Windowing이란
사용자에게 보이는 것만 렌더링하는 개념.
사용자가 스크롤을 하면 스크롤에 따라 보이는 콘텐츠의 창이 움직인다. 이 때 창에서 벗어나는 DOM 노드는 재활용되거나, 사용자가 목록을 스크롤 할 때 새로운 요소로 즉시 교체하면 창 크기게 따라 렌더링 된 모든 요소의 수를 유지할 수 있다.
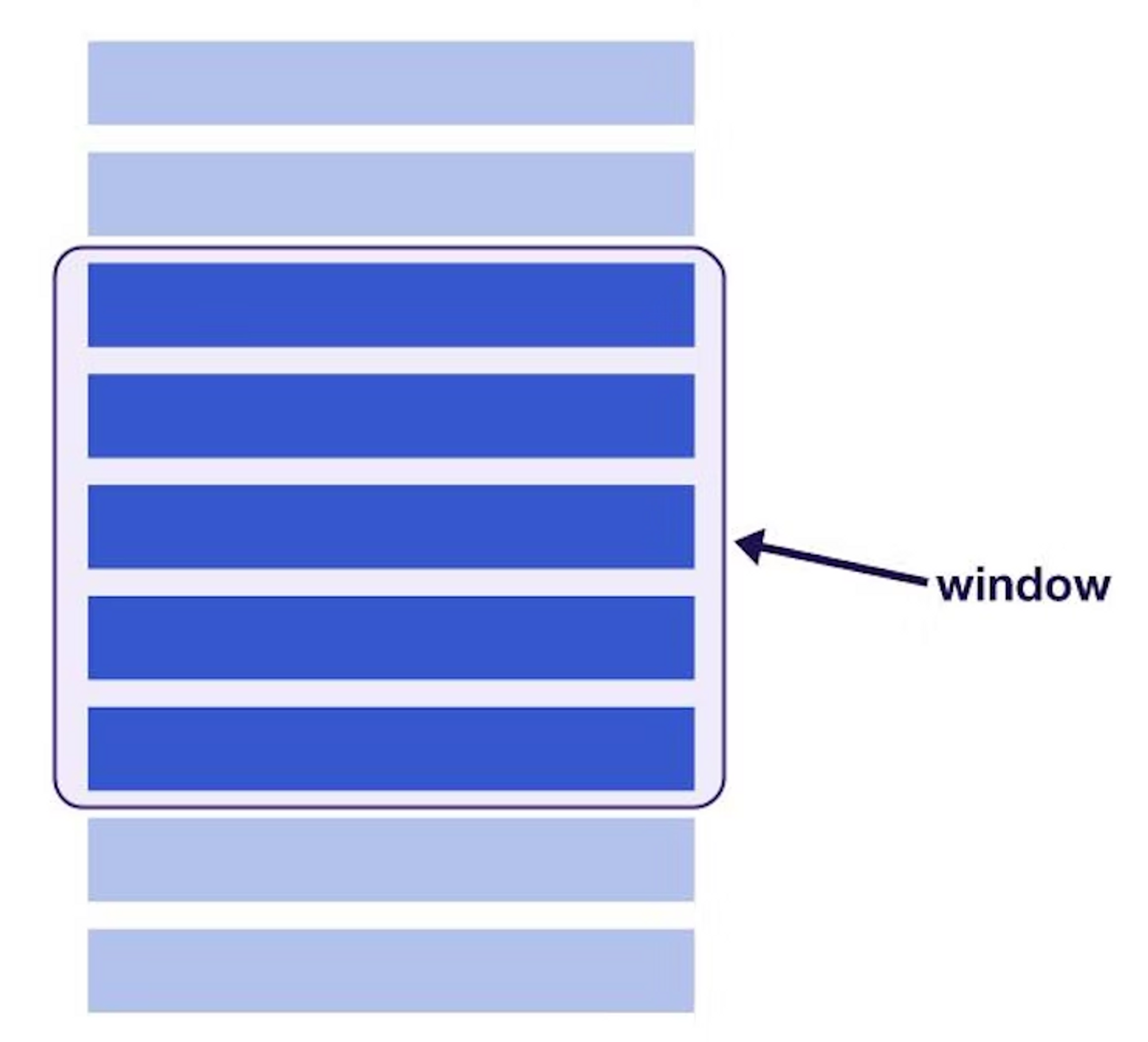
Windowing을 적용하게 된 계기
Knoticle(링크)이라는 블로그 서비스를 팀 프로젝트로 진행했는데, 해당 서비스의 검색페이지에는 무한스크롤이 적용되어있다. 검색어를 입력하면 우선 일정 개수의 데이터를 받아오고, 페이지를 아래로 스크롤하면 추가로 데이터를 더 받아오는 형식이다. 그러다보니 계속 스크롤을 할 경우 검색페이지에 너무 많은 DOM 요소가 쌓이게 되었다. 이는 무한스크롤의 대표적인 단점 중 하나인데, DOM 요소가 쌓일 경우 스크롤 시 버벅이는 현상이 발생한다.
