파이썬을 통해 웹스크래핑을 공부하던 중이었다.
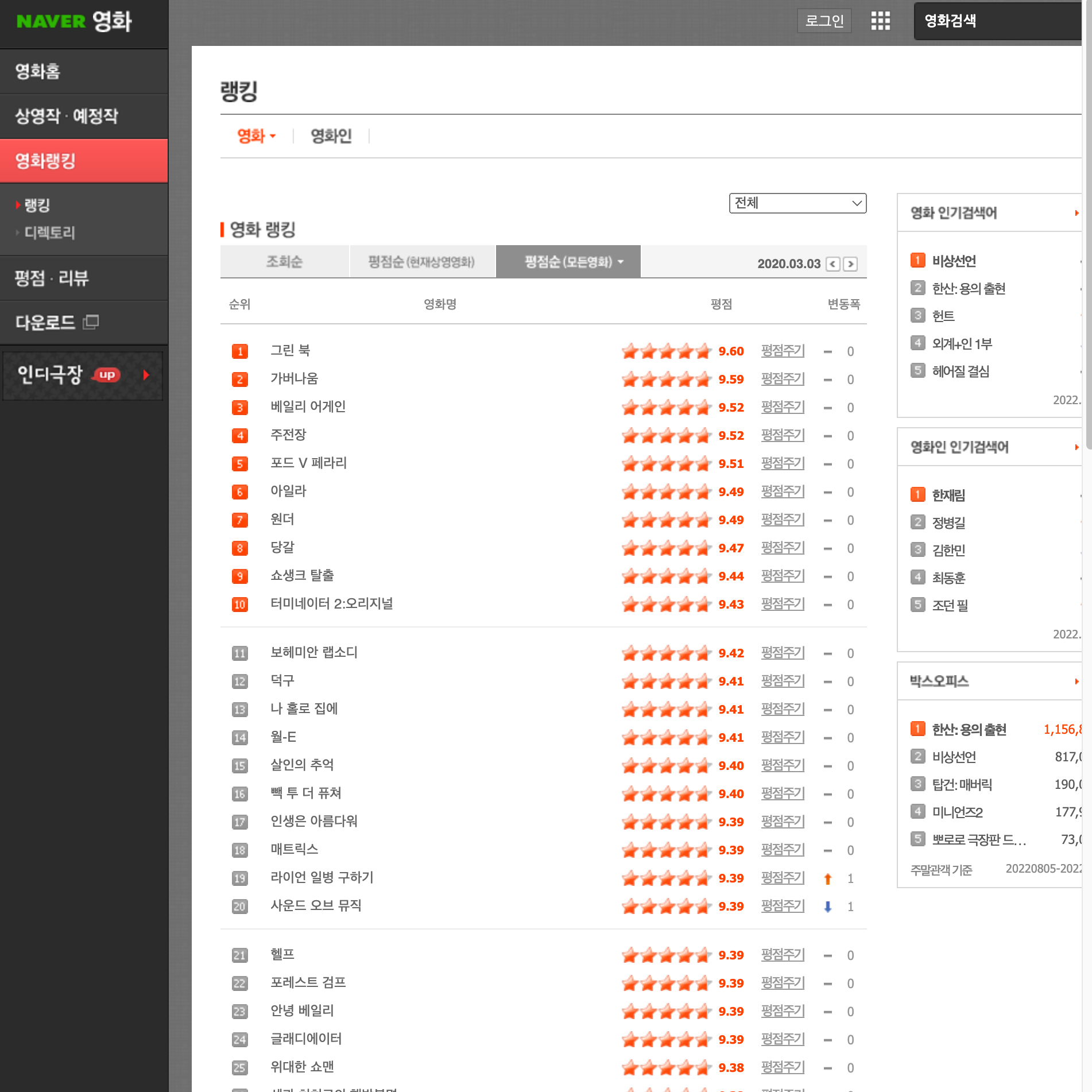
해당 영화의 순위들을 스크래핑하는 것이 목표.
