SIC
data, character 이동 연산

-
Instruction
LDA FIVE: 레지스터 A ← FIVE에 있는 값 (5)
STA ALPHA: 레지스터 A에 있던 값(5)을 ALPHA 주소에 저장
LDCH CHARZ: 레지스터 A의 오른쪽 1바이트 ← CHARZ에 저장된 문자('Z')
STCH C1: A의 오른쪽 1바이트('Z')를 C1 주소에 저장 -
데이터 정의 (Directive)
ALPHA RESW 1: 1개의 WORD를 위한 3바이트 공간 예약
FIVE WORD 5: 정수 5를 3바이트 크기로 메모리 주소 FIVE에 저장
CHARZ BYTE C'Z': 문자 'Z'를 1바이트 크기로 메모리 주소 CHARZ에 저장
C1 RESB 1: 1바이트 공간 예약
ALPHA, FIVE, CHARZ, C1 : 메모리 주소에 대한 label (=메모리 주소에 붙인 이름)
산술 연산

-
Instruction
LDA ALPHA: ALPHA에 저장된 값을 레지스터 A로 로드
ADD INCR: A ← (A) + INCR에 저장된 값
SUB ONE: A ← (A) - ONE (즉, 1을 뺌)
STA BETA: 결과값을 BETA 주소에 저장 -
데이터 정의 (Directive)
ONE WORD 1: 정수 1을 3바이트로 저장
ALPHA RESW 1: 3바이트 공간 예약 (초기값 없음)
BETA RESW 1: 3바이트 공간 예약
INCR RESW 1: 3바이트 공간 예약
Looping, Indexing 연산
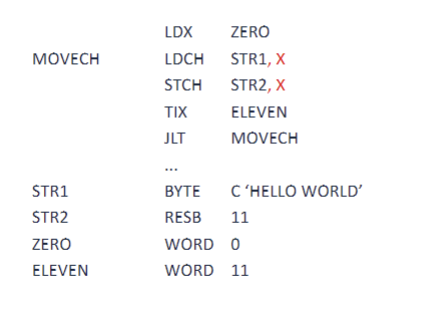
"HELLO WORLD"라는 문자열을 STR1 → STR2로 복사
-
Instruction
LDX ZERO: X 레지스터 ← 0 (복사 시작 인덱스)
MOVECH LDCH STR1,X: STR1[X]에 있는 문자 1바이트를 A 레지스터의 오른쪽 바이트에 로드
STCH STR2,X: A의 오른쪽 바이트를 STR2[X]에 저장
TIX ELEVEN: X ← X + 1 후, X를 ELEVEN(11)과 비교하고 CC 설정
JLT MOVECH: CC가 <일 경우, MOVECH 라벨로 점프 (계속 복사: 루프 반복) -
데이터 정의 (Directive)
STR1 BYTE C'HELLO WORLD': STR1에 "HELLO WORLD"를 11바이트로 저장
STR2 RESB 11: STR2에 11바이트 공간 확보 (복사 대상)
ZERO WORD 0: 정수 0을 3바이트 크기로 메모리 주소 ZERO에 저장 (초기 인덱스 값, X레지스터 시작값)
ELEVEN WORD 11: 정수 11을 3바이트 크기로 메모리 주소 ELEVEN에 저장 (루프 종료 조건)
입출력 연산

입력 장치에서 데이터를 읽어와서, 출력 장치를 통해 출력
- Instruction
- 입력 루틴 (INLOOP)
INLOOP TD INDEV: INDEV 장치 준비 상태 검사 후 CC 설정
JEQ INLOOP: 준비 안 됐으면 계속 검사 (INLOOP 라벨로 점프)
RD INDEV: INDEV 장치에서 1바이트 읽어서 A 레지스터의 가장 오른쪽 바이트에 저장
STCH DATA: A의 오른쪽 바이트 → DATA 메모리에 저장 - 출력 루틴 (OUTLP)
OUTLP TD OUTDEV: OUTDEV 장치 준비 상태 검사 후 CC 설정
JEQ OUTLP: 준비 안 됐으면 계속 검사 (OUTLP 라벨로 점프)
LDCH DATA: DATA에 있는 1바이트 → A 레지스터 오른쪽 바이트로 로드
WD OUTDEV: A의 오른쪽 바이트를 OUTDEV 장치로 출력
- 입력 루틴 (INLOOP)
- 데이터 저장 (Directive)
INDEV BYTE X'F5': 입력 장치 코드 F5를 1바이트 크기로 저장 (예: 장치 번호 F5h)
OUTDEV BYTE X'08': 출력 장치 코드 08을 1바이트 크기로 저장 (예: 장치 번호 08h)
DATA RESB 1: 1바이트 데이터 저장용 공간
Assembly source code에서 Object code로 변환하는 과정은 해당 링크에서 확인할 수 있다.
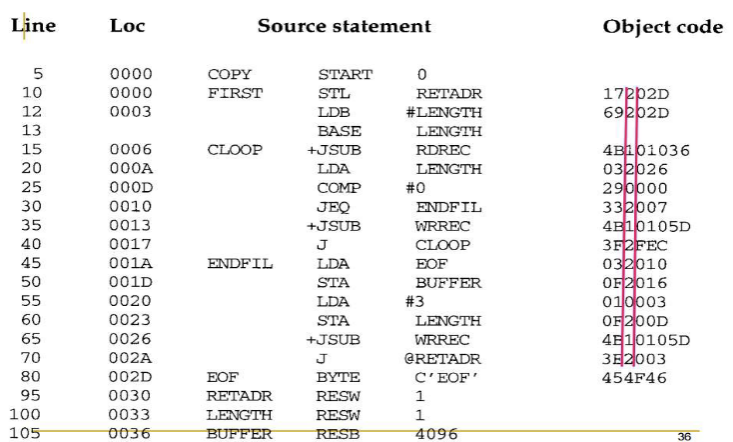
COPY program (Assembly listing file)

