🔴 SIC (Simplified Instructional Computer)
실제로 컴퓨터에서 자주 사용되는 하드웨어 기능은 포함하면서 복잡하거나 특이한 요소들은 배제한 가상의 컴퓨터
- SIC : 기본 표준 모델
- SIC/XE : 확장 모델
-> SIC 용으로 작성된 프로그램은 SIC/XE 머신에서도 실행 가능
Memory in General
-
단일 차원의 커다란 배열이며,
address는 해당 배열의 인덱스 역할을 하며 0부터 시작
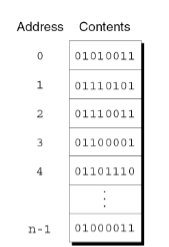
-
고정 크기 단위인 cell로 나누어지며, 각 cell은 고유한 식별자인 address와 연결
-
메모리의 어떤 위치든, 해당 주소만 지정하면 빠르게 접근 가능
-
프로그램과 데이터는 실행중일 때 Main Memory(주기억장치)에 저장
-
RAM은 CPU와 연결되어 있어 데이터가 빠르게 이동 가능
Memory in SIC
- 8비트 단위로 구성
- 하나의 word는 3-byte (24bit)
- 사용 가능한 메모리 최대 크기: bytes (32KB)
Registers in General
- CPU 내부에 존재하는 개별 고속 저장소
- 임시 데이터를 저장하는 데 사용
- 일부는 특정 목적을 위해 예약되어 있으며, 나머지는 계산 중 임시 저장소로 사용
Registers in SIC
각 24 bits
- A (0) : Accumulator - 기본적인 산술 연산 수행 시 사용
- X (1) : Index register - 주소 계산을 위한 인덱스 값 저장
- L (2) : Linkage register - 서브루틴으로 점프하기 전 되돌아올 주소 저장
- PC (8) : Program Counter - 다음에 실행할 명령어의 주소 저장
- SW (9) : Status Word - 비교 및 조건 분기 명령 등에 사용되는 조건 코드(Condition Code) 비트를 포함한 다양한 상태 정보 저장
괄호 안의 숫자: Register ID
Data Formats
- Integers는 24-bit 이진수로 저장
음수는 2의 보수 방식으로 표현 - Characters는 8-bit 아스키코드로 저장
- 부동소수점 연산을 위한 하드웨어는 없음
Machine Instrunction Formats
- 표준 SIC 버전의 모든 명령어는 24-bit 형식 사용
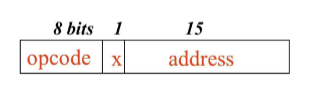
- Operation code 필드 (op code)
- 하드웨어가 인식하는, 기계어 연산마다 고유하게 지정된 숫자
- Address 필드
- 연산이 수행될 값이 위치한 메모리 주소
Addressing Modes in General
: 피연산자(operand)의 실제(target) 메모리 주소를 계산하는 방법을 지정
→ 레지스터에 저장된 값 또는 명령어에 포함된 상수 값 등을 사용
Addressing Modes in SIC
🔹 Direct Addressing Mode (직접 주소 지정 방식)
- x비트 = 0
Target Address = address
🔹Indexed addressing Mode (인덱스 주소 지정 방식)
→ assmbly 표현: label(주소),X
→ ex) LDCH BUFFER,X
-
object code의 bit값: x비트 = 1
Target Address = address + (X 레지스터 값)Target Address : CPU가 명령어를 실행할 때 실제 접근하는 메모리 주소
address: 명령어 내에 명시된 기본 주소 (연산의 기준이 되는 주소)
Instruction Set (명령어 집합)
= ISA(Instruction Set Architecture)
CPU가 인식하고 실행할 수 있는 모든 기계어 명령어의 집합
정의하는 것 :
명령어(instructions), 주소 지정 방식(addressing modes), 기본 데이터 타입(native data types), 레지스터(registers), 메모리 구조(memory architecture), 인터럽트(interrupt), 예외 처리(exception handling), 외부 입출력(external I/O)
🟡Basic set of instructions provided by SIC
🟨 메모리로부터의 읽기/쓰기(Load or Store) 명령어
LDA, LDX, STA, STX, ...