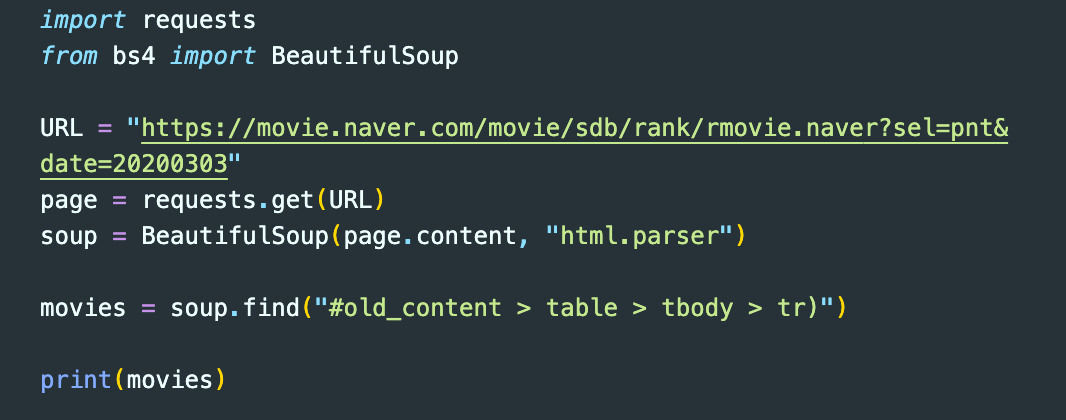
그래서 일단 beautifulsoup library를 활용해서 웹페이지를 추출하고 영화 정보들만 추출하기 위해서 해당 경로를 movies라는 변수에 담고, 이를 확인해보려니,

오잉 왜 아무값이 안나오지?
구글링을 해보니 select()를 활용하란다
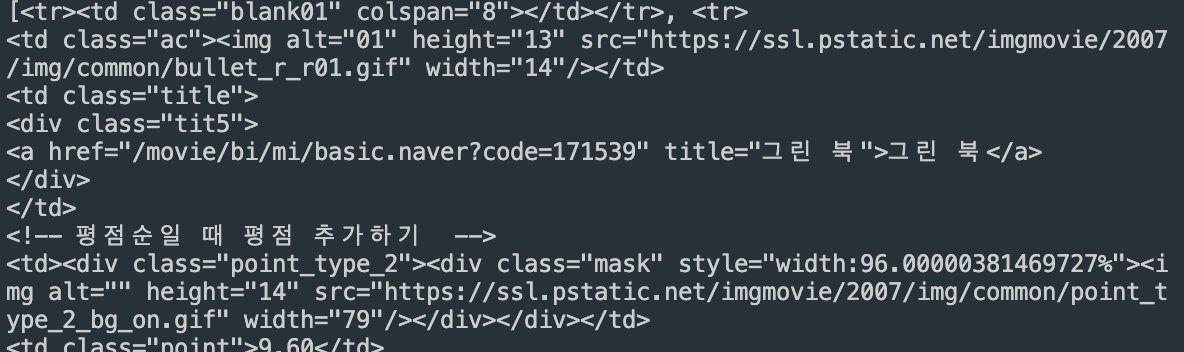
select로 바꿔보니 잘된다.. 음 그러면 find()와 select()가 서로 다른 역할을 하고 있는거니까 다른 결과가 나타난 것일텐데
그 이유가 무엇일까?
