서버가 여러대일 때 세션 저장소 관리는 어떻게 해야할까?
개요
사용자가 서버로 로그인할 때 일반적으로 쿠키와 세션을 동시에 사용한다. 사용자가 로그인으로 POST 메서드를 보내면 서버는 이 요청을 받아 세션 ID를 발급한다. 그리고 세션 ID를 응답 객체에 실어 사용자에게 재전송하고 사용자는 브라우저의 쿠키 저장소에 이 세션 ID를 저장해 상태 유지를 할 수 있다.
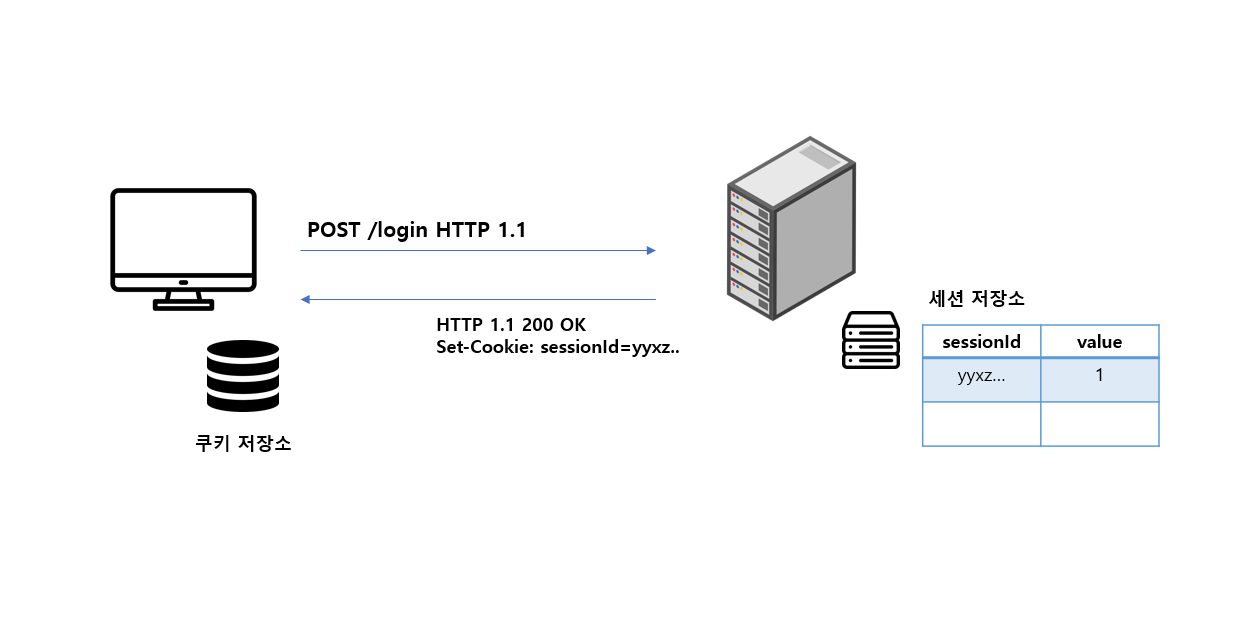
위 그림처럼 서버가 한 대인 경우는 세션 불일치를 고려할 필요가 없다. 문제는 서버가 여러대일 때 발생한다. 상용 서비스는 서버 한 대만으로 운용하는 경우는 거의 없다. 트래픽이 몰릴 때 서버 한 대만으로는 모든 사용자의 요청을 제 시간에 처리하기 어렵기 때문이다.
