🍞 서론
무거운 엑셀 데이터는 웬만하면 SAX 기반으로 조회하는 게 좋습니다.
그래야 메모리가 터지지 않겠죠?
문제는 apache-poi 기반의 SAX 코드를 작성하는 게 생각보다 많이 복잡합니다.
이를 추상화한 라이브러리가 없나 둘러보다가 HUTOOL-POI 를 알게 되었습니다!
이 라이브러리에 대한 기본 사용법과
이를 응용해서 Excel 데이터를 Database Table 로 옮기는 것까지 한번 해봅시다!
🍞 기본 사용법
1. dependency 추가
저는 maven 을 사용하므로 pom.xml 에 아래와 같이 의존성을 추가해줬습니다.
<!-- pom.xml 에 아래처럼 dependency 추가 -->
<dependencies>
<!-- ...생략... -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>xerces</groupId>
<artifactId>xercesImpl</artifactId>
<version>2.12.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-poi</artifactId>
<version>5.8.32</version>
</dependency>
</dependencies>2. Java 코드 예시
package coding.toast.bread.excel_upload;
import cn.hutool.poi.excel.ExcelUtil;
import cn.hutool.poi.excel.sax.Excel03SaxReader;
import cn.hutool.poi.excel.sax.Excel07SaxReader;
import cn.hutool.poi.excel.sax.handler.RowHandler;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.util.List;
@Slf4j
public class HutoolExcelReaderWithSaxTest {
String xlsFilePath = "C:\\test\\file_50_row.xls"
String xlsxFilePath = "C:\\test\\file_50_row.xlsx"
@Test
@DisplayName("xls 읽기")
public void readXlsTest() {
Excel03SaxReader reader = new Excel03SaxReader(createRowHandler());
reader.read(xlsFilePath, 0); // 첫번째 시트(=0) 조회,
// 모든 시트 조회는 -1 설정.
// 위 2줄을 아래처럼 한줄로 바꿀 수 있습니다.
ExcelUtil.readBySax(xlsFilePath, 0, createRowHandler());
}
@Test
@DisplayName("xlsx 읽기")
public void readXlsxTest() {
Excel07SaxReader reader = new Excel07SaxReader(createRowHandler());
reader.read(xlsxFilePath, 0);
// 위 2줄을 아래처럼 한줄로 바꿀 수 있습니다.
ExcelUtil.readBySax(xlsxFilePath, 0, createRowHandler());
}
private static RowHandler createRowHandler() {
return new RowHandler() {
@Override
public void handle(int sheetIndex, long rowIndex, List<Object> rowlist) {
log.info("[{}] [{}] {}", sheetIndex, rowIndex, rowlist);
}
};
}
}더 궁금하신 분들은 HuTool poi document (영문) 를 참조해주세요!
🍞 응용 - Excel To Db Table
기본 사용법만 보자니 너무 썰렁해서
엑셀의 데이터를 Database Table 로 옮기는 코드를 작성해봤습니다.
1. 사전 준비
참고(1) : maven dependency 에
spring-jdbc관련 라이브러리를 추가하고 진행하세요.
저는 spring boot 환경에서 개발을 하다보니 아래와 같이 추가했습니다.<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jdbc</artifactId> </dependency>
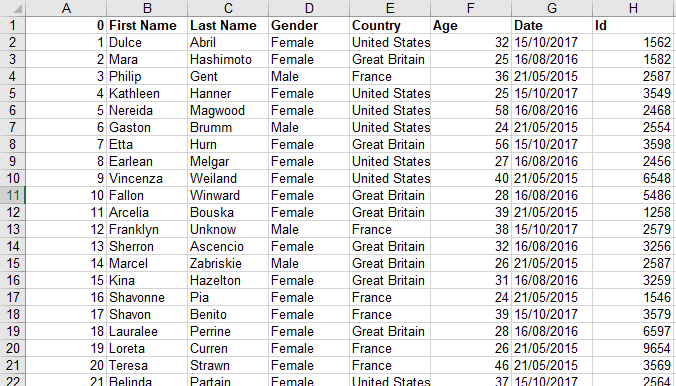
참고(2) : 사용 중인 예시 데이터 (
file_example_XLS_50.xls) 는 아래와 같습니다.
