주의 : 공부하면서 적은 글이므로 틀린 정보가 있을 수도 있으며, 코드 참고할 내용은 없습니다 일부러 안적었습니다.
Intro
8GB 램, 16GB 램, 조립컴퓨터를 맞춰 봤다면 당연히 알 것이고, 적어도 게임에 관심있는 사람이라면 들어봤을 것이다. 아니 애초에 이 글을 읽고 있을 것이라면 적어도 램이 '메인메모리'라는 것은 깔고 가야 할 부분일 것이다.
위와 같이 메모리는 한정된 크기를 가진다. 그럼에도 우리는 많은 프로그램을 동시에 실행하고 있다.
어떻게 이것이 가능할까?
운영체제는 한정된 메모리 공간을 효율적으로 사용하기 위해 가상메모리 기법을 사용하기 때문이다.
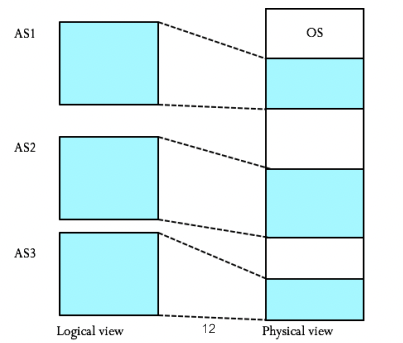
각 프로그램에 실제 메모리의 주소가 아닌 가상의 메모리의 주소를 주는 방식이다.
가상메모리를 이용하여 실제 물리 메모리가 가진 크기보다 논리적으로 확장하여 사용할 수 있다.
가상메모리 시스템에서는 각 프로그램은 가상 메모리의 주소를 가지고 CPU가 메모리 참조를 시도할 때에는 MMU를 통해 해당 가상주소를 실제 물리주소로 변환시켜서 메모리 참조가 이루어진다.
가상메모리 기법은 크게 요구 페이징 방식(demand paging)과 요구 세그먼테이션 방식(demand segmentation)으로 구현이 된다. 대부분의 경우에는 요구 페이징 방식을 사용한다.
하지만 실제로는 물리주소는 한정되어 있고 프로세스에게 인식되는 가상 주소보다 훨씬 작은 크기이다. 이번 Project 3에서는 직접 구현을 해보면서 그것이 어떻게 가능한지 알아보았다.
Managing the Frame Table
프레임 테이블의 관리
Requirements
The frame table contains one entry for each frame. Each entry in the frame table contains a pointer to the page, if any, that currently occupies it, and other data of your choice. The frame table allows Pintos to efficiently implement an eviction policy, by choosing a page to evict when no frames are free.
프레임 테이블에는 각 프레임의 엔트리 정보가 담겨 있습니다. 프레임 테이블의 각 엔트리에는 현재 해당 엔트리를 차지하고 있는 페이지에 대한 포인터(있는 경우라면), 그리고 당신의 선택에 따라 넣을 수 있는 기타 데이터들이 담겨 있습니다. 프레임 테이블은 비어있는 프레임이 없을 때 쫓아낼 페이지를 골라줌으로써, Pintos가 효율적으로 eviction policy를 구현할 수 있도록 해줍니다.
Implementation
void vm_init(void)
{
vm_anon_init();
vm_file_init();
#ifdef EFILESYS /* For project 4 */
pagecache_init();
#endif
register_inspect_intr();
/* DO NOT MODIFY UPPER LINES. */
/* TODO: Your code goes here. */
/* initialize global frame table (for users) */
list_init(&ft);
}프레임 테이블은 물리 메모리의 이용 현황을 파악하는 자료구조이다. 이번 프로젝트에서는 list로 구현했다.
프레임 테이블이 왜 필요할까?
모든 페이지는 메모리가 구성될 때 메모리에 대한 메타 데이터를 보유하고 있지 않다. 따라서 물리 메모리를 관리하기 위한 다른 방식이 필요하다. 바로, 물리 메모리 내 각 프레임 정보를 갖고 있는 frame table이 필요하다.
