이번 JPQL 중급 문법은 이전 JPQL 게시글의 테스트 데이터를 그대로 사용합니다 😉
1. 테이블 전체 모습
2. 현재 데이터 상태

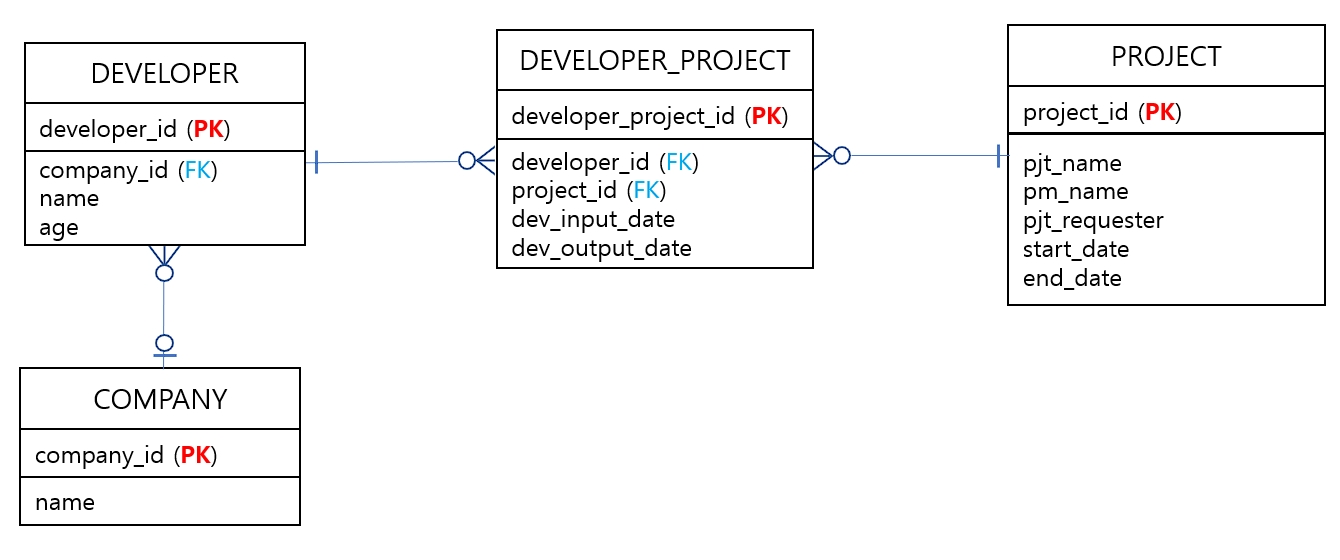
🍀 경로 표현식
👏 용어 정리
- 상태 필드(state field): 값을 담기 위한 필드
- 연관 필드(association field): 연관관계 참조를 위한 필드
- 단일 값 연관필드 (ex:
@ManyToOne) - 컬렉션 값 연관 필드 (ex:
@OneToMany)
- 단일 값 연관필드 (ex:
👏 특징
- 상태필드 : 경로탐색의 끝
- 단일 값 연관 : 묵시적 내부 조인 O, 추가 탐색 O
- 컬렉션 값 연관 : 묵시적 내부 조인 O, 추가 탐색 X
==>From 절에서 명시적 조인으로 별칭을 얻어서 해소 가능!
묵시적 조인은 정말로 사용하지 말자.
묵시적 조인이 발생하지 않도록 항상 명시적 조인을 사용하자.
👏 묵시적 조인?
위에 빨간 글씨로 써서 묵시적 조인을 쓰지 말라는데... 묵시적 조인이 대체 뭘까?
아래 예시 코드를 한번 테스트 해보자.
테스트 코드
Query query = em.createQuery("select d.company from Developer d");
List resultList = query.getResultList();콘솔 출력
Hibernate:
select
company1_.company_id as company_1_0_,
company1_.name as name2_0_
from
developer developer0_
inner join
company company1_
on developer0_.company_id=company1_.company_id테스트 코드를 보면 "join"이라는 키워드를 사용하지 않았다.
그런데 실제 나가는 쿼리에는 join 쿼리가 사용된다 😱
편해보이지만, 이걸 쓰면 쿼리 튜닝 시에 많은 어려움을 준다고 하니 쓰지 말자.
