
스파르타코딩클럽 [왕초보] 엑셀보다 쉬운 sql
3주 차엔 여러 테이블을 연결하여 보다 풍부한 데이터 분석을 할 것이다.
1,2주 차에 배웠던 것을 바탕으로 다양한 데이터를 분석하기에 용이하다고 한다..(시작 할 때만해도 이렇게 복잡한지 몰랐던 나..반성해..)
1. JOIN
두 테이블의 공통된 정보(key 값)를 기준으로 테이블을 연결, 한 테이블 처럼 보는 것을 의미한다.
2. join의 종류
join에는 left join과 inner join 두 개가 있다.
sql에서 join은 두 집합 사이의 관계와 같다 생각하면 된다.
사용의 빈도는 inner join이 많다고 한다.
2-1] left join

위의 그림에서 A와B는 테이블이다.
left join은 A를 기준으로 B를 붙이는 것을 의미한다.
(그림처럼 왼쪽에(A) 붙인다고 보면 이해하기 쉽다.)
» 없는 것들을 포함해서 통계를 내고 싶을 때 사용한다.
select * from users u
left join point_users pu on u.user_id = pu.user_id아래의 예시 사진을 보면
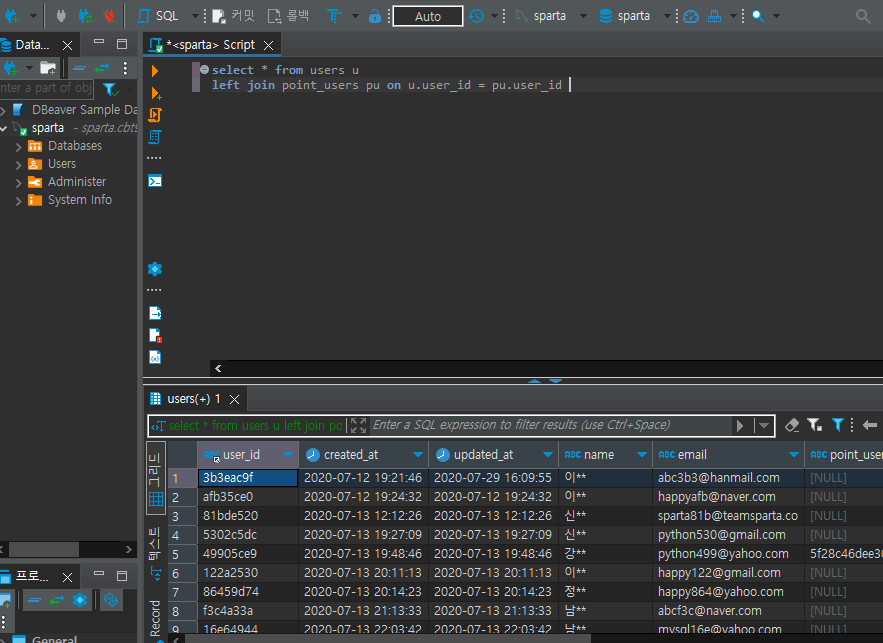
채워 있는 데이터 필드가 있는 반면, 비어있는 데이터 필드가 있다.(NULL=비어있다, 아무것도 없다의 뜻)
채워있는 데이터는 user_id 필드값이 point_users 테이블에 존재해 연결 한 경우이고, 비어있는 데이터는
그와 반대로 point_users 테이블에 존재하지 않기 때문이다.
