registration) 패턴: 서비스 인스턴스는 서비스 레지스트리에 자기 자신을 등록한다.
- 서비스 인스턴스는 자신의 네트워크 위치를 서비스 레지스트리 등록 API를 호출해서 등록한다. 또한 헬스 체크를 제공하는 서비스도 있다. 서비스 인스턴스가 현재 건강한지, 요청을 순조롭게 처리할 수 있는 상태인지 서비스 레지스트리가 주기적으로 확인하기 위해 필요한 API Endpoint. 서비스 인스턴스가 자신이 전에 등록한 네트워크 위치가 만료되지 않도록 하트비트 API를 호출해야 하는 서비스 API도 존재한다.
- 클라이언트 쪽 디스커버리 패턴: 서비스 클라이언트는 서비스 레지스트리에 있는 가용 서비스 인스턴스 목록을 조회하고 부하 분산한다.
- 클라이언트는 서비스를 호출할 때 먼저 서비스 레지스트리에 서비스 인스턴스 목록을 요청해서 넘겨받는다. (이 목록을 캐시하면 성능을 높일 수 있다). 그 다음 서비스 클라이언트는 라운드 로빈이나 랜덤 같은 부하 분산 알고리즘을 이용해 서비스 인스턴스를 선택한 후 요청을 전송한다.
- 자가 등록 (self registration) 패턴: 서비스 인스턴스는 서비스 레지스트리에 자기 자신을 등록한다.
- 애플리케이션 수준의 디스커버리는 넷플릭스와 피보탈 덕분에 대중화 되었다.
- 넷플릭스는 유레카라는 고가용성 서비스 레지스트리, 유레카 자바 클라이언트, 리본 등 여러가지 컴포넌트를 개발하고 오픈 소스화 했다. 또한 피보탈은 이 넷플릭스 컴포넌트를 아주 쉽게 사용할 수 있게 스프링 클라우드라는 스프링 기반의 프레임워크를 개발했다.
플랫폼에 내장된 서비스 디스커버리 패턴 적용
- 도커나 k8s 등 최신 배포 플랫폼에는 대부분 서비스 레지스트리, 서비스 디스커버리 메커니즘이 탑재되어 있다.
- 배포 플랫폼은 DNS명, 가상 IP, VIP 주소로 해석되는 DNS명을 각 서비스마다 부여한다. 서비스 클라이언트가 DNS명/VIP를 요청하면 배포 플랫폼이 알아서 가용 서비스 인스턴스 중 하나로 요청을 라우팅 한다. -> 배포 플랫폼이 서비스 등록, 서비스 디스커버리, 요청 라우팅을 전부 관장하는 것이다.
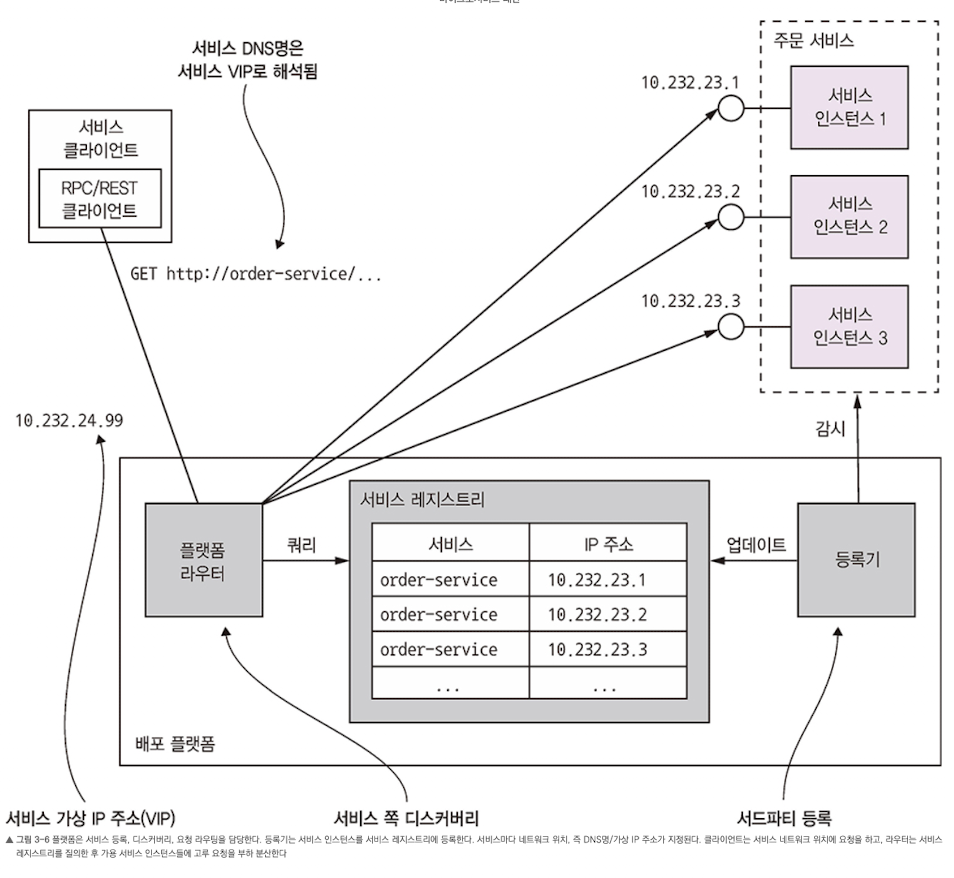
- 이 방식도 두 패턴을 접목시켰다.
- 서드파티 등록 패턴: 서드파티가 서비스 인스턴스를 서비스 레지스트리에 자동 등록
- 서비스가 자신을 서비스 레지스트리에 등록하는 것이 아니라, 배포 플랫폼의 일부인 등록기(Registrar)라는 서드파티가 이 작업을 대행한다.
- 서버 쪽 디스커버리 패턴: 클라이언트가 서비스 디스커버리를 담당한 라우터에 요청
- 클라이언트가 서비스 레지스트리를 쿼리하지 않고 DNS명을 요청한다. 그러면 서비스 레지스트리를 쿼리하고 요청을 부하 분산하는 요청 라우터로 해석된다.
- 서드파티 등록 패턴: 서드파티가 서비스 인스턴스를 서비스 레지스트리에 자동 등록
- 플랫폼에서 제공되는 서비스 디스커버리를 사용하면 서비스 개발 언어와 상관 없이 모든 클라이언트/서비스에 곧바로 적용할 수 있으나. 해당 플랫폼으로 배포한 서비스 디스커버리만 지원되는 단점도 존재한다. 가령 쿠버네티스에 기반한 디스커버리는 오직 쿠버네티스로 배포한 서비스에서만 적용된다. 이런 단점도 있지만 플랫폼에서 제공되는 서비스 디스커버리를 사용하는 것이 권장된다.
3.3 비동기 메시징 패턴 응용 통신
- 메시징: 클라이언트는 비동기 메시징을 통해 서비스를 호출한다.