하지만 사실 100개 이상의 데이터를 넣어서 테스트 해봤을 때 눈에 띄는 버벅임은 없었다(…)
brunch와 medium에선 어떻게 하고 있는지 살펴봤는데 windowing 적용없이 무한스크롤 시 DOM 요소가 계속해서 추가되고 있었다. 스크롤을 굉장히 많이 내려봤을 때에도 마찬가지로 딱히 버벅이는 현상은 없었다.
그럼에도 windowing을 적용하기로 한 이유는, 화면에 보여줄 객체만 그리기 때문에 렌더링 속도를 높일 수 있었기 때문이다.
현재 검색 페이지에서 페이지를 이동해도 검색 결과를 보존하기 위해서 검색 결과를 세션스토리지에 저장하고 있다. 이를 초기 접속 시 한꺼번에 렌더링하다보니, scripting과 layout에 너무 많은 시간이 소요되고 있었다. 아래와 같이 속도가 느리다는 걸 확연히 느낄 수 있을 정도였다.

이를 개선하기 위해서 스크롤 위치만 저장하고 → 스크롤 위치에 따라 받아올 페이지를 계산해서 해당 페이지의 데이터만 요청하고 → 위, 아래로 스크롤함에 따라 데이터를 불러오도록 구현할 수도 있었다.
하지만 windowing을 적용하는 것을 택한 이유는 1) 점진적으로 개선해보고 싶었기도 하고, 2) 이에 더해 DOM 요소의 수를 줄일 수 있다는 장점이 있었기 때문이다.
검색 결과를 렌더링하는 부분을 windowing 라이브러리에서 제시한 문법에 따라 바꿔주면 쉽게 적용할 수 있으리라고 생각했다.
React-window 라이브러리
React-virtualized보다 패키지 사이즈가 작다. (896kb vs 2.27mb)
검색페이지 요소들 높이가 모두 고정되어 있기도 하고 많은 추가 기능이 필요 없기에 위 라이브러리를 선택했다.
불편했던 점
그러나 위 라이브러리를 사용하면서 몇 가지 불편한 점들이 있었다.
-
무조건 다음과 같은 문법으로 사용해야 한다.
import { FixedSizeList as List } from 'react-window'; const Row = ({ index, style }) => ( <div style={style}>Row {index}</div> ); const Example = () => ( <List height={150} itemCount={1000} itemSize={35} itemData={{ articles, keywords }} width={300} > {Row} </List> );<List>컴포넌트는 아이템들을 감싸고 있는 컨테이너라고 생각하면 되고,Row는 각 아이템 요소를 의미한다.itemCount를 지정하면 개수만큼의Row컴포넌트를 생성하고, 각Row컴포넌트를 생성할 때index를 넘겨준다.- Row 컴포넌트 안에서 index를 통해 어떤 데이터를 표시할 지 결정할 수 있다. 이 때 데이터는
List컴포넌트의itemDataprops로 넘겨준다. (아래에 전체 코드가 있으니 참고)
여기서,
{Row}의 위/아래에 다른 요소를 넣어줄 수 없다.기존 코드에서 무한스크롤의 타겟 요소가 아이템들의 가장 하단에 위치했는데, 위 문법을 따를 경우 타겟 요소를 따로 넣어주기가 어려웠다.
→ react-window-infinite-loader라는 라이브러리를 함께 사용해서 해결할 수 있다.
-
리스트들이 들어있는 컨테이너의 높이(height)를 지정해줘야 한다.