그리고 딱봐도 코드가 조금만 복잡해지면 디버깅하기에도 어려워 보인다.
무조건 명시적으로 join을 쓰자.
묵시적 조인 주의사항
- 항상 내부 조인
- 경로 탐색은 주로 SELECT, WHERE 절에서 사용
==>묵시적 조인으로 인해 SQL의 FROM(JOIN) 절에 영향을 준다 💀
👏 컬렉션 값 연관 필드의 탐색 제한
컬렉션 값 연관 필드를 통한 탐색은 제한이 있다.
이는 IDE의 자동완성 기능을 통해서 눈치 챌 수 있다.

이러는 이유는 우리는 JPQL, 즉 객체지향쿼리를 쓰고 있기 때문이다.
c.developers 는 실제로 Java에서는 Collection이다.
Collection으로 필드를 찍는다는 건 좀 이상하다.
(대신 제한적으로 size 정도는 가져올 수 있다)
물론 이를 해결할 방법은 있다.
컬렉션 연관 필드로 탐색이 가능하도록 하고 싶다면 아래처럼 명시적 조인을 사용하면 된다.
명시적 조인을 통해서 별칭을 얻고, 그 별칭으로 계속 탐색이 가능하다.

🍀 페치 조인
👏 개요
- SQL 조인 종류 X
- 성능 최적화 : 연관 엔티티나 컬렉션을 SQL 한번에 같이 조회
- JPQL에서는
join fetch명령어로 사용
👏 성능 최적화
fetch 조인에 의한 성능 최적화가 가능하다.
여기서 말하는 성능 최적화는 우리가 기존에 @ManyToOne(fetch = FetchType.LAZY) 를
하면 프록시를 이용해서 Lazy 하게 일어 온다.
그런데 종종 우리는 fetch = FetchType.LAZY 설정을 했어도 FetchType.EAGER처럼
쿼리 한방에 싹다 읽어 오고 싶다.
이때 쓰는게 fetch join이다.
fetch join은 비록 LAZY 설정이 되어 있는 연관필드여도 EAGER 처럼 한번의 쿼리로
다 읽어오게 된다.
이러면 LAZY 설정으로 인한 N+1 문제 같은 경우를 많이 해결할 수 있다.
이론은 어느정도 알겠으니, 이제 실습을 통해 이해해 보자.
👏 문제상황
잠시 fetch join을 안했을 때 코드와 콘솔 출력 결과를 보자.
- 코드
TypedQuery<Developer> query
= em.createQuery("select d from Developer d", Developer.class);
List<Developer> resultList = query.getResultList();
for (Developer developer : resultList) {
System.out.println(
"developer = " + developer
+ ", companyName : " + developer.getCompany().getName()
);
}- 콘솔 출력
Hibernate:
select
developer0_.developer_id as develope1_1_,
developer0_.age as age2_1_,
developer0_.company_id as company_4_1_,
developer0_.name as name3_1_
from
developer developer0_
Hibernate:
select
company0_.company_id as company_1_0_0_,
company0_.name as name2_0_0_
from
company company0_
where
company0_.company_id=?
developer = Developer(id=3, name=naverDev1, age=26), companyName : naver
developer = Developer(id=4, name=naverDev2, age=22), companyName : naver
Hibernate:
select
company0_.company_id as company_1_0_0_,
company0_.name as name2_0_0_
from
company company0_
where
company0_.company_id=?
developer = Developer(id=5, name=kakaoDev1, age=27), companyName : kakao
developer = Developer(id=6, name=kakaoDev2, age=30), companyName : kakao콘솔 출력을 하나하나 뜯어보면, developer.getCompany().getName() 코드에 의해서
프록시 초기화가 일어나면서 그 순간 쿼리가 날라간다.
그런데 지금이야 겨우 4명이지만, 우리가 100명의 Developer 정보를 조회하면서, 동시에
연관필드 Company의 companyName 필드를 조회하는 경우가 발생하면?
한명의 개발자당 하나의 쿼리가 더 나간다고 생각해보라.
==> 이것이 우리가 흔히 말하는 N+1 문제이다!!
참고1.
아마 이런 방법이 되지 않을까~? 하는 분들을 위한 테스트
TypedQuery<Developer> query = em.createQuery("select d from Developer d join d.company c", Developer.class);과연 이 문제가 해결될까? 어림없다.
