
isolation이 안될 때 나타날 수 있는 여러 현상들
다중 사용자 데이터베이스 환경에서 여러 트랜잭션이 동시에 실행될 때, 서로 다른 트랜잭션 간의 간섭으로 인해 이상 현상이 발생할 수있다. 동시성 제어는 트랜잭션이 올바르게 실행되고 데이터베이스의 무결성을 유지하는데 필수적이다.
그렇게 하기 위해서는 이상 현상에 대해서 파악하고 있어야 한다.
지금부터 이상 현상들에 대해서 알아보도록 하자.
1. Dirty read
트랜잭션B가 데이터를 변경(write)하고 커밋하지 않은 시점에서, 트랜잭션 A가 변경된 데이터를 읽어오는 것을 말한다.
이 때, 트랜잭션B에 이슈가 발생하여 변경된 데이터를 커밋하지 않고 롤백하는 상황에서 문제가 된다.
아래 그림을 살펴보자.
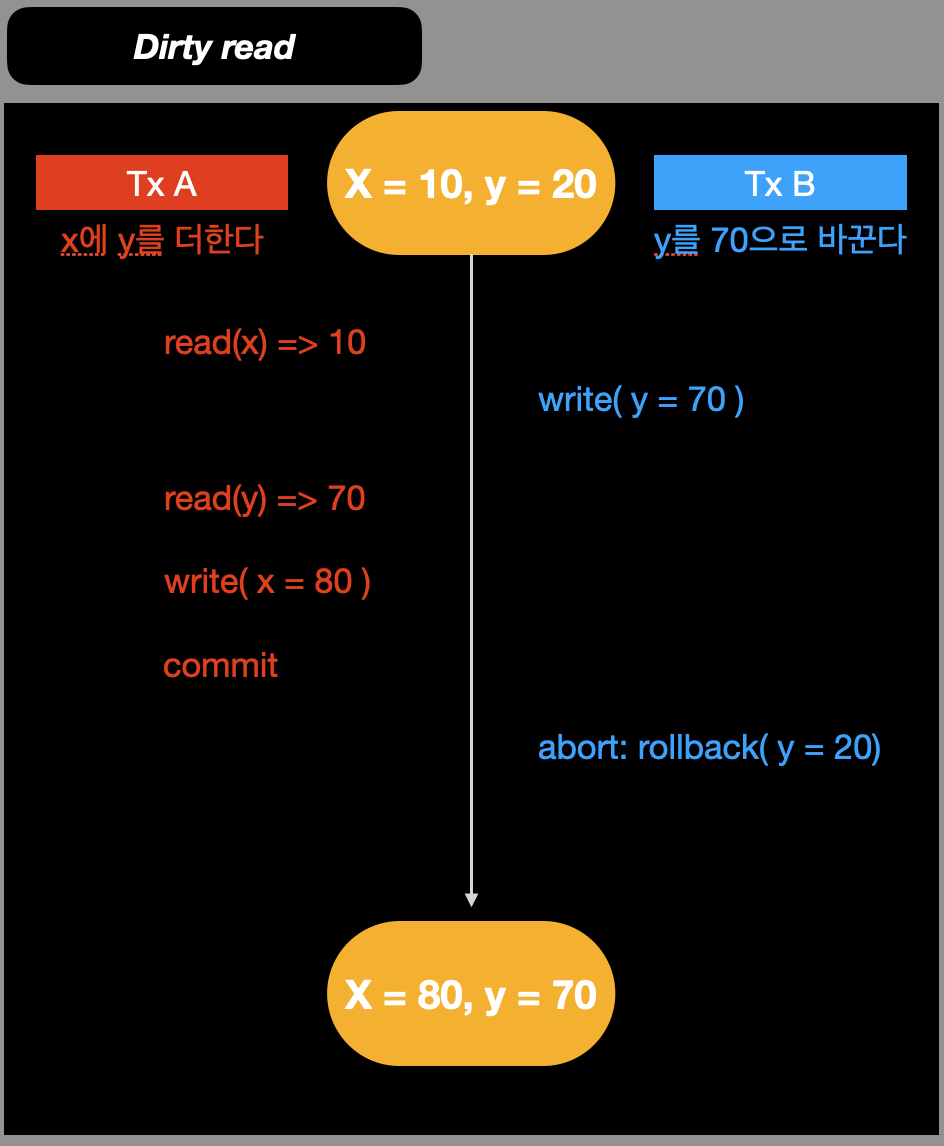
- tx-A가 실행되기 위해 read(x)
- tx-B를 실행하기 위해 write(y)
- x에 y를 더하기 위해 tx-A의 read(y) => 70 (3번이 dirty read가 된다)
- x = x+y 값을 적용하기 위해 tx-A의 wirte(x) 후 commit
- tx-B에서 문제가 발생하여 y가 초기값인 20으로 rollback
rollback으로 y=70이라는 데이터는 유효하지 않은 데이터가 되었으므로,
그 데이터를 읽어 나온 결과인 x=80도 유효하지 않은 데이터가 된다.
