데이터 모델 절차
개념적 데이터 모델 → 논리적 데이터 모델 → 물리적 데이터 모델
개념적 데이터 모델
- 현실 세계에 대한 인식을 추상적, 개념적으로 표현 → 개념적 구조 도출
- 트랜잭션 모델링, View 통합방법 및 Attribute 합성 고려
- DB종류와 관계 없음
- 주요 산출물: 개체관계 다이어그램(ERD)
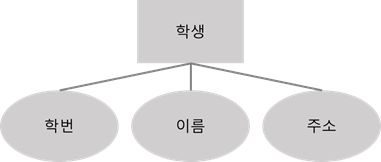
논리적 데이터 모델
논리 데이터 모델링 속성
- 개체(Entity): 사물 또는 사건으로 정의 / 사각형 표시
- 속성(Attributes): 개체가 가지고 있는 요소 또는 성질 / 타원 표시
- 관계(Relationship): 두 개체 간의 관계 정의 / 마름모 표시
논리적 데이터 모델링 종류
-
관계 데이터 모델
논리적 구조가 2차원 테이블 형태로 구성
기본키(PK)와 이를 참조하는 외래키(FK)
1:1, 1:N, N:M 관계
[관계 데이터 모델의 구성요소]
-
릴레이션: 행(Row)과 열(Column)로 구성된 테이블
-
튜플(Tuple): 릴레이션의 행(Row)에 해당되는 요소
-
속성(Attribute): 릴레이션의 열(Column)에 해당되는 요소
-
카디널리티(Cardinality): 튜플(Row)의 수
-
차수(Degree): 애트리뷰트(Column)의 수
-
스키마(Schema): 데이터베이스의 구조, 제약조건 등의 정보를 담고 있는 기본적인 구조
-
인스턴스(Instance): 정의된 스키마에 따라 생성된 테이블에 실제 저장된 데이터의 집합
[관계 대수]
관계형 DB에서 원하는 정보와 그 정보를 어떻게 유도하는 가를 기술하는 절차적 정형 언어
-
일반 집합 연산자
수학의 집합 개념을 릴레이션에 적용한 연산자
- 합집합(Union)
- 교집합(Intersection)
- 차집합(Difference)
- 카티션 프로덕트(CARTESIAN Product)
-
순수 관계 연산자
관계 DB에 적용할 수 있도록 특별히 개발한 관계 연산자
- 셀렉트(Select)
- 프로젝트(Project)
- 조인(Join)
- 디비전(Division)
-
-
계층 데이터 모델
논리적 구조가 트리 형태로 구성
상하관계만 존재(부모 개체 - 자식 개체)
1:N 관계
-
네트워크 데이터 모델
논리적 구조가 그래프 형태로 구성
N:M 만족
정규화(Normalization)
관계형 데이터 모델에서 데이터의 중복성을 제거하여 이상 현상을 방지하고, 데이터의 일관성과 정확성을 유지하기 위해 무손실 분해하는 과정
[이상 현상]
(정규화를 하지 않았을 때)데이터의 중복성으로 인해 릴레이션을 조직할 때 발생하는 비합리적 현상
- 삽입 이상: 정보 저장 시 해당 정보의 불필요한 세부 정보를 입력해야하는 경우
- 삭제 이상: 정보 삭제 시 원치 않는 다른 정보가 같이 삭제되는 경우
- 갱신 이상: 중복 데이터 중에서 특정 부분만 수정되어 중복된 값이 모순을 일으키는 경우
데이터베이스 정규화 단계 - 원부이 결다조
- 1정규형(1NF): 원자값으로 구성
- 2정규형(2NF): 부분 함수 종속 제거(완전 함수적 종속 관계)
- 3정규형(3NF): 이행 함수 종속 제거
- 보이스-코드 정규형(BCNF): 결정자 후보 키가 아닌 함수 종속 제거
- 4정규형(4NF): 다치(다중 값) 종속 제거
- 5정규형(5NF): 조인 종속 제거
반 정규화(De-Normalization)
정규화된 엔터티, 속성, 관계에 대해 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법
비정규화, 역정규화라고도 함
[장점] 성능 향상과 관리의 효율성 증가
[단점] 데이터의 일관성 및 정합성 저하
[기법] - 테병분중 컬중 관중...
- 테이블 병합
- 테이블 분할
- 테이블 중복 테이블 추가
- 컬럼 중복화
- 중복 관계 추가