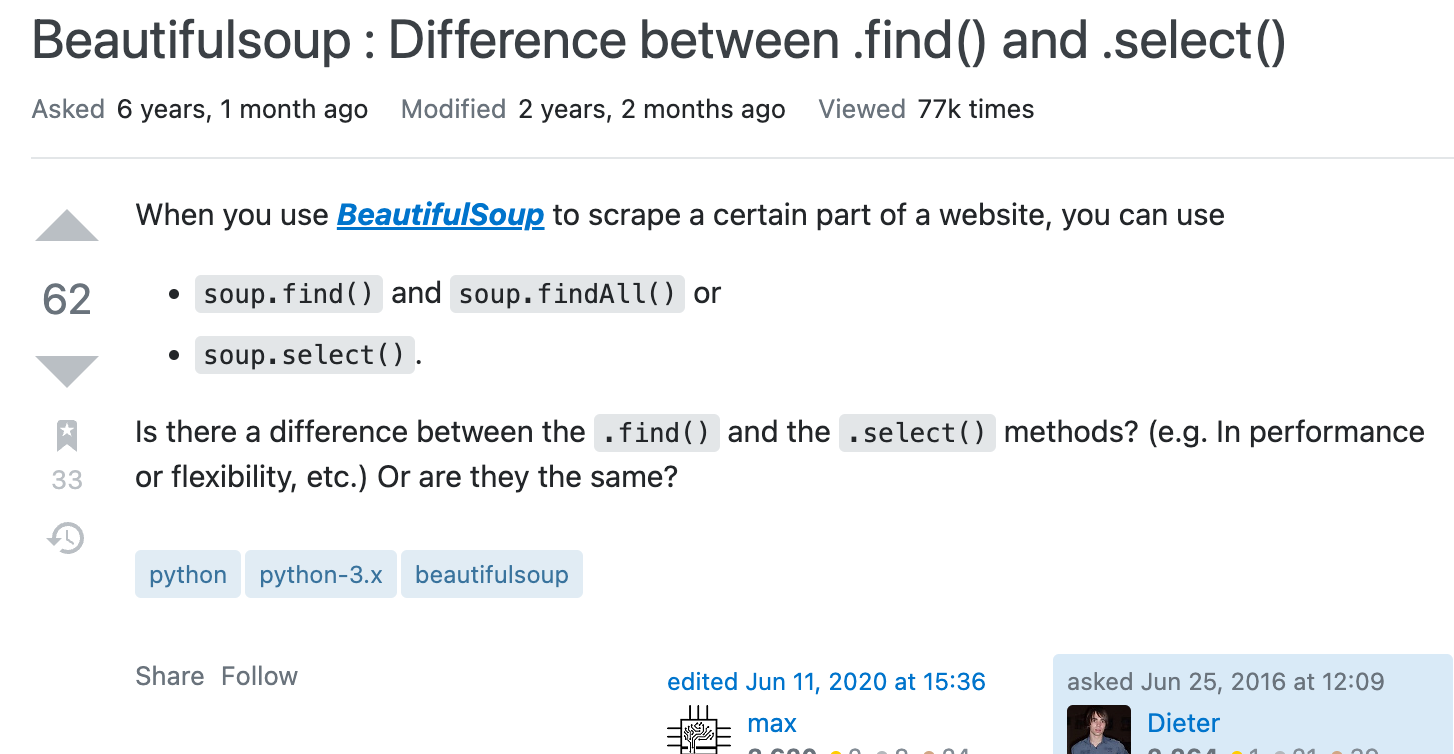
(출처 :https://stackoverflow.com/questions/38028384/beautifulsoup-difference-between-find-and-select)
(대충 해석: 웹페이지의 특정 부분을 스크래핑하기 위해서 BS의 find와 select메소드를 모두 활용할 수 있는데 이거의 차이가 뭐임? 아니면 둘다 같은거임?)
우리의 Dieter 형님도 나와 같은 궁금증을 가지고 계셨나보다.
