class DecisionTransformer(nn.Module):
def __init__(self, state_dim, act_dim, n_blocks, h_dim, context_len,
n_heads, drop_p, max_timestep=4096):
super().__init__()
self.state_dim = state_dim
self.act_dim = act_dim
self.h_dim = h_dim
### transformer blocks
input_seq_len = 3 * context_len
blocks = [Block(h_dim, input_seq_len, n_heads, drop_p) for _ in range(n_blocks)]
self.transformer = nn.Sequential(*blocks)
### projection heads (project to embedding)
self.embed_ln = nn.LayerNorm(h_dim)
self.embed_timestep = nn.Embedding(max_timestep, h_dim)
self.embed_rtg = torch.nn.Linear(1, h_dim)
self.embed_state = torch.nn.Linear(state_dim, h_dim)
# # discrete actions
# self.embed_action = torch.nn.Embedding(act_dim, h_dim)
# use_action_tanh = False # False for discrete actions
# continuous actions
self.embed_action = torch.nn.Linear(act_dim, h_dim)
use_action_tanh = True # True for continuous actions
### prediction heads
self.predict_rtg = torch.nn.Linear(h_dim, 1)
self.predict_state = torch.nn.Linear(h_dim, state_dim)
self.predict_action = nn.Sequential(
*([nn.Linear(h_dim, act_dim)] + ([nn.Tanh()] if use_action_tanh else []))
)
def forward(self, timesteps, states, actions, returns_to_go):
B, T, _ = states.shape
time_embeddings = self.embed_timestep(timesteps)
# time embeddings are treated similar to positional embeddings
state_embeddings = self.embed_state(states) + time_embeddings
action_embeddings = self.embed_action(actions) + time_embeddings
returns_embeddings = self.embed_rtg(returns_to_go) + time_embeddings
# stack rtg, states and actions and reshape sequence as
# (r1, s1, a1, r2, s2, a2 ...)
h = torch.stack(
(returns_embeddings, state_embeddings, action_embeddings), dim=1
).permute(0, 2, 1, 3).reshape(B, 3 * T, self.h_dim)
h = self.embed_ln(h)
# transformer and prediction
h = self.transformer(h)
# get h reshaped such that its size = (B x 3 x T x h_dim) and
# h[:, 0, t] is conditioned on r_0, s_0, a_0 ... r_t
# h[:, 1, t] is conditioned on r_0, s_0, a_0 ... r_t, s_t
# h[:, 2, t] is conditioned on r_0, s_0, a_0 ... r_t, s_t, a_t
h = h.reshape(B, T, 3, self.h_dim).permute(0, 2, 1, 3)
# get predictions
return_preds = self.predict_rtg(h[:,2]) # predict next rtg given r, s, a
state_preds = self.predict_state(h[:,2]) # predict next state given r, s, a
action_preds = self.predict_action(h[:,1]) # predict action given r, s
return state_preds, action_preds, return_predsclass DecisionTransformer(nn.Module):
def __init__(self, state_dim, act_dim, n_blocks, h_dim, context_len,
n_heads, drop_p, max_timestep=4096):forward를 살펴보기 전, 여기서 Decision Transformer의 인자들을 살펴보겠습니다.
state_dim은 state의 차원입니다. 만약 gym Mountain_Car환경을 사용한다면
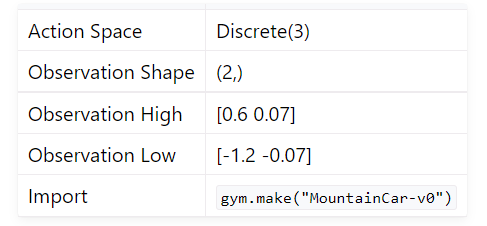
state_dim은 car의 x방향 위치, car의 속도 두개로 이루어져 있으므로 총 2개입니다.
RL환경이 이렇게 쉬울리가 없죠?ㅎㅎ
위와같은 task는 굉장히 쉬운거고, 우리에게 시야밖에 주어지지 않는다면 어떻게 해야할까요?
그때는 CNN을 통과시켜 직접 observation을 추출해내야 합니다.
직접 state_dim을 설정해줄 수도 있겠네요.
action_dim은 action의 차원입니다. Mountain_Car환경에서는 action_dim은 3개입니다.
n_blocks는 transformer의 layer의 개수입니다.