3.3.1 메시징 개요
메시지
- 메시지는 헤더와 바디로 구성된다. 헤더에는 송신된 데이터에 관한 메타데이터에 해당하는 키/값들로 구성된다. 메시지 바디는 실제로 송신할 텍스트 또는 이진 포맷 데이터다.
- 문서 (document): 데이터만 포함된 제네릭한 메시지 (예: 커맨드에 대한 응답). 메시지를 어떻게 해석할지는 수신자가 결정한다.
- 커맨드 (command): RPC 요청과 동등한 메세지. 호출할 작업과 전달할 매개변수가 지정되어 있다.
- 이벤트 (event): 송신자에게 어떤 사건이 발생했음을 알리는 메시지. 이벤트는 대부분
Order,Customer같은 도메인 객체의 상태 변화를 나타내는 도메인 이벤트다.
메시지 채널
- 메시지는 채널을 통해 교환된다.
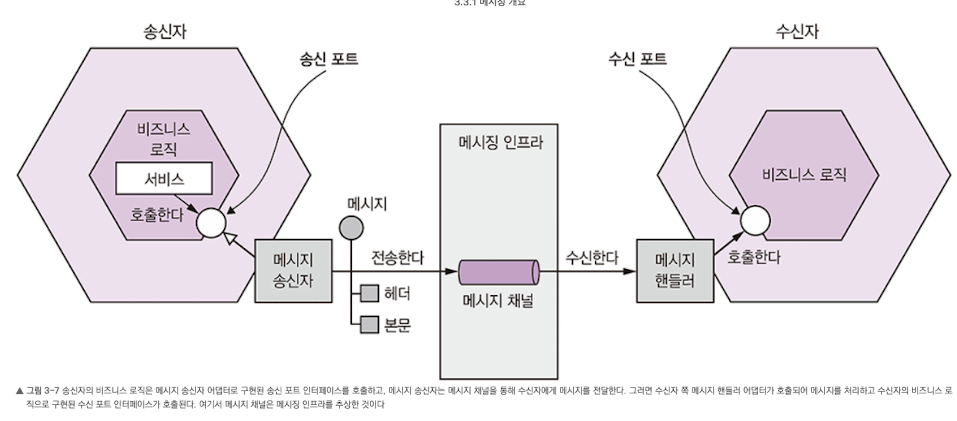
- 채널은 두 종류가 있다.
- point-to-point 채널: 채널을 읽는 컨슈머 중 딱 하나만 지정하여 메시지를 전달한다. 앞서 설명한 일대일 상호 작용 스타일의 서비스가 이 채널을 사용한다. (예: 커맨드 메시지)
- publish-subscribe 채널: 같은 채널을 바라보는 모든 컨슈머에 메시지를 전달한다. 앞서 설명한 일대다 상호 작용 스타일의 서비스가 이 채널을 사용한다. (예: 이벤트 메시지)
3.3.2 메시징 상호 작용 스타일 구현
요청/응답 및 비동기 요청/응답
- 클라이언트/서비스는 한 쌍의 메시지를 주고받는 비동기 요청/응답 스타일로 상호 작용한다. 클라이언트는 수행할 작업과 매개변수가 담긴 커맨드 메시지를 서비스가 소유한 point-to-point 메시징 채널에 보낸다. 메시징은 원래 비동기적이라 비동기 요청/응답만 제공하지만 응답을 수신할 때 까지 클라이언트를 블로킹할 수도 있다.
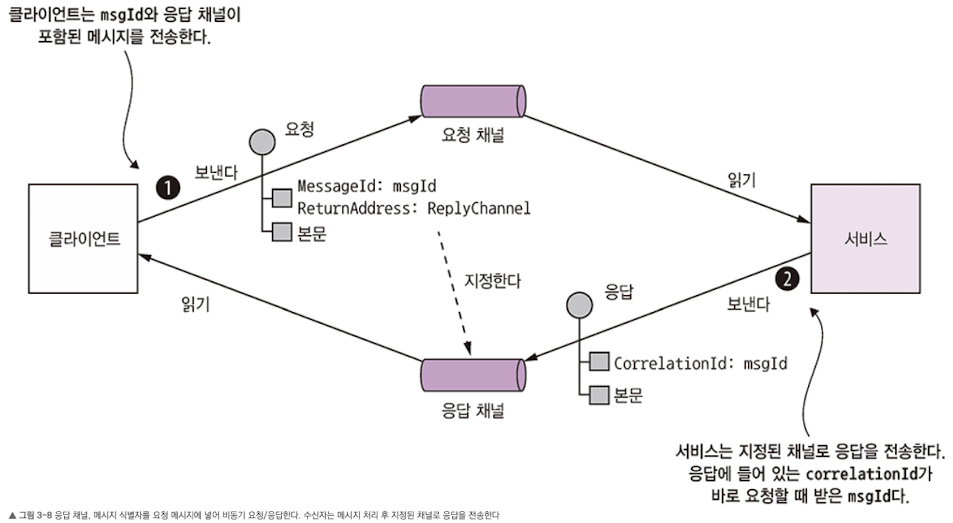
- 클라이언트는 수행할 작업과 매개변수가 담긴 커맨드 메시지를 서비스가 소유한 point-to-point 메시징 채널에 보낸다. 그러면 서비스는 요청을 처리한 후 그 결과가 담긴 응답 메시지를 클라이언트가 소유한 point-to-point 채널로 돌려보낸다.
- 클라이언트는 서비스가 어디로 응답 메시지를 보내야 하는지 알려주고 이렇게 받은 응답 메시지는 요청과 짝이 맞아야 한다.
- 클라이언트는 MessageId 및 응답 채널이 헤더에 명시된 커맨드 메시지를 보내고, 서버는 MessageId와 값이 동일한 CorrelationId가 포함된 응답 메시지를 지정된 응답 채널에 쓰면 된다. 클라이언트는 이 CorrelationId를 이용하여 응답 메시지와 요청을 맞춰볼 수 있다.
단방향 알림
- 단방향 알림 (One-way notification)은 비동기 메시징을 이용하여 직관적으로 구현할 수 있다. 서비스가 소유한 point-to-point 채널로 클라이언트가 메시지 (커맨드 메시지)를 보내면, 서비스는 이 채널을 구독해서 메시지를 처리하는 구조다. 단방향이므로 서비스는 응답을 보내지 않는다.
발행/구독
- 클라이언트는 여러 컨슈머가 읽는 발행/구독 채널에 메시지를 발행하고, 서비스는 도메인 객체의 변경 사실을 알리는 도메인 이벤트를 발행해야 한다.
- 도메인 이벤트를 발행한 서비스는 해당 도메인 클래스의 이름을 딴 발행/구독 채널을 소유한다.
- 주문 서비스는 Order 이벤트를 Order 채널에 발행하고, 배달 서비스는 Delivery 이벤트를 Delivery 채널에 발행한다.
- 서비스는 자신이 관심 있는 도메인 객체의 이벤트 채널을 구독한다.
발행/비동기 응답
- 클라이언트는 응답 채널 헤더가 명시된 메시지를 발행/구독 채널에 발행하고, 컨슈머는 CorrelationId가 포함된 응답 메시지를 지정된 응답 채널에 쓴다. 클라이언트는 이 CorrelationId로 응답을 취합하여 응답 메시지와 요청을 맞춰본다.