1번과도 얽혀있는 불편한 점이긴 한데, 기존에는 리스트들이 들어있는 컨테이너의 높이를 따로 지정해주지 않았다. 따라서 검색 결과의 높이 합이 페이지 높이를 초과할 경우 아래와 같이 전체 스크롤이 생기게 되었다.
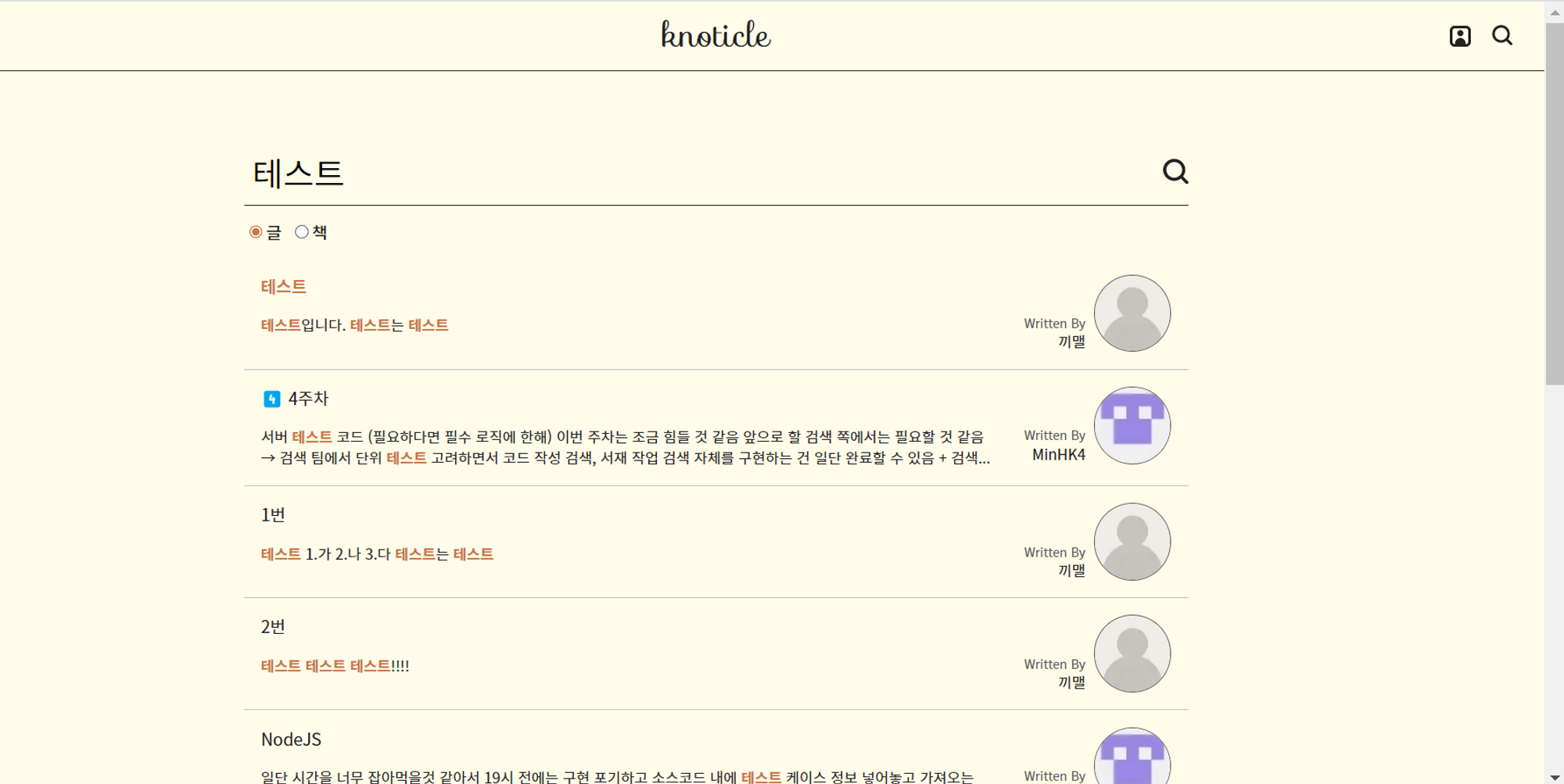
하지만 해당 라이브러리를 사용할 경우 windowing이 적용되는 요소(리스트들의 컨테이너)의 높이를 지정해줘야 하고, 높이를 초과할 경우 아래와 같이 내부 스크롤이 생긴다.