전 포스트에서 언급했던 block Nx겠네요!
h_dim은 transformer의 hidden dimension입니다.
context_len은 transformer의 context length입니다.
n_heads는 transformer의 head의 개수입니다.
drop_p는 transformer의 dropout 확률입니다.
Decision Transformer 역시 forward를 보면서 코드를 이해해보겠습니다.
time_embeddings = self.embed_timestep(timesteps)논문에서 언급한대로 time embedding을 추가해줍니다.
batch_size를 빼고 생각하면,
time embedding의 차원은 (T, h_dim)이고, T는 timestep의 개수입니다.
# time embeddings are treated similar to positional embeddings
state_embeddings = self.embed_state(states) + time_embeddings
action_embeddings = self.embed_action(actions) + time_embeddings
returns_embeddings = self.embed_rtg(returns_to_go) + time_embeddings여기서 포인트는 time_embeddings를 state, action, return_to_go에 따로따로 더해주는 것이 아닌
time_embeddings를 한번만 계산해서, 동일하게 더해준다는 것입니다.
embedding들의 차원은
h = torch.stack(
(returns_embeddings, state_embeddings, action_embeddings), dim=1
).permute(0, 2, 1, 3).reshape(B, 3 * T, self.h_dim)이렇게 나온 임베딩들을 하나로 합쳐(stack)줍니다.
그러면 h의 차원은 (B, 3T, h_dim)이 됩니다.
그리고 이를 permute를 통해 (B, h_dim, 3T)로 바꿔줍니다.
그리고 reshape를 통해 (B, 3T, h_dim)로 바꿔줍니다.
이게 뭐하는 짓이냐고요?
한번 예시를 들어 봅시다.
import torch
states = torch.tensor([[0,0,0],[1,1,1],[2,2,2]])
actions = torch.tensor([[3,3,3],[4,4,4],[5,5,5]])
rtgs = torch.tensor([[6,6,6],[7,7,7],[8,8,8]])
h = torch.stack((states, actions, rtgs), dim=1)
h_dim = 3states에서 [0,0,0]은 첫번째 state, [1,1,1]은 두번째 state, [2,2,2]는 세번째 state입니다.
여기서 h_dim은 3이므로, 3개의 숫자가 하나의 state를 표현한다고 생각하면 되겠죠?
다음과 같이 선언해주고 stack을 해주면
h = tensor([[[0, 0, 0],
[3, 3, 3],
[6, 6, 6]],
[[1, 1, 1],
[4, 4, 4],
[7, 7, 7]],
[[2, 2, 2],
[5, 5, 5],
[8, 8, 8]]])위와같이 나오게 됩니다.
같은 시점의 state, action, return_to_go를 하나로 묶어주게 됩니다.
h.permute(1,0,2).reshape(3*3,3)위와 같이 permute을 해주고 reshape를 해주면
tensor([[0, 0, 0],
[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4],
[5, 5, 5],
[6, 6, 6],
[7, 7, 7],
[8, 8, 8]])깔끔하게 각 줄이 state, action, return_to_go를 하나로 묶어준 것을 볼 수 있습니다.
순서대로 해줘야되는데, 왜 이렇게 하냐면,
이미 time_embeddings를 더해주었기 때문에, 시간또한 고려되어 있는 상태입니다.
(물론 이 예시에서는 안더했지만요.)
다시 코드로 돌아가봅시다.
h = self.embed_ln(h)
# transformer and prediction
h = self.transformer(h)layer norm을 해준 후,
전 post에서 설명했던 transformer를 통과시켜줍니다.
잠깐 init에서 transformer를 어떻게 선언했는지 살펴보면
### transformer blocks
input_seq_len = 3 * context_len # state, action, return_to_go 3개를 context_len만큼
blocks = [Block(h_dim, input_seq_len, n_heads, drop_p) for _ in range(n_blocks)]
self.transformer = nn.Sequential(*blocks)그림에서의 Nx를 다음과 같이 구현했군요!
블럭을 N번 반복해서 transformer를 만들어주었습니다.
주목해야할 것은 N개의 같은 블럭이 반복되는 것이 아니라, N개의 다른 블럭이 반복되는 것입니다.
