하둡을 배워야하는 이유는?
- 데이터 홍수의 시대
우리는 데이터 홍수의 시대에 살고 있으며, 하둡은 비정형 데이터를 포함한 빅데이터를 다루기 위한 가장 적절한 플랫폼이다. - 글로벌 하둡 마켓의 성장
- 하둡 엔지니어의 수요 증가
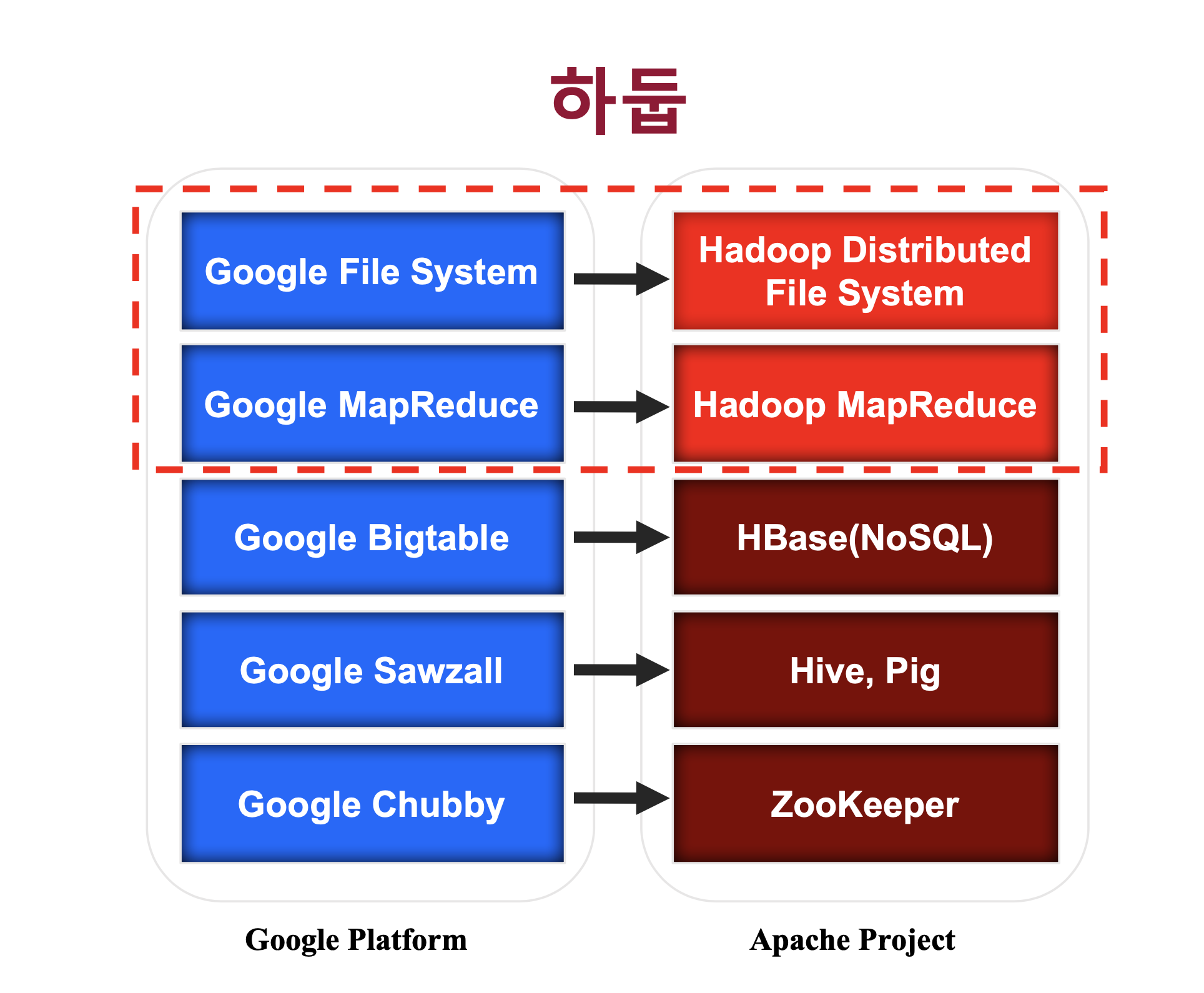
하둡은 소프트웨어 플랫폼이다. 하둡은 특정 모듈 보다는 데이터처리 플랫폼 전체를 뜻한다. 에코시스템은 하둡 핵심 기능을 보완하는 서브 오픈 소스 소프트웨어들이다. 하둡이란 플랫폼상에 다양한 에코시스템인 Pig, Zookeeper, Hive, Flume, Scoop, Spark 등 수 많은 오픈소스 기술이 하둡 플랫폼과 함께 사용된다. 하지만 단지 소프트웨어만 안다고해서 하둡을 잘 할 수 있는 것이 아니라 SA들도 TA영역을 잘 알 필요가 있다. 하둡은 3.0 버전까지 나왔으며 꽤 성숙된 소프트웨어이다.
- SA : Solutions Architect
- TA : Technical Architect
-
Hive
하둡의 분산파일 시스템에 저장된 정보를 SQL과 비슷하게 처리할 수 있다. -
Scoop
여전히 관계형 데이터베이스는 기업 내에서 자주 사용된다. 관계형 데이터베이스와 하둡 간의 데이터를 주고받을 수 있는 과정을 쉽게 할 수 있도록 만든 프레임워크이다.
하둡 생태계의 진화
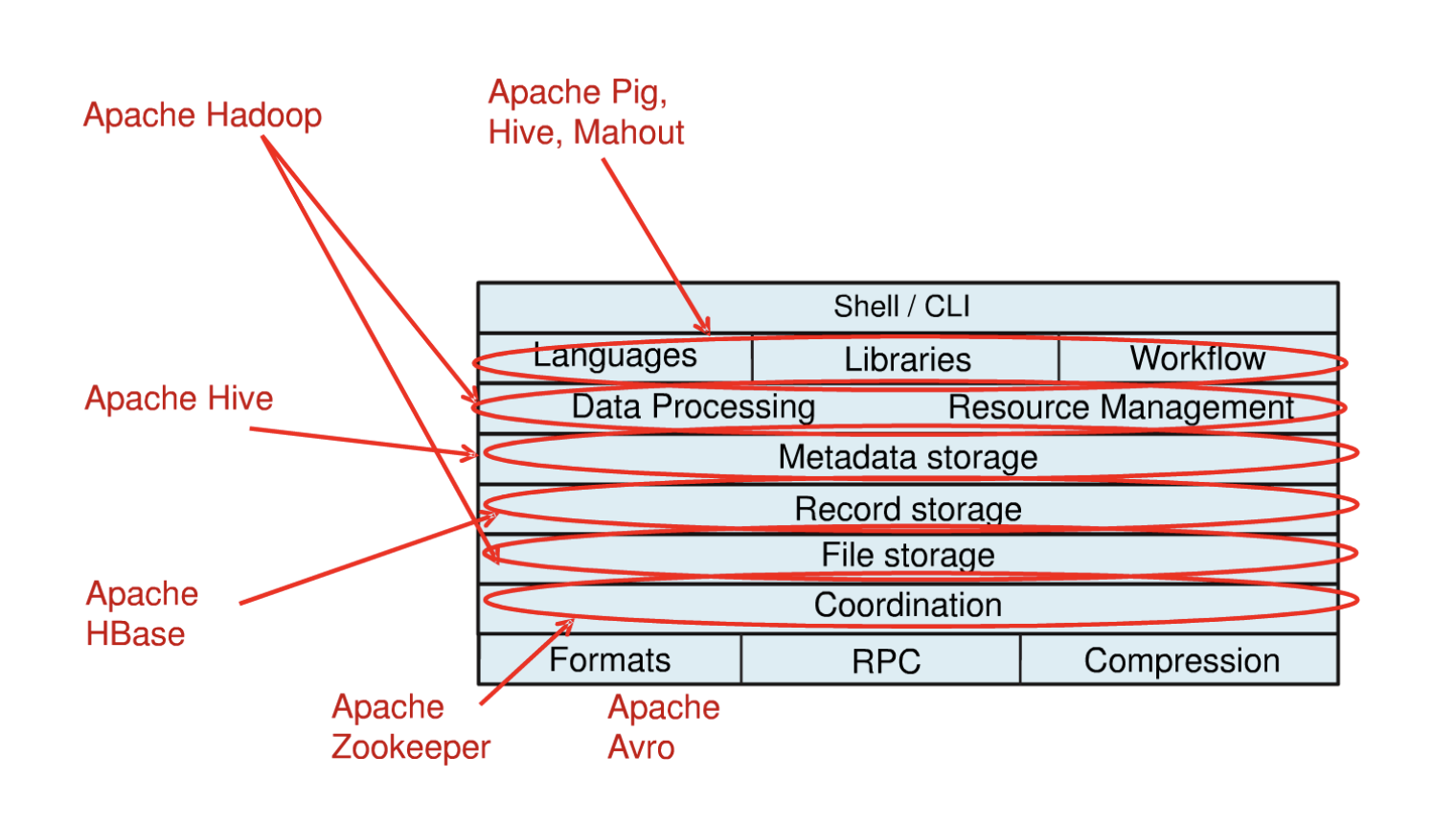
기술적인 레이어로 정리하면 위의 사진과 같다. 기본적으로 하둡은 데이터를 저장하고 프로세싱하는 영역이다. 저장하고 프로세싱할 때 여러 컴퓨팅 리소스들을 분산처리하기 때문에 리소스 매니지먼트를 하는 부분이 필요하다. 이를 내장하고 있는게 하둡이다.
Hive는 기본적으로 저장되어있는 메타스토어를 참조해서 쿼리를 던진다. ( 메타스토어는 별도로 있다 )
Apache Hbase는 분산 데이터베이스이다. Zookeeper가 코디네이터 역할을 하고, Avro가 데이터를 송수신할 때 시리얼라이제이션이나 디시리얼라이제이션을 하는 프레임워크다. 서버와 클라이언트 프로그래밍을 할 때 경량 어플리케이션으로 구성을 할 수 있는 프레임워크로 사용되기도 한다.
점점 프로젝트들이 세분화되면서 하둡의 에코 시스템들은 지속적으로 발전하고 있다.
하둡 덕분에 이제는 더 이상 많은 데이터를 저장하기 위해 큰 비용이 들지 않는다.
데이터로부터 새로운 인사이트를 찾아서 사업기회를 만든다.
저렴한 물건들 마저 똑똑해지고, 네트웍을 품기 시작했다.
