
안녕하세요
오늘은 온라인 인과추론 스터디에서 발표한
"분산 추정 및 민감도 개선 : 함정 및 해결책" Chapter에 대한 내용을 소개하려고 합니다.
인과추론 스터디가 어떤건지 궁금하신 분은 위 페이지를 참고하시면 됩니다.

여기서 함께 공부하는 책은 A/B테스트 신뢰할 수 있는 온라인 종합 대조 실험 책 입니다.
발표한 부분은 Chapter 18. 분산 추정 및 민감도 개선 부분입니다.
이외 chapter가 궁금하신 분들은 스터디 github을 참고하시길 바랍니다.
https://github.com/CausalInferenceLab
이번 글은 책과 함께 보셔야 좀더 재밌게 읽을 수 있습니다.
(tmi) 꽁꽁 얼어붙은 발표 분위기 고양이 넣기

제 발표 첫 페이지 분산 추정에 대해 요즘 핫한 고양이를 넣어보았었습니다.
(발표때 상상) 우리 조용한 이 꽁꽁 얼어붙은 분위기를 분산시키기 위해 고양이를 넣어보았습니다.
라고 회심의 일격을 준비했지만 ...
(현실) 분산 추정 및 민감도 개선 함정 및 해결책에 대해 발표하겠습니다.
조용한 발표 분위기를 환기시키진 못했습니다.
분산 추정 및 민감도 개선 : 함정 및 해결책
위 챕터에서는 크게 2가지 관점을 이야기 합니다.
1) 분산을 정확하게 추정하는 것 (일반적 함정)
2) 통계적 가설 검정의 민감도를 얻기 위해 분산을 줄이는 방법
책에서는 분산을 실험 분석의 "핵심" 이라고 말합니다.
그만큼 분산을 정확하게 추정하고, 민감도를 위해 분산을 줄이는 것은 실험에서 중요한 것을 강조합니다.

본론에 들어가기 전, 이런 글이 써있습니다.
분산을 잘못 추정하면 p값과 신뢰구간이 잘못돼 가설 검정의 결론에 오류가 발생한다.
->크게 추정하면 거짓 음성
->과소 추정하면 거짓 양성에 가깝다는 이야기를 합니다
위 이야기는 분산이 과대 추정되면 -> 표준 오차 값 또한 과대 추정 되고, -> t통계량의 절대값을 감소시킵니다.

그렇게 되면 p 값이 증가되면서 임계값을 넘기 어려워지고 (0.05) 잘못 채택될 확률로 이어집니다 (type2 에러 즉, 거짓 음성)
분산을 실제보다 과소 추정하면 -> 표준 편차가 실제보다 작아지고 -> t통계량의 절대값이 증가됩니다. -> 이는 즉 p값이 감소되고 기각확률을 높이게 되어 차이가 없지만 있다고 결론이 나올 수 있습니다 (type1에러 , 거짓음성)
분산을 잘 추정하자 : (델타 vs 델타 %)
여기서 저자는 처음으로 실험 결과 보고에서 우리는 상대적 차이를 사용한다 말을 많이 한다.
yc (대조군) : 평균 10
yt (실험군) : 평균 10.01
실험군이 대조군보다 0.01 늘었어요 (0.01/10)*100 = 1% 늘었습니다!!! (대박)
하지만, 이렇게 구할 시 올바른 추정이 아니다.
왜냐! 모든 대조군 값이 10인것도 아닌데 10으로 나누는것은 모든 값을 10으로 가정한것이기 때문이다. 따라서 분모에도 분산의 영향도를 주어야 합니다.
10으로 나누면 대조군의 분산을 무시해버린것입니다...
(0.01 / yc의 분산) *100% = 으로 늘었습니다 (대박!)
분산을 잘 추정하자 : 분석단위 & 실험단위 다른경우
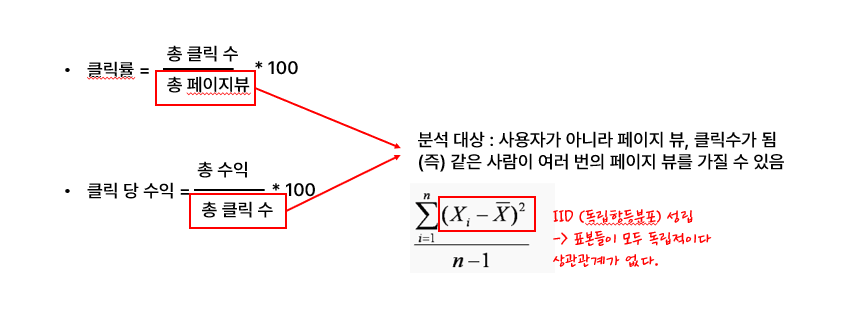
위 부분에서는 클릭률을 예시로 들면서 저자는 이야기를 시작한다.
클릭률의 경우는 총 클릭수 / 총 페이지 뷰 *100 인데,
실제 사용자가 아니라 총 페이지 , 클릭수가 집계 대상이 되면서 같은 사람이 여러번 페이지 뷰를 가질 수 있습니다.
이는 우리가 알고 있는 독립 항등분포(iid) 성립이 불가능하다
나라는 사람이 여러번 페이지 방문을 하면 상관관계가 생길 수 있기 때문이다.
따라서 사용자 수준의 지표의 평균으로 변경을 권장하는 편이다.