3.3.3 메시징 기반 서비스의 API 명세 작성
- 서비스의 비동기 API 명세에는 메시지 채널명, 각 채널을 통해 교환되는 메시지 타입과 포맷을 명시하고, 메시지 포맷은 JSON, XML, 프로토콜 버퍼 등 표준 포맷으로 기술해야 한다.
- 그러나 채널 및 메시지 타입은 딱히 정해진 문서화 표준이 없어 자유롭게 적으면 된다.
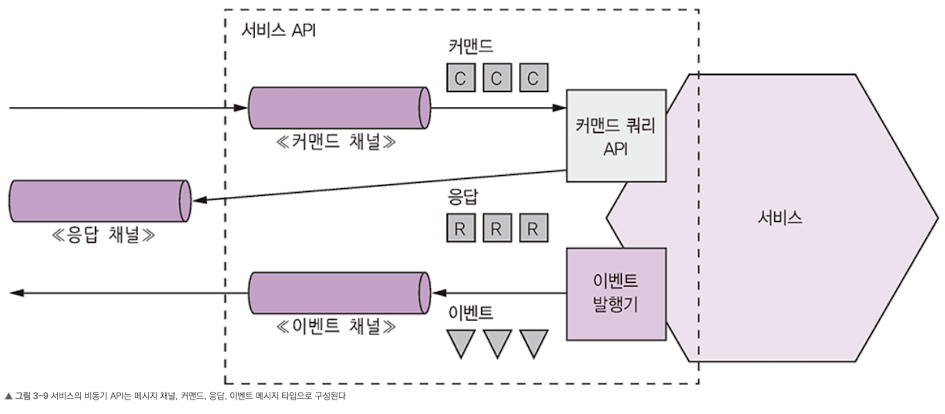
비동기 작업 문서화
- 서비스 작업은 두 가지 상호 작용 스타일 중 하나로 호출할 수 있다.
- 요청/비동기 응답 스타일 API: 서비스의 커맨드 메시지 채널, 서비스가 받는 커맨드 메시지의 타입과 포맷, 서비스가 반환하는 응답 메시지의 타입과 포맷으로 구성된다.
- 단방향 알림 스타일 API: 서비스의 커맨드 메시지 채널, 서비스가 받는 커맨드 메시지의 타입과 포맷으로 구성된다.
발행 이벤트 문서화
- 서비스는 Pub/Sub 스타일로도 이벤트를 발행할 수 있다. 이러한 스타일의 API 명세는 이벤트 채널, 서비스가 채널에 발행하는 이벤트 메시지의 타입과 포맷으로 구성된다.
3.3.4 메시지 브로커
- 메시지 브로커는 서비스가 서로 통신할 수 있게 해주는 인프라 서비스이다. 서비스가 서로 직접 통신하는 브로커리스 기반의 메시징 아키텍처도 있으나 일반적으로 브로커 기반의 아키텍처가 더 낫다.
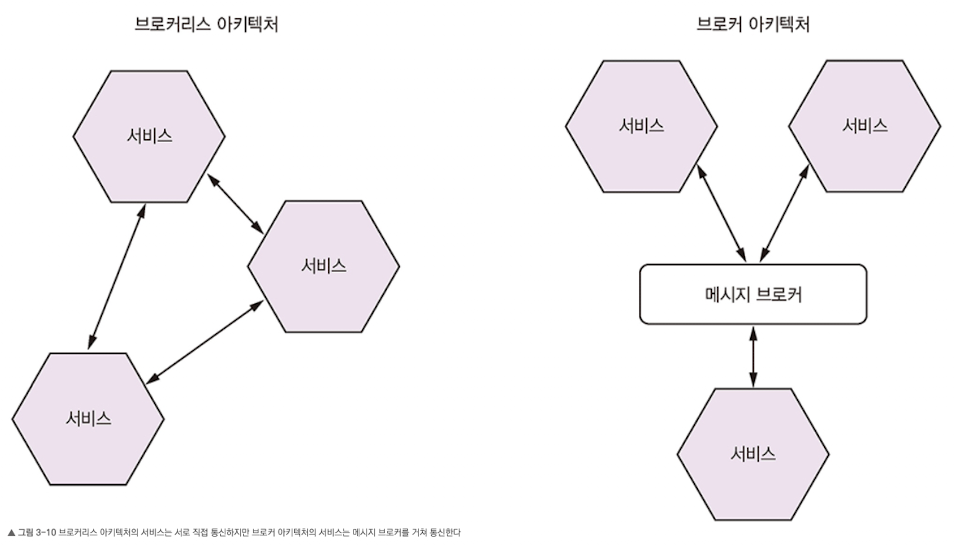
브로커리스 메시징
- 브로커리스 아키텍처의 서비스는 메시지를 서로 직접 교환한다.
Pron and Cons
- 장점
- 송신자가 보낸 메시지가 브로커를 거쳐 수신자로 이동하는 것이 아니라, 송신자에서 수신자로 직접 전달므로 네트워크 트래픽이 가볍고 지연 시간이 짧다.
- 메시지 브로커가 성능 병목점이나 Sing Point Of Failure가 될 일이 없다.
- 메시지 브로커를 설정/관리할 필요가 없으므로 운영 복잡도가 낮다.
- 단점
- 서비스가 서로의 위치를 알고 있어야 하므로 서비스 디스커버리 메커니즘 중 하나를 사용해야 한다.
- 메시지 교환 시 송신자/수신자 모두 실행중이여야 하므로 가용성이 떨어진다.
- 전달 보장같은 메커니즘을 구현하기가 어렵다.
브로커 기반 메시징 개요
- 메시지 브로커는 모든 메시지가 지나가는 중간 지점. 송신자가 메시지 브로커에 메시지를 쓰면 브로커는 메시지를 수신자에게 전달한다.
- 가장 큰 장점은 송신자가 컨슈머의 네트워크 위치를 몰라도 된다는 것이다. 또 컨슈머가 메시지를 처리할 수 있을 때 까지 메시지 브로커에 메시지를 버퍼링 할 수도 있다.
- RabbigMQ, Apache Kafka가 대표적인 오픈소스
- 메시지 브로커를 선택할 때에는 다음 항목을 잘 검토해야 한다.
- 프로그래밍 언어 지원 여부: 다양한 프로그래밍 언어를 지원할 수록 좋다
- 메시징 표준 지원 여부: AMOP나 STOMP 등 표준 프로토콜을 지원하는 제품인가, 아니면 자체 표준만 지원하는 제품인가?
- 메시지 순서: 메시지 순서가 유지되는가?
- 전달 보장: 어떤 종류의 전달 보장을 하는가?
- 영속화: 브로커가 고장 나도 문제가 없도록 메시지를 디스크에 저장하는가?
- 내구성: 컨슈머가 메시지 브로커에 다시 접속할 경우, 접속이 중단된 시간에 전달된 메시지를 받을 수 있나?