하둡과 같은 오픈소스 빅데이터 플랫폼 기술이 발전하면서 데이터 저장/분석 인프라의 가격 경쟁력이 확보된다. 이에 따라 데이터 분석의 역량이 새로운 가치 창출의 기히를 만들어 내는 시대가 됐다.
하둡 분산파일시스템의 이해
대부분의 분산 환경에서 작동하는 분산 플랫폼들 ( 물리적으로 여러 대의 서버가 하나의 클러스터처럼 동작하는 플랫폼 )의 아키텍처를 크게 두 개로 나누면 마스터-슬레이브 구조와 마스터가 없는 구조가 있다.
마스터-슬레이브 구조는 마스터 역할을 하는 마스터쪽 데몬들이 있고, 마스터의 관리를 받는 슬레이브쪽 데몬들이 있는 그런 구조를 마스터-슬레이브 구조라고 한다. 슬레이브 서버들은 대부분 엔드의 서버로 확장을 할 수 있는 스케일 아웃 아키텍처를 갖는다. 하둡만 그런게 아니고 대부분의 분산 플랫폼이 그런 구조이다.
마스터 자체가 없는 구조도 있다. 마스터가 가지고있어야 되는 정보들을 모든 노드들이 공유하는 플랫폼 아키텍처로 구성되어있는 유형이다.
구글 파일 시스템은 마스터-슬레이브 구조이다. 그림에서 GFS master 가 마스터 서버고 GFS chunkserver 가 슬레이브 서버다. GFS chunkserver는 여러 대로 계속 확장될 수 있는 구조이다. 하둡이 이 아키텍처를 보고 소프트웨어로 구현한 것이기 때문에 구조적으로 거의 동일하다. 마스터-슬레이브 구조에서 가장 중요한것은 마스터에 부하가 가지 않는 환경을 만들어주는 것이다.
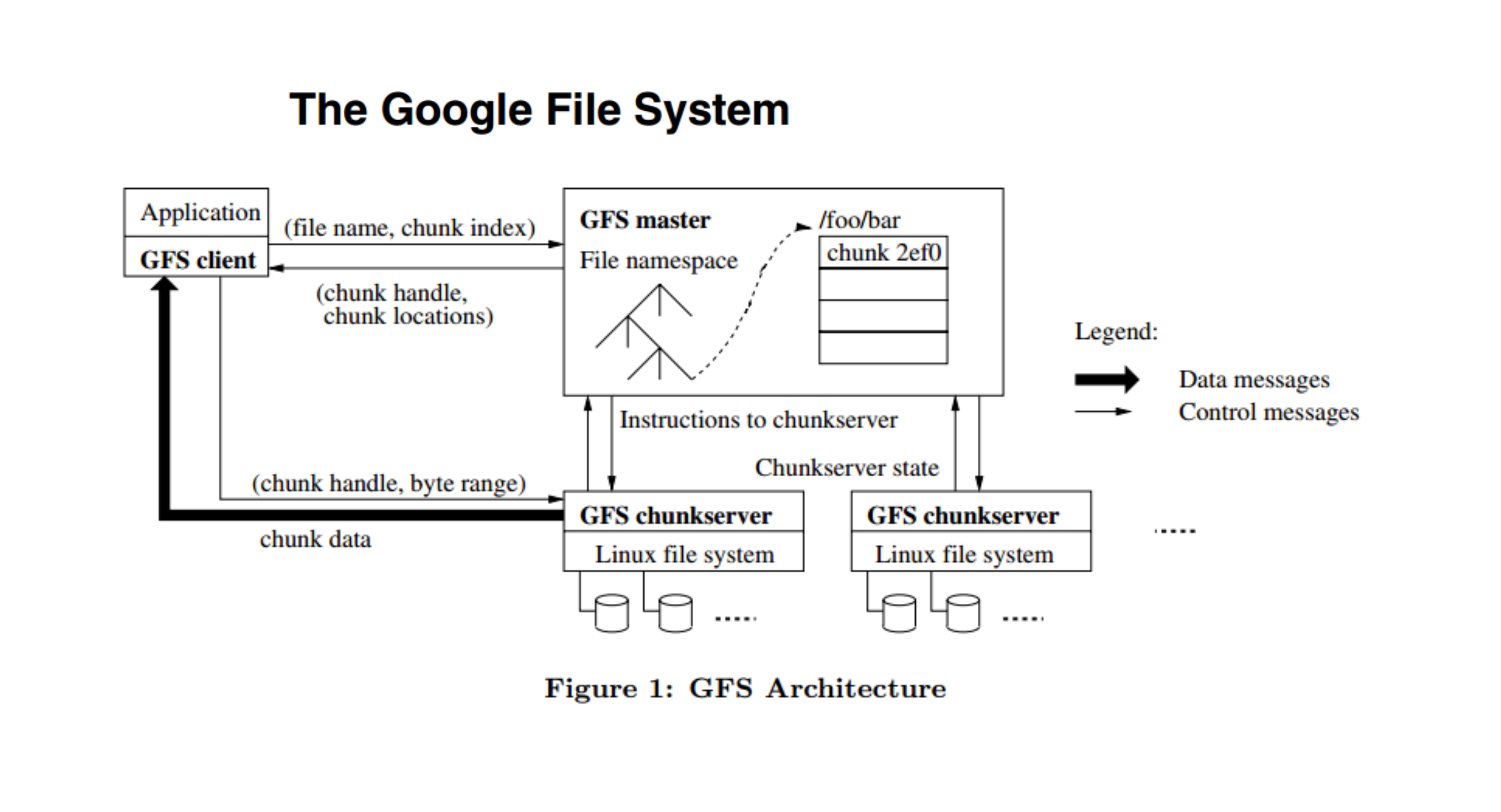
굵은 선의 chunk data 부분을 보면 클라이언트하고 chunk 서버하고 다이렉트로 연결되게 구성이 되어있다. 이 부분이 실제로 트래픽을 주고받을 때 client와 chunk 서버와는 데이터를 주고받지만 GFS master하고는 데이터를 주고받지 않는 구조로 설계가 되어있다. 아키텍쳐 설계상 마스터에서 데이터를 프로세싱 혹은 데이터를 주지 않는다. 그게 보통 마스터-슬레이브 구조를 갖는 분산 플랫폼의 기본적인 특성이다. 마스터-슬레이브 성향은 마스터쪽에 장애가 나면 전체 클러스터의 역할을 못하게 되는 장애가 발생한다. 마스터의 안정성을 보장할 수 있는 아키텍처로 구성하고 운용을 할 때도 그 부분을 신경쓰면서 운용해야한다.
구글 플랫폼의 철학
- 한 대의 고가 장비보다 여러 대의 저가 장비가 낫다. (스케일 업, 스케일 아웃)
- 데이터는 분산 저장한다.
parallel은 보다 cpu 병렬 처리를 의미를 강조한다. 데이터를 공유 스토리지에 공유해놓고 cpu를 늘리는 것이 그 예이다.distribute vs parallel
distribute 는 보다 데이터에 중점을 둔다. 데이터를 분산 처리하는 것을 뜻한다.
- 시스템(H/W)은 언제든지 죽을 수 있다.(Smart S/W)
스마트 소프트웨어로 죽지 않을 수 있게 보완 - 시스템 확장이 쉬워야한다.
데이터가 늘어나고 처리해야되는 양이 많아지면 아키텍처 장비를 바꾸고 개발을 새로하는게 아니라 클러스터 노드 수를 늘리면 잘 동작하도록 설계한다.
분산처리와 자동화를 키워드로 생각해도 무방하다.
하둡은 구글 플랫폼의 철학을 그대로 가져온다.
하둡 특성
- 수천대 이상의 리눅스 기반 범용 서버들을 하나의 클러스터로 사용
- 마스터-슬레이브 구조
- 파일은 블록(block) 단위로 저장
- 블록 데이터의 복제본 유지로 인한 신뢰성 보장 (기본 3개의 복제본)
- 높은 내고장성 (Fault-Tolerance)
- 데이터 처리의 지역성 보장 (Locality)
cf) 내고장성:
시스템의 일부가 고장이 나도 전체에는 영향을 주지 않고, 항상 시스템의 정상 작동을 유지하는 능력.
하둡은 여러대의 서버를 하나의 클러스터로 운영한다.
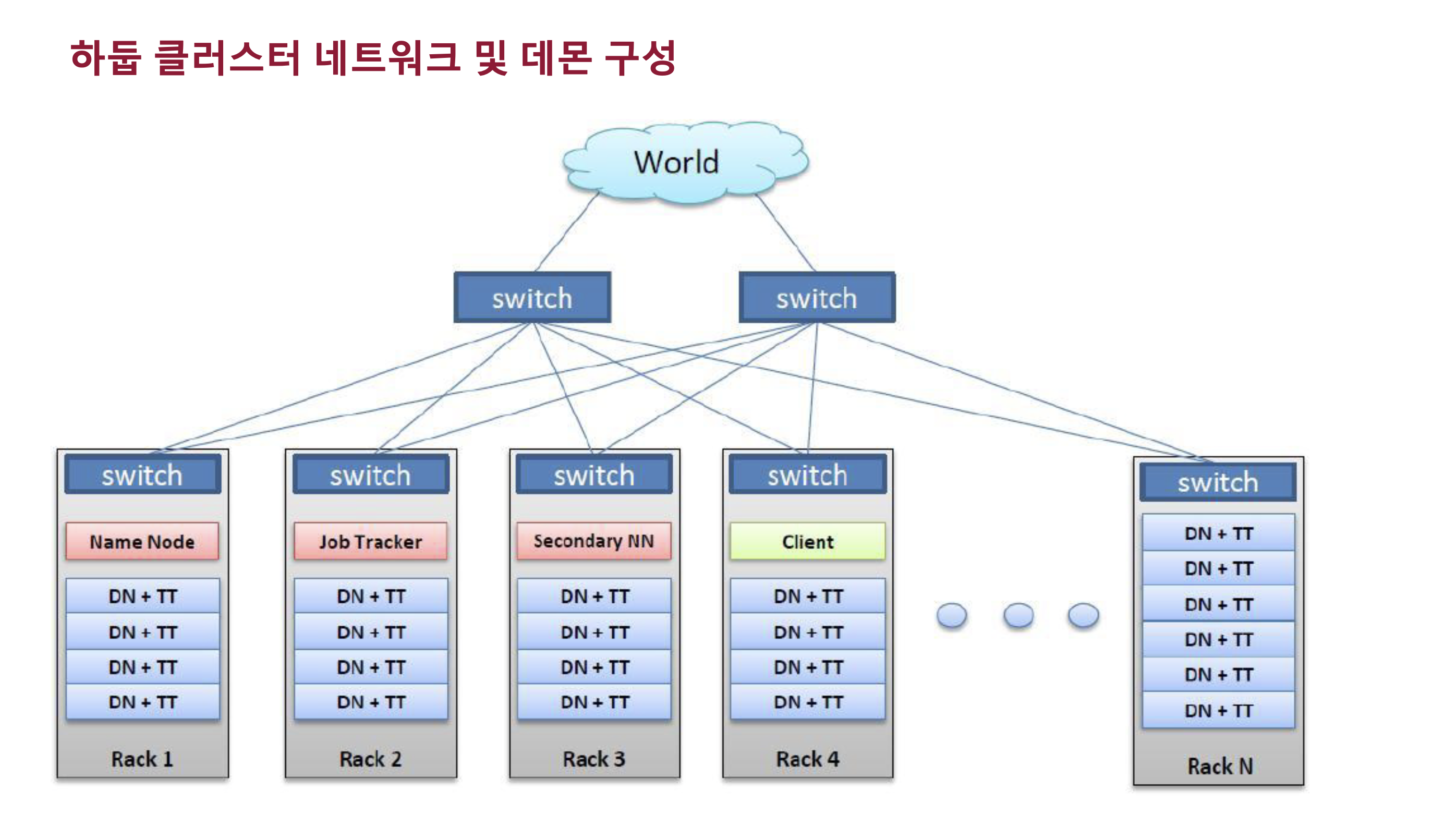 하둡은 최소 몇십대, 몇백대 이상 사용해야 의미가 있다. (이에 대한 이유는 뒤에 나온다)
하둡은 최소 몇십대, 몇백대 이상 사용해야 의미가 있다. (이에 대한 이유는 뒤에 나온다)
실제 물리적으로 rack형을 사용한다.