모든 프레임이 가득찬 상태가 아니라면 프레임을 얻어오는 것은 쉽다, 하지만 모든 프레임이 가득 찼을 때 우리는 프레임을 어떻게 얻어올 것인지에 대해 고려해야 한다.
해결 방안 : Eviction, frame table에 의한 관리
Managing the Supplemental Page Table
보조 페이지 테이블의 관리
Requirments
The supplemental page table supplements the page table with additional data about each page. It is needed because of the limitations imposed by the page table's format. Such a data structure is often called a "page table" also; we add the word "supplemental" to reduce confusion.
보조 페이지 테이블은 각 페이지에 대한 추가 데이터를 이용해서 페이지 테이블을 보조합니다. 페이지 테이블의 포맷으로 인해 생기는 제한들 때문에 보조 페이지 테이블이 필요합니다. 이런 자료구조는 종종 “페이지 테이블”로도 불리는데, 저희는 혼란을 방지하기 위해서 “보조”라는 단어를 붙였습니다.
과제 요구서에서는 page fault와 자원관리를 처리하기 위해 각 페이지에 대한 추가적인 정보를 담고 있을 보충 페이지 테이블(Supplemnetary page table)을 구현할 것을 요구하고 있다.
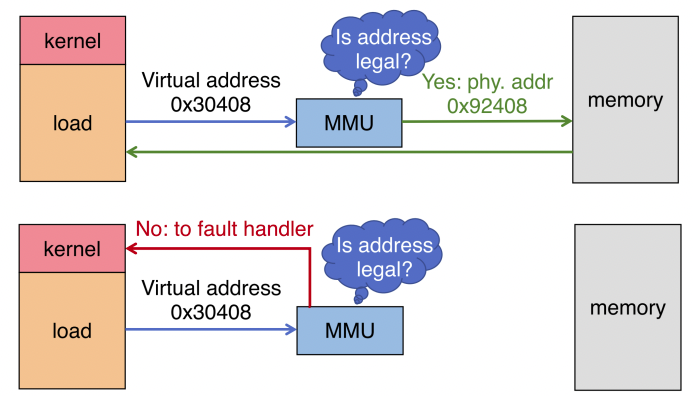
위와 같이 CPU에서 어떠한 인스트럭션을 수행하기 위해 가상주소에 접근한다고 가정해보자. 가상 주소에 접근하면 MMU를 통해 해당 가상주소에 대응하는 물리 주소로 변환되어 해당 물리주소에 접근한다.
하지만 요구 페이징 기법을 사용하였기 때문에 특정 페이지에 대해 CPU의 요청이 들어온 뒤 해당 페이지를 메모리에 적재하는 lazy loading으로 인한 page fault가 발생한다. 이러한 bogus한 page fault를 관리하기 위해 필요한 자료구조가 supplemental page table이다.
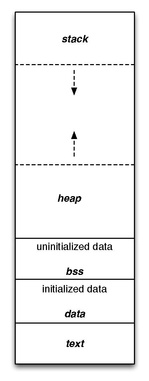
프로세스의 data segment는 load될 때 바로 물리주소를 할당하는 것이 아니라 page 단위로 disk의 스왑영역에 위치하게 된다.
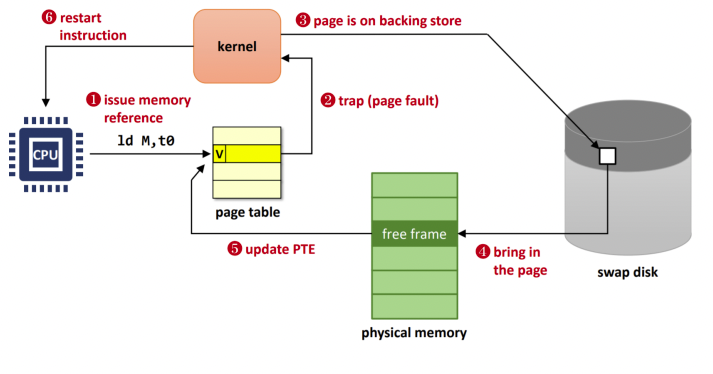
물리 메모리가 가득 찰 경우 물리 메모리를 점유하고 있는 가상 주소를 할당받지 않고 disk의 swap영역에 존재하고 있다. 그 여부를 확인하기 위한 자료구조가 supplemental page table이다. pintos에서는 load -> load_segment -> vm_alloc_page_with_initializer 순으로 실행되는데 이때 UNINIT 페이지를 생성하고 이를 SPT에 삽입한다.