- 확장성: 얼마나 확장성이 좋은가?
- 지연 시간: 종단 간 지연 시간은 얼마나 되나?
- 경쟁사 컨슈머: 경쟁사의 컨슈머를 지원하는가?
- 브로커마다 다 장단점이 존재한다. 지연 시간이 매우 짧은 브로커는 메시지 순서가 유지되지 않거나 메시지 전달이 보장되지 않는다든지, 아니면 메시지를 메모리에만 저장한다든지 하는 단점이 존재한다. 반대로 메시지 전달을 보장하고 메시지를 디스크에 확실히 저장하는 브로커는 지연 시간이 긴 편이다. 하지만 어느 브로커든 메시징 순서 유지 및 확장성은 필수 조건이다.
메시지 브로커로 메시지 채널 구현

브로커 기반 메시징의 장단점
- Pron
- 느슨한 결합: 클라이언트는 적절한 채널에 그냥 메시지를 보내는 식으로 요청한다. 클라이언트는 서비스 인스턴스를 몰라도 되므로 서비스 인스턴스의 위치를 알려주는 디스커버리 메커니즘도 필요 없다.
- 메시지 버퍼링: 메시지 브로커는 처리 가능한 시점까지 메시지를 버퍼링한다. 덕분에 온라인 상점에서 주문 이행 시스템이 느려지거나 불능 상태에 빠지는 사고가 발생해도 컨슈머는 주문을 계속 접수할 수 있다.
- 유연한 통신: 메시징은 지금까지 설명한 모든 상호 작용 스타일을 지원한다.
- 명시적 IPC: RPC 메커니즘은 원격 서비스가 마치 자신이 로컬 서비스인 양 호출은 시도한다.
- Cons
- 성능 병목 가능성: 메시지 브로커가 성능 병목점이 될 위험이 있으나, 요즘 메시지 브로커는 대부분 확장이 잘 되도록 설계되어있다.
- 단일 장애점 가능성: 메시지 브로커는 가용성이 높아야 한다. 그렇지 않으면 시스템의 신뢰성에 흠이 갈 수 있다. 다행히 요즘 브로커는 대부분 고가용성이 보장되도록 설계되어 있다.
- 운영 복잡도 부가: 메시징 시스템 역시 설치 구성, 운영해야 할 시스템 컴포넌트다.
3.3.5 수신자 경합과 메시지 순서 유지
- 메시지 순서를 유지한 채 메시지 수신자를 Scale Out 할 수 있을까? 일반적으로 메시지를 동시 처리하려면 서비스 인스턴스를 여러 두어야 한다. 물론 단인 서비스 인스턴스라도 스레드를 이용하면 여러 메시지를 동시 처리할 수 있지만, 다수의 스레드와 서비스 인스턴스를 동원하면 애플리케이션 처리율이 증가한다. 그런데 이렇게 메시지를 동시 처리하면 각 메시지를 정확히 한 번만 순서대로 처리해야 한다.
- 예를 들어 동일한 point-to-point 채널을 읽는 서비스 인스턴스가 3개 있고, 송신자는 주문 생성됨, 주문 변경됨, 주문 취소됨 이벤트 메시지를 차례로 전송한다고 하자. 단순하게 메시지를 종류별로 정해 정해진 수신자에게 동시 전달하면 될 것 같지만, 갖가지 네트워크 이슈나 가비지 컬렉션 문제로 지연이 발생하고 메시지 처리 순서가 어긋나면 시스템이 오동작할 수 있다. 다른 서비스가 주문 생성됨 메시지를 처리하기 전에 주문 취소됨 메시지를 처리하는 현상이 일어날 수 있다.
- 그래서 요즘 메시지 브로커는 샤딩된 채널을 이용한다.
- 샤딩된 채널은 복수의 샤드로 구성되며, 각 샤드는 채널처럼 작동한다.
- 송신자는 메시지 헤더에 샤드 키 (보통 무작위 문자열 또는 바이트)를 지정한다. 메시지 브로커는 메시지를 샤드 키 별로 샤드/파티션에 배정한다. 예를 들어 샤드 키 해시 값을 샤드 개수로 나눈 나머지를 계산해서 샤드를 선택하는 식.
- 메시징 브로커는 여러 컨슈머 인스턴스를 묶어 마치 동일한 논리 수신자처럼 취급. (카프카 용어로 컨슈머 그룹). 메시지 브로커는 각 샤드를 하나의 컨슈머에 배정하고, 컨슈머가 시동/종료하면 샤드를 재배정한다.
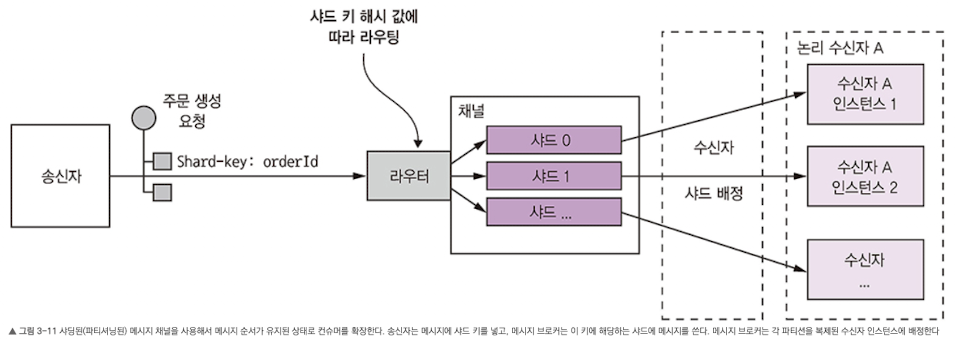
- orderId가 각 주문 이벤트 메시지의 샤드 키가 된다. 주문별 이벤트는 각각 동일한 샤드에 발행되고, 어느 한 컨슈머 인스턴스만 메시지를 읽기 때문에 메시지 처리 순서가 보장된다.
3.3.6 중복 메시지 처리
- 보통 메시지 브로커는 적어도 한 번 이상 메시지를 전달함
- 시스템이 정상일 때 적어도 한 번 전달을 보장하는 메시지 브로커는 각 메시지를 한 번만 전달한다. 그러나 클라이언트나 네트워크 또는 브로커 자신이 실패할 경우, 같은 메시지를 여러 번 전달할 수도 있다. 메시지 처리 후 DB 업데이트까지 마쳤는데, 메시지를 ACK하기 전에 클라이언트가 갑자기 멎었다고 가정해보자. 클라이언트가 재시동되면 메시지 브로커는 ACK 안된 메시지를 다시 보내거나 다른 클라이언트 레플리카에 전송할 것이다.
- 메시지 브로커가 메시지를 재전송할 때 원래 순서까지 유지하는 것이 이상적이다.
- 클라이언트가 주문 생성됨 이벤트 -> 주문 취소됨 이벤트 순서로 처리하는데, 뭔가 문제가 발생해서 '주문 생성됨' ACK를 못 받았을 때, 메시지 브로커가 주문 생성됨 이벤트만 재전송하면 클라이언트가 주문 취소를 언두할 가능성이 있기 때문에 주 생성됨, 주문 취소됨 두 이벤트를 모두 재전송해야 한다.
