
서론
다양한 정렬 알고리즘에 대한 정리 글을 들어가기에 앞서 왜(WHY) 정렬 알고리즘에 대해 알아야 하는지 나의 생각을 정리해본다면 다음과 같다.
WHY? 정렬알고리즘에 대해 공부하는 이유
앞으로 다양한 종류, 크기, 형태의 데이터를 다루게 될 것 이고, 이러한 데이터 중 나에게 필요한, 필요에 맞는 데이터를 잘 추출하기 위해서는 데이터를 정렬하는 과정이 필수적이기 때문에 정렬 알고리즘에 대해 공부해야한다.
1. 버블 정렬
버블 정렬이란.
- 버블정렬이란 첫 번째 원소부터 인접한 원소끼리 그 크기에 따라 자리를 교환하는 과정을 거치며 리스트자료형 데이터를 정렬하는 방법이다.
- 한 단계가 끝나면 가장 큰 원소가 마지막 자리로 정렬된다.
- 자리를 이동하며 가장 큰 원소가 맨 위(리스트자료형의 마지막 자리) 까지 올라오는 모습이 마치 물 위로 떠오르는 거품모양과 같다고 하여 버블 정렬 이라고 한다.
- 버블 정렬의 과정은 아래 gif와 같다.(출처: https://visualgo.net/en)
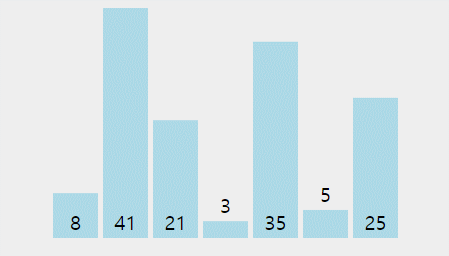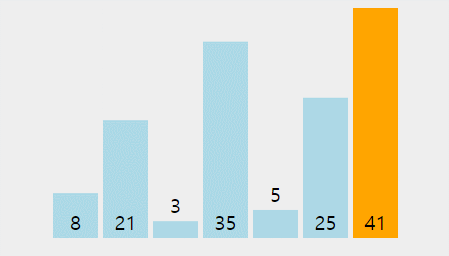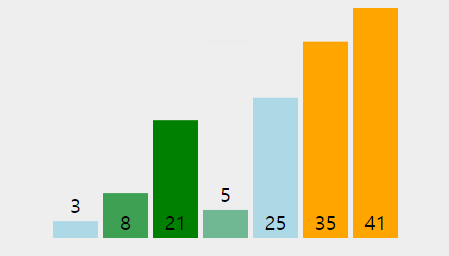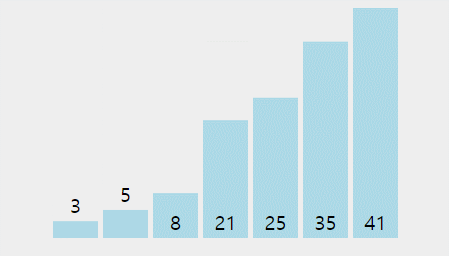
버블 정렬의 시간 복잡도: O(n^2)
- 버블정렬의 경우 for문이 중첩되어 실행되므로 n*n = n^2의 시간 복잡도를 갖는다.
버블 정렬 구현
a = [3,8,5,35,21,41,25]
def BubbleSort(a, N): # a는 정렬할 리스트, N은 원소의 수, 리스트만 입력받고 len(list)를 사용해도 무방함
for i in range(N-1, 0 , -1):
for j in range(i):
if a[j] > a[j+1]:
a[j], a[j+1] = a[j+1], a[j]버블정렬 장,단점
-
장점👍 : 인접한 값만 계속해서 비교하는 방식으로 구현이 쉬우며, 코드가 직관적이다. n개 원소에 대해 n개의 메모리를 사용하기에 데이터를 하나씩 정밀 비교가 가능하다.
-
단점👎 : 최선, 평균, 최악의 경우 모두 O(n^2)이라는 시간복잡도를 가진다. n개 원소에 대해 n개의 메모리를 사용하기에 원소의 개수가 많아지면 비교 횟수가 많아져 성능이 저하된다.
2. 카운팅 정렬
카운팅 정렬(계수 정렬)이란
-
항목들의 순서를 결정하기 위해 집합에 각 항목이 몇 개씩 있는지 세는 작업을 통해 선형 시간에 정렬하는 알고리즘
-
카운팅 정렬의 제한사항
- 정수나 정수로 표현할 수 있는 자료에 대해서만 적용 가능
- 카운트들을 위한 충분한 공간을 할당하려면 집합 내의 가장 큰 정수를 알아야 한다.
카운팅 정렬 시간 복잡도
- 카운팅 정렬은 O(n+k)의 시간 복잡도를 갖는다.
- n은 리스트의 길이, k는 정수 최대값을 뜻 한다.
카운팅 정렬 구현
def Counting_Sort(a):
m = max(a) # 주어진 리스트 a의 정수 최대값 찾기
Counting_list = [0]*(m+1) # 최대값 +1만큼 카운팅 리스트를 생성
for i in range(len(a)):
Counting_list[a[i]] += 1
print(Counting_list)
for x in range(1,m+1):
Counting_list[x] += Counting_list[x-1]
#카운팅 리스트 완성
print(Counting_list)
result = [0]*len(a)
for r in range(len(a)-1, -1, -1): # 리스트의 마지막 값부터 역순으로 순회
Counting_list[a[r]] -= 1
result[Counting_list[a[r]]] = a[r]
print(result)
li = [4,4,3,2,1,5,6,7]
Counting_Sort(li)애니매이션으로 보면 이해하기 쉽다.
링크로 접속해보는 것을 권장한다.
카운팅 정렬 장단점
-
장점👍 : 비교적 준수한 시간복잡도를 갖는다. k의 수가 작을경우 O(N)에 가까운 시간 복잡도를 갖는다. 또한 안정정렬을 구현할 수 있다. 위 코드 처럼 카운팅 정렬을 구현할 경우 리스트에서 중복되는 값들 끼리도 그 순서가 보장된다.(4가 두번 나오는데 4끼리의 순서가 변하지 않음)
-
단점👎 : 정수 최대값만큼 counting_list를 만들어야 하므로 메모리의 낭비가 발생 될 수 있다.
선택 정렬
선택 정렬이란
- 선택 정렬은 0번 인덱스 값과 1~len(list)번 인덱스값을 비교하여 최솟값을 찾은 후 그 둘의 위치를 바꾸는 과정을 0번 부터 len(list)-1번 까지 반복하며 정렬하는 방법이다.
- (출처: https://visualgo.net/en)
선택 정렬 시간 복잡도
- 비교하는 과정이 상수 시간에 이루어진다는 가정 하에, O(n^2)의 시간 복잡도를 갖는다.
선택 정렬 구현
def SelectionSort(li):
for i in range(len(li)-1):# -1번까지 하는 이유는 n-1번 정렬을 수행하면 최댓값이 마지막 인덱스 자리에 위치하게 되기 때문이다.
min_index = i
for z in range(i,len(li)):
if li[min_index] > li[z]:
min_index = z
li[i],li[min_index] = li[min_index],li[i]
return li선택 정렬 장,단점
- 장점👍
- 구현이 간단하다.
- 정렬이 진행됨에 따라 속도가 빨라진다.
- 단점👎
- 최선, 평균, 최악의 경우 모두 O(n^2)이라는 시간복잡도를 가진다.
삽입정렬, 퀵 정렬 등 다음시간에...

우공이산