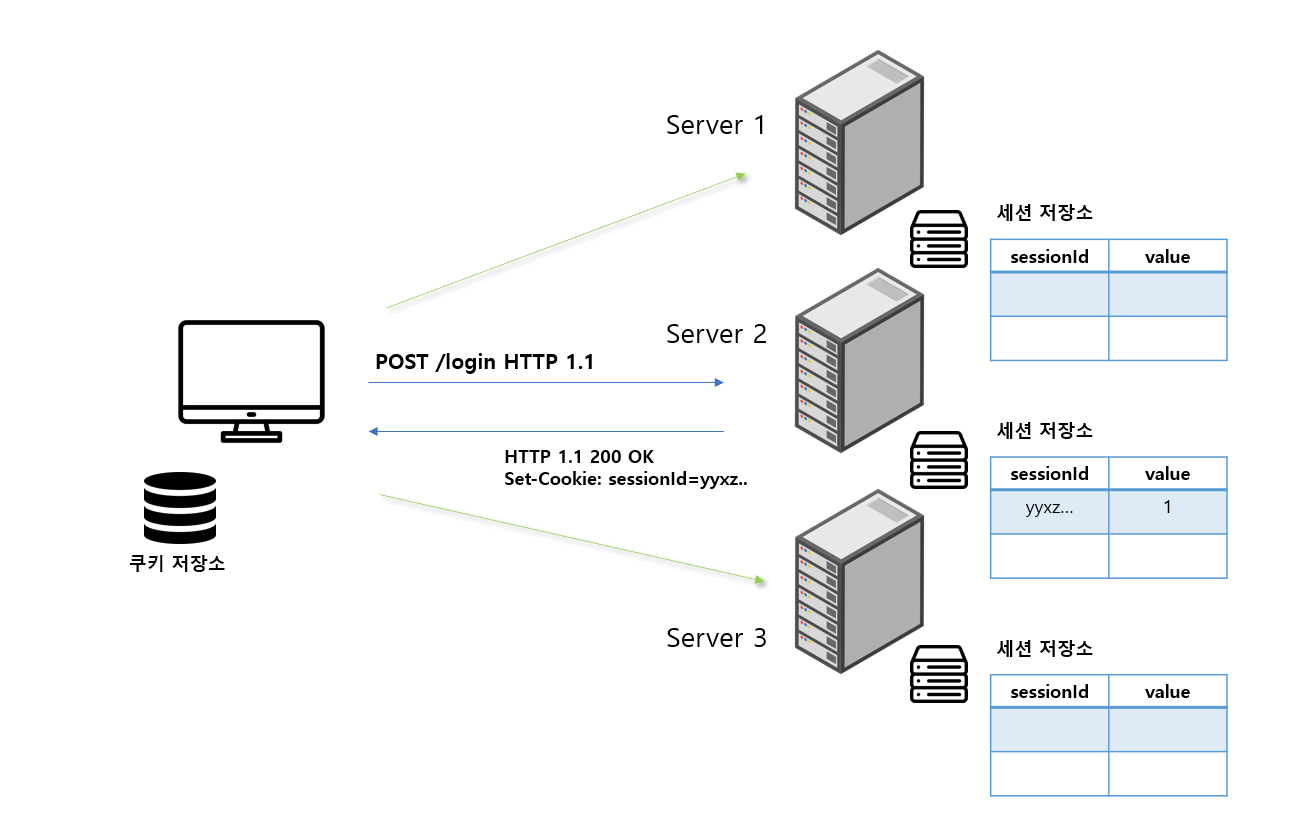
그림을 보면 사용자가 로그인 하기 위해 통신한 서버는 서버2이다. 그래서 현재 서버1과 서버3은 세션 아이디를 가지고 있지 않다.
만약 사용자가 서버2와 통신하다가 다음 요청부터는 서버1이나 서버 3에 요청을 보내면 어떻게 될까? 이런 문제는 흔하다. 기본적으로 하나의 사용자가 하나의 서버만 지정해서 통신한다면 서버가 아무리 많아도 트래픽이 몰릴 때 제대로 된 분배가 불가능하다.
다시 돌아와서 사용자가 서버1과 서버3에 요청을 보내면 당연히 상태 유지는 불가능하고 로그인이 풀릴 것이다. 쿠키 저장소에 담긴 세션 ID를 보내도 서버1과 3의 세션 저장소에는 일치하는 세션 ID가 없기 때문이다.
이런 문제를 해결하기 위한 방법은 세 가지가 있다.
- Session Clustering
- Sticky Session
- Redis Session
이제 각 해결 방법에 대해서 알아보자.
Session Clustering
세션 클러스터링은 두 대 이상의 WAS가 있을 때 통신하지 않는 WAS에도 세션을 공유하는 기술이다.