물론 콘솔에 쿼리 상에서는 분명 join이 되는 것을 확인할 수 있다.
콘솔 출력(부분)
Hibernate: select developer0_.developer_id as develope1_1_, developer0_.age as age2_1_, developer0_.company_id as company_4_1_, developer0_.name as name3_1_ from developer developer0_ inner join company company1_ on developer0_.company_id=company1_.company_id하지만 바로 그 다음에 company를 조회하는 쿼리가 날라간다.
즉 이렇게 한다고 해결 되는게 아니다!왜 그럴까? 그 이유는 우리가
select내에서Company별칭을 안 쓰고,
오로지Developer별칭만 써서 그렇다. 실제 select Clause 를 보면 developer 정보만
읽어오는 것을 알 수 있다.그렇다면 select 에
Company별칭 도 같이 쓰면 되지 않을까 싶다.
하지만 그러면Object[]로 결과 값을 받고, 추가적인 작업들을 많이 하게 된다.지금이야 겨우 엔티티 2개지만, 4개,5개 늘어나면 그렇게 select에 모든 별칭을 작성하고,
Object[]로 다시 풀어내는 작업은 정말 고역일 것이다.이런 전체적인 상황들을 모두 타파하는게
fetch join이다.
참고2
그런데 JPQL을 사용할 때, fetch 전략을 EAGER 로 한다고 이게 해결될까? 아니다!
EAGER를 해도JPQL을 쓰면 비슷한 현상이 발생한다.
JPQL은 EAGER 가 있어도 일단 select로 엔티티를 읽고나서,
연관관계 필드 위에 EAGER가 있는 걸 인식하고, 바로 이어서 쿼리를 다시 날린다.즉 JPQL을 사용할 때 EAGER를 사용해서 N+1 문제는 해결할 수 없는 것이다!
👏 fetch join을 통한 문제해결
이제 fetch join을 사용해서 이를 해결해보자.
코드
TypedQuery<Developer> query
= em.createQuery("select d from Developer d join fetch d.company c", Developer.class);
List<Developer> resultList = query.getResultList();
for (Developer developer : resultList) {
System.out.println(
"developer = " + developer
+ ", companyName : " + developer.getCompany().getName()
);
}콘솔 출력
Hibernate:
select
developer0_.developer_id as develope1_1_0_,
company1_.company_id as company_1_0_1_,
developer0_.age as age2_1_0_,
developer0_.company_id as company_4_1_0_,
developer0_.name as name3_1_0_,
company1_.name as name2_0_1_
from
developer developer0_
inner join
company company1_
on developer0_.company_id=company1_.company_id
developer = Developer(id=3, name=naverDev1, age=26), companyName : naver
developer = Developer(id=4, name=naverDev2, age=22), companyName : naver
developer = Developer(id=5, name=kakaoDev1, age=27), companyName : kakao
developer = Developer(id=6, name=kakaoDev2, age=30), companyName : kakao일단 join이 나가는 건 딱봐도 알겠다.
select clause 를 자세히 보면 developer, company의 데이터를 모두 읽어온다.
그래서 developer 엔티티 하나를 읽어왔지만, company 도 프록시가 아닌 진짜가 들어와 있다.
fetch join을 쓰면 우리가 JPQL에 비록 하나의 엔티티 별칭만 써도,
해당 엔티티의 연관관계 정보까지 같이 읽어오는게 가능한 것이다.
👏 collection fetch join
코드
TypedQuery<Company> query
= em.createQuery("select c from Company c join fetch c.developers d", Company.class);
List<Company> resultList = query.getResultList();
for (Company company : resultList) {
System.out.println(
"company = " + company
+ ", how Many developers : " + company.getDevelopers().size()
);
}콘솔 출력
Hibernate:
select
company0_.company_id as company_1_0_0_,
developers1_.developer_id as develope1_1_1_,
company0_.name as name2_0_0_,
developers1_.age as age2_1_1_,
developers1_.company_id as company_4_1_1_,
developers1_.name as name3_1_1_,
developers1_.company_id as company_4_1_0__,
developers1_.developer_id as develope1_1_0__
from
company company0_
inner join
developer developers1_
on company0_.company_id=developers1_.company_id
company = Company(id=1, name=naver), how Many developers : 2
company = Company(id=1, name=naver), how Many developers : 2
company = Company(id=2, name=kakao), how Many developers : 2
company = Company(id=2, name=kakao), how Many developers : 2음? 뭔가 이상하다. Company는 사실 DB Table 에 2개밖에 없는데,
조회된 결과는 Developer의 개수만큼 뻥튀기(?)가 되어서 조회된다.