여기서 M이 무엇인가!? -> M은 앞서 페이지에서 나온 클릭수/총수익을 의미하고,
이를 델타 방법을 사용해서 분산 추정을 진행한 내용입니다.
(사실 위 부분은 완전한 이해가 아직 부족하여 5월에 좀더 자세히 기록해보겠다 (__) 양해점)
여기서 사용자 수준 지표의 비율로 기록할 수 없는 지표는 (델타 방법 못쓴다고? 그러면 부트스트랩 써봐) 부트 스트랩 방법 사용을 권장하는 편입니다.
*부트스트랩은 아시다 싶이 데이터 세트에서 반복적으로 샘플을 뽑아서 원하는 통계치를 계산하는 방법입니다. 비용이 크다는 단점이 있다.
분산을 잘 추정하자 : 이상치 조심해 ∠(・`_´・ )
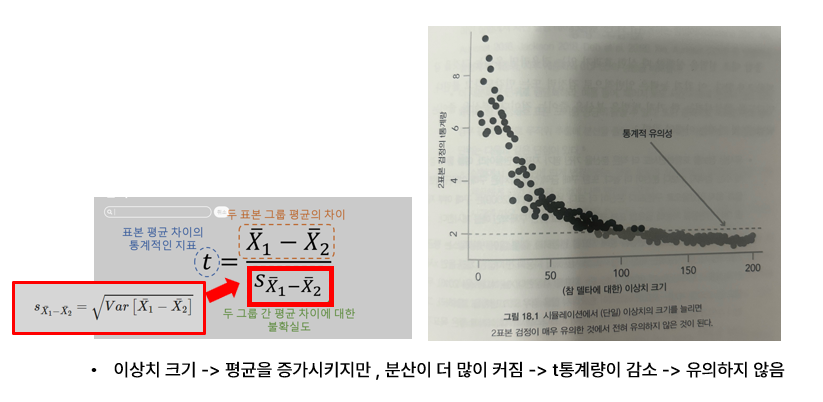
이상치의 경우에는 온라인 실험에서는 페이지 뷰에서 봇, 스팸행위로 인해 이상치들이 만들어질 수 있습니다. 이러한 이상치의 크기가 커질 수록 평균을 증가시키지만, 분산이 더 많이 커지면서 t 통계량이 자연스럽게 감소되고 유의하지 않은 단계로 가게됩니다.
분산을 줄이자 : 민감도를 향상시키자.
마지막으로 민감도를 향상시키는 다양한 방법들을 책에서 소개한다.
민감도 라는 것은 실제로 양성인 케이스를 양성으로 정확하게 판단하는 능력을 나타낸다.
분산을 줄이는 것이 곧 민감도를 향상키실 수 있기 때문에 다양한 방법들을 소개한다
유사한 정보를 포함하지만, 적은 분산을 가진 지표를 만들자.
좀더 분산이 적은 지표로 변경하는 방법이다.
예를들면 검색 수보단 검색자 수 , 구매금액 보단 구매여부와 같은 지표로 분산을 줄일 수 있다.
이진화, 로그 변환을 통한 지표를 변환
스트리밍 시간을 측정하는 것을 스트리밍 여부 ( 스트리밍O , X) 와 같이 이진화 해서 나타낸다던지, 로그 변환을 해서 전반적인 분산을 줄일 수 있다.
트리거 분석을 사용하기
트리거 분석은 명확한 기준ㅇㄹ 설정해서, 관련 없는 데이터 정보의 영향을 최소화 시킬 수 있다.