세션을 공유하는 방식은 모든 WAS 서버에 세션 스토리지를 복제한다. 세션을 복제하면 어떤 WAS 서버에 접속하더라도 세션 ID를 찾을 수 있으므로 정합성 문제가 해결된다. 하지만 복제의 문제는 모든 서버의 세션 저장소에 같은 세션 ID를 저장해야 하기 때문에 세션 저장소의 크기를 상당히 많이 할당해야 한다.
트래픽이 몰릴수록 새로운 사용자의 요청을 처리하는 일은 많아진다. 그리고 많은 요청을 처리하기 위해 서버의 개수도 증가한다. 그리고 새로운 사용자의 요청마다 세션 ID를 발급해야 하는데, 모든 서버에 세션 ID를 복제해야하기 때문에 성능 저하가 발생한다.
세션 클러스터링을 지원하는 WAS 서버에는 Tomcat이 있다. Tomcat에서 지원하는 세션 클러스터링 방법엔 두 가지가 있다.
- all to all 복제를 수행하는 방식(
DeltaManager사용) - 하나의 노드에만 백업 복제를 수행하는 방식(
BackupManager사용)
공식 문서에서도 all-to-all 방식은 클러스터가 작을 때 효율적인 방식이라고 설명하고 있다. 위에서 설명했다시피, 모든 WAS 서버에 세션 저장소를 그대로 복제하면 서버가 많아질수록 성능이 기하급수적으로 떨어지기 때문이다.
더 큰 클러스터인 경우 BackupManager를 사용해 세션이 하나의 백업 노드에만 저장되는 Primary-Backup 세션 복제 전략을 사용해야 한다. 이 방식을 설명하기 위해 아래 그림을 보자. Tomcat WAS가 있고 노드 A, 노드 B, 노드 C가 있다. 참고로 노드는 각각의 Tomcat 프로세스를 의미한다.
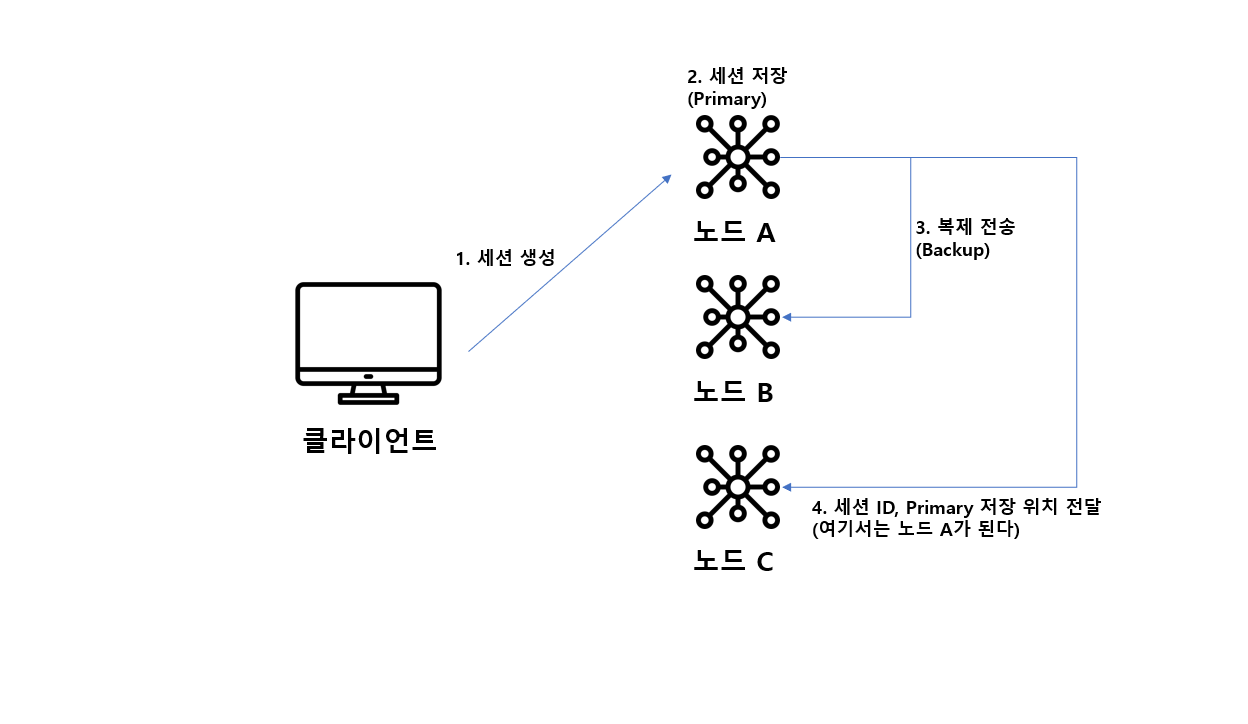
- 최초로 세션 ID와 세션 Value값을 생성해서 노드 A에 전달한다. 여기서 노드 A는 Primary 노드가 된다.