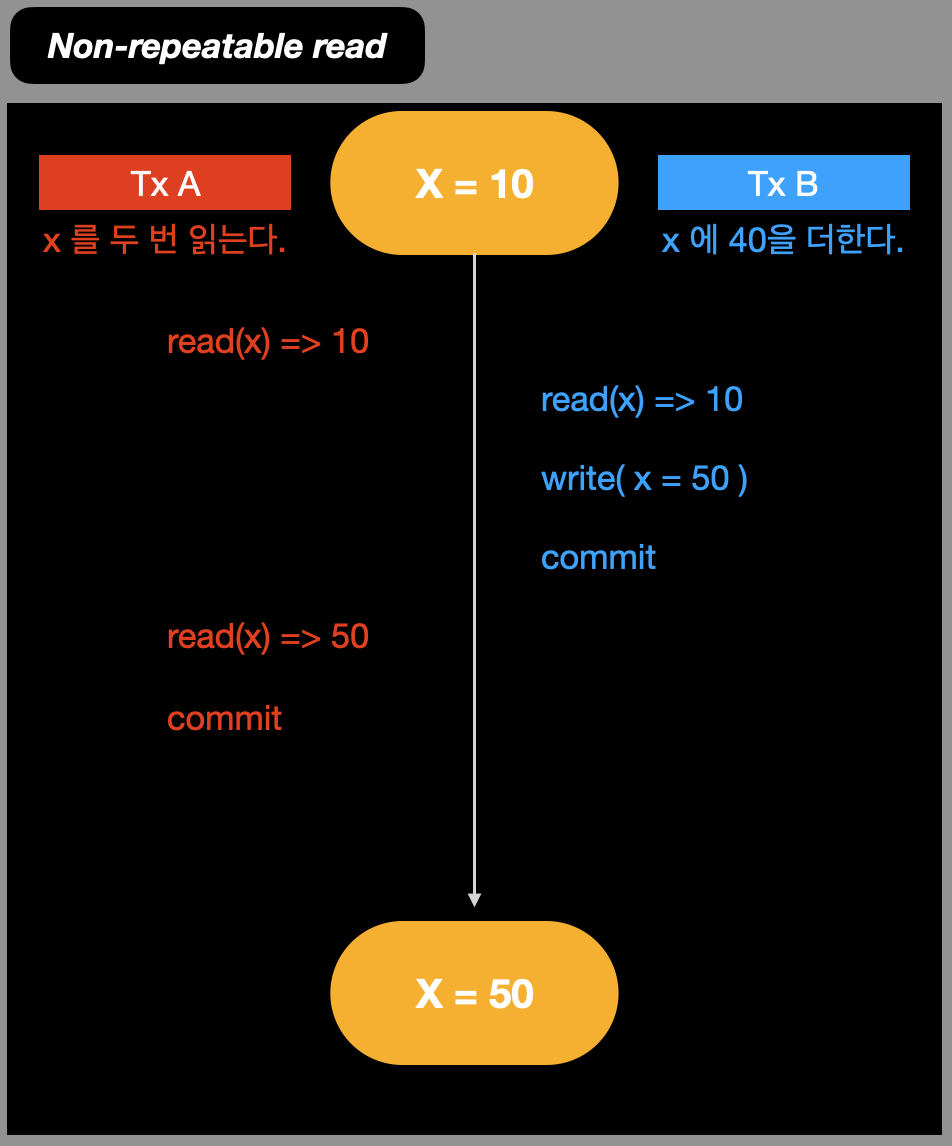
2. Non-repeatable read
하나의 트랜잭션 내에서 같은 데이터를 같은 조건으로 여러번 조회 했을때, 서로 다른 데이터를 가져오는 것을 말한다.
이는 isolation 관점에서 보면 일어나면 안되는 현상이다.
isolation 속성의 의미는 '여러 트랜잭션이 동시에 실행되어도, 각각의 트랜잭션은 독립적으로 실행되야한다.' 이기 때문.
3. Phantom read
하나의 트랜잭션 내에서 같은 조회 쿼리를 두 번 실행했을 때,
첫번째 조회 결과에서 없던 레코드가 생성되거나 있었던 레코드가 없어지는 것을 말한다.