필요하신 분들은 이 링크에서 다운로드 가능합니다.
2. Java 코드
Custom RowMapper 생성
저는 커스텀한 RowMapper 를 만들어 봤습니다.
조금 복잡합니다. 읽기 귀찮으신 분들은 그냥 코드 가져다가 쓰고,
좀 더 아래로 내려가서 "사용법"만 참고하시기 바랍니다.
package coding.toast.bread.excel_upload;
import cn.hutool.poi.excel.sax.handler.RowHandler;
import lombok.extern.slf4j.Slf4j;
import org.springframework.dao.DataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.util.CollectionUtils;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
@Slf4j
public class DatabaseUploadRowHandler implements RowHandler {
private final JdbcTemplate jdbcTemplate;
private String insertSql;
private final int batchSize;
private final String schema;
private final String tableName;
private int skipRowCount = 0;
private final List<String> headerNames = new ArrayList<>();
private final List<List<Object>> insertRows = new ArrayList<>();
/**
* (flag) skipRowCount 를 모두 넘기고 나서 맨 처음 만난 row 에 대한 사용이 끝났는지를 알려준다.
*/
private boolean firstRowUsed = false;
/**
* (flag) 사용자가 커스텀한 header 명칭 지정 여부
*/
private boolean customHeaderConfigured = false;
/**
* 첫번째 row header 라고 가정하게 된다.<br>
* 만약에 직접적으로 헤더명을 지정하고 싶다면 setHeaderNames 를 호출해서 header 를 지정해주세요.<br>
* setHeaderNames 를 통해서 헤더명이 지정되면, 첫번째 row 도 다른 row 와 마찬가지로 data 로 인식합니다.<br>
*/
public DatabaseUploadRowHandler(JdbcTemplate jdbcTemplate, String schema, String tableName, int batchSize) {
this.jdbcTemplate = jdbcTemplate;
this.batchSize = batchSize;
this.schema = schema;
this.tableName = tableName;
}
@Override
public void handle(int sheetIndex, long rowIndex, List<Object> rowCells) {
// 일단 skip 하고자하는 row 는 모두 pass
if (rowIndex < skipRowCount) {
return;
}
// header 세팅을 위한 if 분기문이다.
// 위의 skip 문을 모두 통과한 후 만나는 가장 첫번째 row 는 header 가 될 수도, 아닐 수도 있다.
// header 가 아닌 경우는 사용자가 setHeaderNames 메소드를 통해서 custom 하게 header 명을 지정하지 않았을 때이다.
// 이때는 가장 처음 만난 row 도 하나의 data row 로 생각하고 처리한다.
// 반대로 setHeaderNames 를 호출하지 않았다면 여기서 만난 첫번째 row 가 header 가 된다.
if (!firstRowUsed) {
// 만약 user setting header 가 아니면 첫번째 row 를 header 로 따진다.
if (!customHeaderConfigured) {
List<String> headerList = rowCells.stream().map(String::valueOf).toList();
log.info("header : {}", rowCells);
headerNames.addAll(headerList);
}
dropAndCreateTable();
createInsertSql();
// 사용자가 header 를 지정한 거라면 첫번째 row 도 data 이므로 insert 해줘야 한다.
if (customHeaderConfigured) {
insertRows.add(rowCells);
}
firstRowUsed = true;
return;
}
log.info("read : [{}] [{}] {}", sheetIndex, rowIndex, rowCells);
insertRows.add(rowCells);
if (insertRows.size() % batchSize == 0) {
log.info("BATCH INSERT!");
insertBatch();
insertRows.clear();
}
}
private void createInsertSql() {
insertSql =
"insert into " + schema + "." + tableName + " values (" +
String.join(",", Collections.nCopies(headerNames.size(), "?"))
