
Pintos Project 3 - Memory Management까지 큰 그림
In project 2, a page fault always indicated a bug in the kernel or a user program. In project 3, this is no longer true. Now, a page fault might only indicate that the page must be brought in from a file or swap slot.
프로젝트 2에서는, 페이지 폴트는 항상 커널 또는 유저 프로그램의 버그를 의미했습니다. 하지만 프로젝트 3에서는 더 이상 아닙니다. 이제 페이지 폴트는 파일 또는 스왑 슬롯에서 페이지를 가져와야 한다는 사실을 의미하게 됩니다.
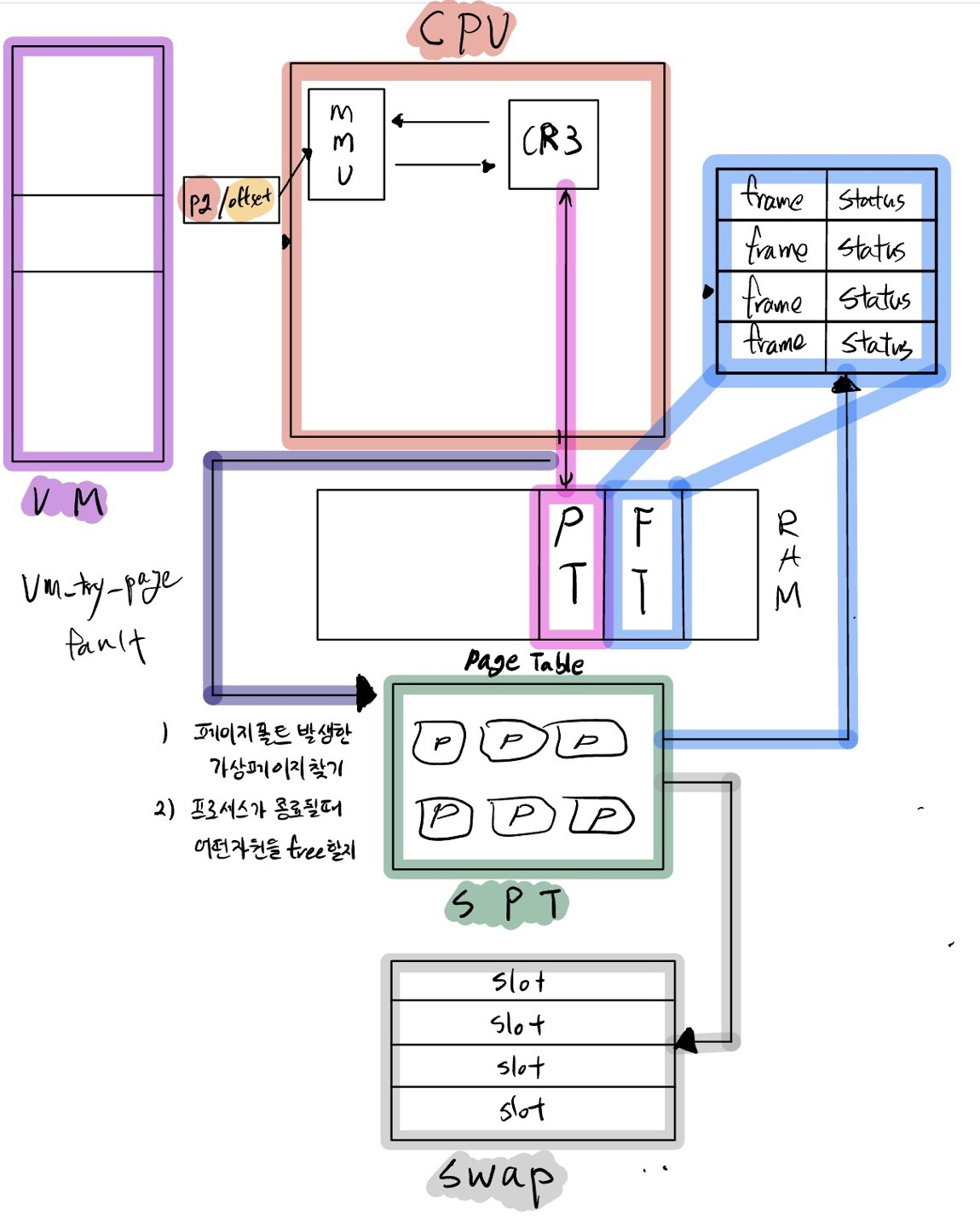
페이지 폴트란 프로그램이 자신의 주소 공간에는 존재하지만 시스템의 RAM에는 현재 없는 데이터나 코드에 접근 시도하였을 경우 발생하는 현상을 의미한다. 페이지 폴트가 발생하면 운영 체제는 그 데이터를 메모리로 가져와서 마치 페이지 폴트가 전혀 발생하지 않은 것처럼 프로그램이 계속적으로 작동하게 하여야 한다.