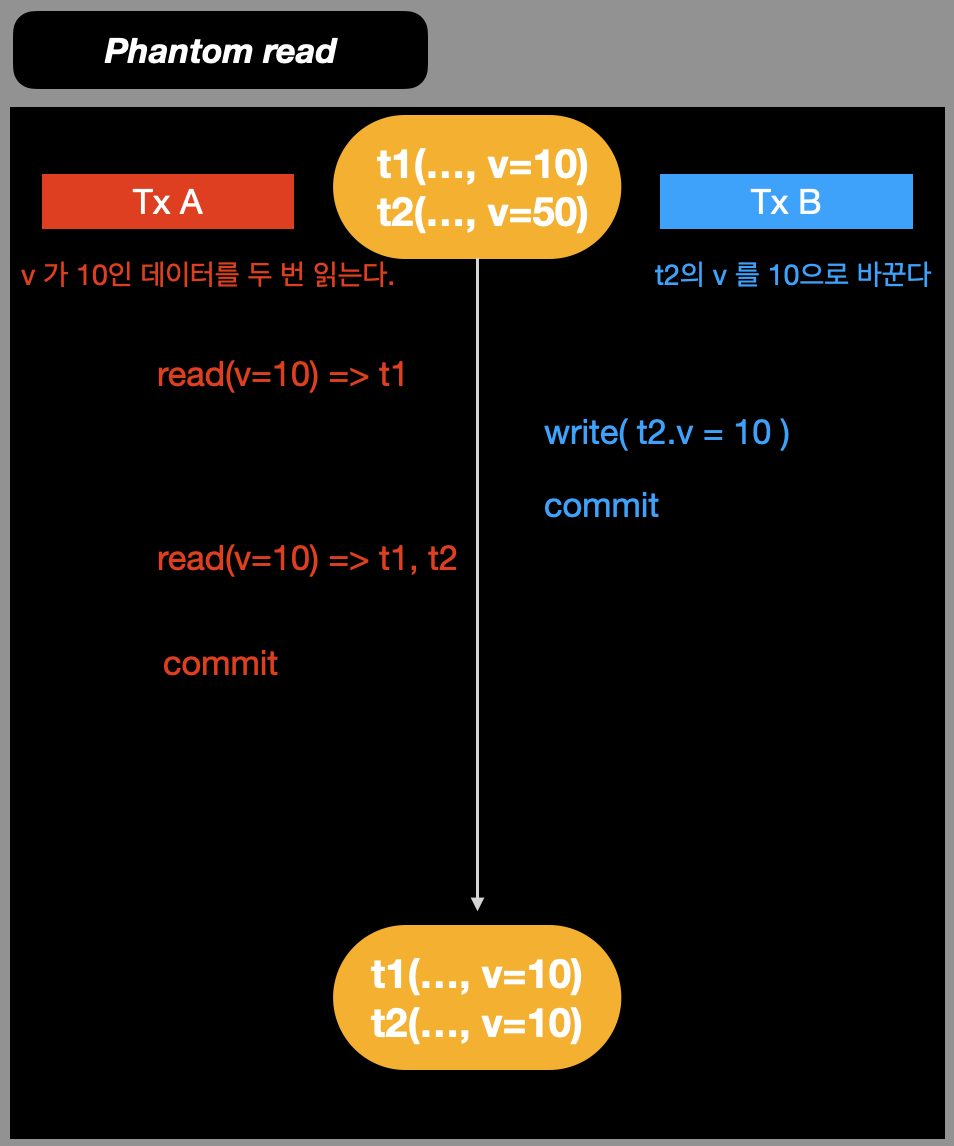
- tx-A에서 v=10인 데이터를 read(v=10) (t1만 조회)
- tx-B에서 t2.v를 10으로 바꾸기 위해 write(t2.v=10) 후, commit
- tx-A에서 두번째로 v=10인 데이터를 read(v=10) 후 commit (t1, t2 조회)
Tx-B에 의해서 Tx-A의 처음 조회와, 두번째 조회의 결과가 달라졌다.
Non-repeatable read 와 Phantom read의 차이점은 무엇일까?
- Non Repeatable Read은
하나의 레코드의 값이 한 트랜잭션 내에서 다르게 조회될 수 있음을 말한다.- Phantom read
하나의 트랜잭션 내에서 조회 쿼리 결과의 레코드의 수가 달라질 수 있음을 말한다.
Isolation level
이상 현상들을 모두 발생하지 않게 만들 수 있지만, 그렇게 하기엔 제약사항이 너무 많아져서 동시 처리 가능한 트랜잭션 수가 줄어들게 된다. 결국 DB의 전체 처리량이 하락하게 된다.(perfomance 하락)
때문에 일부 이상 현상은 허용하는 몇 가지 level을 만들어서 사용자가 필요에 따라서 적절하게 선택할 수 있도록 하자.
바로 이 아이디어가 Isolation level 이다.

- Read uncommitted는 데이터 처리량은 가장 높지만, 자유도가 높아 안정성이 낮다.
- Read committed는 대부분의 DBMS에서 default로 사용되고 있는 isolation level이다.
- Serializable은 이상현상이 아예 일어나지 않는 수준으로, 거의 사용되지는 않는다.
- isolation level이 엄격해 질수록 동시성은 줄어들어, 트랜잭션 처리량이 가장 낮다.
- 어플리케이션 설계자는 isolation level을 통해 전체 처리량과 데이터 일관성 사이에서어느 정도 거래를 할 수 있다
즉 데이터 처리량과 데이터 일관성은 서로 trade-off 관계에 있다.
이외의 이상 현상에는 다음 4가지가 추가적으로 더 존재한다.
- Dirty write
- Lost update
- Read skew
- Write skew
또한 isolation level중 snapshot level도 존재하는데 이는 다음에 따로 정리해보도록 하겠다.