+ ")";
}
/**
* 모든 row 를 다 순회하고 마지막으로 호출되는 훅(Hook) 메소드이다.
*/
@Override
public void doAfterAllAnalysed() {
log.info("excel read complete!");
if (!insertRows.isEmpty()) {
log.info("insert remaining rows after read finished.\n==> {}", insertRows);
insertBatch();
}
}
@SuppressWarnings("SqlSourceToSinkFlow") // IntelliJ IDE SQL Injection warning suppress!
private void dropAndCreateTable() {
log.info("creating Table! (drop if already exists) => {}.{}", schema, tableName);
String ddlFragment = headerNames.stream()
.map(columnNm -> "\"" + columnNm + "\" VARCHAR ")
.collect(Collectors.joining(","));
try {
try {
jdbcTemplate.execute("""
drop table %s.%s""".formatted(schema, tableName));
} catch (DataAccessException e) {
System.out.println("ignore!");
}
jdbcTemplate.execute("""
create table %s.%s (%s)""".formatted(schema, tableName, ddlFragment));
} catch (DataAccessException e) {
throw new IllegalStateException("엑셀 업로드 - 테이블 생성 기능에서 예외가 발생했습니다.", e);
}
}
private void insertBatch() {
jdbcTemplate.batchUpdate(insertSql, insertRows, batchSize, (ps, rowCells) -> {
for (int i = 0; i < rowCells.size(); i++) {
Object value = rowCells.get(i);
ps.setObject(i + 1, value);
}
});
}
public void setHeaderNames(List<String> headerNames) {
if (CollectionUtils.isEmpty(headerNames)) {
throw new IllegalArgumentException("headerNames is null or empty");
}
this.headerNames.addAll(new ArrayList<>(headerNames));
this.customHeaderConfigured = true;
}
public void setHeaderNames(String... headerNames) {
if (headerNames == null || headerNames.length == 0) {
throw new IllegalArgumentException("headerNames is null or empty");
}
this.headerNames.addAll(Arrays.asList(headerNames));
this.customHeaderConfigured = true;
}
public boolean isHeaderNameEmpty() {
return CollectionUtils.isEmpty(this.headerNames);
}
public void setSkipRowCount(int skipRowCount) {
this.skipRowCount = skipRowCount;
}
}사용법
사용 방법은 아래와 같이 여러가지 경우를 생각해서 테스트 코드로 작성해봤습니다.
package coding.toast.bread.excel_upload;
import cn.hutool.poi.excel.ExcelUtil;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.DriverManagerDataSource;