🔹LDA m
→ A ⇐ (m..m+2)
→ 여기서 A는 레지스터, m은 메모리 주소
→ 메모리 주소 m부터 m+2까지의 내용을 레지스터 A에 로드
🔹STA m
→ m..m+2 ⇐ (A)
→ 레지스터 A의 값을 주소 m부터 시작하는 메모리에 저장
🟨 정수 산술 연산 명령어
모든 산술 연산은 레지스터 A와 메모리에 있는 값을 대상으로 수행되며, 결과는 레지스터 A에 저장됨.
ADD, SUB, MUL, DIV
🔹ADD m
→ A ← A + (m..m+2)
→ A에 있는 값과 메모리(m~m+2)의 값을 더해서 A에 다시 저장
→ A += [메모리 값]
🔹 SUB m
→ A ← A - (m..m+2)
→ A 값에서 메모리의 값을 빼서 A에 저장
→ A -= [메모리 값]
🔹 MUL m
→ A ← A * (m..m+2)
→ A와 메모리 값을 곱해서 A에 저장
DIV m
→ A ← A / (m..m+2)
→ A를 메모리 값으로 나눈 결과를 A에 저장
🟨 비교 명령어
🔹 COMP m
→ COMP m ? (A) : (m..m+2)
→ 레지스터 A의 값과 메모리 주소 m~m+2의 값을 비교
→ 그 결과에 따라 SW(Status Word)의 CC(조건 코드) 값 설정
-
CC(조건 코드)의 설정 방식:
-
A < M: CC =01 -
A = M: CC =00 -
A > M: CC =10
-
🟨 조건 분기 명령어 (Conditional Jump)
CC 값을 확인하고, 조건이 참이면 PC 레지스터에 지정된 주소로 분기(Jump)
JLT, JEQ, JGT
🔹JLT m
→ PC ← m if CC가 '작다(01)'로 설정되어 있을 때 점프
🔹JEQ m
→ PC ← m if CC가 '같다(00)'일 때 점프
🔹JGT m
→ PC ← m if CC가 '크다(10)'일 때 점프
🟨 서브루틴 연결 (Subroutine linkage)
JSUB, RSUB
🔹JSUB m
→ L ← (PC) ; PC ← m
→ 복귀 주소를 레지스터 L에 저장하고 서브루틴 주소 m으로 점프
🔹RSUB
→ PC ← (L)
→ 레지스터 L에 저장된 주소로 복귀
🟨 입출력 (I/O)
- 레지스터 A의 가장 오른쪽 8비트를 통해 1바이트씩 전송 또는 수신
- 각 장치(device)는 고유한 8비트 코드를 부여받음
TD(Test Drive), RD(Read Data), WD(Write Data)
🔹TD m
→ 주소 m에 해당하는 장치가 데이터 송수신 준비가 되었는지 검사
→ 장치가 준비되었으면: 상태 레지스터 SW의 CC 값이 < (01)로 설정됨
→ 준비되지 않았으면: CC 값이 = (00)으로 설정됨
🔹RD m
→ A[가장 오른쪽 1바이트] ← 장치(m)로부터 받은 데이터
→ 주소 m에 해당하는 장치로부터 1바이트 데이터를 읽어와 레지스터 A의 가장 오른쪽 바이트에 저장
🔹WD m
→ 장치(m) ← A[가장 오른쪽 1바이트]
→ 레지스터 A의 오른쪽 1바이트 값을 주소 m에 해당하는 장치에 쓰기
🟨 인덱스 관련 명령어
🔹TIX m
→ X ← X + 1 하고, 그 값을 주소 (m~m+2)의 값과 비교해 CC 설정
🟡 Directives
⚠️ Directive는 Object code로 번역되지 않음
→ Just 어셈블러에게 필요한 정보를 제공하기 위한 용도
→ 주의: BYTE, WORD (데이터 정의용 directive)
→ 메모리에 값을 저장해야 하기 때문에 Assembler가 저장할 데이터 값을 Object Code로 변환하여 포함시킴
🔹 START
→ 프로그램의 이름과 시작 주소를 지정함
COPY START 1000
: COPY라는 이름의 프로그램을 주소 1000번지부터 시작하겠다
🔹 END
→ 소스 프로그램의 끝
→ (optional) 가장 먼저 실행될 명령어의 위치 지정 가능
FIRST STL RETADR
...