하둡 1.0의 경우 네임노드가 마스터 서버 역할을 한다. (하둡 분산파일시스템에 대한 마스터)
HDFS의 마스터 데몬 = 네임노드
슬레이브 데몬 = 데이터노드
분산파일시스템에 저장되어있는 데이터에 대한 job을 어플리케이션 연산을 처리하기 위해서 어플리케이션을 관리하는 데몬은 잡 트래커이다. 잡 트래커가 죽으면 잡을 컨트롤 할 수 없다.
DataNode + TaskTracker => 슬레이브 영역
위 그림처럼 하둡 클러스트는 랙 단위로 큰 클러스터를 구축하는게 일반적인 구성이다.
하둡 1.0의 주요 데몬은 마스터의 dfs를 관리하는 네임노드, job을 관리하는 잡트래커, 슬레이브쪽에는 데이터를 저장 관리하는 데이터 노드, 실제로 어플리케이션 업무를 수행하게되는 태스크 트래커가 있다.
하둡에서 블록(Block)이란?

- 하나의 파일을 여러 개의 Block으로 저장
- 블록 크기가 128MB 보다 적은 경우는 실제 크기 만큼만 용량을 차지
하둡에서 블록(Block) 하나의 크기가 큰 이유는?
- HDFS의 블록은 128MB와 같이 매우 큰 단위
- 블록이 큰 이유는 탐색 비용을 최소화할 수 있기 때문
- 블록이 크면 하드디스크에서 블록의 시작점을 탐색하는 데 걸리는 시간을 줄일 수 있고, 네트워크를 통해 데이터를 전송하는데 더 많은 시간을 할당이 가능함
블록 크기 분할과 추상화에 따른 이점
- 블록 단위로 나누어 저장하기 때문에 디스크 사이즈보다 더 큰 파일을 보관할 수 있음
- 블록 단위로 파일을 나누어 저장하기 때문에 700GB * 2 = 1.4T 크기의 HDFS에 1T 의 파일 저장 가능
- 파일 단위보다 블록 단위로 추상화를 하면 스토리지의 서브 시스템을 단순하게 만들 수 있으며, 파일 탐색 지점이나 메타정보를 저장할 때 사이즈가 고정되어 있으므로 구현이 용이함
- 내고장성을 제공하는데 필요한 복제(replication)을 구현할 때 매우 적합
- 같은 파일을 분산 처리하여 데이터 처리 성능을 개선할 수 있음
- 같은 노드에 같은 블록이 존재하지 않도록 복제하여 노드가 고장일 경우 다른 노드의 블록으로 복 구할 수 있음
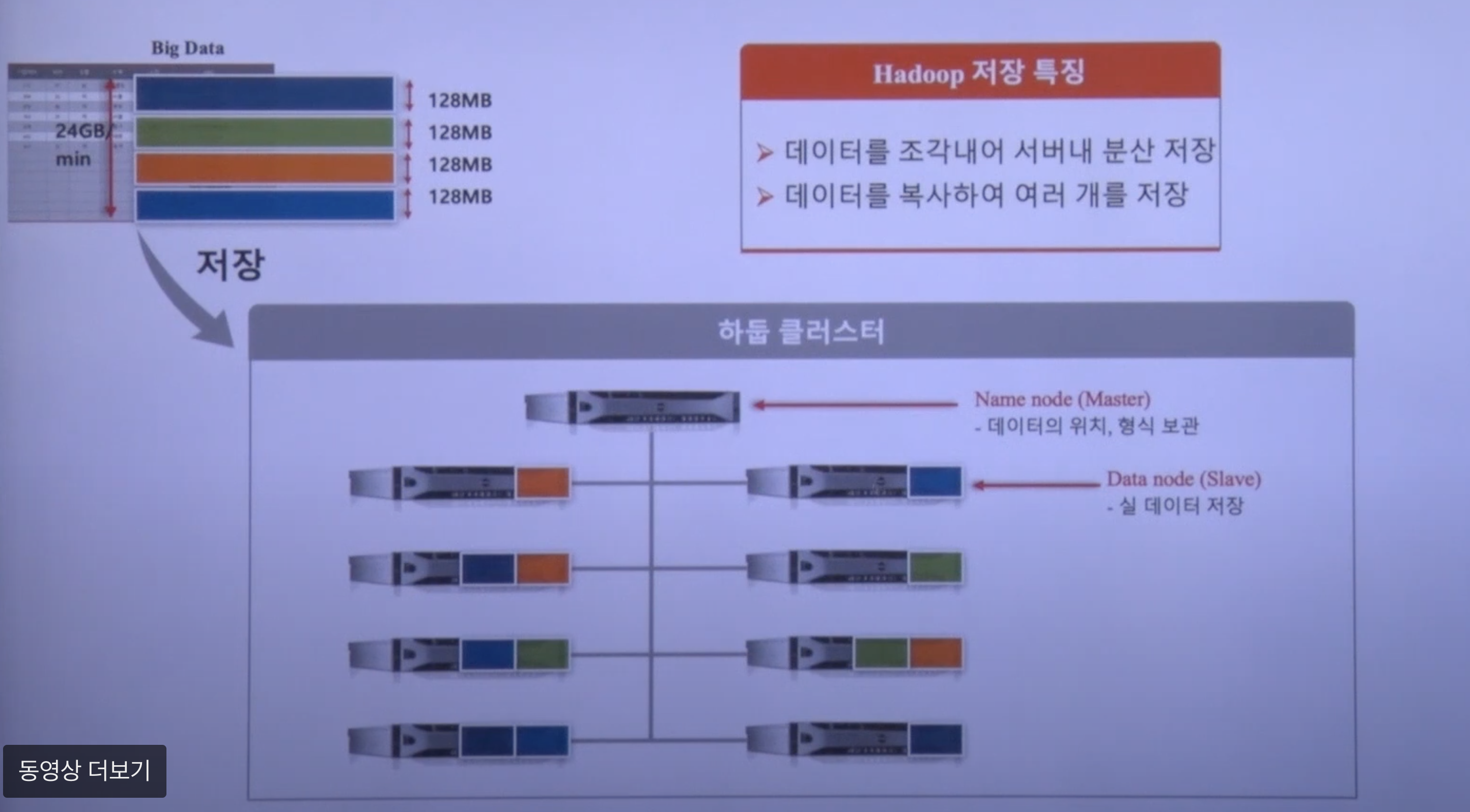
예를 들어 24GB의 데이터라고 생각해보자. 총 (24GB//128MB)+1 개의 블록이 생길 것이다.
( 마스터 서버에는 데이터를 저장하지 않는다 )
같은 블록을 서로 다른 데이터 노드 세 대에 스스로 복사한다. (사용자가 할 일은 없다)
만약 한 데이터 노드쪽의 네트워크가 끊겼다고 생각해보자.
하둡 마스터는(네임노드는) 주기적으로 슬레이브의 데이터 노드의 Heartbeat를 3초마다 받는다. Heartbeat을 보내지 않은 시간이 일정 시간을 넘어가면 네임노드는 그 데이터 노드에 장애가 발생한 것으로 판단한다. 네임노드는 파일 사이즈와 파일명을 기록해두고 있기 때문에 장애가 발생한 데이터 노드가 가지고 있는 파일을 다른 데이터노드에 1 개 더 복사하도록 명령한다. 따라서 결국 장애가 발생한 데이터 노드를 제외하고 다시 데이터 블록마다의 3 개의 복사본을 유지하게 된다. 네트워크가 정상적으로 연결되게되면 다시 4개의 블록이 되는데 (over replicate) 이것 역시 네임노드가 캐치해서 알아서 삭제하도록 한다. 이 과정에서 사용자가 할 일은 없다. Replication default의 값은 설정할 수 있다. 보통 3을 기본 설정으로 사용한다.
3 대의 데이터 노드가 동시에 마비가 되면 데이터 유실이 발생할 수 있다.
3 대 이상의 장애가 동시에 발생하지 않는 한 하둡 자체에서 데이터 유실이 발생할 일은 없다.
Q. 24GB 의 파일을 저장하게 되면 각 블록이 3개가 replicate돼서 72GB가 되는것인가?
A. 그렇다. 이 부분이 초반에 하둡이 지적받았던 부분이다. 하둡 3.0에서 데이터를 세 배가 아닌두 배 정도로 유지할 수 있는 방법의 대책이 등장한다. 이레이즈코딩이라는 기술. 원본 비율 대비 2배로 저장할 수 있다.