- 중복 메시지를 처리하는 두 가지 방법
- 멱등한 메시지 핸들러를 작성
- 메시지를 추척해서 중복을 솎아 내기
멱등한 메시지 핸들러 작성
- 애플리케이션의 메시지 처리 로직을 멱등하게 구현한다. 가령 이미 취소된 주문을 다시 취소하는 작업이나 클라이언트가 전달한 ID로 주문을 생성하는 작업도 멱등하다.
- 그러나 이렇게 멱등한 애플리케이션 로직은 실제로 별로 없음. 메시지를 다시 전송하면 순서를 보장하지 않는 메시지 브로커를 사용 중일수도 있다. 중복 메시지와 순서가 안 맞는 메시지는 오류를 일으키기 때문에 중복 메시지를 솎아 내는 메시지 핸들러가 필요하다.
메시지 추척과 중복 메시지 솎아 내기
- 구매자 신용카드를 승인하는 메시지 핸들러가 있다고 해보자. 정확히 1회를 승인해야 한다. 이런 종류의 애플리케이션 로직은 호출될 때마다 영향을 미치므로 중복 메시지 때문에 같은 로직이 여러 번 실행되면 문제가 심각해진다. 반드시 메시지 핸들러가 중복 메시지를 걸러 내서 멱등하게 동작하도록 만들어야 한다.
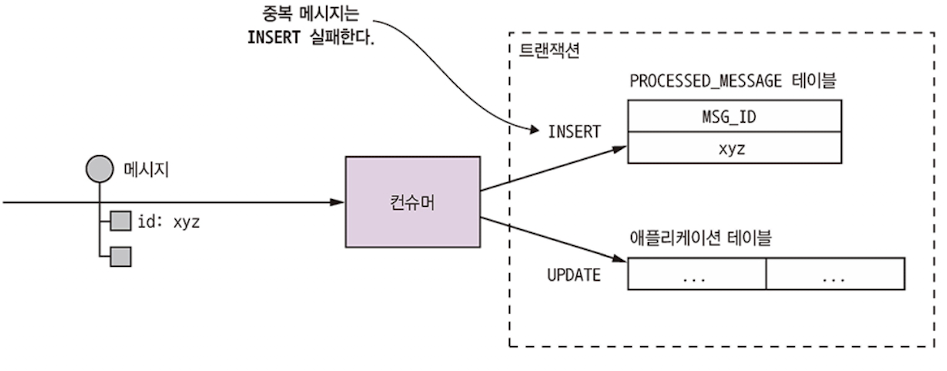
3.3.7 트랜잭셔널 메시징
- DB 업데이트와 메시지 전송을 한 트랜잭션으로 묶기 위해 (원자적으로 묶기 위해) 트랜잭셔널 아웃박스 패턴을 적용한다
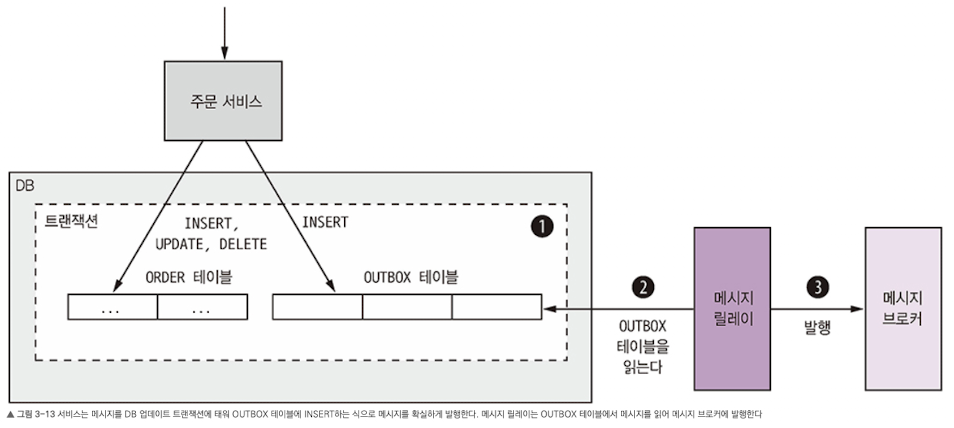
- 메시지를 보내는 서비스에 OUTBOX라는 DB 테이블을 만들고, 비즈니스 객체를 생성, 수정, 삭제하는 DB 트랜잭션의 일부로 OUTBOX 테이블에 메시지를 삽입한다. 로컬 ACID 트랜잭션이기 때문에 원자성은 자동 보당된다.
- OUTBOX 테이블은 임시 메시지 큐 역할을 한다. 메시지 릴레이는 OUTBOX 테이블을 읽어 메시지 브로커에 메시지를 발행하는 컴포넌트다. NoSQL DB도 방법은 비슷하다.
- 메시지를 DB에서 메시지 브로커로 옮기는 방법은 두 가지가 존재한다.
이벤트 발행: 폴링 발행기 패턴
- 폴링 발행기 패턴: DB에 있는 아웃박스를 폴링해서 메시지를 발행한다.
- 메시지 릴레이로 테이블을 폴링해서 미발행 메시지를 조회하는 것이다. 아래의 쿼리를 주기적으로 실행하면 된다.
SELET * FROM OUTBOX ORDER BY ... ASC- 메시지 릴레이는 이렇게 조회한 메시지를 하나씩 각자의 목적지 채널로 보내 메시지 브로커에 발행한다. 이후 OUTBOX 테이블에서 메시지를 삭제한다
BEGIN
DELETE FROM OUTBOX WHERE ID in (...)
COMMIT이벤트 발행: 트랜잭션 로그 테일링 패턴
- 트랜잭션 로그 테일링: 트랜잭션 로그를 테일링하여 DB에 반영된 변경분을 발행한다.
- 메시지 릴레이로 DB 트랜잭션 로그(커밋 로그)를 테일링하는 방법이다. 애플리케이션에서 커밋도니 업데이트는 각 DB 트랜잭션 로그 엔트리 (log entry)로 남는다. 트랜잭션 로그 마이너 (transaction log miner)로 트랜잭션 로그를 읽어 변경분을 하나씩 메시지로 메시지 브로커에 발행하는 것이다.