이러는 이유는 1:N 관계에서 1쪽을 기준으로 N을 join 하면
조회 결과의 row 수를 정하는 기준이 항상 N이기 때문이다.
이해가 안된다면 아래 그림을 가볍게 보자.
- 조인 과정

- 조인 결과

이해가 되었길 바란다.
아무튼 컬렉션 연관필드로 fetch join을 하면 예상한 것보다 많은 데이터가 조회된다.
하지만 1:N 이라도 최종 결과의 주도권을 1 쪽에 주고 싶다면 어떡할까?
그때 필요한 게 JPQL 에서는 DISTINCT 기능을 제공한다.
JPQL의 DISTINCT 는 쿼리 자체에도 distinct를 써주고,
그리고 얻어온 결과인 엔티티의 중복도 애플리케이션에서 제거해준다.
아래 코드를 보자.
테스트 코드
// distinct 추가!
TypedQuery<Company> query
= em.createQuery("select distinct c from Company c join fetch c.developers d", Company.class);
List<Company> resultList = query.getResultList();
for (Company company : resultList) {
System.out.println(
"company = " + company
+ ", how Many developers : " + company.getDevelopers().size()
);
}콘솔 출력
Hibernate:
select
distinct company0_.company_id as company_1_0_0_,
developers1_.developer_id as develope1_1_1_,
company0_.name as name2_0_0_,
developers1_.age as age2_1_1_,
developers1_.company_id as company_4_1_1_,
developers1_.name as name3_1_1_,
developers1_.company_id as company_4_1_0__,
developers1_.developer_id as develope1_1_0__
from
company company0_
inner join
developer developers1_
on company0_.company_id=developers1_.company_id
company = Company(id=1, name=naver), how Many developers : 2
company = Company(id=2, name=kakao), how Many developers : 2😎
👏 fetch join 의 한계
- 페치 조인 대상에는 별칭 ❌
fetch join을 통한 별칭을 주고, 그 별칭으로 "필터링"을 하는 것을 막기 위함이다.
여기서 말하는 필터링은 on, where 등의 필터링 조건 모두를 말한다.
fetch join을 쓰면 연관된 모든 엔티티 정보를 읽어오는 게 원칙이다.
OneToMany 관계에서 Collection 형태로 조회되는 연관 필드가 바로 이 원칙의 주요 대상이다.
이렇게 모두 읽어옴으로써 DB와 애플리케이션에서 모두 같은 개수의 연관 데이터가
존재하도록 하기 위함이다. 즉 객체와 DB의 일관성이 유지시키기 위해서다.
필터링이 필요한 Collection 이 있다면, fetch join과 별개로 jpql을 하나 더 만들고
필터링을 해주자.
이것과 관련된 심도 깊은 QnA가 있다.
참고: https://www.inflearn.com/questions/15876
- 페치 조인 별칭 예외사항
그런데 하이버네이트에서는 fetch join 이더라도 별칭을 쓸 수 있다.
하지만 그렇다고 해서 위의 원칙을 어기는 건 아니다. 일관성은 유지가 된다는 전제하에서
사용이 가능하다는 것이다.
참고: https://www.inflearn.com/questions/15876 답변 중 일부...
먼저 일관성이 문제가 없으면 사용해도 됩니다!
예를 들어서 문의주신 내용중에 다음 쿼리는 가능합니다.
Select m from Member m join fetch m.team t where t.name=:teamName
이 쿼리는 회원과 팀의 일관성을 해치지 않습니다. 그러니까 조회된 회원은 db와 동일한 일관성을 유지한 팀의 결과를 가지고 있습니다.
하지만 이 쿼리를 left join fetch로 변경하면 일관성이 깨질 수 있습니다.
- 둘 이상의 컬렉션은 페치 조인 ❌
기능이 될 때도 있고, 안될 때도 있다.