Q. Master가 죽으면 모든 것을 잃는건데 대비책이 있나요?
A. 하둡 1.0에서는 장애에 대한 대책이 없다. 대책이 하둡 2.0에서 등장한다. 마스터서버의 이중화.
블록의 지역성(Locality)
- 네트워크를 이용한 데이터 전송 시간 감소
- 대용량 데이터 확인을 위한 디스크 탐색 시간 감소
- 적절한 단위의 블록 크기를 이용한 CPU 처리시간 증가
저장된 데이터에서 연산을 진행하고 싶다.
저장된 데이터에서 '저장'이라는 단어가 몇번이나 등장하지? 라고 세고싶다면
mapreduce 프로그래밍을 작성하고 실행한다. 이 때 실제 데이터를 처리하는 데몬은 테스크 트래커다.
블록 캐싱
하둡에서 자주쓰는 것들은 블록 캐싱이라는 캐싱 방식을 사용해서 데이터 노드가 가지고 있는 데이터 메모리에 캐시를 등록해놓을 수 있다. 예를 들면 어떤 데이터에 유저의 아이디가 로그로 남는 로그가 있다. 그 유저의 아이디에 해당하는 마스터성 테이블을 보면 유저의 아이디에 해당하는 이름도 있고, 성별 등 여러가지 정보가 있다. 예를 들어 관계형 데이터 베이스라고 가정하면 join 과정을 거친 후 봐야한다. 조인해야하는 마스터성 데이터가 크지 않다는 전제하에 (내가 가지고 있는 물리적인 하드웨어 스펙에 데이터 노드가 들고 올라가는 메모리가 정해져 있는데 거기 안에 캐시를 등록할 수 있는 용량, 결국 상대적인 수치인 것) 자주 사용하는 케이스는 캐시로 등록을 해둘 수 있다는 것이다.
- 데이터 노드에 저장된 데이터 중 자주 읽는 블록은 블록 캐시(block cache)라는 데이터 노드의 메모리에 명시적으로 캐싱할 수 있음
- 파일 단위로 캐싱할 수도 있어서 조인에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있음
네임노드의 역할

- 전체 HDFS에 대한 NameSpace 관리
- DataNode로부터 Block 리포트를 받음
- Data에 대한 Replication 유지를 위한 커맨더 역할 수행
- 파일시스템 이미지 파일 관리(fsimage)
fsimage는 스냅샷과 같다. - 파일시스템에 대한 editslog 관리
보조 네임노드 (Secondery Name Node)
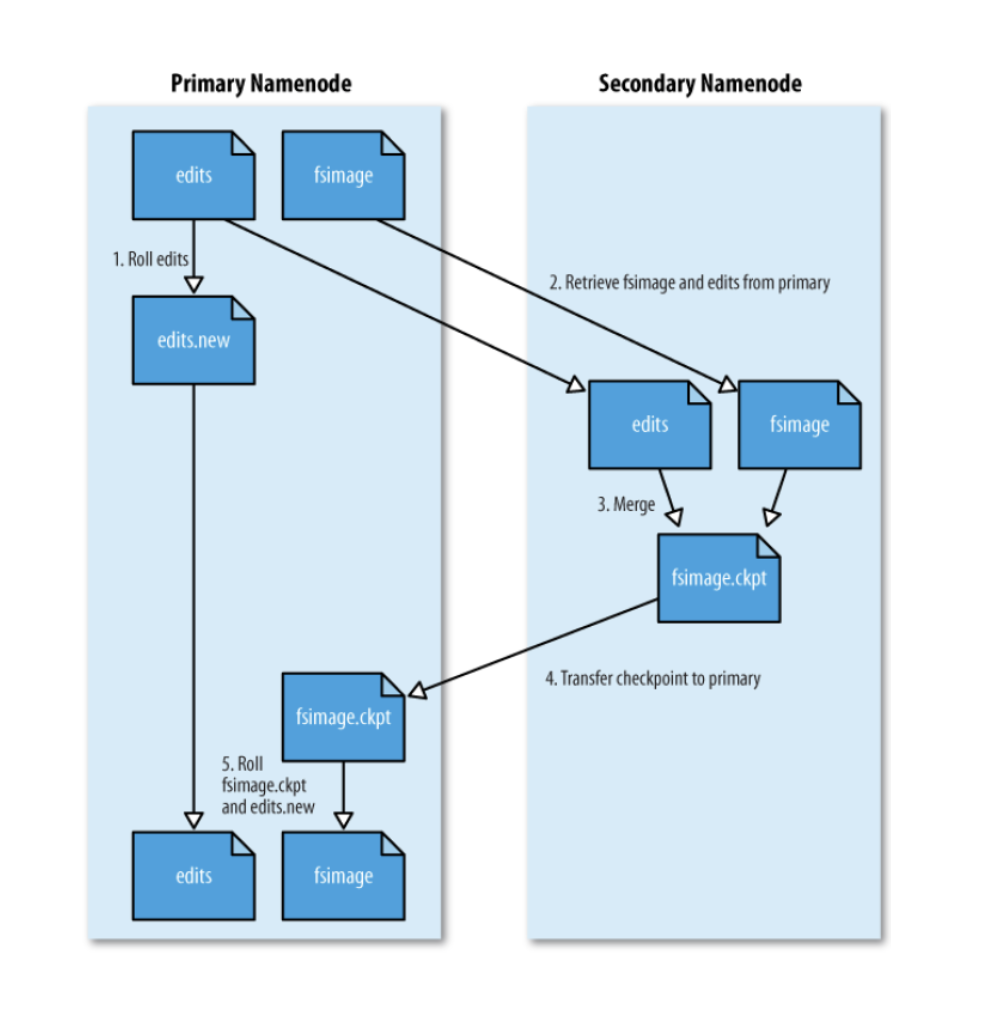
- 네임노드(NN)와 보조 네임노드(SNN)
- Active/Standby 구조 아님
- fsimage 와 edits 파일을 주기적으로 병합
- 체크 포인트
- 1시간 주기로 실행
- editslog가 일정 사이즈 이상이면 실행
- 이슈사항
- 네임노드가 SPOF
- 보조 네임노드의 장애 상황 감지 툴 없음
이름만 보면 마스터 네임노드를 보조할 수 있는 것처럼, 이중화할 수 있는 것처럼 보이지만 그 역할이 아니다.
이미지 파일은 네임노드 디스크 어딘가에 남아있다. 네임노드의 메모리는 항상 최신상태를 유지하도록 되어있다. 네임노드가 데몬을 구동하면 fsimage를 읽고 메모리에 스냅샷을 구성한다. 전체 하둡 클러스터에 있는 파일 메타 정보를 구성하고, editslog를 쭉 읽어가면서 변경된 내용을 메모리에 다 반영한다. 이 과정이 모두 끝나면 네임노드 구성이 마치고 서비스가 시작되는 것이다. 그 이후로 하둡 파일시스템에 변경이 되면 editslog에 남는다. 그러면 edits log의 용량은 계속 늘어나게된다. fsimage에 병합을 해줘야하는데, 이 때 네임노드에서 직접 병합하지 않고 SNN로 두 파일을 보내고 SNN에서 두 파일을 merge를 한다음에 fsimage를 바꿔치기 해주는 작업을 주기적으로 돌아가며 한다. fsimage를 최근 네임노드의 메모리의 상태정보와 거의 유사한 형태, 즉 editslog의 양이 최소한으로 줄어들 수 있도록 계속 merge 해주는 과정을 SNN에서 한다.
Q. SNN에서 장애가 일어나면?
A. 하둡 클러스터 전체 운영 관점에서는 문제가 발생하지 않는다. 다만 edits log가 커진다. 하둡 네임노드를 리스타트하는 경우에 edits log를 읽고 메모리에 반영해야되는데 파일이 너무 크면 읽지못하고 아웃오브 메모리 익셉션이 발생할 수 있다.
따라서 SNN가 잘 살아있어서 fsimage가 잘 병합되고 있는지 관리하는 것도 중요하다.
데이터노드 (Datanode) 역할
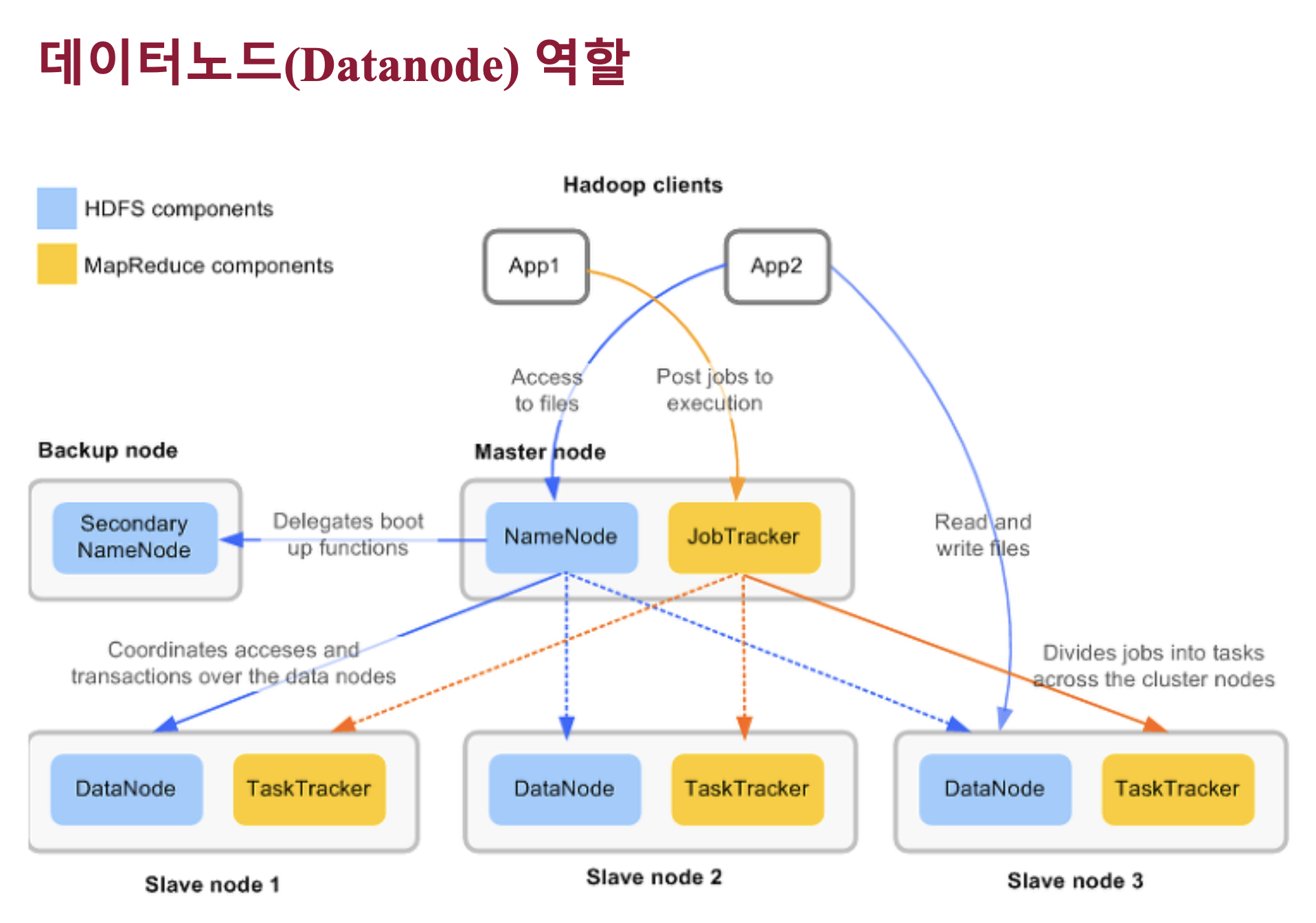
마스터 서버에게 현재 갖고있는 데이터를 계속 리포트한다. 데이터노드는 물리적으로 로컬 파일시스템에 HDFS 데이터를 저장한다. 네임노드는 실제로 데이터를 가지고 있지 않다.
