2020년에 Decision Transformer: Reinforcement Learning via Sequence Modeling을 읽고 제대로 정리한 글입니다.

Decision Transformer는 Transformer architecture를 강화학습에 적용한 논문입니다.
기존의 Transformer architecture는 자연어 처리(GPT, BERT)에 적용되었습니다.
이 논문에서는 Transformer를 이용한 새로운 architecture를 제시합니다.
기존 RL model과 다르게, 인과관계를 활용해(Transformer의 특징) 최적의 action을 선택합니다.
이런 기존 Transformer의 특징을 활용한 단순함에도, 최신 model-free RL과 비슷하거나 그 이상의 성능을 보입니다.
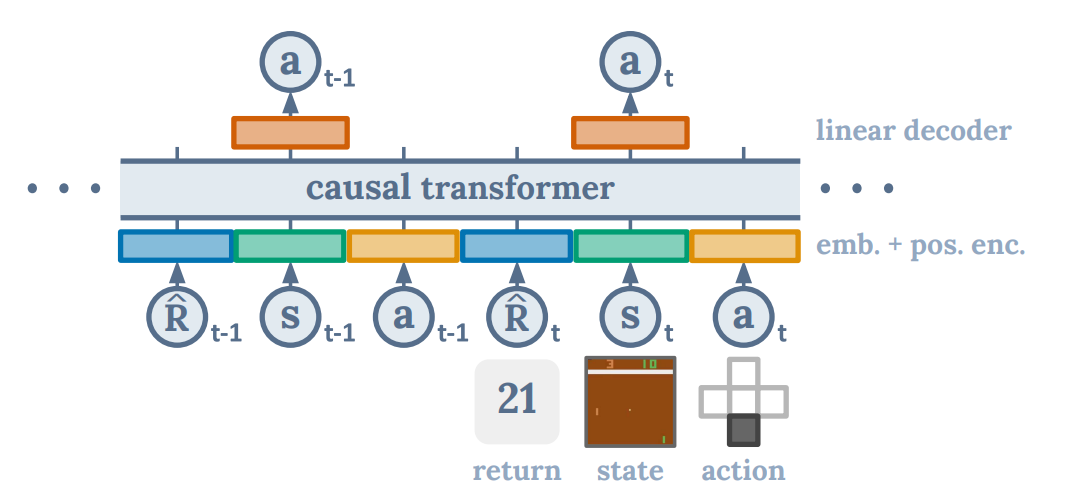
위 그림은 Decision Transformer의 가장 대표적인 사진입니다.
states, actions, returns를 input으로 주면(물론 embedding과 positional encoding을 거친 후),
causal attention을 통해 action을 선택합니다.
(뒤에서 causal attention에 대해 설명하겠습니다.)
1 Introduction
정말 유명한 논문이죠.
ML을 다루시는 분들은 필수로 알아야만 하는 attention is all you need 논문을 필두로,
vision, NLP(자연어 처리)분야 계속해서 관련 논문들이 쏟아지고 있습니다(2022-12-22 기준 60860 citation).
제대로 모르는 것 같다면 꼭 다시 읽어보시길 바랍니다.
위 논문의 주제인 Transformer의 특징을 간단하게 서술하면,
self-attention을 통해 각 단어(NLP), 각 pixel(vision)의 관계를 파악하고 이를 통해 NLP, vision task를 수행합니다.
여기서 관계라는 단어가 굉장히 굉장히 중요합니다.
RL도 관계를 파악시킬 수 있죠. 앞을 보고 뒤의 action을 sequential하게 선택하는 것이죠.
그래서 이 논문에서는 Transformer architecture를 RL에 적용시켰습니다.
논문에서는 자꾸 casual attention이란 말을 사용하는데, 이는 Transformer의 특징 중 하나입니다.
자연어 처리 과정을 예로 들어, 문장의 다음 말을 예측시 이전의 단어만으로 예측을 진행해야지,
다음 단어를 미리 알고 예측하는 것은 합리적이지 않습니다.
그래서 뒤의 단어는 참고하지 않고, 앞의 단어만을 참고하여 예측을 진행합니다.
이것을 causal attention이라고 합니다.(합리적이죠?)