기존 형태를 원했지만 달리 방법은 없었기에 조금 양보해서 아래 형태를 채택하되, 추후에 사용자가 스크롤을 내리면 검색바가 숨겨지도록 개선해보기로 결정했다.
완성된 코드
import AutoSizer from 'react-virtualized-auto-sizer';
import { FixedSizeList as List } from 'react-window';
import InfiniteLoader from 'react-window-infinite-loader';
...
<ArticleListWrapper>
<AutoSizer>
{({ height, width }) => (
<InfiniteLoader
isItemLoaded={isItemLoaded}
itemCount={articles.length}
loadMoreItems={loadMoreItems}
>
{({ onItemsRendered, ref }) => (
<List
height={height}
width={width}
itemSize={110.95}
itemData={{ articles, keywords }}
itemCount={articles.length}
ref={ref}
onItemsRendered={onItemsRendered}
>
{ArticleItem}
</List>
)}
</InfiniteLoader>
)}
</AutoSizer>
</ArticleListWrapper>Autosizer는 부모의 너비와 높이를 전달해주는 라이브러리이다.react-window를 사용할 때는 List의 높이와 너비를 지정해줘야 하는데,FixedSizeList에서는width="100%"처럼 string으로 지정이 가능했지만FixedSizeGrid에서는 