실제 데이터 노드, 슬레이브 노드에 로컬 디스크에 저장되게 되어있다.
실제 하둡을 로컬에서 직접 클러스터를 구성해서 설치를 할 때 예를 들어보자. 하나의 데이터노드에 디스크가 6개가 꽂혀있다고하면 보통 os가 설치되고 하둡 플랫폼같은 플랫폼이 설치하는 os설치 영역 관련된 디스크는 굉장히 작은 크기의 디스크로 레이드 구성을 한다. 디스크를 두 개정도 두고 하나에 장애가 나도 실제 서비스에 지장이 없도록 구성을 하는게 일반적이다. 하둡에서는 진짜 데이터가 저장되는 데이터 디스크들이 6개 있다고 가정하면 데이터 디스크들은 일반적으로 레이드 구성을 하지 않는다. 레이드 구성을 하는 것이 이상한 것이다. 왜냐하면 레이드 구성을 하는 순간 사용할 수 있는 전체 용량이 줄어든다. 레이드 구성을 하는 순간 2TB 디스크 6개를 가지고 있으면 12TB의 용량을 쓸 수 있어야되는데 결과적으로 다 사용하지 못하는 것이다. 그렇지만 JBOD(Just a Bunch of Disks) 라는 형태로 레이드 구성을 하지 않으면 12TB의 물리적인 데이터를 모두 사용할 수 있다.
데이터 노드는 주기적으로 내가 갖고 있는 내용을 네임노드에 보내고 블록에 이상이 있는지 체크를 해서 이상이 있으면 네임노드한테 리포트를 보낸다. 그러면 네임노드는 그거 지우고 다른 데이터노드한테 또 복사하라는 등의 관리를 해준다. 데이터노드는 네임보드한테 주기적으로 블록리포트를 해서 블록을 안정한 상태로 항상 유지하는 역할이 기본적인 역할이고 실제 데이터 저장을 한다.
-
DataNode는 물리적으로 로컬파일시스템에 HDFS 데이터를 저장
-
DataNode는 HDFS에 대한 지식이 없음
-
일반적으로 레이드 구성을 하지 않음 (JBOD구성)
-
블록 리포트 : NameNode가 시작될 때, 그리고 (주기적으로)로컬 파일시스템에 있는 모든 HDFS 블록들을 검사 후 정상적인 블록의 목록을 만들어 NameNode에 전송
JBOD (Just a Bunch of Disks)
- 물리디스크 두 개 이상을 마치 하나의 디스크처럼 만들어 주는 것, 스패닝(Spanning)이라고도 합니다.
500GB와 250GB 저장장치 2개를 연결하면, 하나의 750GB 저장장치처럼 사용 가능합니다. - 여러 디스크의 용량을 단순히 이어붙여주는 것입니다.
- JBOD로 연결하는 디스크는 용량이 같지 않아도 되고, 디스크가 동시에 엑세스가 일어나지도 않습니다.
- RAID와 다르게 동시에 디스크 I/O가 발생하지 않기 때문에 성능이 향상되지 않습니다.
내결함성도 제공되지 않으며 오로지 용량 늘리기 용으로 사용합니다. - 구성된 디스크중 하나의 디스크만 에러가 발생해도 전체 볼륨이 문제가 생깁니다. 이에 따라, 자료손실의 위험도 있습니다.
- JBOD로 구성된 디스크는 데이터를 순차적으로 저장합니다.
(예를 들어, 데이터는 디스크 1에 먼저 기록 → 디스크 1이 꽉 차면 → 디스크 2 기록 → 디스크 2 꽉차면 → 디스크 3 기록 와 같은 방식)
출처 - https://melonicedlatte.com/2022/05/04/144000.html
- 물리디스크 두 개 이상을 마치 하나의 디스크처럼 만들어 주는 것, 스패닝(Spanning)이라고도 합니다.
데이터노드 블록 스캐너
- DataNode는 NameNode가 시작될 때, 그리고 (주기적으로) 로컬파일시스템에 있는 모든 HDFS 블록들을 검사 후 정상적인 블록의 목록을 만들어 NameNode에 전송
HDFS 읽기 연산 처리 메커니즘

HDFS 쓰기 연산 처리 메커니즘

- 데이터 복제 시 클라이언트가 네임노드로부터 데이터노드 리스트를 전달 받음
- 파이프라인 형태로 데이터 복사 (4kb 단위)
- 네트워크 트래픽은 클라이언트와 데이터노드간에만 발생
하둡 명령어
대부분 리눅스에서 사용하는 명령어와 일치한다.
하둡 홈을 설정하면 하둡 명령어를 던질 때 편하다.
홈디렉토리 설정
vi .bash_profile
=>
export HADOOP_HOME = 경로
export PATH=\$HADOOP_HOME/bin:\$PATH
<=
source .bash_profile 위 코드를 통해 하둡 홈을 설정하면 어떤 디렉토리에 있든 hadoop 치면 하둡 명령어가 실행이 된다.
- setrep
- text : 하둡에 저장되어있는 데이터를 볼 때
- stat : 저장되어있는 정보의 통계 몇개 출력
- usage : usage 출력
- help : usage보다 디테일한 옵션 보여줌
- getmerge : 하둡에 있는 파일들을 머지해서 로컬로 저장
hadoop fs
어떤 명령어가 있는지 보여준다
hadoop fs -ls /
하둡의 루트 디렉토리
hadoop fs -ls /user
유저 디렉토리 밑에 누가 있는지 확인
hadoop fs -mkdir hadoop_mkdir_test
hadoop fs -ls
=> hadoop_mkdir_test 디렉토리 생성됨을 알 수 있다.
<테스트용 연습문제>
vi LICENSE
아파치 라이센스 파일이 있다.
hadoop fs -put LICENSE.txt hadoop_mkdir_test
로컬 파일에 있는 LICENSE.txt. 파일을 hadoop_mkdir_test 디렉토리에 넣겠다.
hadoop fs -ls hadoop_mkdir_test
hadoop fs -ls -hadoop_mkdir_test
휴먼 리더블하게 용량과 같은 정보까지 나오는것
hadoop fs -text hadoop_mkdir_test/LICENSE.txt
옮겨진 파일을 읽어보자
Rack Awareness
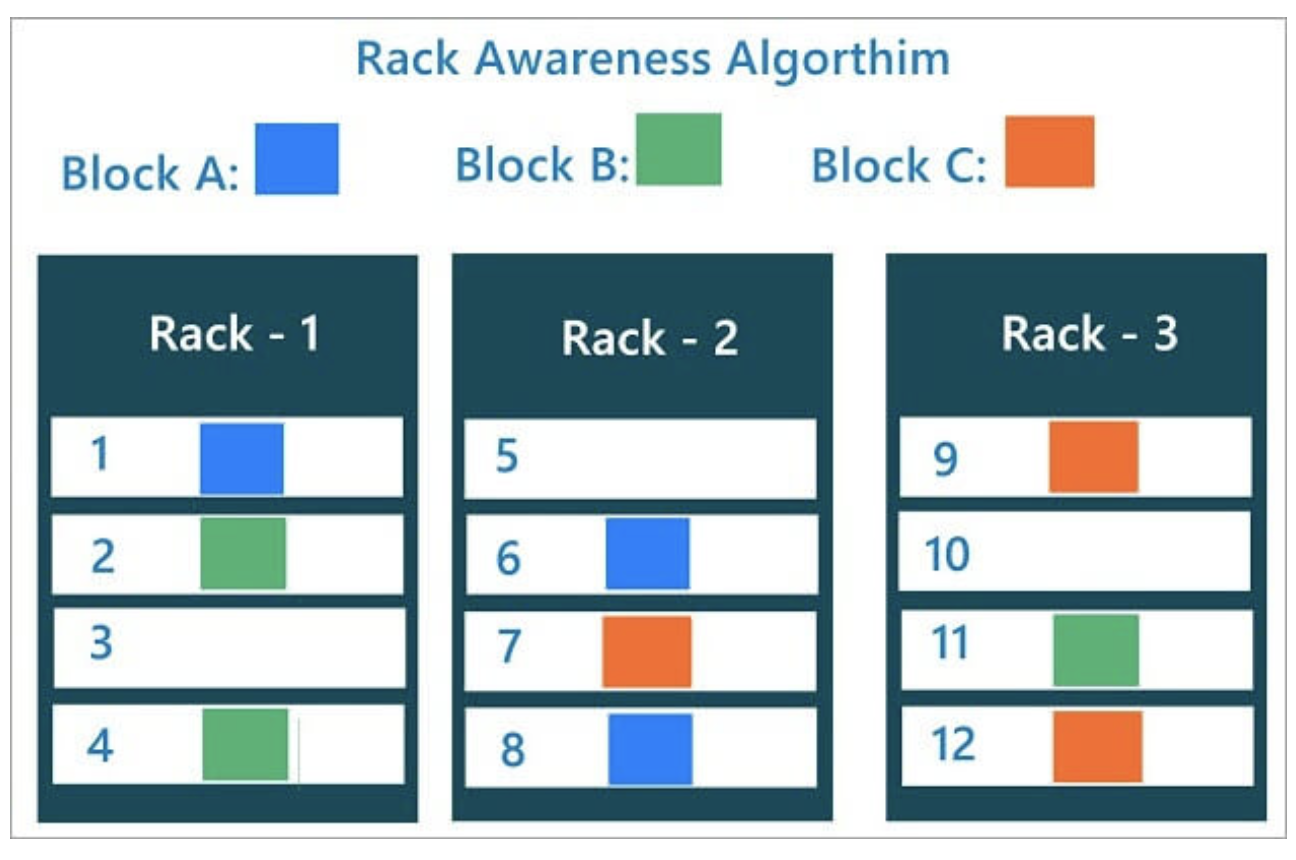
랙단위로 장애가 나는 경우가 있을 수 있다. 랙의 스위치 자체가 장애가 나거나 랙의 전원이 이중화가 되어있지 않은 상태에서 장애가 났을 경우이다.