/* TODO: and then create "uninit" page struct by calling uninit_new. You
* TODO: should modify the field after calling the uninit_new. */
uninit_new(page, upage, init, type, aux, initializer_for_type);
page->writable = writable;
/* TODO: Insert the page into the spt. */
return spt_insert_page(spt, page);이렇게 spt에 page를 삽입하여 두면, 후에 page fault가 발생하여 이를 핸들링 할 때, spt를 확인하여 해당 fault가 valid한 fault인지 여부를 판단하고 spt에 존재할 경우, lazy loading에 의한 bogus한 fault로 판단하여 이를 핸들링하는 함수 vm_try_handle_fault를 호출한다.
Implementation
supplemental_page_table_init
/* Initialize new supplemental page table */
void supplemental_page_table_init(struct supplemental_page_table *spt UNUSED)
{
hash_init(&spt->pages);
}userprog/process.c의 initd 함수로 새로운 프로세스가 시작하거나 process.c의 __do_fork로 자식 프로세스가 생성될 때 위의 함수가 호출된다.
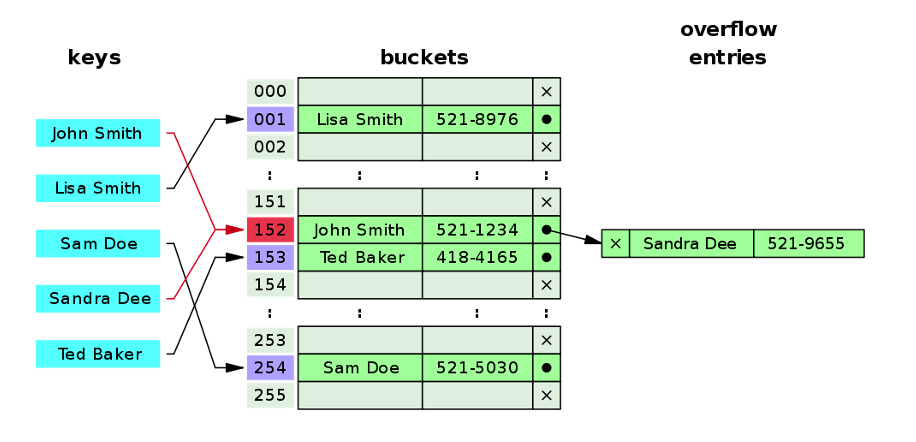
hash table로 구현한 이유.
- 효율적인 데이터 관리가 가능하다.
많은 양의 데이터를 작은 크기의 메모리의 해쉬테이블로 관리할 수 있다. - 빠른 데이터 처리가 가능하다.
해쉬 함수를 사용해서 변환한 해쉬 값을 인덱스로 한 bucket에 요소를 삽입하기 때문에 나중에 해당 요소를 찾을 때 순회할 필요 없이 해당 인덱스를 찾는다. 이로 인해 상수시간 에 삽입/삭제를 빠르게 수행할 수 있다.
hash table을 생성할때
bool hash_init (struct hash *hash, hash_hash_func *hash_func, hash_less_func
*less_func, void *aux)함수를 사용하는데, 이는 해쉬 함수 hash_func과 bucket에서의 정렬함수 hash_less_func을 인자로 갖는 hash table을 만든다는 의미이다.
hash 함수를 만들 때 pintos - hash.c에 이미 구현되어 있던 함수를 활용했다.
/* Returns a hash of the SIZE bytes in BUF. */
uint64_t
hash_bytes (const void *buf_, size_t size) {
/* Fowler-Noll-Vo 32-bit hash, for bytes. */
const unsigned char *buf = buf_;
uint64_t hash;
ASSERT (buf != NULL);
hash = FNV_64_BASIS;
while (size-- > 0)
hash = (hash * FNV_64_PRIME) ^ *buf++;
return hash;
}