EX) 온라인 실험에서는 예를들어 상품 구매에 있어서 구매 단계에서 결제 창에서 카드 선택에서 디자인 A,B를 테스트해볼때 주문 페이지를 트리거로 했을때 주문 페이지에 접근한 유저 대상만 그때무터 트리거 대상이 됩니다.
변수의 영향을 받지 않는 사람들에 의해 발생하는 노이즈를 제거하기에 좋습니다.
계층화, 통제변수, CUPED 사용
계층화의 경우는 플랫폼 , 브라우저 유형 요일과 같이 샘플링을 하는 느낌
통제 변수 : 실험에서 분선에서 고정, 통제되는 변수를 사용
CUPED : 사전 실험 데이터를 기반으로 실험 후 결과 분산을 줄이는 방식입니다.
EX) 이전 처리 전 결과를 분석해서 변동성을 제거하고, 효과에 대한 내용을 좀더 정확하게 추론합니다.
세분화 된 단위로 랜덤화
검색어 지표와 같은 경우 , 검색어 별로 무작위 추출을 통해 분산을 줄일 수 있습니다.
쌍으로 묶인 실험을 설계하기
동일한 사용자에게 실험군, 대조군의 모든 것들을 제공하는 기법입니다.
(변동효과를 제거하고 분산을 작게 만드는 것입니다)
교차 배포 라고도 하는데, 그룹을 교체해서 한 그룹이 A,B 모든 것들을 보게 하는 것입니다.
대조 집단을 통합하라
아마 대조 집단을 통합하라는 것은 샘플 사이즈가 증가되니까 변동성이 감소되고, 표본의 대표성이 증가되어 통합하는 것을 의미합니다. (하지만 위험성이 있는 기법이라고 생각합니다. 다양한 실험을 하지 못하거나 실험 기간이 다르게 되면 다음 실험에 영향을 미칠 수 있습니다)
이렇게 해서 분산 추정에 대한 발표 내용을 공유드렸습니다.
여러분들의 실무에서 분산을 줄이고, 추정의 중요성을 느낀 사례가 있으시다면 편하게 공유 주세요!

스터디에서 내가 모르는 사례나 이외 확신이 안드는 개념들에 대해 내용을 함께 나눌 수 있어서 좋았습니다. 금주에 스터디 발표가 2개나 있어서 조금 힘들긴 했습니다.. ㅎㅎ
하지만 생각해보면 5월이 가기 전 스터디 공부를 한번 정리하고 싶었고,
발표 준비도 같이 할 수 있었고, 어려운 부분을 맡게 되어서 좀더 통계 지식들의 정리를 해야겠다 라는 결심이 든 순간이어서 너무 좋았습니다 ㅎㅎ
ヾ(ゝω・)ノ 5월도 화이팅 ヾ(ゝω・)ノ