하둡의 데이터를 적재를 할 때 서로 다른 랙에 블록이 최소 하나는 복사가 될 수 있도록 설정한다.
블록을 저장할 때, 2개의 블록은 같은 랙에, 나머지 하나의 블록은 다른 랙에 저장하도록 구성한다.
-> 랙단위 장애 발생(전원, 스위치 등)에도 전체 블록이 유실되지 않도록 구성한다.
HDFS 세이프모드
리플리케이션 블록이 하나도 없거나 블록이 일정 퍼센트가 안될 경우에 세이프모드에 들어간다.
- HDFS의 세이프모드(safemode)는 데이터 노드를 수정할 수 없는 상태
- 세이프 모드가 되면 데이터는 읽기 전용 상태가 되고, 데이터 추가와 수정이 불가능 하며 데이터 복제도 일어나지 않음
- 관리자가 서버 운영 정비를 위해 세이프 모드를 설정 할 수 있음
- 네임노드에 문제가 생겨서 정상적인 동작을 할 수 없을 때 자동으로 세이프 모드로 전환
->주로 missing block 이 발생하는 경우, 혹은 클러스터 재 구동 시 블록 리포트를 다 받기 전까지 Safe mode 로 동작 - 세이프 모드 상태일 때 파일 복사를 시도하면 아래와 같은 에러 메시지 발생
HDFS 세이프 모드 명령어 및 복구
HDFS 운영 중 safemode 에 진입한 경우, 네임노드의 문제인지 데이터노드의 문제인지 파악이 필요하며, fsck 명령으로 HDFS의 무결성을 체크하고, hdfs dfsadmin -report 명령으로 각 데이터 노드의 상태를 확인하여 문제를 확인하고 해결한 후 세이프 모드를 해제해야한다.
커럽트 블록
블록 자체가 깨졌다. 유실 발생.
- HDFS는 하트비트를 통해 데이터 블록에 문제가 생기는 것을 감지하고 자동으로 복구를 진행함
- 다른 데이터 노드에 복제된 데이터를 가져와서 복구하지만, 모든 복제 블록에 문제가 생겨서 복구 하지 못 하게 되면 커럽트 상태가 됨.
- 커럽트 상태의 파일들은 삭제하고, 원본 파일을 다시 HDFS에 올려주어야 함
HDFS 휴지통
하둡은 휴지통 기능이 있다.
HDFS는 데이터 삭제 시 영구적 데이터를 삭제하지 않도록 휴지통 설정을 할 수 있다.
운영자 커맨드 목록
주로 실행이나 설정에 관련된 명령어가 많음
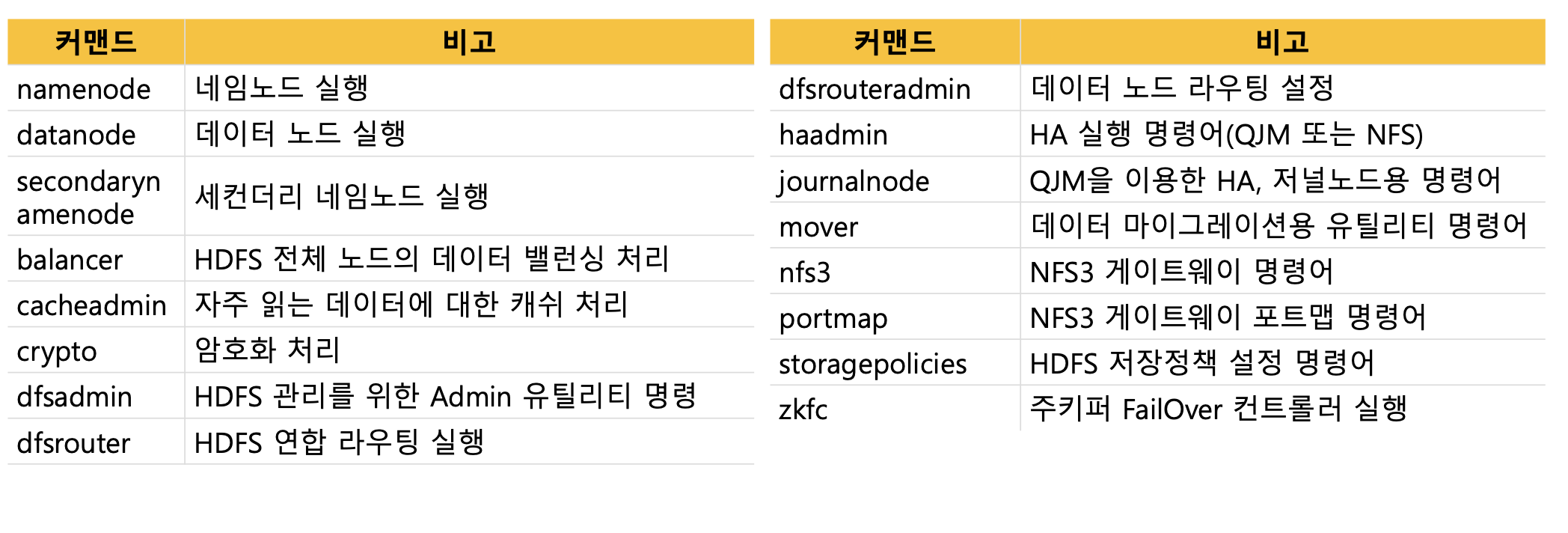
HDFS 운영자 커맨드 - dfsadmin
dfsadmin -report
- 리포트를 작성해라.
- HDFS의 각 노드들의 상태를 출력하며, HDFS의 전체 사용량과 각 노드의 상태를 확인할 수 있음
dfsadmin -setQuota
- 일정 디렉토리에 용량 Quota 설정
HDFS Balancers
하둡 클러스터가 도입시기에 따라서 서로 상이한 스펙으로 하나의 클러스트를 구성하는 경우가 있다. 이런 경우에 서로 디스크 간 Balancing이 안되는경우가 있다.
예를들어 2018년도에 도입했던 서버에서는 하나의 데이터 노드의 디스크가 20TB 를 가지고 있다. 이후 2020년도에는 40TB를 추가했다고 가정해보자. 전체 HDFS를 운영할 때 네임노드가 데이터를 저장을 할 때 블록을 가지고 있는 전체 퍼센트를 보면서 얼라인을 하긴하는데 완벽하지 않다. 하둡 전체 알고리즘은 내부 알고리즘을 따라 동작하는데, 옛날에 도입한 노드 하나의 디스크 서버는 작다고 최근에 도입한 노드 하나의 디스크 서버는 크다. 그렇게되면 어떤 어떤 노드의 디스크는 용량의 80% 사용하고 어떤 노드는 디스크 용량의 30%만 사용하는 경우가 생길 수 있다.
하둡 2.0까지는 이걸 잘 관리해줘야한다. (하둡 3.0부터는 이 부분에서 나아진 부분이 있다)
운용중인 하둡 클러스터에서 Balancing 작업을 한다는건 되게 위험한 일일 수 있다. 왜냐하면 하둡을 운영을하면 기본적으로 큰 데이터가 저장이 되고 있고 그 데이터에 굉장히 많은 job들이 항상 돌아가고 있다. 주기적으로 돌아야하는 ETL 이 있고 어떤 경우는 adhoc하게 분석가들이 분석을 돌리기도 한다. 따라서 발란싱 작업은 고려해야될 옵션들이 많은 어려운 작업이다.
두 가지를 말해보자면,
첫번째는 동시에 얼마나 빨리 복사를 할 것인지.
쓰레드를 여러개 끼워서 디스크에 밸런싱을 할 때 얼마나 많은 쓰레드가 처리하게 만들것인지.
두번째는 데이터 노드 기준으로 bandwidth를 얼마나 줄 것인지.
밸런싱을 하게되면 데이터 노드들끼리 데이터를 주고받으면서 전체적인 퍼센테이지를 균등하게 맞추기때문에 트래픽이 발생한다. 그 트래픽의 밴드위드를 얼마나 쓸건지에 대한 고민이 필요하다.
보통은 보수적으로 설정을 한다. 리소스를 많이 안잡게 설정한다.
따라서 백그라운드에서 알아서 조금씩 조금씩 Balancing이 될 수 있도록 설정을 하는게 일반적이다. 이미 운영중인 상태에서 돌아가야되는 job들에게 어느정도의 리소스를 보장해줘야하기때문에 보수적으로 잡고 Balancing을 한다. 클러스터 규모에 따라 굉장히 오랫동안 발란싱이 진행되는 경우도 있다. 2주 ~3주, 1달 이렇게 Balancing이 되기도 한다. 굉장히 중요한 작업이다. 온프레미스에서 하둡 클러스터를 운영하는 경우 년단위로 프로젝트를 계획하고 장비를 투입하기때문에 장비 도입년도에 따라서 상이한 스펙으로 하둡 클러스터를 구축하게되면 이런 부분들을 하둡 운영자가 신경써줘야한다. 디스크 크기 기준으로는 모든 노드가 대략 비슷한 크기의 디스크를 갖는것이 바람직하다. 하지만 현실은 그렇지 못한 경우가 발생할 수 있다.
- 하둡을 운영하다보면, 서로 다른 스펙의 데이터노드를 하나의 클러스터로 구성하게 됨
- 이 경우 노드 간 디스크 크기가 다를 수 있고, 전체 데이터의 밸런싱이 되지 않는 문제가 발생할 수 있음 • 신규 데이터 노드를 추가 하는 경우에도 발생할 수 있음
-> 이 경우 NameNode 에서 데이터 적재량이 적은 노드를 우선적으로 선정하여 block 을 추가하는데, 이 때 특정 노드에 부하가 몰릴 수 있음
WEB HDFS REST API
하둡은 Web HDFS REST API를 제공해서 원격에서 REST API를 통해서 하둡에다가 파일을 적재를 하는 등의 여러가지 연산처리를 할 수 있다.