무조건 number로 지정해줘야 했다. (검색 결과에 두 종류가 있는데, 하나는 검색 결과를 Grid 형태로 표시하고 있다.) 따라서 편리하게 부모 컴포넌트의 너비와 높이를 얻기 위해Autosizer라이브러리를 사용했다.InfiniteLoader은 무한스크롤을 위한 라이브러리이다.FixedSizeList를InfiniteLoader안에 래핑해준다.-
itemCount: 아이템의 개수 -
loadMoreItems: 스크롤을 내렸을 시 실행하려는 함수(데이터를 더 받아오는 함수). Promise여야 함. -
isItemLoaded: 특정 항목이 로드되었는지 확인하는 메서드사용할 때
FixedSizeList에onItemsRendered와ref를 props로 전달해주어야 한다.
-
적용 결과
- 다음과 같이 보여지는 요소들만 렌더링되는 것을 확인할 수 있었다.

기존과의 성능 비교하기
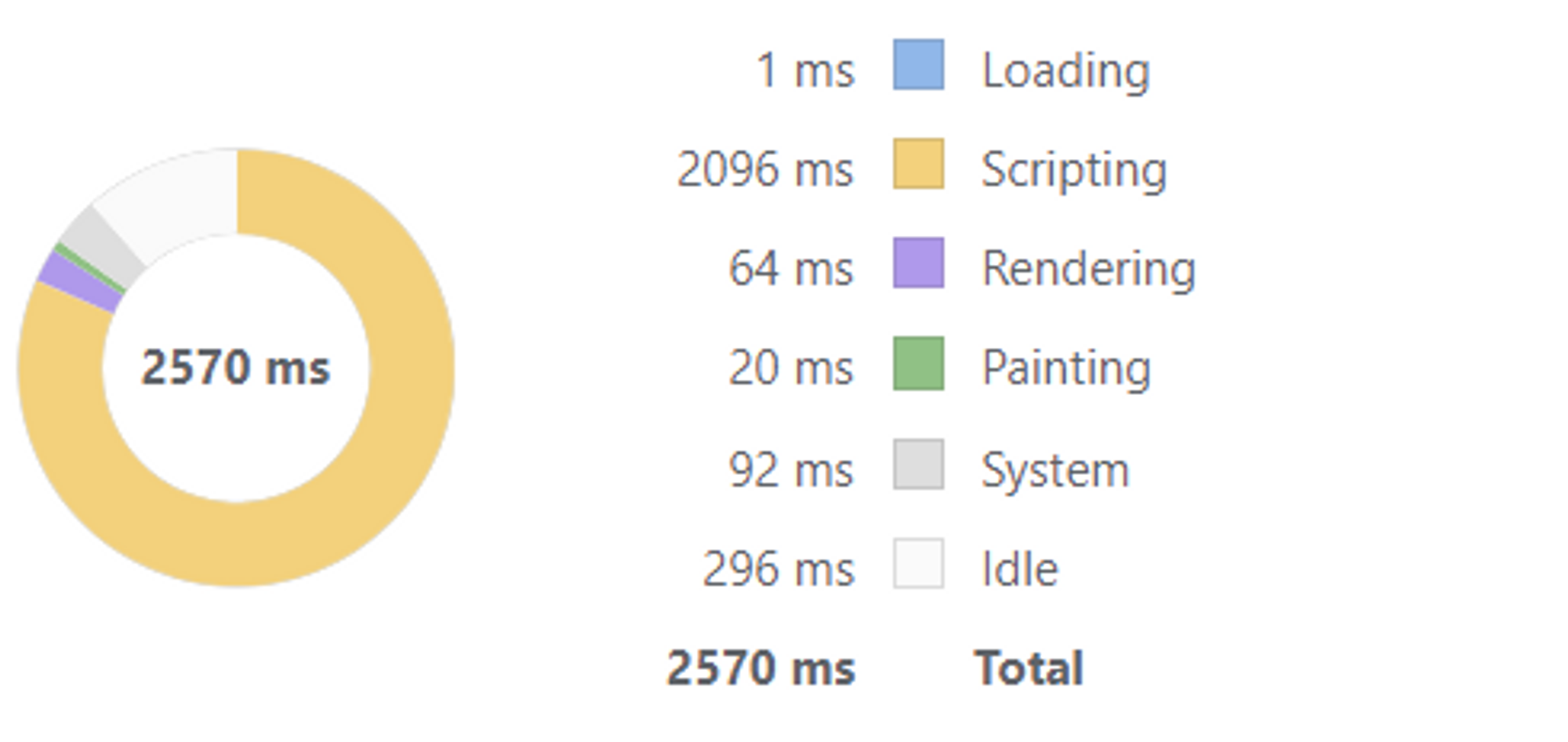
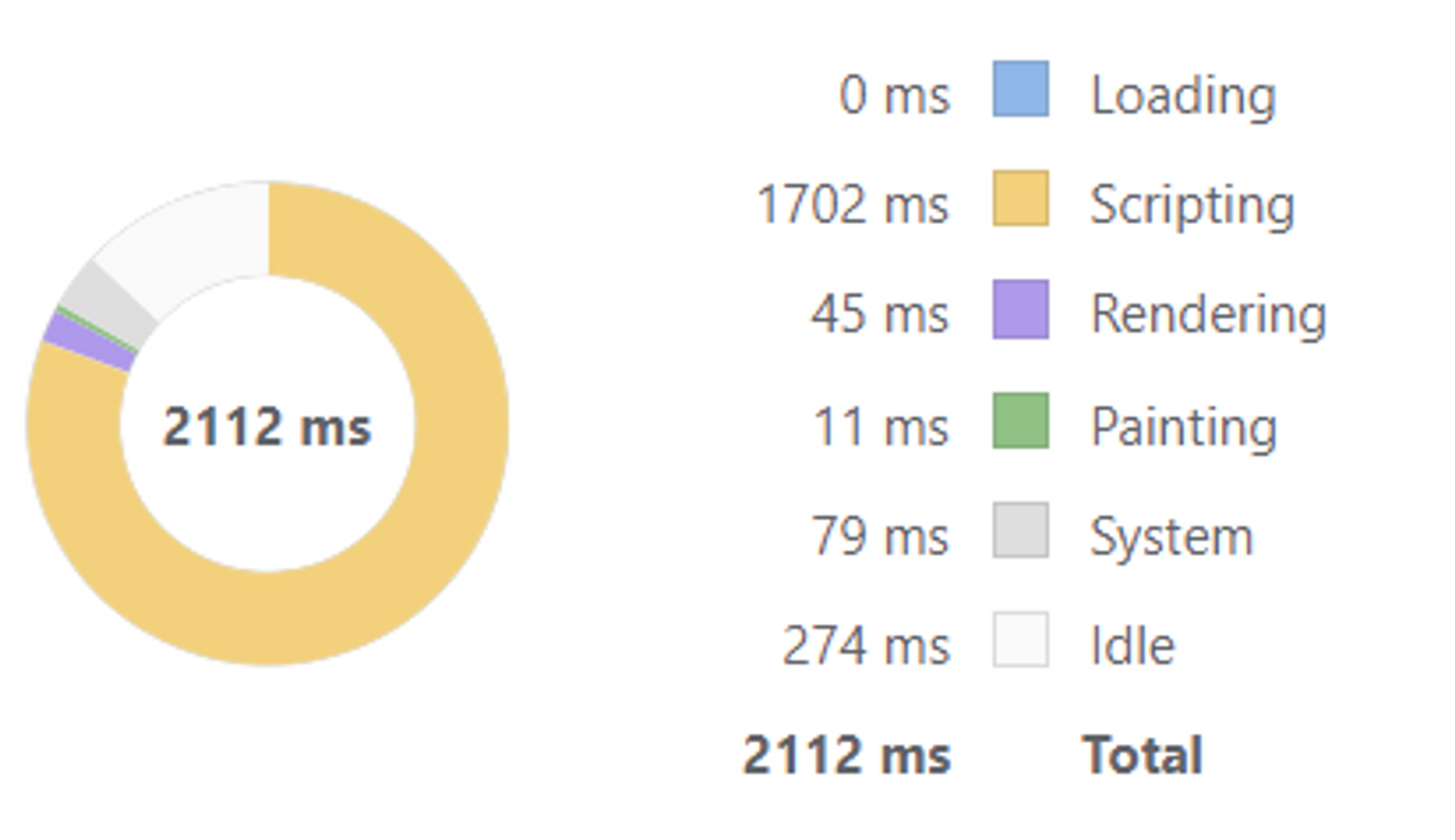
“knot” 키워드로 검색
- 11개가 저장되어 있을 때 화면에 7개만 렌더링되는 것을 확인했고, 렌더링하기까지 총 소요 시간이 2570ms → 2112ms로 감소하였다.
- 적용 전
- 적용 후
- 적용 전
-
끝까지 로딩한 후(35개 아이템), 가장 아래로 스크롤 한 후 새로 고침 했을 때 렌더링 시간이 3738ms -> 1622ms로 감소했다.
-
적용 전
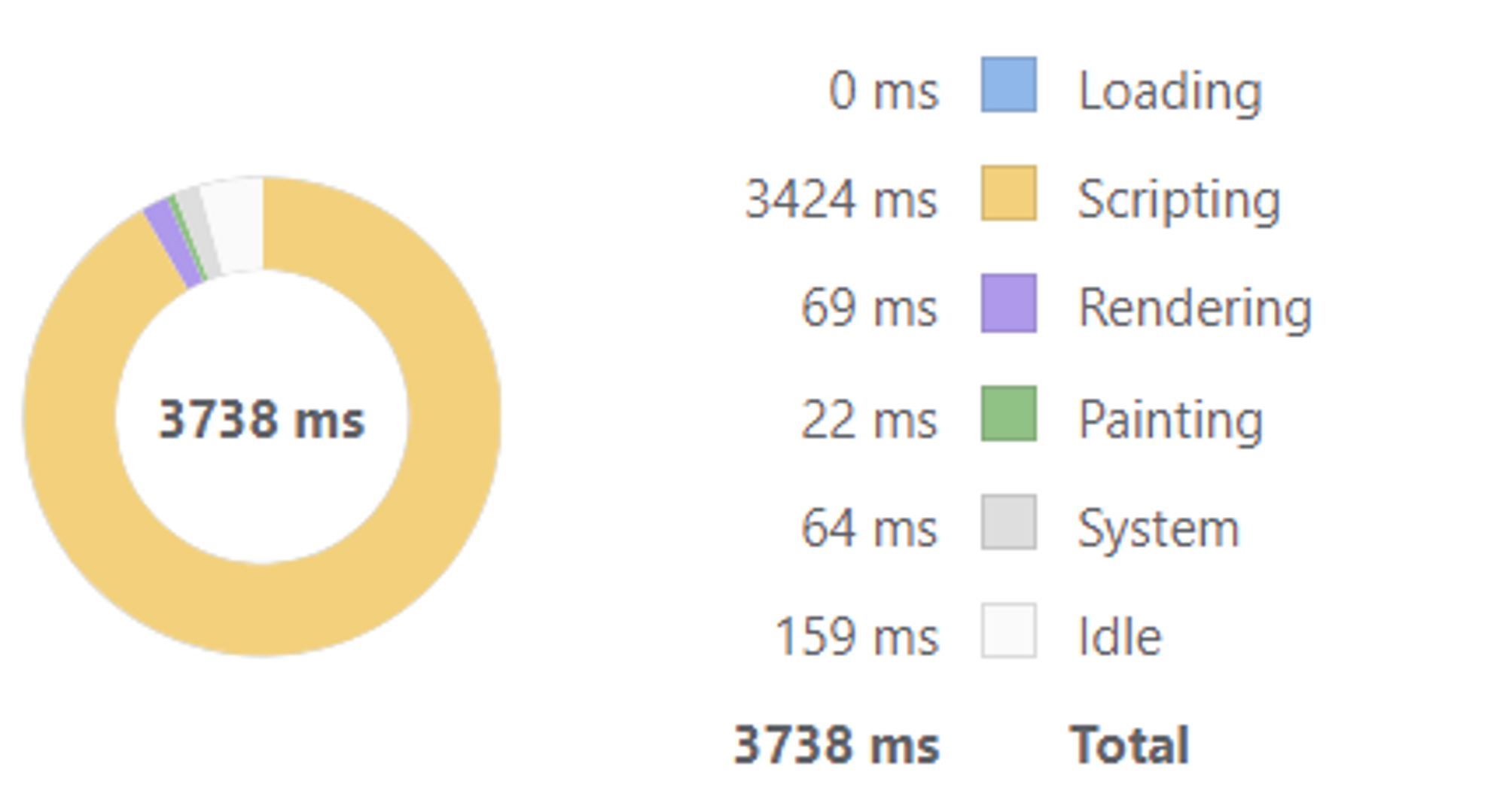
-
적용 후
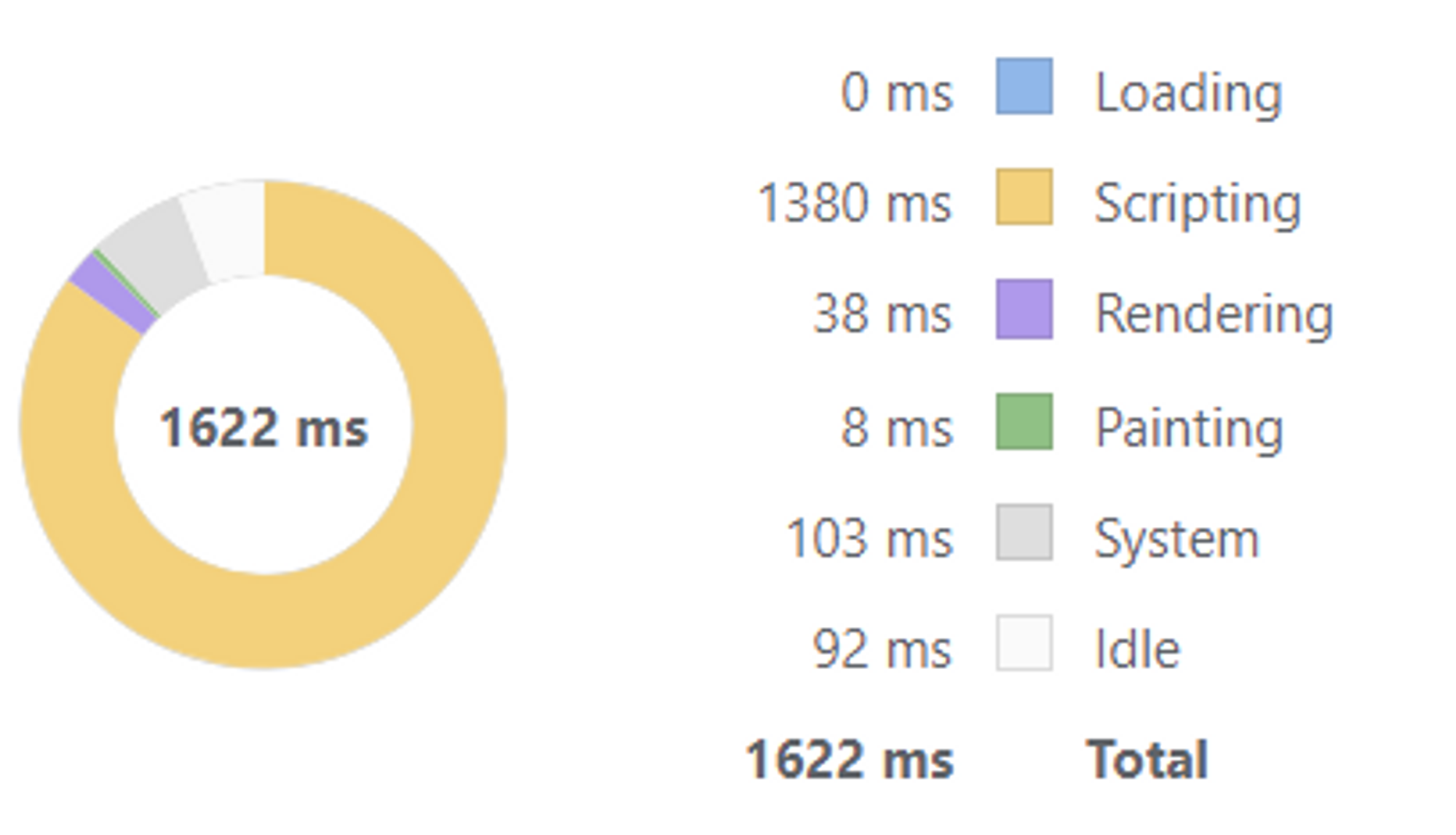
적용 전, 후 렌더링 속도 차이를 아래와 같이 체감할 수 있었다.