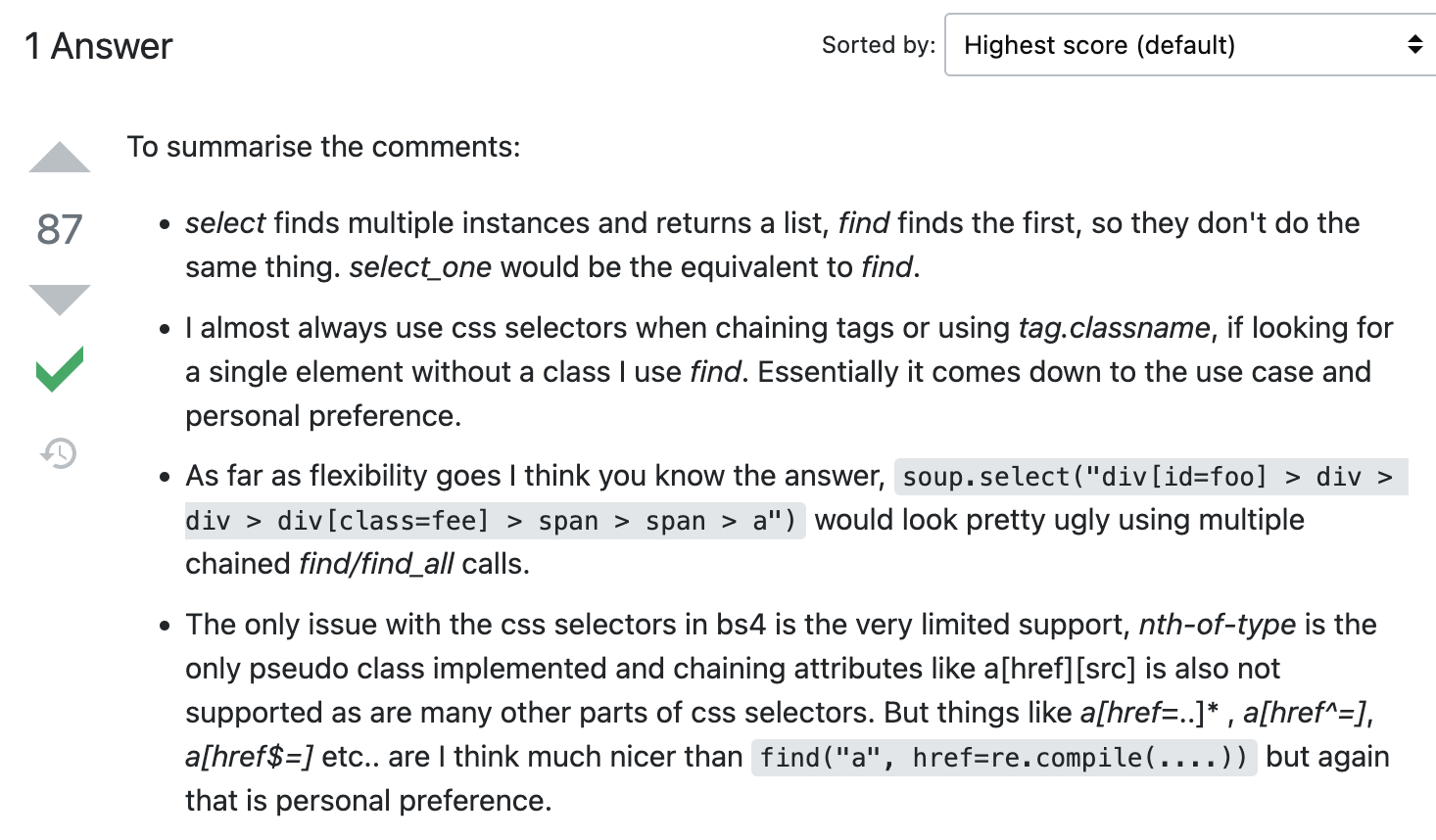
영어, 파이썬 지식이 모두 일천한 상황이기 때문에.. 내가 일단 이해할 수 있는 수준만 이해해보자
일단 select의 경우 만족 여러개의 instance들을 담을수 있고 그것들을 목록화하여 반환할 수 있지만
find는 맨 처음 인스턴스만 찾는다고 한다.
movies = soup.select("#old_content > table > tbody > tr")select는 이렇게 여러개로 태그를 담을 수 있지만,
find가 select를 구현하려면 여러면 실행해야 할 것이다.(위 코드같이 하려면 4번..?)
각자의 취향이나 코드의 작성에 따라 차이가 있겠으나,
개인적으로는 select가 보다 더 직관적으로 느껴지기에 웹스크래핑을 할 때에는 해당 메소드를 주로 활용할 듯 하다.