- HDFS는 REST API를 이용하여 파일을 조회하고, 생성, 수정, 삭제하는 기능을 제공함
- 상세 내용 : https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
- 이 기능을 이용하여 원격지에서 HDFS의 내용에 접근하는 것이 가능함
HDFS 암호화 - KMS
KMS를 별도로 띄우고 서버에서 생성한 키를 가지고 하둡의 특정 영역을 암호화 영역으로 설정하고 여기에 저장되는 데이터는 자동으로 암호화되도록 한다. 이 과정에서 디테일 설정 과정이 필요하다.
- 하둡 KMS 는 KeyProvider API 를 기반으로 하는 암호화 키 관리 서버임 (REST API 제공) - 상세 내용 : https://hadoop.apache.org/docs/current/hadoop-kms/index.html
Hadoop 2.0 Cluster Architecture
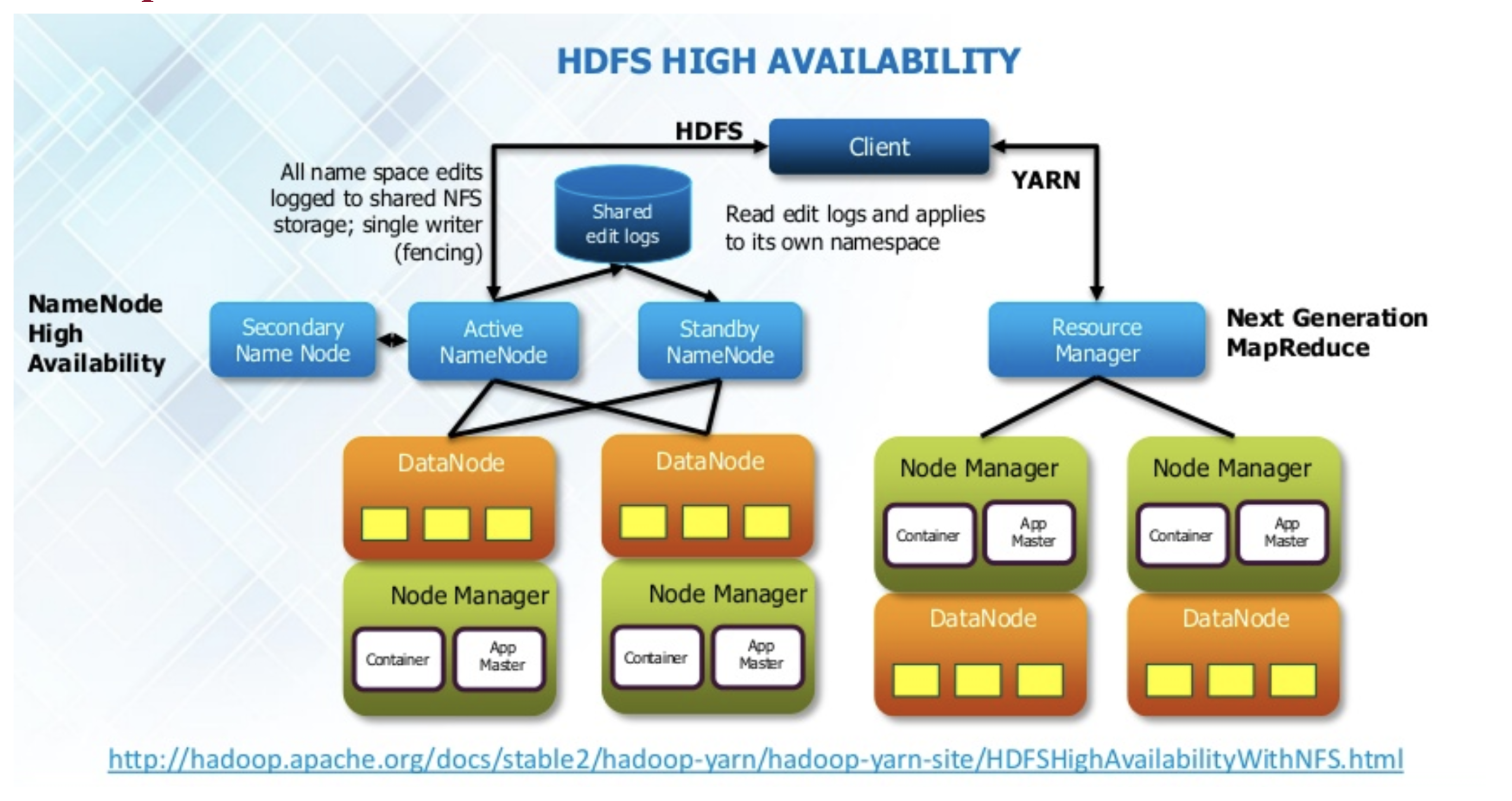
마스터 서버의 장애를 해결하기위한 부분이 가장 큰 변화포인트이다.
그림에서 보시면 액티브 네임노드 세컨더리 네임노드 이 두개는 기존과 똑같다. fsimage랑 editslog를 병합하는 역할을 한다. 하나 추가된것은 스탠바이 네임노드다. 데이터노드가 블락리포트를 한다던지 네임노드랑 통신하는것을 항상 양쪽으로 통신하도록 되어있다.(액티브랑 스탠바이로) 그리고 스탠바이는 정보는 가지고 있지만 평소에는 동작하지 않다가 액티브가 다운됐을 때 얘가 액티브로 올라서게 된다. 그래서 네임노드가 2중화 구성이 되도록 구성되어있다. 하둡 2.0에서는 액티브에서 네임노드가 스탠바이로 바뀌는 과정에서 약간의 다운타임이 발생할 수 있다. 하둡 네임노드에 들어가있는 메타정보가 얼마나 크냐에 따라서 다운타임이 발생할 수 있다. 경험적으로는 하둡에 들어가있는 파일이 몇억개단위의 파일이 들어가있다면 하둡 네임노드 파일의 네임스페이스 정보의 크기가 100기가 이상 메모리의 정보를 가지고 있다. 쥬시가 발생하면 1~2분정도 쥬시가 발생하기도 한다. 쥬시가 최대한 생하지않도록 운영하는 것은 굉장한 노하우가 필요하다. 몇억개정도의 파일이 되면 5분에서 10분 사이 정도 다운타임이 발생할 수 있다. 하둡 1.0에서는 그냥 액티브 죽으면 장애였는데, 2.0에서는 스탠바이네임노드가 액티브로 전환이 된다.
(((((2.0기준으로 가장 중요한 부분은 Shared Editlogs인데)))))))
네임노드 고가용성 High Availability
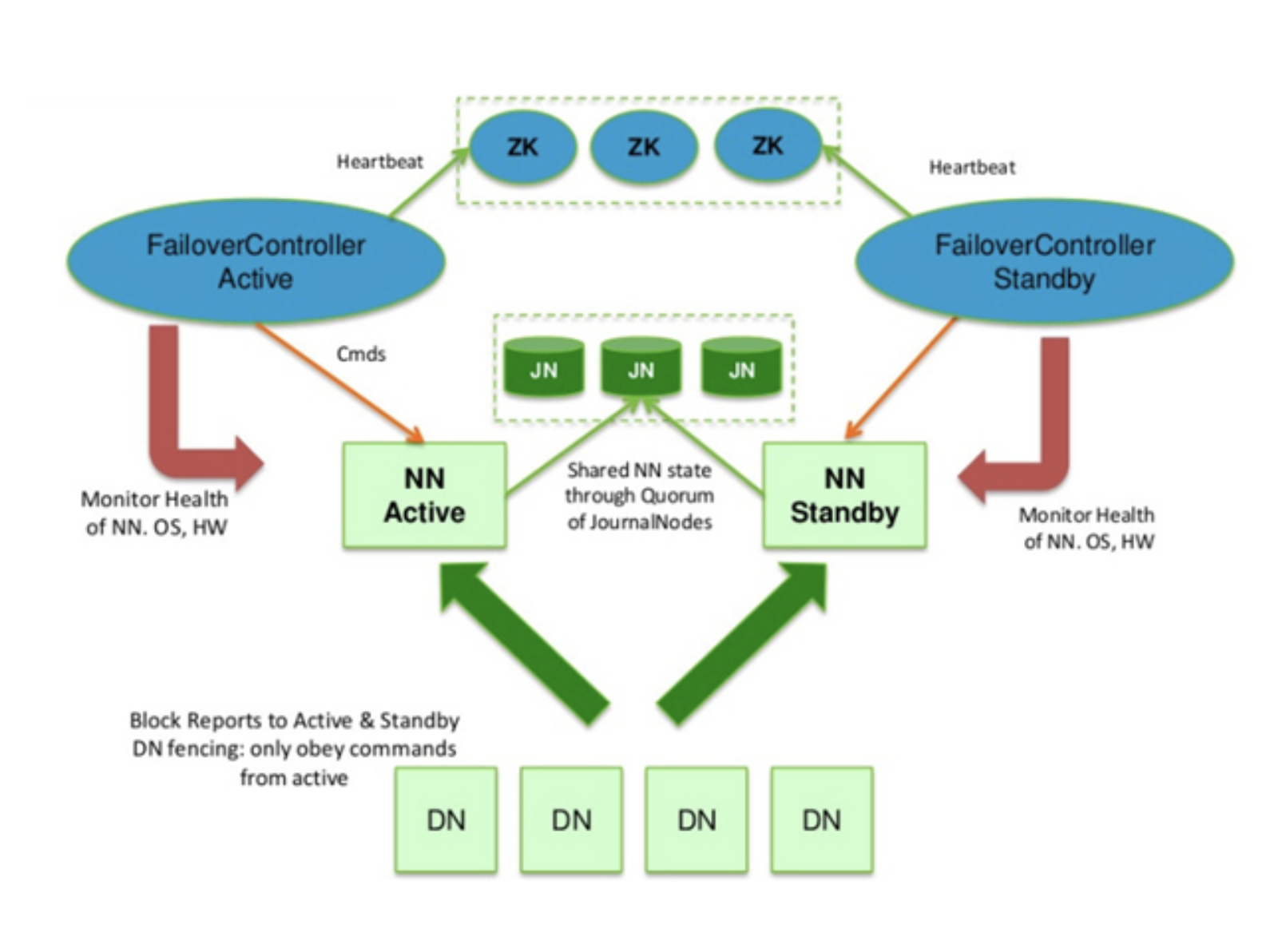
- HDFS 고가용성은 이중화된 두대의 서버인 액티브(active) 네임 노드와 스탠바이(standby) 네임노드를 이용하여 지원
- 액티브 네임노드와 스탠바이 네임노드는 데이터 노드로부터 블록 리포트와 하트비트를 모두 받아서 동일한 메타데이터를 유지하고, 공유 스토리지를 이용하여 에디트파일을 공유
- 액티브 네임노드는 네임노드의 역할을 수행하고, 스탠바이 네 임노드는 액티브 네임노드와 동일한 메타데이터 정보를 유지하 다가, 액티브 네임노드에 문제가 발생하면 스탠바이 네임노드 가 액티브 네임노드로 동작
- 액티브 네임노드에 문제가 발생하는 것을 자동으로 확인하는 것이 어렵기 때문에 보통 주키퍼를 이용하여 장애 발생시 자동 으로 변경될 수 있도록 구성함
Zookeeper 라는애가 등장한다. 분산 코디네이터이다.