각 블럭은 다른 weight를 가지고 있습니다.
transformer를 거친 후,
h = h.reshape(B, T, 3, self.h_dim).permute(0, 2, 1, 3)reshape를 해주고 permute를 해줍니다.
왜해주는지는 위의 예시에서 설명했죠?
이 h는 N개의 블럭을 거친 후의 결과입니다.
자 이제 h로 다음 state, action, return_to_go를 예측해봅시다!
# h[:, 0, t] is conditioned on r_0, s_0, a_0 ... r_t
# h[:, 1, t] is conditioned on r_0, s_0, a_0 ... r_t, s_t
# h[:, 2, t] is conditioned on r_0, s_0, a_0 ... r_t, s_t, a_t
# get predictions
return_preds = self.predict_rtg(h[:,2]) # predict next rtg given r, s, a
state_preds = self.predict_state(h[:,2]) # predict next state given r, s, a
action_preds = self.predict_action(h[:,1]) # predict action given r, s
return state_preds, action_preds, return_preds이렇게 Decision Transformer 코드가 끝났습니다.
이걸 어떻게 training하는지 한번 봅시다.
Training
model = DecisionTransformer(
state_dim=state_dim,
act_dim=act_dim,
n_blocks=n_blocks,
h_dim=embed_dim,
context_len=context_len,
n_heads=n_heads,
drop_p=dropout_p,
).to(device)다음처럼 선언해주시고,
for _ in range(num_updates_per_iter):
try:
timesteps, states, actions, returns_to_go, traj_mask = next(data_iter)
except StopIteration:
data_iter = iter(traj_data_loader)
timesteps, states, actions, returns_to_go, traj_mask = next(data_iter)
timesteps = timesteps.to(device) # Batch_size X Sequence_length
states = states.to(device) # Batch_size x Sequence_length x state_dim
actions = actions.to(device) # Batch_size x Sequence_length x act_dim
returns_to_go = returns_to_go.to(device).unsqueeze(dim=-1) # Batch_size x Sequence_length x 1
traj_mask = traj_mask.to(device) # Batch_size x Sequence_length
action_target = torch.clone(actions).detach().to(device)
state_preds, action_preds, return_preds = model.forward(
timesteps=timesteps,
states=states,
actions=actions,
returns_to_go=returns_to_go
)
# only consider non padded elements
action_preds = action_preds.view(-1, act_dim)[traj_mask.view(-1,) > 0]
action_target = action_target.view(-1, act_dim)[traj_mask.view(-1,) > 0]
action_loss = F.mse_loss(action_preds, action_target, reduction='mean')
optimizer.zero_grad()
action_loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.25)
optimizer.step()
scheduler.step()이렇게 학습을 시켜주시면 됩니다.
풀어서 한번 보면
timesteps = timesteps.to(device) # Batch_size X Sequence_length
states = states.to(device) # Batch_size x Sequence_length x state_dim
actions = actions.to(device) # Batch_size x Sequence_length x act_dim
returns_to_go = returns_to_go.to(device).unsqueeze(dim=-1) # Batch_size x Sequence_length x 1
traj_mask = traj_mask.to(device) # Batch_size x Sequence_lengthdataset에서 다음과 같이 꺼내오고 있습니다.
현재 이상태는 Sequence_length만큼의 길이를 가지고 있습니다.
state_preds, action_preds, return_preds = model.forward(
timesteps=timesteps,
states=states,
actions=actions,
returns_to_go=returns_to_go
)이제 예측을 해봅시다.
timesteps, states, actions, returns_to_go를 넣어주면
위에서 정의한 것처럼 예측을 얻을 수 있습니다.
action_preds = action_preds.view(-1, act_dim)[traj_mask.view(-1,) > 0]
action_target = action_target.view(-1, act_dim)[traj_mask.view(-1,) > 0]우리는 뒤에 있는 값을 이용해 예측하지 않는다고 말했죠?
뒤에 있는 값들인 mask를 이용해 뒤에 있는 값을 제거해줍니다.
action_loss = F.mse_loss(action_preds, action_target, reduction='mean')특이한 점은 action만 loss를 구해서 학습을 시킵니다.
state와 return은 loss를 구하지 않습니다.
끝!
