학습내용
서브쿼리
SELECT film_id, title
FROM film
WHERE film_id IN
(SELECT inventory.film_id
FROM rental
INNER JOIN inventory ON inventory.inventory_id = rental.inventory_id
WHERE rental.return_date BETWEEN '2005-05-29' AND '2005-05-30')
-- inventory테이블, rental테이블에서
-- 인벤토리 아이디가 같은 것들의 교집합을 join서브쿼리는 다양한 결괏값을 갖고있으니 IN 오퍼레이터를 써야한다.
기본키
기본키 (Primary Key, PK)
- 각 행을 고유하게 식별하는 열의조합이다. => 고유한 값만 가지며, NULL값은 허용X
- 한 테이블에는 하나의 기본키만 존재.
외래키 (Foreign Key, FK)
- 다른 테이블의 기본키를 참조하는 한 테이블의 열.
- 외래키가 참조하는 테이블은 레퍼런스 테이블이라고 부르고, 참조하는 테이블의 값이 변경될때 외래키가 있는 테이블에도 영향이 반영됨 => 무결성 유지
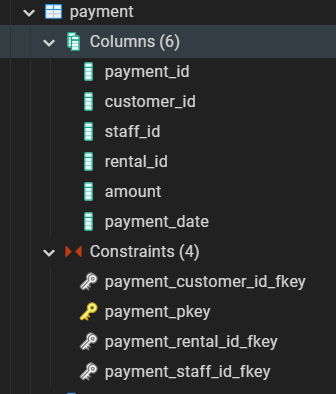
⇒ Constraints 탭에서 금색키 기호가 payment표의 기본키이다.
⇒ 여기서 특정한 키를 클릭한후 쿼리 에디터 탭을 dependencies 탭으로 바꾸면,
어떤 표와 레퍼런스 되어 있는지 알 수 있다.
customer.customer_id라고 레퍼런싱이 나와있다.
테이블 생성하기
단순하게 create 명령어만 생각할게 아닌, 외래키 제약조건이나, 인덱스를 추가한다거나 등의 작업도 생각을 해야한다.
CREATE TABLE account(
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
password VARCHAR(50) NOT NULL,
email VARCHAR(250) UNIQUE NOT NULL,
created_on TIMESTAMP NOT NULL,
last_login TIMESTAMP
)팀스터디
Q1. RDBMS와 NoSQL의 차이에 대해 설명해주세요 + 장단점
RDBMS
특징
- SQL 쿼리언어를 사용하여 데이터 관리를 할 수 있고, 효율적인 보관이 목적이다. => 구조화가 굉장히 중요하다!
- 사전에 엄격하게 정의된 스키마가 있다. => 테이블 기반으로 데이터의 '관계'를 관리. => 무결성 보장, 데이터 중복방지
- 기존 애플리케이션과의 호환성 문제가 적다.
단점
- 수직적 확장 => 비용면에서 비싸고, 데이터가 한곳의 서버에서 관리되므로 이슈생기면 곤란함.
- 유연성X => 스키마가 엄격하게 정의되어 있으므로.
NoSQL
특징
- 사전에 엄격하게 정의된 스키마 X => 유연성⬆️, 비정형 데이터 다루기 용이
- 수평확장을 할 수 있다. => 데이터 분산처리를 지원하여 대규모 데이터를 다루기에 용이하다.
- 대표적으로 document DB, key-value store 등이 있다.
단점
- 유연하다는 장점이 오히려 데이터 구조 결정을 지연시키기도 함.
- 데이터가 여러 컬렉션에 중복되어 있으므로, 수정시 모든 컬렉션에서 계속 업데이트 해야함.
Q2. 데이터베이스에서 인덱스를 사용하는 이유와 장단점에 대해 설명해주세요☺️
인덱스란?
인덱스는 데이터 검색에 있어서 책의 마지막장에 있는 '색인'과 같은 역할을 한다.
책의 본문 내용을 한장씩 찾아보지 않더라도 색인을 통해 빠르게 펼쳐볼 수 있는 것처럼, 인덱스를 설정하면 테이블 안에 찾고자 하는 데이터를 빠르게 찾을 수 있습니다.
효율적인 이유(장점)
균형잡힌 B-Tree 기반 탐색
트리 생성 과정에서의 대수 확장성
단점
데이터베이스 파일 크기가 증가합니다.
Q3. 정규화와 비정규화에 대해 설명해주세요.
-
정규화란, 데이터 무결성을 유지하기 위해 정의된 방식으로 테이블을 분할하여 데이터베이스에서 중복 데이터를 제거하는 프로세스입니다. 이 과정을 통해 저장 공간을 절약하고 이상 현상을 제거할 수 있습니다. 그러나 릴레이션 분해로 인해 연산이 증가한다는 단점이 있습니다.
-
반정규화란, 데이터베이스 성능 향상을 위해 테이블에 중복 데이터를 추가하는 프로세스입니다.
Q4. 데이터 무결성의 의미와 유형에 대해 설명해주세요.
-
의미
말 그대로 데이터에 결함이 없는 상태를 뜻하며, 데이터를 정확하고 유효하게 유지하는 것을 말한다.
데이터의 정확성과 일관성을 유지/보증하기 위해 데이터베이스의 삽입, 삭제, 연산으로 상태가 변하더라도 무결성 제약조건을 반드시 지켜져야 한다. -
유형
🔑 Key란?
- 개체무결성
=> 모든 테이블은 기본키를 가져야하며, null값은 허용 X- 참조무결성
=> 모든 외래 키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 한다. 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다.- 도메인무결성
=> 정의된 범위에서 모든 열이 선언되어야 한다.- 키 무결성
=> 릴레이션에는 최소한 하나의 키가 존재해야 한다.- null 무결성
=> 특정속성은 스키마를 정의할때 null 값을 가질 수없게 정의한다.- 고유 무결성
=> 각 튜플의 속성값은 중복되지 않는 고유한 값이어야 한다. e.g. 유저아이디, 이메일
검색, 정렬 시 튜플(레코드, 행)을 구분할 수 있는 기준이 되는 속성을 말한다.
- 기본키(Primary Key) : table당 1개만 지정하며, 하나의 테이블에서 특정 튜플을 구별할 수 있는 속성(Attribute)을 의미한다.
- 후보키(Candidate Key) : 기본키로 사용할 수 있는 속성(유일성, 최소성)을 의미한다.
- 외래키(Foreign Key) : 참조되는 테이블의 기본키와 대응되어 테이블 간에 참조 관계를 표시하는 키로, 테이블 간의 잘못된 매핑을 방지하는 역할을 한다.