그리고 설사 되더라도 결과 데이터가 이상하게 꼬이는 경우가 많다고 한다.
아직 이런 경험이 없어서 와닿지 않는다.
- 컬렉션을 페치 조인하면 페이징 API 사용 ❌
- 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인 + 페이징 API 사용 가능!
- 하이버네이트는 경고 로그를 남기고 메모리에서 페이징! 매우 위험!
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
테스트 코드
TypedQuery<Company> query
= em.createQuery("select c from Company c join fetch c.developers d", Company.class);
List<Company> resultList = query.setFirstResult(0).setMaxResults(1).getResultList();
for (Company company : resultList) {
System.out.println(
"company = " + company
+ ", how Many developers : " + company.getDevelopers().size()
);
}콘솔 출력
// 경고 문구!
HH000104: firstResult/maxResults specified with collection fetch; applying in memory!
Hibernate:
select
company0_.company_id as company_1_0_0_,
developers1_.developer_id as develope1_1_1_,
company0_.name as name2_0_0_,
developers1_.age as age2_1_1_,
developers1_.company_id as company_4_1_1_,
developers1_.name as name3_1_1_,
developers1_.company_id as company_4_1_0__,
developers1_.developer_id as develope1_1_0__
from
company company0_
inner join
developer developers1_
on company0_.company_id=developers1_.company_id
company = Company(id=1, name=naver), how Many developers : 2이에 대한 해결법은 뭐가 있을까?
1:N가 아니라N:1방향으로fetch join을 뒤집는다.fetch join을 제거하고 컬렉션 연관관계 필드 위에
@BatchSize(size=100)를 사용하여 연관관계 데이터를 한번에 조회한다.- 아예 새로운 DTO를 생성하여 jpql new 문법을 사용한다.
여기서는 Batch Size 정도만 테스트 해보자.
- 엔티티 코드 수정
@Entity
@Getter
@Setter
@ToString
public class Company {
@Id
@GeneratedValue
@Column(name = "company_id")
private Long id;
private String name;
@ToString.Exclude
@OneToMany(mappedBy = "company")
@BatchSize(size = 10) // ===> 추가!
private List<Developer> developers = new ArrayList<>();
}- 테스트 코드
TypedQuery<Company> query
= em.createQuery("select c from Company c", Company.class);
List<Company> resultList = query.setFirstResult(0).setMaxResults(2).getResultList();
for (Company company : resultList) {
System.out.println("company = " + company);
company.getDevelopers().forEach(System.out::println);
}- 콘솔 출력
// 경고문이 없어졌다!
Hibernate:
select
company0_.company_id as company_1_0_,
company0_.name as name2_0_
from
company company0_ limit ?
company = Company(id=1, name=naver)
Hibernate:
select
developers0_.company_id as company_4_1_1_,
developers0_.developer_id as develope1_1_1_,
developers0_.developer_id as develope1_1_0_,
developers0_.age as age2_1_0_,
developers0_.company_id as company_4_1_0_,
developers0_.name as name3_1_0_
from
developer developers0_
where
developers0_.company_id in ( // 요게 핵심이다!
?, ?
)
Developer(id=3, name=naverDev1, age=26)
Developer(id=4, name=naverDev2, age=22)
company = Company(id=2, name=kakao)
Developer(id=5, name=kakaoDev1, age=27)
Developer(id=6, name=kakaoDev2, age=30)developers0_.company_id in ( ?, ? ) 가 바로 @BatchSize가 적용된 것이다.
@BatchSize 의 size 속성값을 10을 줬는데, 이건 in ( ? , ? ) 에서의 물음표 개수가
최대로 몇개까지 쓸 수 있는지를 의미한다.
만약에 Company 엔티티가 11개 였다면
일단 10개를 in (? , ? , ? , ? , ? , ? , ? , ? , ? , ?) 통해서 메모리에 한번 올리고, 마지막 11번째를 위해서 in (?) 를 사용해서 메모리에 올린다.
참고. 배치 사이즈를 주는 방법 2가지
- Collection 연관관계 필드 위에
@BatchSize표기persistence.xml에서hibernate.default_batch_fetch_size를 설정한다.만약 둘 다 있으면
@BatchSize가 우선순위가 더 높다.
🍀 참고