PintOS에서 CPU가 어떠한 데이터에 접근하고자 할 때 가상 메모리에 접근한다. 가상 메모리에 접근하여 해당 데이터가 위치한 가상 주소를 참조하고 해당 가상주소를 MMU를 통해 frame 주소로 변환된다.
MMU에서 변환하는 과정은 CR3레지스터에는 page table의 주소가 저장되어 있고 이를 통해 page table에 접근할 수 있다. 그러면 MMU는 page table을 통해 가상주소와 맵핑된 물리 메모리의 frame을 확인할 수 있다. 이때 가상메모리에는 존재하나 현재 물리메모리와 맵핑이 아직 되지 않은 경우가 있다.
#ifdef VM
/* For project 3 and later. */
if (vm_try_handle_fault (f, fault_addr, user, write, not_present))
return;
#endif이때 페이지 폴트 핸들러 함수 vm_try_handle_fault를 통해 Supplemetal Page Table에 접근해서 해당 페이지와 맵핑된 떼이터가 위치한 곳을 찾도록 구현해야 한다.
The most important user of the supplemental page table is the page fault handler. In project 2, a page fault always indicated a bug in the kernel or a user program. In project 3, this is no longer true. Now, a page fault might only indicate that the page must be brought in from a file or swap slot. You will have to implement a more sophisticated page fault handler to handle these cases. The page fault handler, which is
page_fault()inuserprog/exception.c, calls your page fault handler,vm_try_handle_fault()invm/vm.c.
보조 페이지 테이블을 사용하는 핵심 유저는 바로 페이지 폴트 핸들러입니다. 프로젝트 2에서는, 페이지 폴트는 항상 커널 또는 유저 프로그램의 버그를 의미했습니다. 하지만 프로젝트 3에서는 더 이상 아닙니다. 이제 페이지 폴트는 파일 또는 스왑 슬롯에서 페이지를 가져와야 한다는 사실을 의미하게 됩니다. 이러한 경우들을 다루기 위해서는, 더 복잡한 페이지 폴트 핸들러를 구현해야 할 것입니다. userprog/exception.c에 있는 페이지 폴트 핸들러 page_fault()는 vm/vm.c 에 있는 당신의 페이지 폴트 핸들러 vm_try_handle_fault() 를 호출합니다
이를 위해서 Supplemental Page Table을 만들고 구현해야 한다.
일단 구상한 것은 해당 자료구조에는 page와 연결된 frame을 저장해놓는 해쉬 테이블의 형태로 해봐야 겠다는 생각이다. 해쉬 테이블은 key를 가지고 있기 때문에 해당 가상주소에 해당하는 page의 frame이 NULL일 경우 page를 찾울 수 있게된다.
또한 프로세스가 종료되면 page안에 프로세스 종료 여부를 확인하는 변수를 선언하여 종료 여부를 갱신 및 저장하고, 리스트를 순회하면서 종료된 page들을 모두 free시키는 방식이다.
frame table이 가득차서 page fault가 발생하게 되면 해당 frame table에서 활용도가 떨어지는 frame을 확인하여 해당 frame과 맵핑되어 있는 page를 swap으로 이동시키는 것이다. 이게 pintos에서 말하는 swap out으로 보인다.
큰 그림을 그리면서 페이지 테이블과 TLB를 더 공부해 봤다.
페이지 테이블
페이지 테이블이랑 가상 페이지와 물리 페이지 사이의 맵핑 정보를 담은 테이블이다.
각 프로세스는 자신만의 페이지 테이블을 가진다. 어제 공부했던 페이징 방식에서 각 프로세스는 논리주소와 페이지 엔트리를 갖고 있다.
어떠한 프로세스가 물리 주소에 접근하고자 한다면 해당 프로세스가 가지고 있는 페이지 엔트리와 논리주소가 존재할 것이고 페이지 엔트리에는 해당 프로세스의 가상 주소페이지가 어떠한 물리주소 페이지와 맵핑되어 있는지 여부를 나타내고 맵핑되어 있다면 맵핑된 물리프레임의 주소가 저장되어 있을 것이다.