@Slf4j
class HutoolExcelReaderWithSaxTest {
private final int BATCH_SIZE = 10;
private JdbcTemplate jdbcTemplate;
private final String TEST_FILE
= "C:\\test\\file_example_XLS_50.xls";
@BeforeEach
void beforeEachTest() {
// db upload 를 위한 jdbcTemplate 생성
DriverManagerDataSource dataSource
= new DriverManagerDataSource(
"jdbc:postgresql://localhost:5432/postgres",
"postgres",
"postgres");
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Test
@DisplayName("첫번째이 행이 header 라고 간주하고 업로드 (default 동작)")
void firstRowAsHeaderTest() {
// HUTOOL POI 가 사용할 Row Handler 생성
DatabaseUploadRowHandler rowHandler
= new DatabaseUploadRowHandler(
jdbcTemplate,
"public", // 데이터 업로드 테이블이 위치한 스키마 명
"somesome", // 데이터 업로드 테이블 명
BATCH_SIZE);// insert 쿼리를 날릴 때 사용할 jdbc batch size
// read 수행
ExcelUtil.readBySax(TEST_FILE, 0, rowHandler);
}
@Test
@DisplayName("모든 Row 가 데이터라고 간주하고 업로드 (header custom 세팅은 필수)")
void allRowIsDataTest() {
DatabaseUploadRowHandler rowHandler
= new DatabaseUploadRowHandler(
jdbcTemplate,
"public", "somesome", BATCH_SIZE);
// 커스텀한 헤더명 지정
rowHandler.setHeaderNames("id",
"first_name",
"last_name",
"gender",
"country",
"age",
"date",
"purchase_count");
// read 수행
ExcelUtil.readBySax(TEST_FILE, 0, rowHandler);
}
@Test
@DisplayName("기존 첫번째 header row 를 스킵하고 custom header 적용하기")
void test() {
DatabaseUploadRowHandler rowHandler
= new DatabaseUploadRowHandler(
jdbcTemplate,
"public", // 엑셀 데이터를 업로드할 테이블이 위치한 스키마 명
"somesome", // 엑셀 데이터를 업로드할 테이블 명
BATCH_SIZE); // 한번에 insert 쿼리를 날릴 때 사용할 jdbc 배치 사이즈
rowHandler.setSkipRowCount(1); // 먼저 기존 header 였던 row 1 을 skip
rowHandler.setHeaderNames("id", // 커스텀한 header 명 지정
"first_name",
"last_name",
"gender",
"country",
"age",
"date",
"purchase_count");
// read 수행
ExcelUtil.readBySax(TEST_FILE, 0, rowHandler);
}
}테스트 해보기
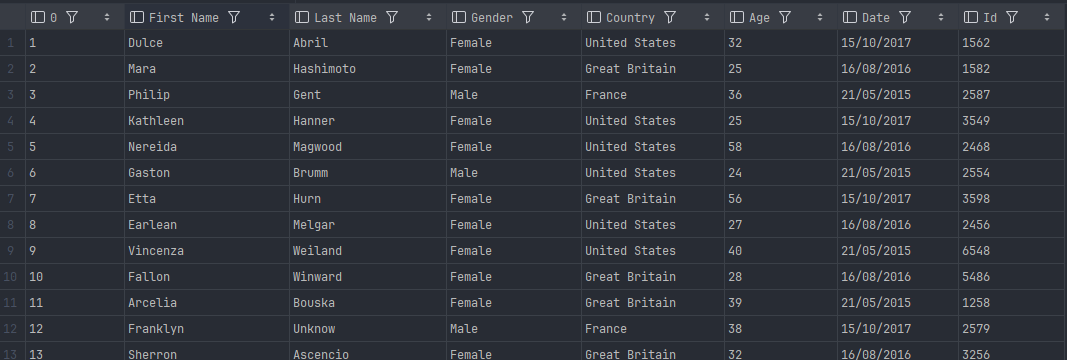
각각의 테스트를 돌려보고 테이블에 데이터가 어떻게 들어갔는지 확인해봅시다.
첫번째이 행이 header 라고 간주하고 업로드 (default 동작)
모든 Row 가 데이터라고 간주하고 업로드 (header custom 세팅은 필수)

기존 첫번째 header row 를 스킵하고 custom header 적용하기
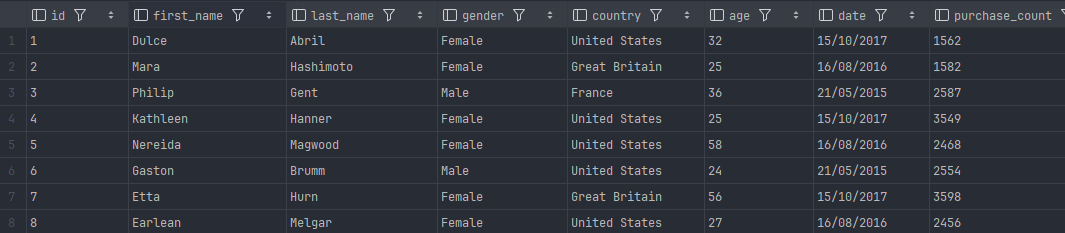
원했던 대로 다 되네요~
🍞 참고링크