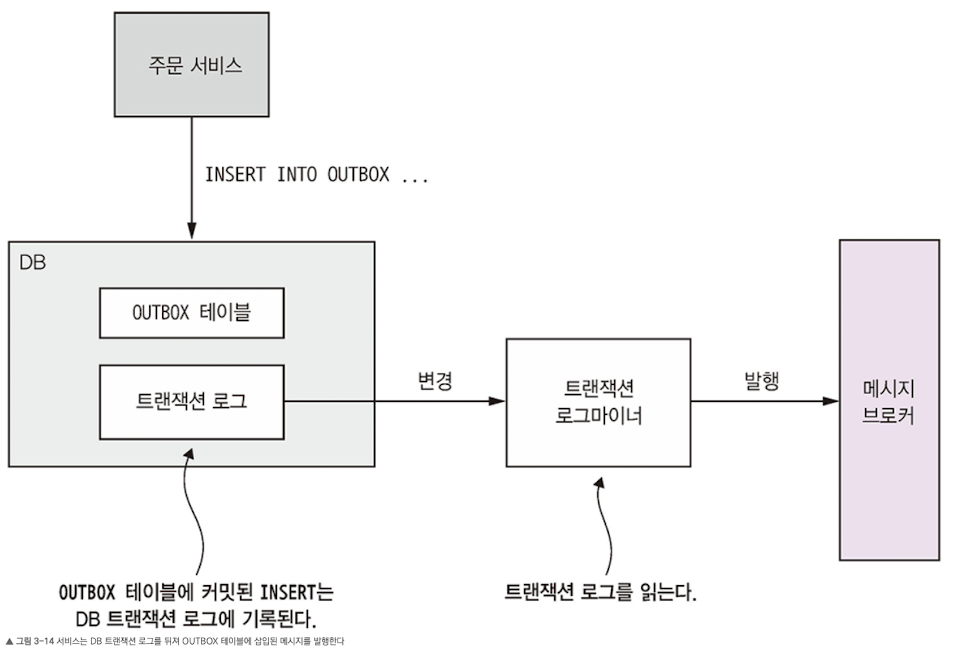
- 트랜잭션 로그 마이너는 트랜잭션 로그 항목을 읽고, 삽입된 메시지에 대응되는 각 로그 항목을 메시지로 전환하여 메시지 브로커에 발행한다. RDBMS의 OUTBOX 테이블에 출력된 메시지 또는 NoSQL DB 레코드로 추가된 메시지를 이런 식으로 발행할 수 있다.
- 이 방식을 이용한 프레임워크는 Debezium, LinkedIn Databux, DynamoDB Streams 등이 존재한다.
3.3.8 메시징 라이브러리/프레임워크
- 서비스와 메시지를 주고받으려면 라이브러리가 필요하다. 메시지 브로커에도 클라이언트 라이브러리가 있지만 직접 사용하면 아래와 같은 문제가 존재한다.
- 메시지 브로커 API에 메시지를 발행하는 비즈니스 로직이 클라이언트 라이브러리와 결합된다.
- 메시지 브로커의 클라이언트 라이브러리는 대부분 저수준이고 메시지를 주고 받는 코드가 꽤 긴편이다. 보일러플레이트 코드를 계속 복붙하고 싶은 개발자는 없다.
- 메시지 브로커의 클라이언트 라이브러리는 기본적인 메시지 소통 수단일 뿐, 고수준의 상호 작용 스타일은 지원하지 않는다.
- 따라서 저수준의 코드를 감추고 고수준의 상호 작용 스타일을 직접 지원하는 고수준 라이브러리 또는 프레임워크가 필요하다. 이 책에서는 저자가 개발한 이벤추에이트 트램 프레임워크를 사용해서 예제를 작성했다.

- 이벤추에이트 트램에는 중요한 메커니즘 두 가지가 구현되어 있다.
- 트랜잭셔널 메시징
- 중복 메시징 감지
기초 메시징
- 기초 메시징 API는
MessageProducer,MessageConsumer두 인터페이스로 구성된다.
// MessageProducer
MessageProducer messageProducer = ...;
String channel = ...;
String payload = ...;
messageProducer.send(destination, MessageBuilder.withPayload(payload).build());// MessageConsumer
MessageConsumer messageConsumer;
messageConsumer.subscribe(subscriberId, Collections.singlton(destination), message -> { ... });- 이 두 인터페이스는 비동기 요청/응답 및 도메인 이벤트 발행에 관한 핵심 고수준 API다.
도메인 이벤트 발행
- 도메인 이벤트는 비즈니스 객체를 생성, 수정, 삭제 시 애그리거트가 발생시킨 이벤트다. 서비스는
DomainEventPublisher인터페이스를 이용하여 도메인 이벤트를 발행한다.
DomainEventPublisher domainEventPublisher;
String accountId = ...;
DomainEvent domainEvent = new AccountDebited(...);
domainEventPublisher.publish("Account", accountId, Collections.singletonList(domainEvent));- 서비스는
DomainEventDispatcher클래스로 도메인 이벤트를 소비한다.
DomainEventHandlers domainEventHandlers = domainEventHandlersBuilder.forAggregateType("order").onEvent(AccountDebited.class, domainEvent -> {...}.build();
new DomainEventDispatcher("eventDispatcherId", domainEventHandlers, messageConsumer);- 이벤추에이트 트램은 이벤트는 물론 Command/Response 기반의 메시징 등 고수준의 메시징 패턴도 지원한다.
커맨드/응답 메시징
- 클라이언트는
CommandProducer인터페이스를 이용하여 커맨드 메시지를 서비스에 보낸다.
CommandProducer commandProducer = ...;
Map<String, String> extraMessageHeaders = Collections.emptyMap();
String commandId = commandProducer.send("CustomerCommandChannel", new DoSomethingCommand(), "ReplyToChannel", extraMessageHeaders);- 서비스는
CommandDispather클래스로 커맨드 메시지를 소비한다
CommandHandlers commandHandlers = CommandHandlersBuilder.fromChannel(commandChannel).onMessage(DoSomethingCommand.class, (command) -> {
... ; return withSuccess();}).build();
CommandDispatcher dispatcher = new CommandDispatcher(subscribeId", commandHandlers, messageConsumer, messagProducer);- 이벤추에이트 트램 프레임워크는 자바 애플리케이션용 트랜잭셔널 메시징을 기본 지원하며, 트랜잭션이 걸린 상태에서 메시지를 주고받을 수 있는 저수준 API도 함께 제공한다. 또 도메인 이벤트를 발행/소비하고 커맨드를 전송/처리하는 고수준 API도 있다.
3.4 비동기 메시징으로 가용성 개선
3.4.1 동기 통신으로 인한 가용성 저하
- REST는 대중적인 IPC지만, 동기 프로토콜이라는 단점이 있다. -> 호출한 서비스가 응답할 때 까지 클라이언트는 Blocking 된다.
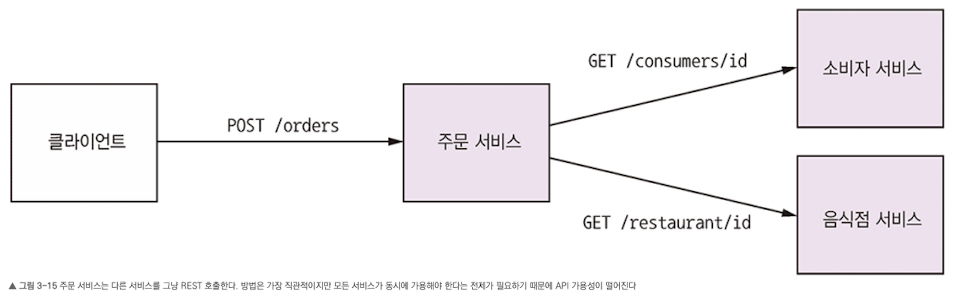
- 주문 생성의 이벤트 순서는 아래와 같다.