⨀ left join은 어디에-> 무엇을 붙일건지, 순서가 중요하다!
ex] 유저 중에 포인트가 없는 사람들(=시작하지 않는 사람들)의 통계
select * from users u
left join point_users pu on u.user_id = pu.user_id
⨠ 강의 시작을 안 한 사람들(point x)
select name, count(*) from users u
left join point_users pu on u.user_id = pu.user_id
where pu.point_user_id is NULL
group by name
⨠ 강의 시작한 사람들(포인트 o)
select name, count(*) from users u
left join point_users pu on u.user_id = pu.user_id
where pu.point_user_id is not NULL
group by name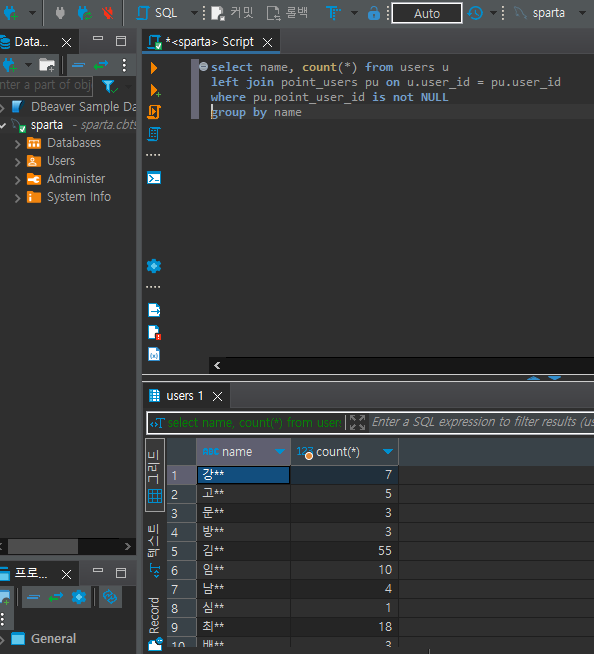
--전혀 간단하지 않았던 연습문제 하나를 예시로 들어보겠다..
(2~3번 다시 풀어봤지만.. 어렵다라고 말하기 보단 헷갈린다..ㅠ
ex] 7월 10일 ~ 7월 19일에 가입한 고객 중, 포인드를 가진 고개의 숫자, 그리고 전체 숫자, 그리고 비율을 보고싶다면 어떻게 해야 할까?
[힌트]
1> count는 NULL을 세지 않는다.
2> Alias도 붙여줘라.
3> 비율은 소수점 둘째자리에서 반올림!
1) left join을 이용하여 데이터 불러오기
select * from users u
left join point_users pu on u.user_id = pu.user_id2) where 절을 이용하여 찾고자 하는 날짜 구간 불러오기
select * from users u
left join point_users pu on u.user_id = pu.user_id
where u.created_at between '2020-07-10' and '2020-07-20'3) 고객의 수, 전체 숫자, 비율 불러오기
select count(point_user_id) as pnt_user_cnt,
count(*) as tot_user_cnt,
round(count(point_user_id)/count(*),2) as ratio
from users u
left join point_users pu on u.user_id = pu.user_id
where u.created_at between '2020-07-10' and '2020-07-20복잡하고 다소 어려움이 많은 연습문제라 풀어서 적어봤다..
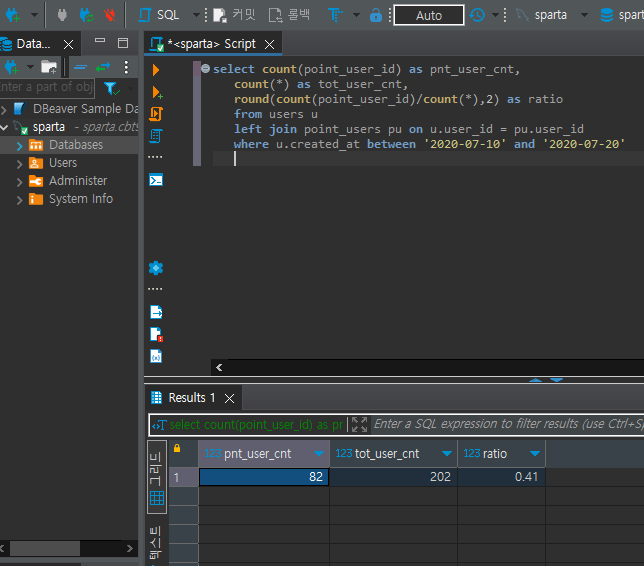
위 사진처럼 결과는 보기 편하다..하하;
2-2] inner join

inner join은 A와B의 교집합을 의미한다.
select * from users u
inner join point_users pu on u.user_id = pu.user_id아래의 예시 사진을 보면 left join과는 다르게 비어있는 데이터 필드가 존재하지 않는다.