END FIRST: 프로그램은 FIRST 레이블에서부터 실행을 시작해라
🔹 BYTE
→ character 또는 hexadecimal constant(16진수 상수)를 메모리에 정의하고 저장할 때 사용
→ constant를 표현하는 데 필요한 만큼의 byte 수만큼 메모리 차지
-
형식
BYTE C'...': character 상수BYTE X'...': 16진수 상수
-
예시
INPUT BYTE X'F1'
:16진수 한 자리는 4bits를 나타냄
:F1은 16진수 2자리 → 1byte
:INPUT이 데이터가 저장될 메모리 위치에 붙이는 라벨 이름
:BYTE(1바이트) 데이터를 정의하겠다는 지시어
:X'F1'저장할 16진수 상수 값 (F1)
EOF BYTE C'EOF'
: 각각의 문자는 ASCII 코드 1byte(8bits)로 표현됨
: character 'EOF' → ASCII 코드 3bytes
:EOF이 데이터가 저장될 메모리 위치에 붙이는 라벨 이름
:BYTE(3바이트) 데이터를 정의하겠다는 지시어
:C'EOF'저장할 character 상수 (EOF)
🔹 WORD
→ 1워드(3바이트) 크기의 integer constant 정의, 저장
THREE WORD 3 : 정수 3을 워드 크기로 저장
🔹 RESB
→ 지정한 바이트 수만큼 메모리 공간 예약 (데이터 저장용)
BUFFER RESB 4096: 4096바이트 공간 확보
🔹 RESW
→ 지정한 워드 수(1워드 = 3바이트)만큼 공간 예약
RETADR RESW 1: 워드 1개 (3바이트) 공간 확보
🔴 SIC/XE
SIC machine 및 assembly program 상위호환 지원
SIC/XE Assembler
- 가능한 경우 register-to-register 명령어 사용 (예:
COMPR A, S)
→ 더 짧고, 다른 메모리 접근이 필요하지 않기 때문 - 가능한 한 immediate addressing(즉시 주소 지정) 및 indirect addressing(간접 주소 지정) 사용
➡️ 프로그램의 실행 속도 향상
Memory
사용 가능한 최대 메모리: 1MB (2²⁰ bytes)
Registers
SIC의 5개 레지스터에 추가로 4개 레지스터(B, S, T, F)가 더 존재
-
B (3): 베이스 레지스터 – 주소 지정에 사용됨 (24 bits)
-
S (4), T (5): 범용 레지스터 – 특별한 용도 없이 일반 작업용 (24 bits)
-
F (6): 부동 소수점 누산기(Floating-point Accumulator) (48 bits)
Data Formats
표준 버전(SIC)과 동일한 데이터 형식을 사용하되, 추가로 48비트 부동 소수점 데이터 타입 지원
Machine Instrunction Formats
🔹Format 1 (1 byte)
메모리 참조 없음

🔹Format 2 (2 byte)
메모리 참조 없음 (2바이트) – 레지스터 연산용

🔹Format 3 (3 byte)
Relative Addressing (상대 주소 지정)
e 비트 = 0
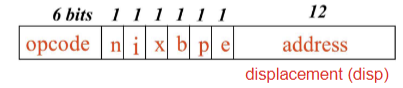
🔹Format 4 (4 byte)
주소 필드 확장 – 20비트 주소 사용
e 비트 = 1
→ assmbly 표현: +명령어
→ ex) +JSUB RDREC

Addressing Modes