연구자들은 기존의(conventional) RL 처럼 policy를 학습시키지 않고, sequence modeling object를 통해 transformer model을 학습시킵니다.
이렇게 하면 기존 RL의 문제중 하나인 long term credit assignment를 해결할 수 있다고 주장합니다.
long term credit assignment?
reward가 행동에 대해 늦게 발생하는 경우, agent가 적절한 행동을 취했을지라도 해당 행동에 대해 reward가 너무 늦게 주어진다면, 해당 행동강화에 대해 어려움이 생깁니다. 적절한 행동을 취했을 지라도 해당 행동에 높은 점수(credit assignment)를 주었을 때, action을 한 이후부터 보상을 받기 전까지 한 행동들이 모두 강화되는 점도 있습니다.
왜냐하면 Transformer는 self-attention을 통해 직접 credit assgnment를 수행할 수 있습니다.
이런 액션이 어디서 영향을 받았으며, 어디서 영향을 주었는지를 알 수 있기(어디에 attention한지) 때문입니다.
따라서 노이즈에도 transformer는 잘 견디는 것으로 알려져 있습니다.
기존(traditional RL)의 Bellman backups는 천천히 reward를 전파하고 산만하게 하는 신호(distractor signals, 외란 정도로 해석하면 좋을 듯 합니다)에 취약하다고 논문에서 말합니다.
또한 Boot-strapping을 피할 수 있습니다.
Boot-strapping은 기존의 RL(TD)를 불한정하게 만드는 요소인데,
기존의 RL은 를 로 업데이트를 진행하면서,
를 계속해서 업데이트를 진행하게 됩니다.
boot-strapping?
DQN처럼 예측을 통해 예측을 하는 방법을 뜻함. 실제 값이 아니기 때문에(TD target) 불안정합니다.
저는 처음 Decision Transformer를 공부할 때 이부분이 가장 헷갈렸는데, 논문에서는 확실하게 밝히고 있네요.
Decision Transformer는 offlineRL의 일종이며,
주어진 suboptimaL data로 학습을 진행하며(optimal data가 아닙니다!),
고정되고 한정된 data이지만 Transformer를 통한 sequence modeling object학습을 진행하면,
autoregressive generative modeling을 통해 policy sampling을 줄일 수 있다고 합니다.
(기존의 offline RL은 위와 같은 문제를 해결할 수 없음 에 대한 논문인 Offline Reinforcement Learning: Tutorial, Review,and Perspectives on Open Problems여력이 된다면 리뷰해보겠습니다.).
연구자들의 연구의 직관을 얻기 위해 방향 그래프에서 가장 짧은 길을 찾는 task를 고려해보자고 합니다.
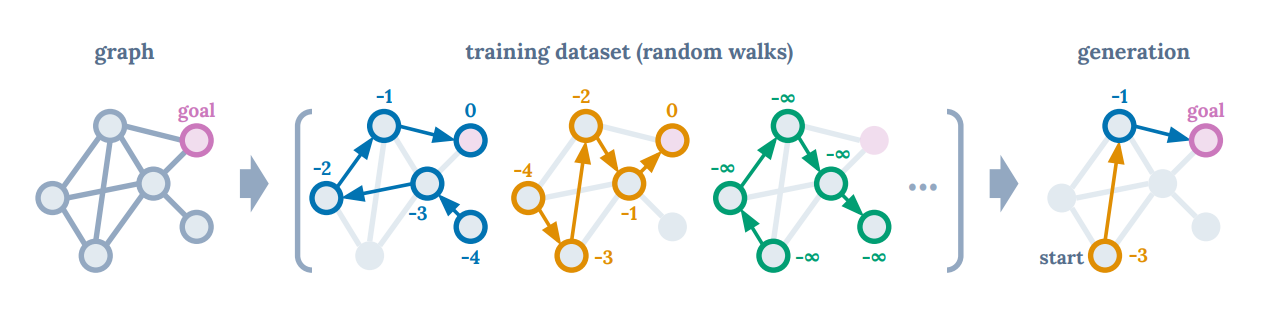
0은 agent가 goal에 도달했을 때 주어지는 reward이며, -1은 agent가 goal에 도달하지 못했을 때 주어지는 reward입니다.