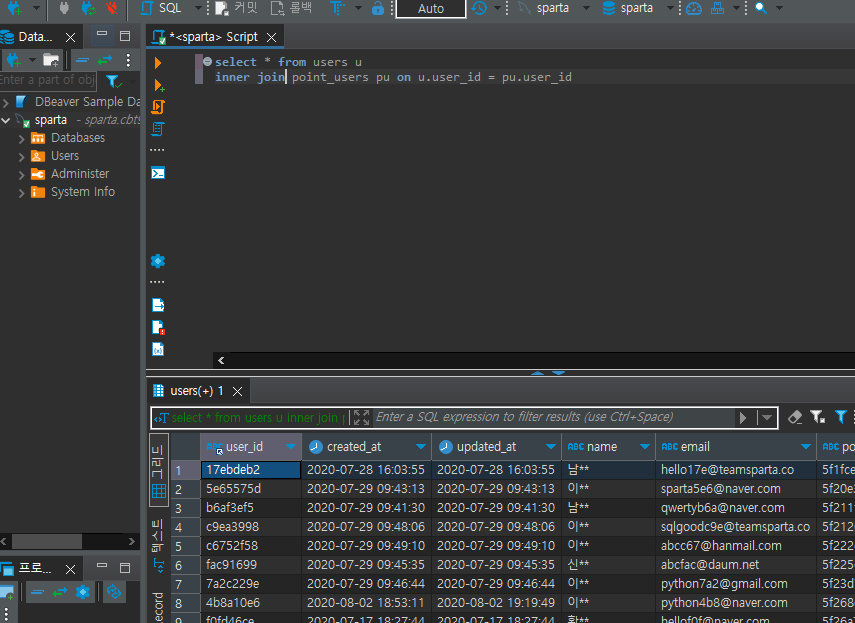
그 이유는 같은 user_id를 두 테이블에서 모두 가지고 있는 데이터만 출렸했기 때문이다.
ex 1]
select * from enrolleds e
inner join courses c on e.course_id = c.course_id1] from enrolleds: enrolleds 테이블 데이터 전체를 가져온다.
2] inner join courses on e.course_id =
c.course_id : courses를 enrolleds 테이블에 붙이는데, enrolleds 테이블의 course_id와 동일한 course_id를 갖는 courses의 테이블을 붙인다.
3] select * : 붙여진 모든 데이터를 출력
위 쿼리가 진행되는 순서: from-> join-> select
⁛ 항상 from에 들어간 테이블을 기준으로, 다른 테이블이 붙는다고 생각하면 된다.
ex 2]
select u.name, count(*) as count_name from orders o
inner join users u
on o.user_id = u.user_id
where u.email like '%naver.com'
group by u.name1] from orders o: orders 테이블 데이터 전체를 가져오고 o라는 별칭을 붙인다(2주 차,Alias 문법 사용)
2] inner join users u on o.user_id = u.user_id : users 테이블을 orders 테이블에 붙이는데, orders 테이블의 user_id와 동일한 user_id를 갖는 users 테이블 데이터를 붙인다.
3] where u.email like '%naver.com': users 테이블 email 필드값이 naver.com으로 끝나는 값만 가져온다.
4] group by u.name: users 테이블의 name값이 같은 값들을 합쳐준다.
5] select u.name, count(u.name) as count_name : users 테이블의 name필드와 name 필드를 기준으로 합쳐진 갯수를 세어서 출력해준다.
위 쿼리의 실행 순서: from-> join-> where-> group by-> select
⁛ join의 실행 순서는 항상 from과 붙어다닌다 생각하면 된다.