- 이것을 노드 A의 세션 저장소에 저장하고 노드 B에는 복제된 값을 저장한다. 여기서 노드 B는 Backup 노드가 된다.
- 노드 C에는 세션 ID와 해당 세션 ID 값의 Primary 저장 위치값만 전달한다.
all-to-all 방식과 차이점은 세션 ID와 세션 Value를 모든 서버에 복제하는게 아니라 세션 Value 대신 단순 위치값만 다른 서버로 보낸다는 점이다. 당연히 값 자체가 들어가는 세션 Value 보단 위치값만 기입하는 것이 메모리 낭비가 적기 때문에 서버가 많아질수록 효율적이다.
알고리즘을 보면 all-to-all 방식과 primary-backup 방식은 서버 두 개를 초과할 때 차이가 발생하므로, 가동하는 WAS 서버가 세 대 이상이고 세션 클러스터링 방식을 이용할 때 primary-backup 방식을 사용하면 된다.
Sticky Session
Sticky Session을 직역하면 고정된 세션이다. 세션 불일치 문제는 사용자가 최초 통신은 서버 A와 했다가 다음 통신은 서버 B로 하기 때문에 발생한다. 그렇다면 사용자를 구별해 최초 통신한 서버로만 통신하면 정합성 이슈에서 벗어날 수 있다.
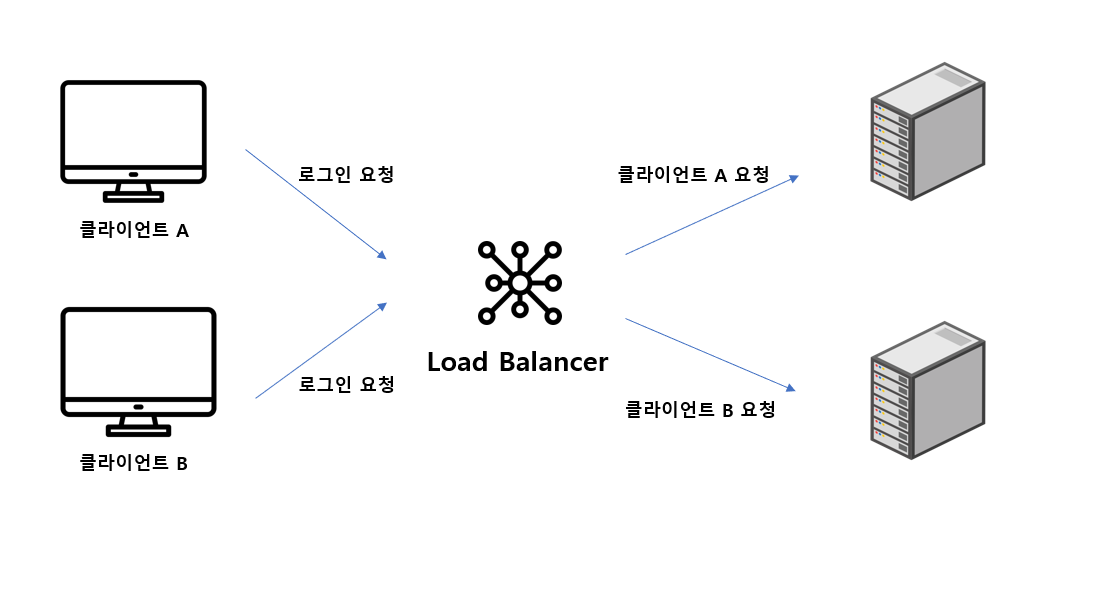
그림과 같이 로그인을 요청한 클라이언트에 로드 밸런서가 서버를 할당하고 그 서버에서만 통신을 주고받는 방식이 Sticky Session 이다. Sticky Session은 세션 복제로 인한 불필요한 메모리 낭비는 없다. 하지만 고정된 세션을 사용한다는 것은 특정 서버에 트래픽이 몰렸을 때도 다른 서버를 사용할 수 없다는 큰 단점이 있다. 또한 하나의 서버가 장애를 일으키면 그 서버와 통신하던 사용자들은 세션 정보를 그대로 잃게 된다. 즉, 가용성이 떨어진다.