이를 통해 맵핑된 물리 프레임에 접근하게 되고 갖고 있는 논리주소는 맵핑된 물리프레임의 오프셋으로 활용되어 실제 물리 주소에 접근할 수 있게 된다.
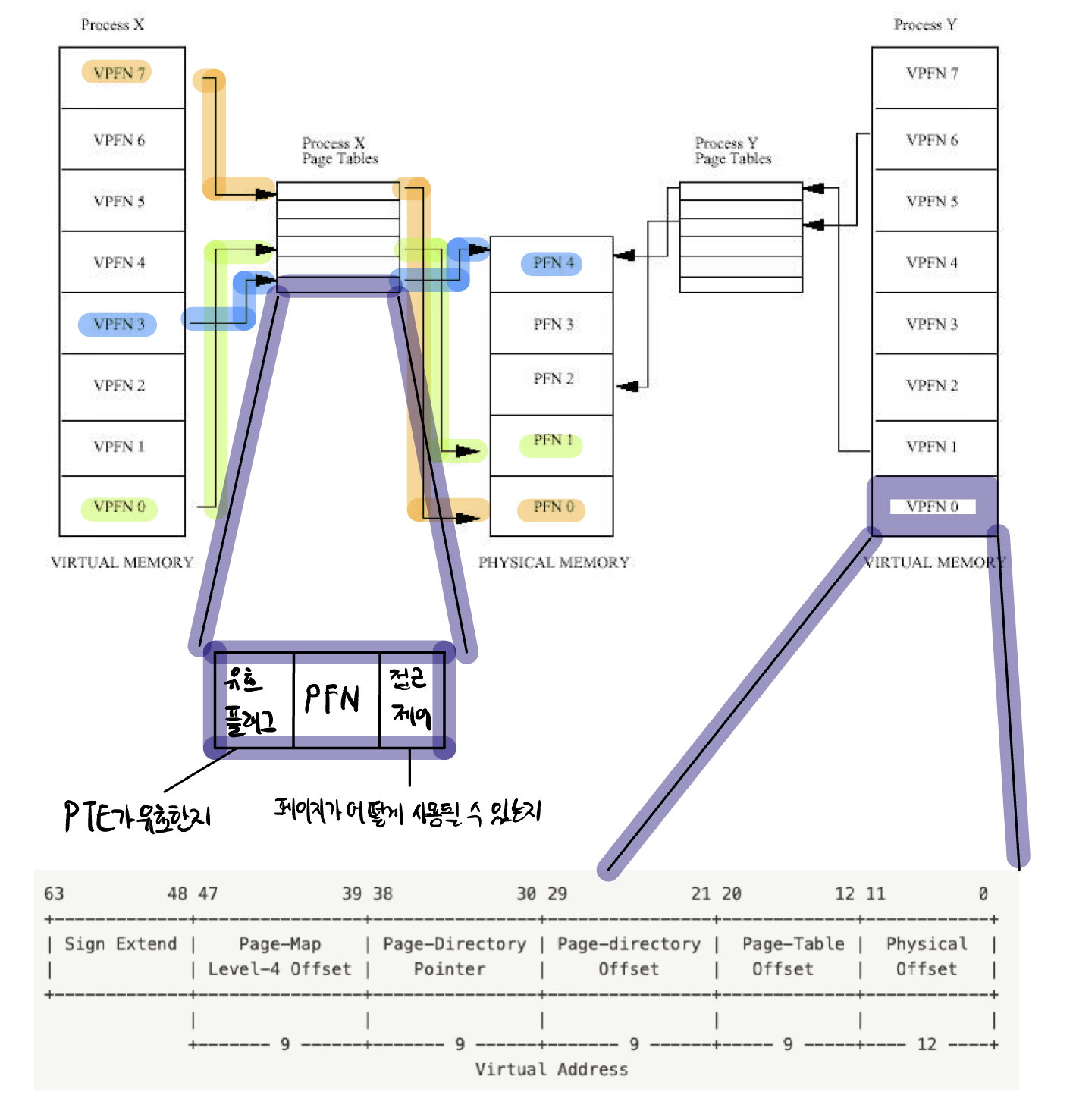
이 그림을 통해 가상메모리에서 물리 메모리로 어떻게 접근되는지 다시 한 번 정리해 보았다.