⚠️ Notice
- Line numbers는 참고용. 프로그램의 일부 X
- Index Addressing은 피연산자(operand) 뒤에
,X를 붙여서 나타냄 - "."으로 시작하는 줄은 전부 주석
- ‘Loc’ column: 프로그램이 어셈블될 때, 각 명령문이 배치되는 machine address(16진수)
프로그램 설명
JSUB 명령어로 COPY 프로그램 호출 → COPY 프로그램 → RSUB 명령어로 COPY 프로그램 종료(control을 OS로 반환) 후 RETADR에 저장된 주소(다음에 실행될 주소)로 복귀
🔹 Main Routine: COPY
입력 장치(장치 코드 F1)로부터 레코드를 읽어와 버퍼(최대 4096바이트) 에 저장한 후 출력 장치(장치 코드 05) 에 레코드를 출력, 파일의 끝이 감지되면 출력장치에 EOF를 쓰고 프로그램 종료
입력 장치 → RDREC → [Assembly Program - Buffer] → WRREC → 출력 장치
🔸 Subroutine
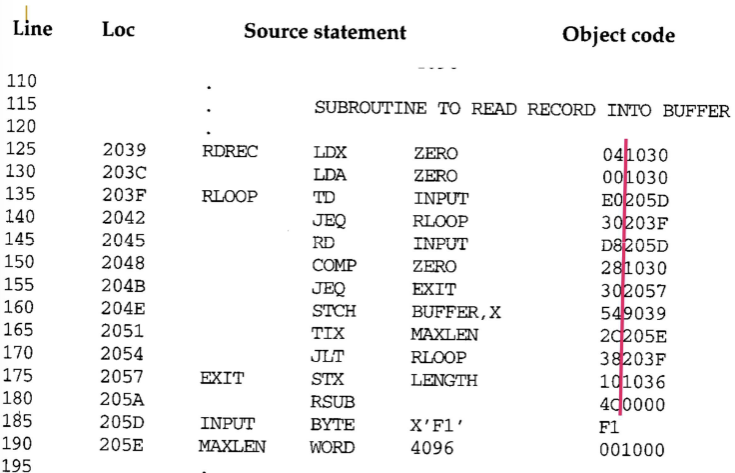
RDREC- 입력 장치로부터 레코드 한 개를 버퍼에 읽어들임
- 1문자씩 RD 명령어로 읽기
WRREC- 버퍼에 저장된 레코드 한 개를 출력 장치로 전송
- 1문자씩 WD 명령어로 쓰기
▫️RECORD
- 하나의 레코드는 여러 문자로 구성
- 각 서브루틴은 레코드를 한 문자씩 전송해야 함
→ 사용 가능한 I/O 명령어는 RD (읽기), WD (쓰기) 뿐이기 때문 (한 문자 단위 처리) - 각 레코드의 끝은 null character(16진수 00) 로 표시됨
▫️버퍼가 필요한 이유
- 입력 장치와 출력 장치 간의 I/O 속도가 다르기 때문
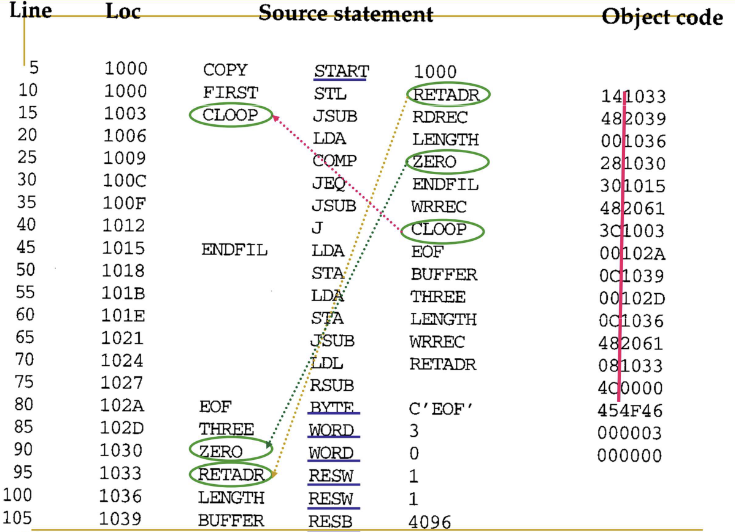
COPY program (Object Program)
Object program의 Format을 보며 위의 COPY program (Assembly listing file)에 대응되는 아래의 COPY program (Object Program)을 해석해보자.