제일 중요한건 저널 노드라는 데몬이 별도로 뜬다. 저널링이라는것은 꼭 하드웨어에만 있는 개념이 아니고 fsimage같은 snapshot이 있고, editslog가 쭉 발생하다가 editslog만 계속 merge 해가지고 백업을 하는 등의 장애에 대응하는 처리 방식은 원래부터 있던 방식이다. 저널링이라는 것은 이미지 스냅샷을 가지고 있고 계속 에디트로그를 가지고 있는 방식을 말한다. 하둡은 저널로그를 여러대를(세 대이상)띄울 수 있는 부분을 2.0에서 자체적으로 가지고 있다. 그래서 네임노드 액티브랑 스탠바이가 이 저널로그에 저장되는 fsimage랑 에디트로그를 서로 공유를 할 수 있는 쉐어드 방식이 있는데, 그러면 실제로 저널 노드도 그냥 물리적인 서버인데 그 이미지 파일을 어디다 저장을 할거냐에 대한 이슈가 생긴다. 어디에 저장할것인지에 대한 이슈가 첫번쨰 해결방식이 에디트로그 공유방식1이 있다.
에디트로그 공유 방식1 : NFS(Network File System)
공유방식1의 한계
- NFS를 이용하는 방법은 에디트 파일을 공유 스토리지를 이용하여 공유하는 방법
- 공유스토리지에 에디트 로그를 공유하고 펜싱 을 이용하여 하나의 네임노드만 에디트 로그를 기록함
- Split Brain 위험이 존재하고, 한계점이 있음
NFS(Network File System) 공유 방식의 문제점
- NN 두개가 모두 Acitive NN 가 될 수 있는 상황이 발생하여, 동시에 Shared Storage 의 데이터를 수정하면 NameNode 의 중요 정보가 Crash 되며, 분산환경에서는 이 상태를 SplitBrain 이라고 함
- 두개의 Active NN 가 발생하는 상황을 막기 dfs.ha.fencing.methods 위해 설정을 통해 Active NN 을 Kill 시키거 나 Shared Storage 를 unmount 해줌
-> sshfence 인 경우 아래 처럼 NameNode 를 Kill 시킴
fuser -v -k -n tcp - 그렇지만 네트워크 장애의 경우, 기존 Active NameNode 가 ZooKeeper 와 Standby NameNode 로만 통신이 되지 않고, SharedStorage와 통신이 되는 상황이라면?
이런 경우 Standby NameNode에서 fencing 처리는 네트워크 단절로 인해 수행할 수 없으며, 기존 Active NameNode 는 여전히 Live한 상태가 됨 (SplitBrain 발생 가능성 존재함)
실제 분산환경에서 클러스터를 운영하다보면 다양한 장애가 발생한다. 가장 문제가 되는 경우가 네트워크 장애다. 하나의 네임노드가 죽었을 때 대기하던 스탠바이 네임노드가 액티브로 전환이되어야 클러스터가 정상으로 운영이 된다. 네임노드가 장애가 나게되면 스탠바이가 액티브로 전환될 수 있도록 처리하는 부분들을 펜싱이라고 한다. 펜싱도 여러가지 방법으로 설정할 수 있는데 하둡 2.0의 액티브 스탠바이의 페일오버 알고리즘은 주키퍼에 의존하고 있다. 주키퍼의 알고리즘에 의해서 액티브 상태가 장애가 났다는 것을 판단을하는데 이 때 문제가 발생할 수 있는 부분이 액티브 네임노드 장애가 주키퍼하고 스탠바이 네임노드로는 통신이 안되고 쉐어드 스토리지로만 통신이 되는 아주 재수없는 상황이 발생할 수 있다. 이런 경우에는 액티브 네임노드가 두개가 이 저널로그의 데이터에 데이터로그를 막 기록하는 상황이 발생한다. 실제로는 액티브네임노드는 하나만 존재해야하는데 두개가 발생한다.확률적으로 적지만 그런 경우가 발생할경우 네임노드의 fsimage와 에디트로그가 크랙되는 상황이 발생하는거고 그런 상황에서 분산환경에서는 스플릿브레인이 발생했다고 말한다.
에디트로그 공유방식 2: Joural Node 그룹 사용
• QJM(Quorum Journal Manager)은 NameNode 내부에 구현된 HDFS 전용 구 현체로, 고가용성 에디트 로그를 지원하기 위한 목적으로 설계됨
• QJM은 저널 노드 그룹에서 동작하며, 각 에디트 로그는 전체 저널 노드에 동시에 쓰여짐
-> 주키퍼의 동작 방식과 유사함
• HDFS 고가용성은 액티브 네임노드를 선 출하기 위해 주키퍼를 이용
Joural Node 사용 시 Failover 절차
- Active NameNode는 edit log 처리용 epoch number를 할당 받는다. 이 번호는 uniq하게 증가하는 번호로 새로 할당 받은 번호는 이전 번호보다 항상 크다.
- Active NameNode는 파일 시스템 변경 시 JournalNode로 변경 사항을 전송한다. 전송 시 epoch number를 같이 전송한다.
- JournalNode는 자신이 가지고 있는 epoch number 보다 큰 번호가 오면 자신의 번호를 새로운 번호로 갱신하고 해당 요청을 처리
한다. - JournalNode는 자신이 가지고 있는 번호보다 작은 epoch number를 받으면 해당 요청은 처리하지 않는다.
- 이런 요청은 주로 SplitBrain 상황에서 발생하게 된다.
- 기존 NameNode가 정상적으로 Standby로 변하지 않았고, 이 NameNode가 정상적으로 fencing 되지 않은 상태이다.
- Standby NameNode는 주기적(1분)으로 JournalNode로 부터 이전에 받은 edit log의 txid 이후의 정보를 받아 메모리의 파일 시스
템 구조에 반영 - Active NameNode 장애 발생 시 Standby NameNode는 마지막 받은 txid 이후의 모든 정보를 받아 메모리 구성에 반영 후 Active
NameNode로 상태 변환 - 새로 Active NameNode가 되면 1번 항목을 처리한다.
HDFS Federation
- 하나의 네임노드에서 관리하는 파일, 블록 개수가 많아 지면 물리적 한계가 있음
- 이를 해결하기 위해 HDFS Federation 을 하둡 2.0 이상에 서 지원
- HDFS 페더레이션을 사용하면 파일, 디렉토리의 정보를 가지는 네임스페이스와 블록의 정보를 가지는 블록 풀을 각 네임노드가 독립적으로 관리
- 네임스페이스와 블록풀을 네임스페이스 볼륨이라하고 네임스페이스 볼륨은 독립적으로 관리되기 때문에 하나 의 네임노드에 문제가 생겨도 다른 네임노드에 영향을 주지 않음
네임노드 이중화가 페더레이션이 헷갈릴 수 있다.
페더레이션이랑은 완전히 다른 개념이다.
하둡 클러스터를 운영하다보면 어느 시점이 되면, 하나의 물리적인 서버의 네임노드의 메모리를 넘어사는 상황이 발생할 수 있다. 512기가바이트인데 전체 클러스터에서 저장되어있는 파일과 블록정보의 메타정보를 메모리에 로딩했더니 700기가바이트라고 해보자. 하나에안올라갈텐데 이럴 경우에 네임노드 자체를 여러대로 운영해야되는 상황이 발생한다. 이를 페더레이션이라고 한다. 2.0에서는 네임 노드도 스케일 아웃 할 수 있도록 지원하고 있다. 국내에서 페더레이션을 하고 있다는 얘기는 들어본적 없다. 페더레이션이 되려면 2000개 노드 이상은 되어야하지않을까 생각한다.
아파치 주키퍼
하둡 에코시스템이 대부분 동물 아이콘을 마스코트로 가지고 있다.
이들을 관리하는 프로젝트라고해서 주키퍼라는 이름을 가졌다.
아래와 같은 목적으로 사용됨
- 설정관리
- 분산클러스터관리
- 명명 서비스
- 분산 동기화
- 분산 시스템에서 리더 선출
- 중앙집중형 신뢰성 있는 데이터 저장소
아파치 주키퍼 구성
- 주키퍼는 n 개의 서버로 단일 클러스터를 구성하며 이를 서버 앙상블 이라고 함
- 주키퍼 서비스는 복수의 서버에 복제되며, 모든 서버는 데이터 카피본을 저장
- Leader 는 구동 시 주키퍼 내부 알고리즘에 의해 자동 선정
- Followers 서버들은 클라이언트로부터 받은 모든 업데이트 이벤트를 리더에게 전달함
- 클라이언트는 모든 주키퍼 서버에서 읽을 수 있으며, 리더를 통해 쓸 수 있고 과반수 서버의 승인(합의)가 필요함
아파치 주키퍼 사용 예
분산 배타적 잠금
db에서 락 생각하면 쉽다. 동시에 하나의 파일에 같은 아이디에 서로 다른 어플리케이션이 데이터를 바꾸고자하면 데이터에 컨시터시나 이런거에 문젯가 생길 수 있기때문에 서버에 락을 잡는다. 락을 잡고있는애만 파일을 변경할 수 있다. 분산환경에서도 비슷한 상황이 생길 수 있다. 분산환경에서 락에 대한 기능을 보통 주키퍼로 해결한다.
2.0 이상부터는 주키퍼는 어떻게보면 하둡 클러스터 안에 들어가있는 하나의 구성 요소로 볼 수 있는 상황이다. 주키퍼는 하둡만이 사용하는 것도 아니다. 하이브도 나중에 버전이 올라가면 아파치 주키퍼를 사용하게된다.
<출처>
skplanet Tacademy 아파치 하둡 입문 세미나 내용