64비트 주소체계를 사용하는 경우 가상주소공간은 , 256테라바이트의 범위를 갖는다.
64비트 머신은 실제로는 , 16엑사바이트 만큼의 메모리 주소를 갖는다고 생각할 수 있지만 실제로는 48비트만 사용한다. 해당 크기 만큼 대규모의 메모리 어드레싱이 필요하지 않기 때문이다. 일단 지금은 그렇다.
-> https://stackoverflow.com/questions/6716946/why-do-x86-64-systems-have-only-a-48-bit-virtual-address-space
그래서 왜 페이지테이블을 계층적으로 써야하는건데?
보통 예시로 32비트 환경이 많이 나오는데 32비트의 주소체계로 보면 주소공간의 크기는 이다. 32비트 환경에서 페이지 하나의 크기는 4KB이고 이는 이다.
그러면 페이지 테이블의 엔트리의 개수는 이 된다. 32비트 환경에서 엔트리 1 = 1word = 32bit = 4byte이므로 실제로 항목당 4byte가 사용된다는 것을 의미한다.
그러면 개의 엔트리가 존재하므로 페이지 테이블의 용량은 4MB이다.
64비트 환경이면 어떻게 될까..
실제로 활용하는 주소공간의 크기로만 생각해도 이다. 64비트 환경에서도 페이지 하나의 크기는 4KB이므로 페이지 테이블의 엔트리의 개수는 이 된다. 64비트 환경에서 엔트리 1 = 1word = 8byte가 되므로 페이지 테이블의 용량은 =512GB가 될 것이다.
그러면 페이지 테이블당 무려 512GB가 연속적으로 필요하게 된다.
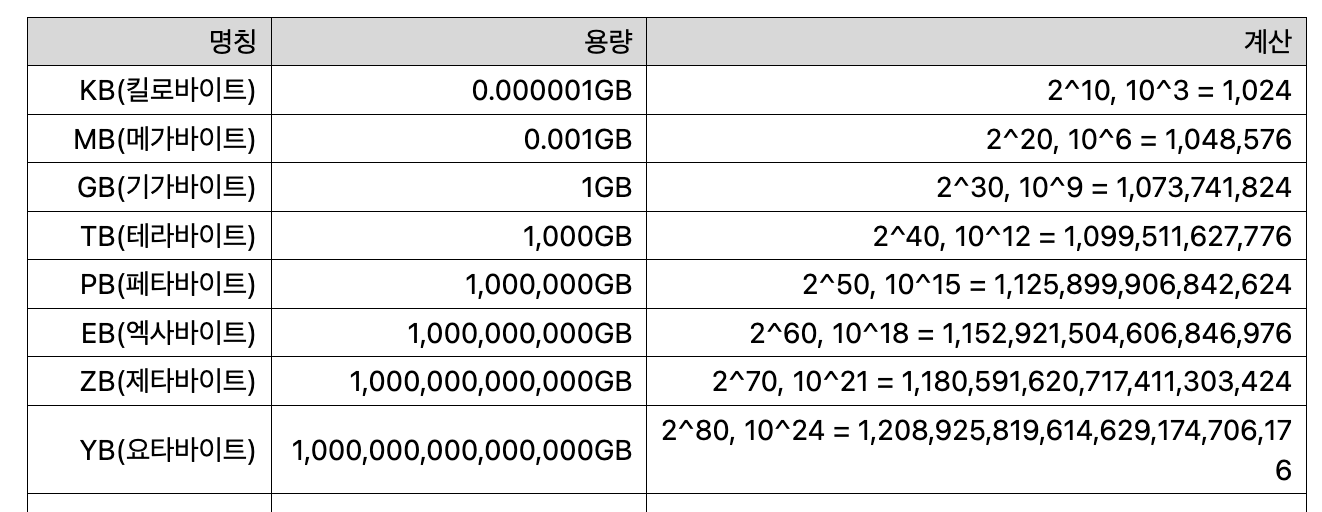
헷갈리지 말고 외우자…
페이징의 목적이 연속된 메모리에 공간을 할당하는 것을 방지하고자 페이지라는 일정한 크기로 분할하는 것이라고 생각했을 때, 오히려 페이징을 하는 목적과 부합하지 않는 문제가 발생한다.