우리는 GPT model을 통해 returns-to-go, states, actions를 예측해보려 합니다.
사진에서의 training data(이곳에서는 expert가 하지 않은 마구잡이로 진행한 data)로 optimal tragectories를 가장 높은 returns를 받는 방향으로 학습합니다.
이 때 dynamic programming은 전혀 사용하지 않습니다.
dynamic programming?
문제를 작은 문제로 나누어 푸는 방법으로, Bellman equation을 통해 optimal policy를 찾는 방법입니다.
Decision Transformer는 이 생각으로부터 영감을 받았다고 하며, autoregressivly model trajectories를 이용하기 위해 GPT를 사용했다고 합니다.
위 Decision Transformer를 사용했을 때 model-free RL과 비교했을 때 기존 sota 알고리즘과 비슷하거나 그 이상이였으며,
long term credit assignment 문제를 해결하는 task는 기존의 model-free RL보다 뛰어나다고 하였습니다.
2 Preliminaries
2.1 Offline Reinforcement Learning
Offline Reinforcement Learning은 environment와 직접적인 상호작용을 통해 data를 얻는 것이 아닌,
전에 임의의 policy 진행한 data로(당연히 수가 정해져 있고 한정적이겠죠?) 학습을 진행합니다.
당연히 OnlineRL보다 explore를 더 어렵게 하며, 추가적인 feedback을 받기 어렵습니다.
2.2 Transformers
Transformers는 위에서 언급한 attention is all you need에서 제안된 모델입니다.
가장 큰 특징은 sequential data에 굉장히 효과적인 모델이라는 점입니다.
이 모델들은 residual-connection, multi-head attention, layer normalization 등을 사용하여 self-attention layers를 쌓아서 만들어집니다.
뒤에서 추가적으로 서술하겠지만, 이 layer들이 credit assignment를 진행하는데 중요한 역할을 합니다.
3 Method
3.1 Trajectory representation
우리가 원하는 것은 trajectory 로부터 meaningful pattern을 학습하고 이를 통해 적절한 action을 선택하는 것입니다.
이를 위해 우리는 과거의 reward를 통해 action을 선택하는 것이 아닌, 미래의 받을 것이라 예상되는 reward를 통해 action을 선택합니다.
결국 이말은 rewards를 바로 지급하는 것이 아닌, 미래의 받을 reward returns-to-go
로 action을 생성할 수 있게 해야합니다.
이를 우리가 원하는 trajectory representation으로 바꾸면
위와같이 나타낼 수 있습니다.
3.2 Architecture
researcher들은 Decision Transformer에게 K timesteps만큼의 trajectory를 주고(state, action, return-to-go니까 총 3K죠?), K+1 timestep의 action을 예측하도록 학습시킵니다.
다른 Transformer과 마찬가지로, embedding dimension으로 사영(project)시키고, layer normalization을 진행합니다.
state가 image일 경우, CNN을 통해 feature를 뽑아내고, 이를 Transformer에 넣어주면 됩니다.
추가적으로 intorduction에서 언급한 것처럼, positional encoding을 추가해줍니다.
이때 positional encoding은 기존 transformer와 다릅니다.
한 time step에 세개의 tokens가 부여되며, GPT 모델에서 사용되는 것처럼 사용됩니다.
이것은 다음 action tokens을 auto-regressive하게 예측하기 위함입니다.
(코드 리뷰에서 자세히 다룹니다)
3.3 Training

먼저 def DecisionTransformer를 보도록 합시다.
인자로는 Returns-to-go, states, actions(위에 언급한것 처럼 K개씩 총 3K개!), timesteps을 받습니다.
첫번째로 positional embedding을 만들기 위해 time step을 embed_t에 넣습니다.
이후 s, a, r을 각각 state, action, return-to-go embedding에 넣어주고 위의 positional embedding과 더해줍니다.
각 embedding을 stack하여 input embeds를 만들어줍니다.
이 때 이 input embeds는 K개의 state, action, return-to-go의 정보를 가지고 있습니다.
이후 transformer에 통과를 시켜 hidden state를 만들어줍니다.