HTTP가 무상태성(stateless)를 지향하는 이유는 서버의 확장에 유연하게 대처하기 위해서인데 Sticky Session을 이용하면 이러한 HTTP의 장점을 그대로 없애버리기 때문에 좋은 문제 해결 방법이라고는 볼 수 없다.
Redis Session
Redis는 키-값 데이터 구조의 스토어이고 다양한 인 메모리 데이터 구조 집합을 제공한다. Redis는 캐싱, 세션 관리 등에 사용할 수 있는데 여기서 설명하고자 하는 것이 Redis를 이용한 세션 관리 방식이다.
Redis Session을 사용한다는 것은 인 메모리 DB를 사용한다는 것인데, 이 방식은 아래 그림처럼 세션 저장소(Session Storage)를 별개로 둔다.
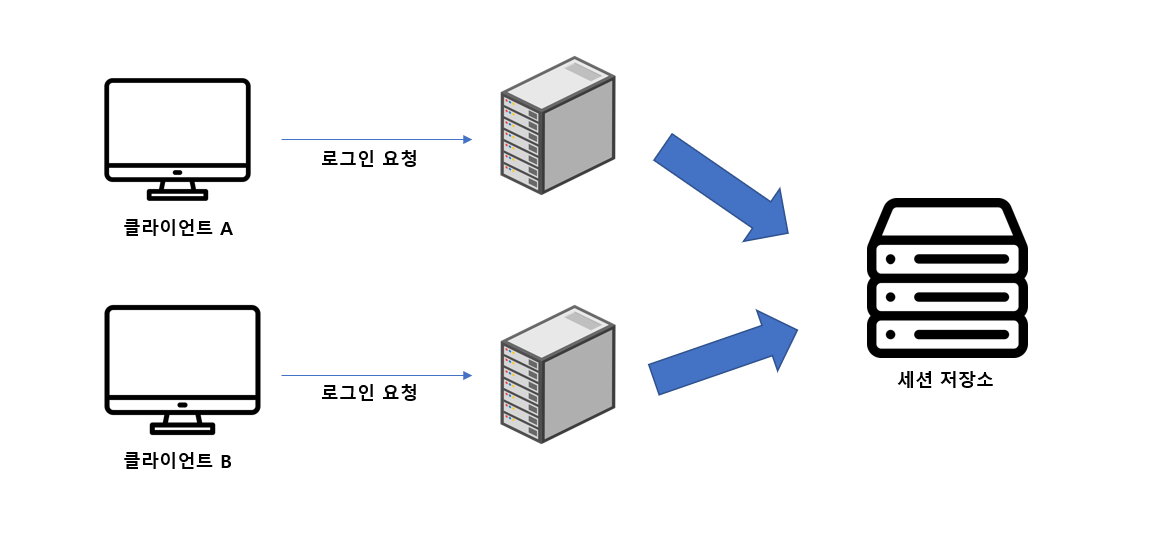
세션 저장소를 별개로 두면 서버가 여러개여도 상관없다. 세션 ID와 세션 값을 별개의 세션 저장소에 저장해두기 때문에 이것을 서로 공유해서 사용하면 되기 때문이다. 이 방식은 트래픽이 몰렸을 때 제대로 분배되지 않는 현상을 고려하지 않아도 되고, 각 WAS엔 세션 저장소가 없기 때문에 메모리 낭비도 일어나지 않는다. 또한 서로 공유해서 사용하는 방식이기 때문에 데이터 정합성 문제도 없다.
다만 하나의 세션 저장소만 운영하는 것은 좋지 않다. 만약 해당 세션 저장소가 오류를 일으키면 모든 세션이 이용 불가능하기 때문에 백업 세션 저장소를 하나 더 두는 것이 좋다.
참고자료
https://tomcat.apache.org/tomcat-8.5-doc/cluster-howto.html#Cluster_Basics