또한 대부분의 프로그램이 주소공간 중 일부분만 사용하기 때문에 페이지테이블을 연속적으로 사용하는 것은 메모리의 낭비이다.
그래서 계층적 페이징 방식을 활용하는 것이다. 페이지 테이블을 논리적인 구조를 여러 개로 나누는 방식이다.
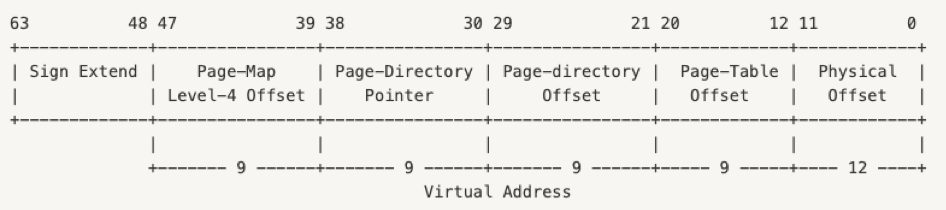
다시 돌아와서 페이지 테이블을 살펴보자. 카이스트 핀토스는 64비트 환경으로 4레벨 페이징 방식으로 페이지 테이블이 구성되어 있다. 이를 통해 각 페이지 테이블의 용량를 = 1KB 크기로 줄였다.
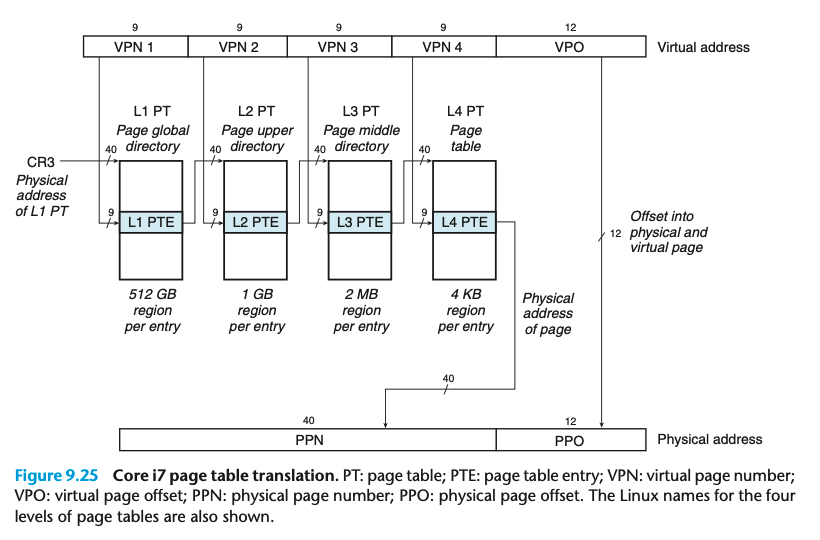
맨 처음 pml4의 테이블 (outer-page)의 시작주소로 접근하여 거기에 pml4의 값을 더해 해당 항목을 찾아가고 거기서 pdp(Page-Directory-Pointer)로 접근하고 거기에 pdp의 값을 더해 해당 페이지의 항목을 찾아가는 방식을 거쳐 마지막 Page-Table에서 해당 페이지에 해당되는 frame번호를 얻고 거기에 offset을 더해 최종 물리주소를 얻어내는 방식이다.
이를 통해 얻을 수 있는 이점은 다음과 같다.
- 연속된 페이지 테이블의 크기를 감소시킨다.
- 가장 바깥쪽에 있는 페이지 테이블(Outer page table)만 커널 메모리에 저장한다.
- 사용하지 않는 page table은 할당하지 않고 있다가 필요할 때만 할당할 수 있다.
사용하지 않는 page의 경우에만 pml4페이지 table을 할당하고 사용하는 outer page에만 하위 page table을 할당해 주면 되기 때문이다. 그렇게 하면 outer page table만 관리하여 주면 된다는 장점도 갖는다.
단점도 있다 이런 방식을 사용하면 한 번의 주소 바인딩을 위해 테이블을 4번 거치게 되므로 속도 부분에서 손해를 볼 수 있다.
4단계 페이지 테이블을 사용하는 경우
- 메모리 접근 시간이 100ns, TLB 접근 시간이 20ns
- 요청된 페이지에 대한 주소 변환 정보가 TLB에 존재할 확률 98%
- 평균 메모리 접근 시간 (EAT) = 0.98 x 120 + 0.02 x 520 = 128ns
- TLB hit이 성공할 때는 TLB 접근 시간과 메모리 접근 시간의 합인 120ns가 된다.