-
검색 결과 보존하기
기존에는 세션스토리지에 검색 페이지를 렌더링하는 데 필요한 데이터들(검색 결과, 검색어, 스크롤 위치 등)을 모두 저장해두고 있었다. Windowing을 적용하고 나서는 나머지는 그대로 보존되었지만 스크롤이 전체 스크롤이 아닌 내부 스크롤로 변경됨에 따라 스크롤 위치는 보존되지 않았다. 따라서 스크롤 위치를 저장하는 훅을 만들고, 이를 각각의 리스트 컴포넌트에서 사용하였다.
- useScrollSaver 타겟 요소와 세션스토리지의 key 이름을 인수로 받고, 스크롤 위치와 스크롤 위치를 변경하는 함수를 반환한다.
import { RefObject, useEffect } from 'react'; import useSessionStorage from '@hooks/useSessionStorage'; const useScrollSaver = (elementRef: RefObject<HTMLDivElement>, key: string) => { const { value: scroll, setValue: setScroll } = useSessionStorage(key, 0); useEffect(() => { if (!elementRef.current) return undefined; let ticking = false; const handleScroll = () => { if (!elementRef.current) return; if (!ticking) { window.requestAnimationFrame(() => { if (elementRef.current) setScroll(elementRef.current.scrollTop); ticking = false; }); ticking = true; } }; elementRef.current.addEventListener('scroll', handleScroll); return () => { if (!elementRef.current) return; elementRef.current.removeEventListener('scroll', handleScroll); }; }, [elementRef.current]); return { scroll, setScroll }; }; export default useScrollSaver; - List를
ref로 잡고 싶다면 아래와 같이outerRef속성을 사용해주면 된다.const target = useRef() as RefObject<HTMLDivElement>; ... <List height={height} width={width} itemSize={110.95} itemData={{ articles, keywords }} itemCount={articles.length} ref={ref} onItemsRendered={onItemsRendered} outerRef={target} initialScrollOffset={scroll} >
To Do
세션스토리지에 모든 데이터를 저장해서 검색페이지에 보존하는 방법은 개선이 필요하다고 생각한다. 스크롤 위치, 검색어까지는 데이터 크기가 작지만, 검색 결과는 스크롤을 많이 내릴수록 데이터 크기가 커지기 때문이다. 세션스토리지는 저장할 수 있는 데이터의 크기 제한(대략 5MB)이 있다.
그래서 처음에는 검색 결과를 아예 새 탭에서 여는 방법을 떠올렸다. 이는 brunch에서 사용하고 있는 방법이기도 하다. 하지만 모바일에선 새 탭이 열리는 게 굉장히 불편할거라 생각했고(brunch의 경우 모바일에선 새 탭이 열리지 않는다), next의 Link 컴포넌트로 작성하던 부분을 모두 a 태그로 바꿔줘야 했는데, 그 과정에서 다른 페이지에서도 사용 중인 공통 컴포넌트를 변경해야 했다.
따라서 이번 개선 작업에서는 우선 기존 로직을 사용하는 방법을 택했다. 추후에 스크롤 위치만 저장해서 렌더링할 수 있게끔 점진적으로 개선해볼 예정이다.
참고자료