⚠️ Notice
-
^기호는 필드를 시각적으로 구분하기 위해 사용된 것
→ 실제 오브젝트 프로그램 안에는 이런 기호 존재 X -
주소 1033 ~ 2038에 해당하는 오브젝트 코드 존재 X
→ 프로그램이 실행될 때, Loader가 실행 중 필요한 데이터를 저장할 수 있도록 메모리를 확보하기 위한 공간
→ 어셈블리 코드 상에서RESW,RESB등의 Directive(지시어) 에 의해 지정됨
프로그램 설명
🔹Header Record
H^COPY ^001000^00107A-
Line 5에서 source가
START 0x1000이므로, 프로그램 시작 주소는1000이 된다. -
프로그램의 전체 길이
107A= 프로그램 끝 주소2079- 프로그램 시작 주소1000+ 1-
프로그램이 끝나는 주소가
207A인 이유는?Line 250에서 시작 주소가
2079이고, 이 주소에서의 directive는BYTE이다. 이 지시어는 16진수 상수X05를 저장하고 있으며, 이는 1byte의 공간을 차지한다. 그러므로 끝 주소는2079이다. 주소는 1000부터 시작하므로 2079 - 1000 + 1 = 107A가 되어, 프로그램의 길이는107A가 된다.
-
🔹Text Records
텍스트 레코드 1개당 최대 30 bytes (즉, 60 hex digits - 보통 10개의 instructions)까지의 object code만 담을 수 있으므로, 이에 맞게 텍스트 레코드를 여러 개로 나누게 된다. 주소가 연속되지 않는 경우(Directive로 인해 object code가 없는 경우)에도 텍스트 레코드를 나누는 기준이 된다.
T^001000^1E^141033^...^00102D이 레코드에 포함된 오브젝트 코드의 시작 주소는 1000이고, 141033부터 00102D까지 10개의 object code를 포함하고 있어 길이는 1E(30bytes)이다.
T^00101E^15^0C1036^482061^081033^4C0000^454F46^000003^000000위 레코드를 해석하며 혼란이 생겼었다.
❌ 잘못된 생각
모든 Directive는 object code로 번역되지 않는 줄 알았지만, BYTE와 WORD는 실제로 Object Code로 변환되어 포함되고 있었다.
⭕ FACT
BYTE와 WORD는 메모리에 값을 저장해야 하기 때문에 Assembler가 저장할 데이터 값을 Object Code로 변환하여 포함시킨다!
Directive인 BYTE와 WORD 자체는 명령어가 아니므로 Object Code로 변환되지 않는다.
이 레코드에 포함된 오브젝트 코드의 시작 주소는 101E이고, 길이는 15(16진수 15이므로 21bytes)이다.
또한, Line 95부터는 object code로 변환되지 않으므로, Line 90(시작주소 1030)까지만 이 텍스트 레코드에 담게 된다.
⚠️ 여기서 주의할 것!
Line 80의 BYTE 지시어는 C'EOF'를 저장하고 있으며,
이는 3개의 문자(E, O, F)를 저장하는 것이므로 3바이트 공간을 차지한다.
-
EOF는 ASCII CODE로 각각
0x45,0x4F,0x46이므로 object code가454F46이 된다. 만약C'EFGHI'가 저장되어있었다면, object code는4546474849가 되고, 총 5바이트를 차지하게 될 것이다.➡️
BYTE는 저장한 데이터의 바이트 수 만큼,WORD는 고정 3바이트를 차지한다.
🔹End Record
E^001000실행이 처음 시작될 명령어의 주소는 1000이다.
🤔 Assembly Listing file vs Object Program
위의 두 SIC 프로그램 COPY 예제를 살펴보았다면 궁금증이 발생할 것이다.
Assembly Listing file과 Object Program은 각각 무슨 역할을 하며 왜 생성된 것일까?
아래 링크를 통해 확인할 수 있다.
Assembly Listing file vs Object program
SIC/XE
data, character 이동 연산
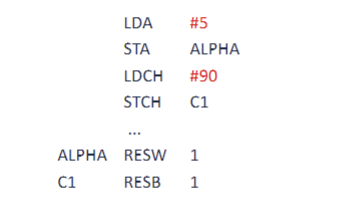
#: Immediate Addressing
사용법:#operand(피연산자)
LDA #5: 5라는 상수 그 자체를 A 레지스터에 로드
LDCH #90: ASCII CODE 90(문자 'Z')를 레지스터에 로드
COPY program (Assembly listing file)