
참고1:
postgresql 11.12,POSTGIS=3.0.3버전 사용
참고2:LSMD_CONT_MV테이블은 오픈마켓에서 제공하는 연속지적도 SHP 을 테이블로 생성한 것입니다. 참고: http://data.nsdi.go.kr/dataset/12771
1. 느린 쿼리
평균적으로 4~5초 걸림
- 작성 SQL
select *
from undgrnd_all a
where
ST_INTERSECTS(
a.GEOM,
(SELECT GEOM FROM LSMD_CONT_MV WHERE PNU = '4812112500100010000')
) -- and A.detail_code in ('01')
order by detail_code, ftr_cde, ftr_idn -- undgrnd_all 테이블에 존재하는 컬럼들입니다. 중요 X
-- offset 0 limit 100- explain analyse 결과
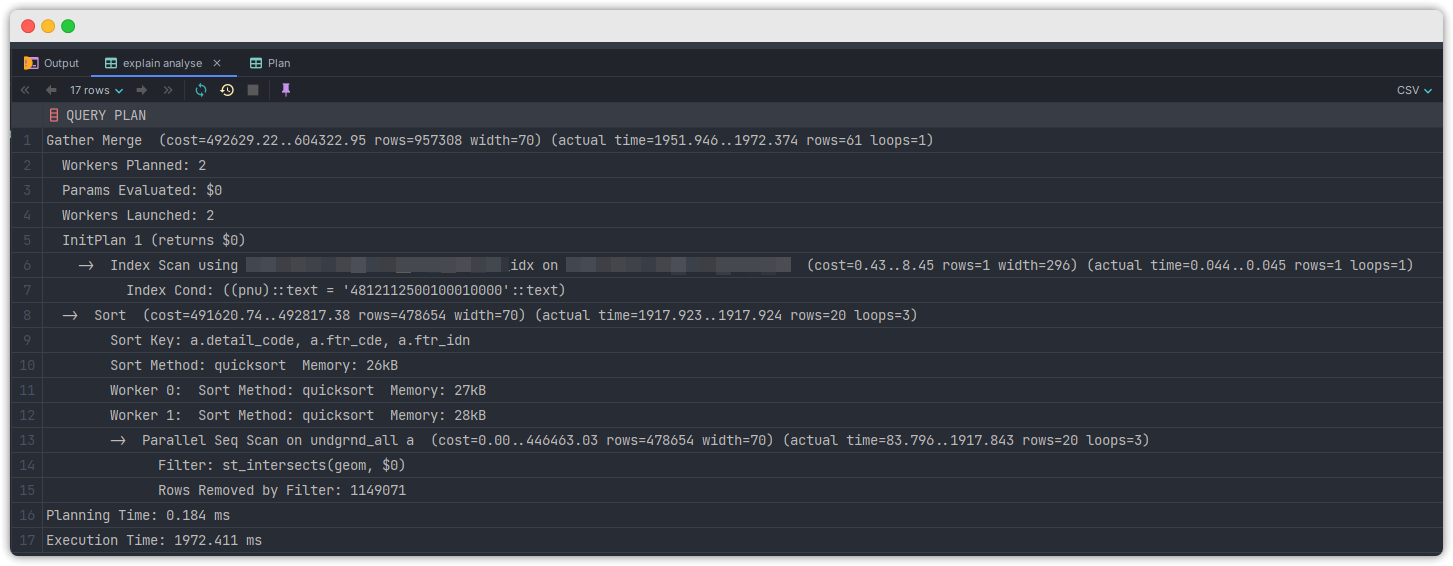