- 클라이언트가 주문 서비스에
HTTP POST /orders요청 - 주문 서비스는 소비자 서비스에
HTTP GET /consumers/id를 요청하여 소비자 정보를 조회 - 주문 서비스는 음식점 서비스에
HTTP GET /restaurant/id를 요청하여 음식점 정보를 조회 - 주문 서비스는 이렇게 조회한 소비자/음식점 정보로 올바른 주문인지 확인
- 주문 서비스는 주문을 생성
- 주문 서비스는 클라이언트에 HTTP 응답
- 클라이언트가 주문 서비스에
- 세 서비스 모두 HTTP를 사용하기 때문에 주문 생성 요청이 정상 처리되려면 서비스가 모두 가동중이여야 한다. 어느 한 서비스라도 장애가 나면 주문 생성은 불가능하다.
- 수학적으로 표현하면 시스템 작업의 가용성은 그 작업이 호출한 서비스의 가용성을 모두 곱한 값과 같다. 가령 주문 서비스와 이 서비스가 호출한 두 서비스의 가용성이 99.5%라면, 전체 가용성은 99.5%3 = 98.5%로 더 낮다.
- REST 뿐 아니라 어떤 서비스가 다른 서비스의 응답을 받은 이후에 자신의 클라이언트에 응답하는 구조라면 가용성은 떨어진다. 비동기 메시징을 통해 요청/응답하는 방식도 마찬가지다.
3.4.2 동기 상호 작용 제거
비동기 상호 작용 스타일
- 모든 트랜잭션은 비동기 상호 작용 스타일로 처리하는 것이 가장 좋다. 가령 클라이언트가 비동기 요청/응답 상호 작용을 통해 주문을 생성했다고 가정하면 클라이언트는 요청 메시지를 주문 서비스에 전송하여 주문을 생성한다. 그러면 주문 서비스는 다른 서비스와 메시지를 비동기 방식으로 교환하고, 최종적으로 클라이언트에 응답 메시지를 전송한다.
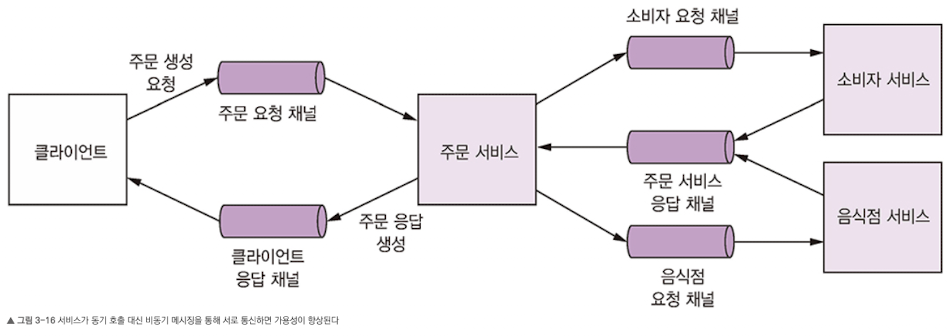
- 클라이언트/서비스는 메시징 채널을 통해 메시지를 전송해서 서로 비동기통신한다. 이런 상호 작용 과정에서는 어느 쪽도 응답을 대기하며 블로킹되지 않는다.
- 이런 아키텍처는 메시지가 소비되는 시점까지 메시지 브로커가 메시지를 버퍼링하기 때문에 매우 탄력적이다. 그러나 REST 같은 동기 프로토콜을 사용하기 때문에 요청 즉시 응답해야 하는 외부 API를 가진 서비스도 있을 것이다.
- 서비스에 동기 API가 있는 경우 **데이터를 복제하면 가용성을 높일 수 있다.
데이터 복제
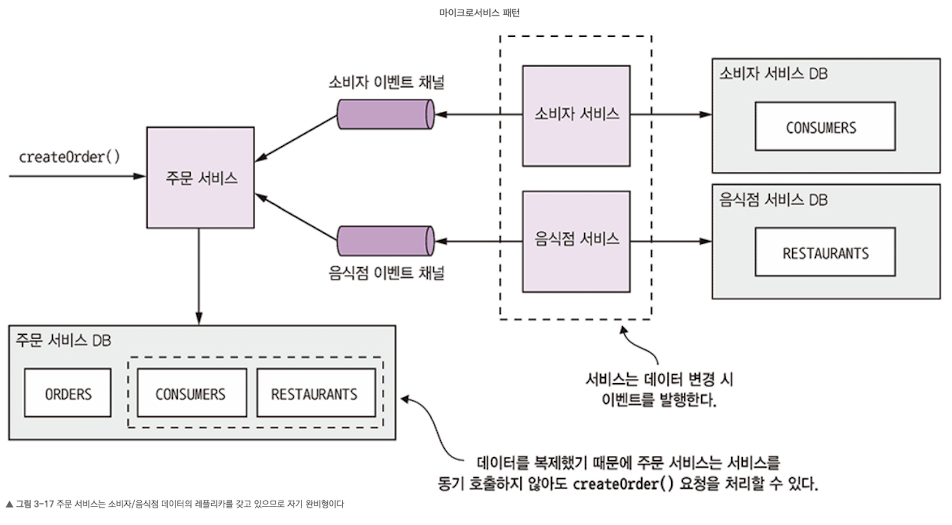
- 서비스 요청 처리에 필요한 데이터의 레플리카를 유지하는 방법
- 데이터 레플리카는 데이터를 소유한 서비스가 발행하는 이벤트를 구독해서 최신 데이터를 유지할 수 있다.
- 가령 소비자/음식점 서비스가 소유한 데이터 레플리카를 주문 서비스가 이미 갖고 있다면 주문 서비스가 주문 생성을 요청할 때 굳이 소비자/음식점 서비스와 상호 작용할 필요가 없다. 소비자/음식점 서비스는 각자 데이터가 변경될 때마다 이벤트를 발행하고, 주문 서비스는 이 이벤트를 구독하여 자기 편 레플리카를 업데이트하는 것이다.
- 데이터 복제는 경우에 따라 유용. 예를 들어 주문 서비스가 음식점 서비스에서 수신한 데이터를 복제해서 메뉴 항목을 검증하고 단가를 매길 때가 유용할 것이다. (5장)
- 물론 대용량 데이터의 레플리카를 만드는 것은 대단히 비효율적이다. 가령 소비자 서비스에 있는 엄청난 양의 소비자 데이터를 주문 서비스에 그대로 복제하는 것은 실용적이지 않고, 다른 서비스가 소유한 데이터를 업데이트하는 문제도 데이터 복제만으로는 해결되지 않는다.
- 한 가지 해결방 방법은 자신의 클라이언트에 응답하기 전까지 다른 서비스와의 상호 작용을 지연시키는 것이다.
응답 반환 후 마무리
- 요청 처리 도중 동기 통신을 제거하려면 요청을 아래와 같이 처리하면 된다.
- 로컬에서 가용한 데이터만 갖고 요청을 검증한다.