이 hidden_states는 각각의 state, action, return-to-go가 어떤 정보에 attention하고 있는지를 나타냅니다.
trainig loop는 코드 리뷰에서 자세히 다뤘으니까 evaluation loop를 자세히 봅시다.

while not done loop 안을 보면-
-
Decision Transformer에 state, action, return-to-go를 넣어줍니다.
-
env.step(action)을 통해 다음 state, reward, done을 받아옵니다.
-
return-to-go를 계산합니다.
-
state, action, return-to-go를 각각 state, action, return-to-go list에 append합니다.
-
K개 만큼만 state, action, return-to-go list를 유지합니다.
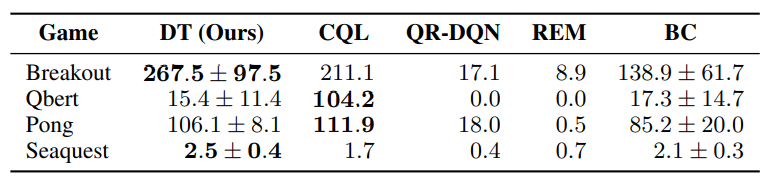
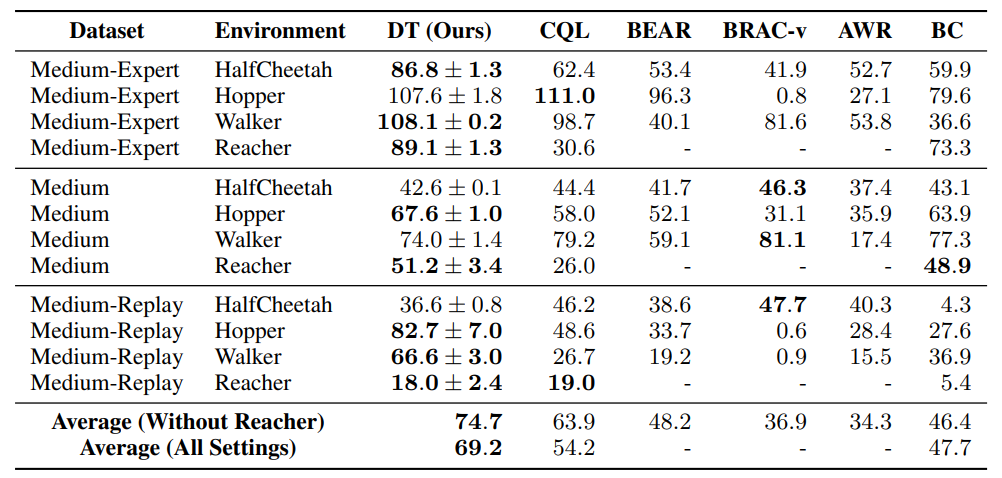
위처럼 진행했을 때 결과는 기존 traditional 방법인 CQL, behavior cloning과 비교했을 때 더 좋은 성능을 보였습니다.
4 Evaluations on Offline RL Benchmarks
이 section에서는 기존 offline RL과 imitaiton learning 방법들과 비교했을 때 Decision Transformer의 성능을 보여줍니다.
Atari와 OpenAI Gym task를 골랐는데 Atari는 큰 observation space와 long-term credit assignment 문제를 가지고 있습니다.
OpenAI Gym은 세밀한 연속 제어를 요합니다.
4.1 Atari
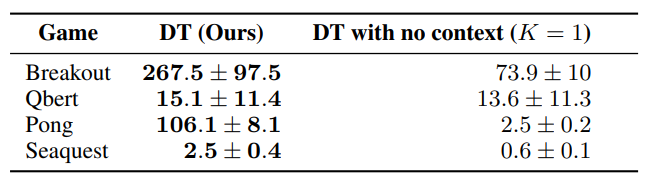
학습시 context lengths를 30으로 설정했고, Pong은 50으로 설정했습니다.
Atari dataset의 1%를 사용해 학습을 진행했다고 합니다.
4개 게임중 3개 게임에서 CQL과 비슷한 성능을 발휘하며, 대부분의 게임에서 다른 baseline보다 뛰어난 성능을 보입니다.
4.2 OpenAI Gym
여기서는 D4RL benchmark를 사용합니다.