- 자세히 보면
Gather Merge라는 표현이 보이는데, 이건 병렬실행을 의미합니다.
참고how-parallel-query-works - 병렬적으로
sorting과indexing을 하는 작업이 나뉘어서 실행됩니다. index스캔은 cost 가 굉장히 낮습니다. 이건 순식간에 진행되었음을 알 수가 있죠.- 하지만 동시에 진행된
sorting은Full Scan이 발생합니다. 이게 문제입니다. - 아무래도 order by 에 있는 모든 컬럼들이 from 절에 있는 테이블과 관련있고, where 절에 쓰인 서브쿼리 결과물들은 order by 와 아무 연관이 없다보니 이렇게 "병렬적으로 실행되는 것이 효율적이다"라고 query planner 가 생각한 모양입니다.
- 하지만 제가 원하는 건 where 절까지 진행되어서 나온 적은 수의 DataSet 에 대한 Sorting 입니다.
ps: 그런데 잘 생각해보면
상관성 서브 쿼리에 의하여 from 절에 있는 테이블의 Row 하나하나를 순차적으로 sub-query 에 던지는 형태다 보니 느릴 수 밖에 없다는 생각도 문득 드네요.
2. 빠른 쿼리
평균적으로 1초 이내
- 작성 SQL
select *
from undgrnd_all A
INNER JOIN LSMD_CONT_MV B
ON ST_INTERSECTS(B.GEOM, A.GEOM)
WHERE B.PNU = '4812112500100010000' -- and A.detail_code in ('01')
ORDER BY DETAIL_CODE, FTR_CDE, FTR_IDN
-- offset 0 limit 100- join 으로 바꿨습니다.
- explain analyse 결과
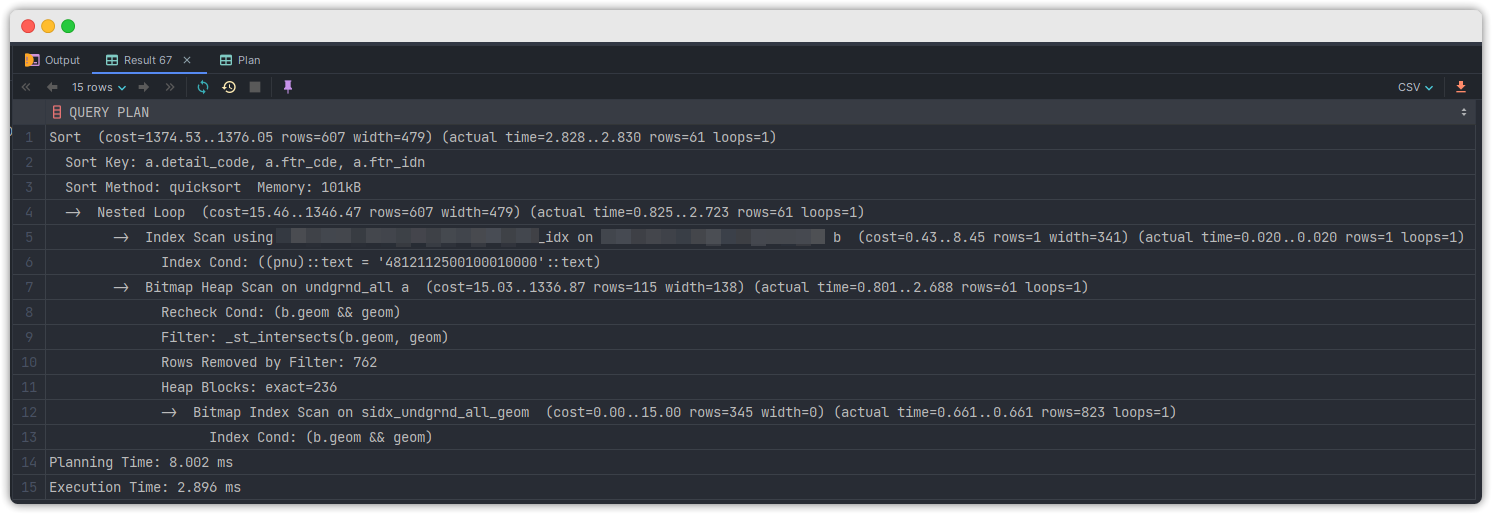

참고
-
Join vs. sub-query : 비록 10년도 넘은 오래된 글이지만, 옛날부터 sub-query 의 유용함은 다들 알지만, performance 를 위해서 어쩔 수 없이 join 을 사용하는 경우가 많았다고 하네요. 다만 요즘은
query planner가 똑똑해져서 sub-query 를 사용해도 어느정도 join 의 성능을 따라잡았다고 하네요. -
아마 지금 최신 postgresql 은 15 버전이니, 분명 개선되지 않았을까 싶습니다.(추측)

백엔드 개발자로 일하고 있는 식빵(🍞)입니다.