-- 5가지 정도의 연습문제를 풀었고 그 중 나에게 어려웠던 문제를 예시로 들어보겠다.
select c1.title, c2.week, count(*) as cnt from courses c1
inner join checkins c2 on c1.course_id = c2.course_id
inner join orders o on c2.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by c1.title, c2.week
order by c1.title, c2.week이 연습 문제는 복잡하기도 했고 여러 문법이 섞여 많이 헷갈리면서 어려웠다..
※ 여기서 준 꿀팁은 orders 테이블에 inner join을 한번 더 걸고, where절로 마무리 하라 했는데, 사실 답안을 보고 나서 이해했다는 후문이..ㅎㅎ;;
3. Union
결과물을 한번에 모아 보고 싶을 때 사용한다.
(단, 두 쿼리의 필드명이 같아야 한다는 조건이 붙는다.)

예를 들어 이해하기 쉽도록 해보자.
위의 ex 2]를 가지고 와 해보도록 하자.
7월과 8월의 데이터를 한번에 보고 싶으면,
(
select '7월' as month, c1.title, c2.week, count(*) as cnt from courses c1
inner join checkins c2 on c1.course_id = c2.course_id
inner join orders o on c2.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by c1.title, c2.week
order by c1.title, c2.week
)
union all
(
select '8월' as month, c1.title, c2.week, count(*) as cnt from courses c1
inner join checkins c2 on c1.course_id = c2.course_id
inner join orders o on c2.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by c1.title, c2.week
order by c1.title, c2.week
)이렇게 기존 쿼리문에 '7월' as month, '8월' as month 를 select 뒤에 입력, ()로 각 쿼리문을 묶어준 후 union all을 사이에 입력하면 원하는 결과 데이터나 나오게 된다.
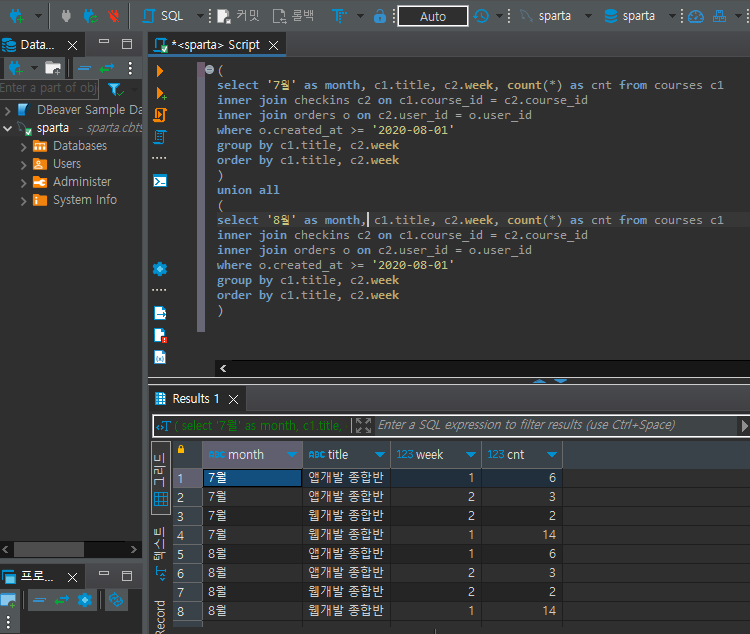
여기서 문제가 하나 있다면 union을 사용하게 되면 내부 정렬이 적용되지 않는다.
이 부분은 4주 차 subQuery에서 배울 예정이다!
3주 차까지 달려온 소감은.. 1,2주 차는 그저 맛보기에 불과했다.. 지금부터 배우는 것이 sql의 정수라는 거.. 어려움도 있고 헷갈리는 부분 역시 존재하지만, 제대로 된 쿼리문을 작성하고 나서의 결과 도출은 생각보다 짜릿함이 있다.(내가 해내다니..!😭) 4주 차도 달려 보자고~!~!~!