🔹Relative addressing (상대 주소 지정)
Format 3에서 사용
-
Base Relative addressing
→b=1, p=0
→ TA = (B) + disp/addr
→ (B 레지스터 값 + 변위) -
PC Relative addressing
→b=0, p=1
→ TA = (PC) + disp/addr
→ (프로그램 카운터 + 변위)
🔹Direct addressing (직접 주소 지정)
→ b=0, p=0
→ TA = disp/addr (변위 자체를 주소로 사용)
- ❌ b=1, p=1은 불가능한 조합 (오류)
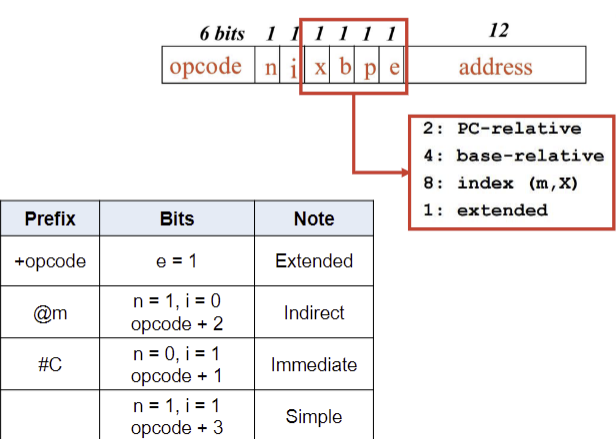
🔹Immediate Addressing (즉시 주소 지정)
→ object code의 bit값: n=0, i=1
→ assmbly 표현: #피연산자
→ ex) COMP #0
→ 메모리를 참조하지 않고, 주소 필드에 들어있는 값 자체가 피연산자 값으로 사용됨
→ 피연산자가 메모리 내부에 포함되어 있기 때문에 어디서 가져올 필요 없이 바로 사용 가능
🔹Indirect Addressing (간접 주소 지정)
→ object code의 bit값: n=1, i=0
→ assmbly 표현: @피연산자(주소)
→ ex) J @RETADR
→ 주소 필드에 있는 값을 메모리 주소로 간주하고, 해당 주소에 있는 값을 다시 참조
→ SIC에 비해 종종 추가적인 명령어를 사용할 필요 없이 처리 가능
🔹Simple Addressing for SIC (SIC용 단순 주소 지정)
→ n=0, i=0
→ 전통 SIC 방식
→ b, p, e 비트가 주소 계산 필드로 사용됨
🔹Simple Addressing for SIC/XE (SIC/XE용 단순 주소 지정)
→ n=1, i=1
❌ 인덱스 주소 지정(Indexing)은 즉시 주소 지정(immediate) 또는 간접 주소 지정(indirect)과 함께 사용 불가
🟡 Instruction Set
표준(SIC) 버전의 모든 명령어 사용 가능
🟨 Load/Store 명령어
LDB, STB, ...
🟨 부동 소수점 산술 연산 명령어
ADDF, SUBF, MULF, DIVF
🔹 ADDF m
→ F ← (F) + (m..m+5)
→ 레지스터 F와 메모리 주소 m부터 m+5까지의 6바이트 값을 더함
🟨 레지스터 간 연산 명령어
RMO, ADDR, SUBR, MULR, DIVR
🔹RMO r1, r2
→ r2 ← (r1)
→ r1의 값을 r2에 복사
🔹ADDR r1, r2
→ r2 ← (r2) + (r1)
→ 두 레지스터 값을 더해 r2에 저장
🟨 레지스터 간 비교 명령어
🔹COMPR r1, r2
→ r1, r2는 값을 비교할 두 레지스터
→ 결과는 Condition Code(CC)에 저장
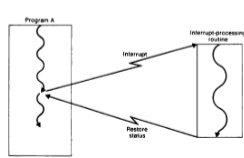
🟨 Supervisor Call (SVC)
🔹SVC n
→ 운영체제와의 통신을 위한 SVC 인터럽트 생성
→ n은 supervisor call 번호 (즉, 인터럽트 번호)
운영체제의 인터럽트 처리 루틴 수행 완료 후 원래 프로그램으로 복귀
🟨 입출력 (I/O)
SIC의 입출력 명령어들은 SIC/XE에서도 사용 가능
추가적으로, 입출력 채널(I/O channels)을 통해 CPU가 다른 명령을 실행하는 동안 입출력 수행 가능
▫️ I/O 채널이란?