- 메시지를 OUTBOX 테이블에 삽입하는 식으로 DB를 업데이트한다.
- 클라이언트에 응답을 반환한다.
- 서비스는 요청 처리 중에 다른 서비스와 동기적 상호 작용을 하지 않는다. 그 대신 다른 서비스에 메시지를 비동기 전송한다. 이렇게 하면 서비스를 느슨하게 결합시킬 수 있다. 마이크로서비스 아키텍처에서는 사가를 이용하여 서비스를 느슨하게 결합한다.
- 주문 서비스를 이런 방식으로 구현한다면 먼저 주문을
PENDING상태로 생성하고, 다른 서비스와 메시지를 교환하여 주문을 비동기 검증한다. 그림 3-18은createOrder()를 호출하면 벌어지는 일이다.
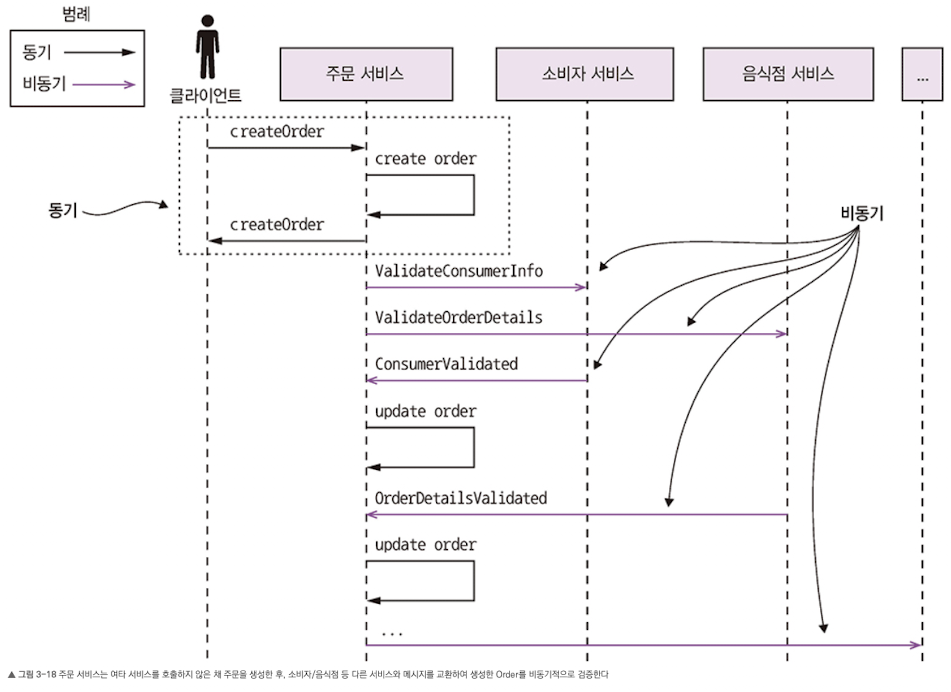
createOrder()를 호출하면 벌어지는 일이다.- 주문 서비스는 주문을
PENDING상태로 생성한다. - 주문 서비스는 주문 ID가 포함된 응답을 클라이언트에 반환한다.
- 주문 서비스는
ValidateConsumerInfo메시지를 소비자 서비스에 전송한다. - 주문 서비스는
ValidateOrderDetails메시지를 음식점 서비스에 전송 - 소비자 서비스는
ValidateConsumerInfo메시지를 받고 주문 가능한 소비자인지 확인 후,ConsumerValidated메시지를 주문 서비스에 보낸다. - 음식점 서비스는
ValidateOrderDetails메시지를 받고 올바른 메뉴 항목인지 음식점에서 주문 배달지로 배달이 가능한지 확인 후,OrderDetailsValidated메시지를 주문 서비스에 전송한다. - 주문 서비스는
ConsumerValidated및OrderDetailsValidated를 받고 주문 상태를 VALIDATED로 변경한다.
- 주문 서비스는 주문을
- 주문 서비스는 어떤 순서로든
ConsumerValidated,OrderDetailsValidated메시지를 받을 수 있다.- 이 서비스는 자신이 최초로 수신한 메시지에 따라 주문 상태를 변경한다.
ConsumerValidated를 먼저 받으면CONSUMER_VALIDATED로,OrderDetailsValidated를 먼저 받으면ORDER_DETAILS_VALIDATED로 주문 상태를 변경한다. 둘 다 다른 메시지를 수신할 때 주문 상태를VALIDATED로 바꾼다.
- 이 서비스는 자신이 최초로 수신한 메시지에 따라 주문 상태를 변경한다.
- 주문 서비스는 주문 검증을 마친 후 나머지 주문 생성 프로세스를 완료한다. 이렇게 처리하면 혹여 소비자 서비스가 내려가는 사고가 발생하더라도 주문 서비스는 계속 주문을 생성하고 클라이언트에 응답할 수 있다. 나중에 소비자 서비스가 재가동되면 큐에 쌓인 메시지를 처리해서 밀린 주문을 다시 검증하면 된다.
스터디 하면서 논의한 내용들
- Q. API 변경이 발생할시 어떻게 배포할 것인가
- A. 버전 번호를 MAJOR, MINOR, PATCH 새 파트로 구성하고 다음 규칙에 따라 각각 증가시킨다.
- Q. API에서 Robustness Principle를 지키기 위해 너무 많은 응답값 반환하는 것이 맞을까?
- A. 여러군데에서 사용되는 API를 만들기 위함이지만, 해당 api가 너무 많은 책임을 지게 되어 변경이 어려울 것 같다. 안쓰는 데이터나 필드들도 정의하면 나중에 리팩토링 할때 시스템 분석이 힘들 것이고, 운영관점에서 네트워크 비용도 무시할수가 없다. 역할과 책임을 잘 나눠서 어디까지 Robust하게 API를 만들 것인가 잘 생각해야 할 것 같다.
- Q. 어떻게 여러 버전의 API를 지원을 할까?
- A. AWS CloudFront를 활용해 API 게이트웨이 버저닝을 구현하는 방법
- 유저가 헤더에 어떤 값을 설정하여 요청을 보냄
- 요청이 CloudFront에 진입하여 Lamda@Edge를 트리거함
- 람다 함수는 저장소에서 해당 헤더값과 API 버전을 매핑한 정보를 가져와서 해당 요청이 어느 버전으로 가야하는지 결정
- CloudFront는 요청에 맞는 API 게이트웨이로 해당 요청을 전달
- A. AWS CloudFront를 활용해 API 게이트웨이 버저닝을 구현하는 방법
- Q. 트랜잭셔널 아웃박스 패턴 구현 시, 이벤트 발행 마다 OUTBOX 테이블에 데이터가 계속 갱신될텐데 성능문제를 어떻게 해결해야 할까?
- A. 복합 인덱스를 적용해 쿼리 성능을 올리거나, 일정 기간이 지나면 이벤트 로그를 OUTBOX 테이블에서 삭제하고 삭제한 데이터를 아카이브 테이블로 옮기는 크론 잡이 필요할 것 같다.

평범한 백엔드 개발자