- TLB hit이 실패할 때는 TLB 접근 시간과 메모리 접근 시간 x 5의 합인 520ns이 된다.
- 결과적으로 주소 변환을 위해서만 28ns가 소요된다.
이를 위한 보완책으로 TLB가 존재한다.
TLB에 대해서도 간단하게 알아보았다.
앞에서 말한 계층형 page table 방식은 가상주소를 물리주소로 변환하는데 시간이 오래 걸린다.
따라서 더욱 빠르게 메모리 변환을 하기위해 TLB가 존재한다. TLB는 하드웨어에 위치하면 일종의 주소 캐쉬 역할을 한다.
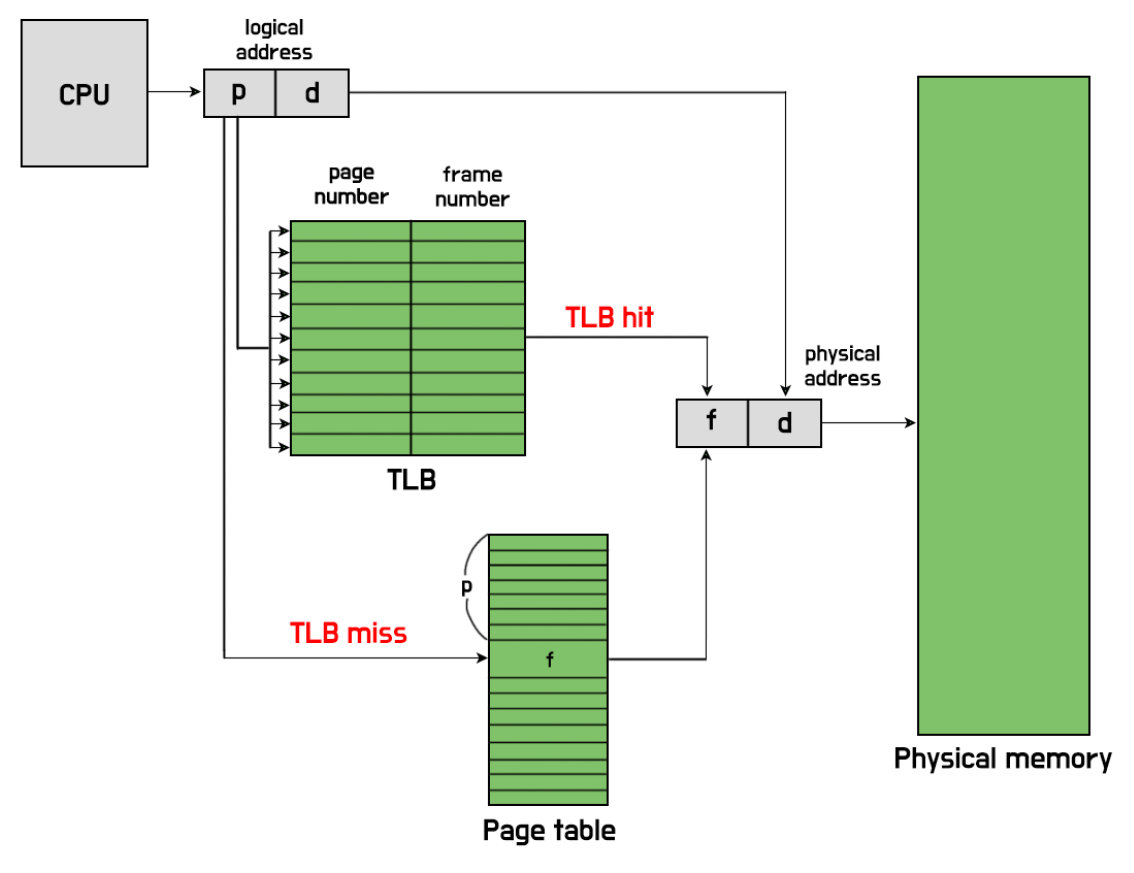
앞서 말한대로 TLB에는 vpn과 vpn에 맵핑되는 pfn을 갖고 있기 때문에 vpn이 TLB에 위치하면 page table을 뒤지지 않아도 바로 pfn을 알 수 있다.
TLB에 있는 경우를 TLB hit, 없으면 TLB miss라고 한다.