CPU 대신 입출력 작업을 수행하는 단순한 처리 장치
👉 계산과 입출력의 병행 처리가 가능하여, 더 효율적인 시스템 운영 가능
🔹SIO
→ 지정된 장치의 입출력 작업을 시작하라는 명령
🔹TIO
→ 장치가 작업을 마쳤는지 또는 준비되었는지 확인
🔹HIO
→ 지정된 장치의 입출력 작업을 중단시킴
🟡 Directives
🔹 BASE
→ Base 레지스터에 어떤 주소가 들어갈 예정인지 어셈블러에게 알려줌
→ BASE LENGTH
→ 앞으로 base-relative 주소 계산할 때 LENGTH 주소를 기준으로 하라는 의미
🔹 NOBASE
→ Base-relative 주소 지정 방식을 더 이상 사용하지 않도록 어셈블러에게 지시하는 것
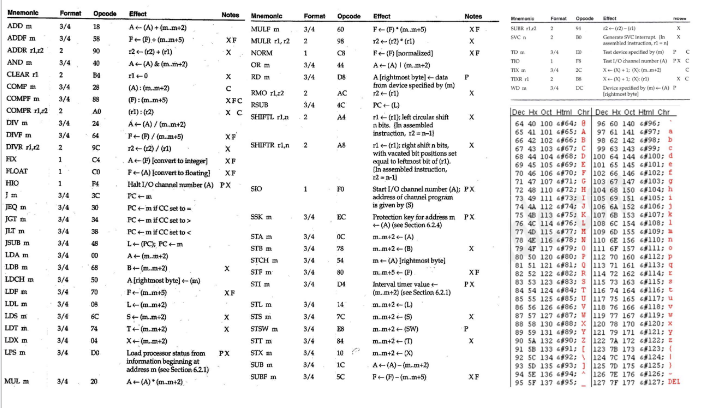
Appendix
아래 Appendix에는 SIC 및 SIC/XE의 모든 명령어 목록,
그에 해당하는 opcode(연산 코드),
그리고 각 명령어가 수행하는 기능의 설명이 포함되어 있음
🔴 실제 Machine Architecture
CISC (Complex Instruction Set Computers)
- 크고 복잡한 명령어 집합을 제공
- 서로 다른 명령어 형식과 길이가 존재
- 다양한 주소 지정 방식(addressing mode) 지원
- 하드웨어 구현이 복잡해지는 경향이 있음
RISC (Reduced Instruction Set Computers)
- 적은 수의 기계어 명령어, 명령어 형식, 주소 지정 방식만 사용
- 표준화된 고정 길이의 명령어 형식, 단일 사이클 실행
- 장점(Advantages):
- 프로세서 설계를 단순화할 수 있음
- 더 빠르고 저렴한 프로세서 개발이 가능
- 더 높은 신뢰성과 빠른 명령어 실행 시간 제공
ARM(Acorn RISC Machine) Architecture
이후에는 Advanced RISC Machine으로 불림
-
ARM 컴파일러 도구 체인 (Toolchain)
Compiler + Assembler로 구성
→ 고급 언어(C/C++ 등)를 어셈블리 코드로 변환 -
고급 언어 → ARM 어셈블리 변환 예시
💻 고급 언어 (C 스타일):
while (i != j) {
if (i > j) i -= j;
else j -= i;
}⚙️ 컴파일 후 ARM 어셈블리 코드:
loop: CMP Ri, Rj ; i와 j 비교 → "NE" 조건 설정 (i ≠ j)
SUBGT Ri, Ri, Rj ; i > j 이면 Ri = Ri - Rj
SUBLT Rj, Rj, Ri ; i < j 이면 Rj = Rj - Ri
BNE loop ; i ≠ j이면 loop로 점프