대부분의 conventional RL에 비해 더 좋은 성능을 보입니다.
5 Discussion
5.1 Does Decision Transformer perform behavior cloning on a subset of the data?
section 5.1의 제목을 그대로 번역하면 Decision Transformer이 데이터의 일부를 이용해 behavior cloning을 하는가? 입니다.
(잘 모르겠음)
데이터셋이 많을 때는 Decision Transformer가 압도했지만,
데이터셋이 적을 때는 behavior cloning이 더 좋은 성능을 보였습니다.
5.2 How does Decision Transformer compare to other imitation learning methods?
모든 task에서 예측되는 return-to-go와 실제로 받은 return이 굉장히 큰 상관관계가 있었음이 관측됩니다.
Pong, HalfCheetah, Walker 같은 경우는 굉장히 잘된다고 자랑했습니다.
추가로, Seqquest같은 경우 dataset에서 할 수 있는 최고의 return을 뛰어넘었다고 했습니다.
dataset이 구린데 이것보다 뛰어난 성능을?
이것을 시사하는 바는 Decision Transformer는 exrapolation도 할 수 있다는 것을 보여줍니다.
5.3 What is the benefit of using a longer context length?
context length에 대한 중요성을 보기 위해 context를 없애버립니다.
K=1일 때는 성능이 떨어지는 것을 볼 수 있습니다.
context length를 늘릴 때 더 성능을 향상 시킬 수 있다는 것을 알 수 있습니다.
5.4 Does Decision Transformer perform effective long-term credit assignment?
정말 Decision Transformer는 long-term credit assignment을 잘할까요?
이를 알아보기 위해 Key-to-Door environment를 사용합니다.
이 환경은 grid based environment로, agent는 key를 찾아서 door를 열어야 합니다.
간단한 설명을 하자면
(1) 첫번째로, agent는 key를 찾아야 합니다.
(2) agent는 empty room에 있게 됩니다.
(3) 마지막으로, agent는 door가 있습니다.
agent는 세번째 페이즈에서 door를 열 때만 reward가 생깁니다. 하지만 무우조건 첫번째 페이즈에서 key를 찾아야 합니다.
딱봐도 어렵죠? 에피소드의 끝에 reward가 있기 때문에 이게 전파되기 어렵겠죠?
key-to-door 성공률을 나타낸 표입니다.
Decision Transformer가 좋은 성능을 보여주는데 반해, TD learning은 credit assignment를 힘들어하는 것을 볼 수 있습니다.
5.5 Can transformers be accurate critics in sparse reward settings?
정말 희소한 보상에서도 transformer가 정확한 비평가(return-to-go)를 잘 맞출까요?
앞의 section에서는 효과적인 actor임을 확인했다면,
이 section에서는 효과적인 critic임을 확인합니다.
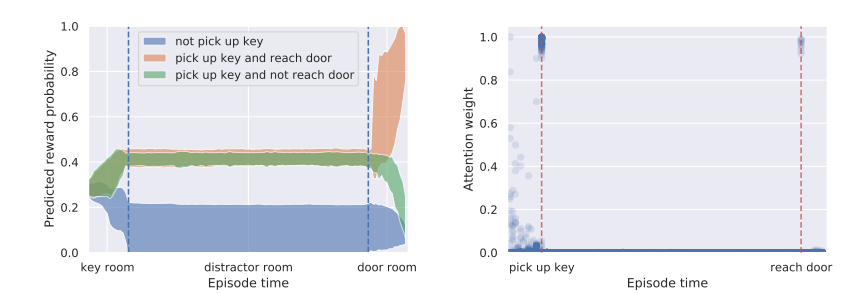
왼쪽 그림을 보면 episode를 진행하면서 계속해서 update가 일어남을 알 수 있으며,
게다가 오른쪽 그림에선 attention weight를 통해 특별한 이벤트에서 집중함을 알 수 있습니다.
5.6 Does Decision Transformer perform well in sparse reward settings?
5.7 Why does Decision Transformer avoid the need for value pessimism or behavior regularization?
5.8 How can Decision Transformer benefit online RL regimes?
어떻게 Decision Transformer가 online RL 체제에 도움이 될까요?
