TOP N QUERY
- 페이징 처리를 효과적으로 수행하기 위해 사용
- 전체 결과에서 특정 N개 추출
ROWNUM
- 출력된 데이터 기준으로 행 번호 부여
- 절대적인 행 번호가 아닌 가상의 번호 ( '=' 연산 불가)
- 첫번째 행이 증가한 이후 할당되므로 '>' 연산 사용 불가
SELECT *
FROM (SELECT * FROM EMP ORDER BY SAL DESC)
WHERE ROWNUM <= 5
ORDER BY SAL DESC;FETCH 절
- 출력될 행의 수를 제한하는 절
- ORACLE 12C 이상부터 제공
- ORDER BY 절 뒤에 사용
... ORDER BY
OFFSET N { ROW | ROWS }
FETCH { FIRST | NEXT } N {ROW | ROWS} ONLY
// EMP에서 SAL 순서대로 상위 5명
SELECT EMPNO, ENAME, JOB, SAL
FROM EMP
ORDER BY SAL DESC FETCH FIRST 5 ROWS ONLY계층형 질의
- 하나의 테이블 내 각 행끼리 관계를 가질 때,
연결고리를 통해 행과 행 사이의 계층을 표현하는 기법 - PRIOR의 위치에 따라 연결하는 데이터가 달라짐
SELECT
FROM 테이블명
START WITH 시작조건
CONNECT BY PRIOR 연결조건
// DEPT2 테이블에 대해 각 부서의 레벨을 출력
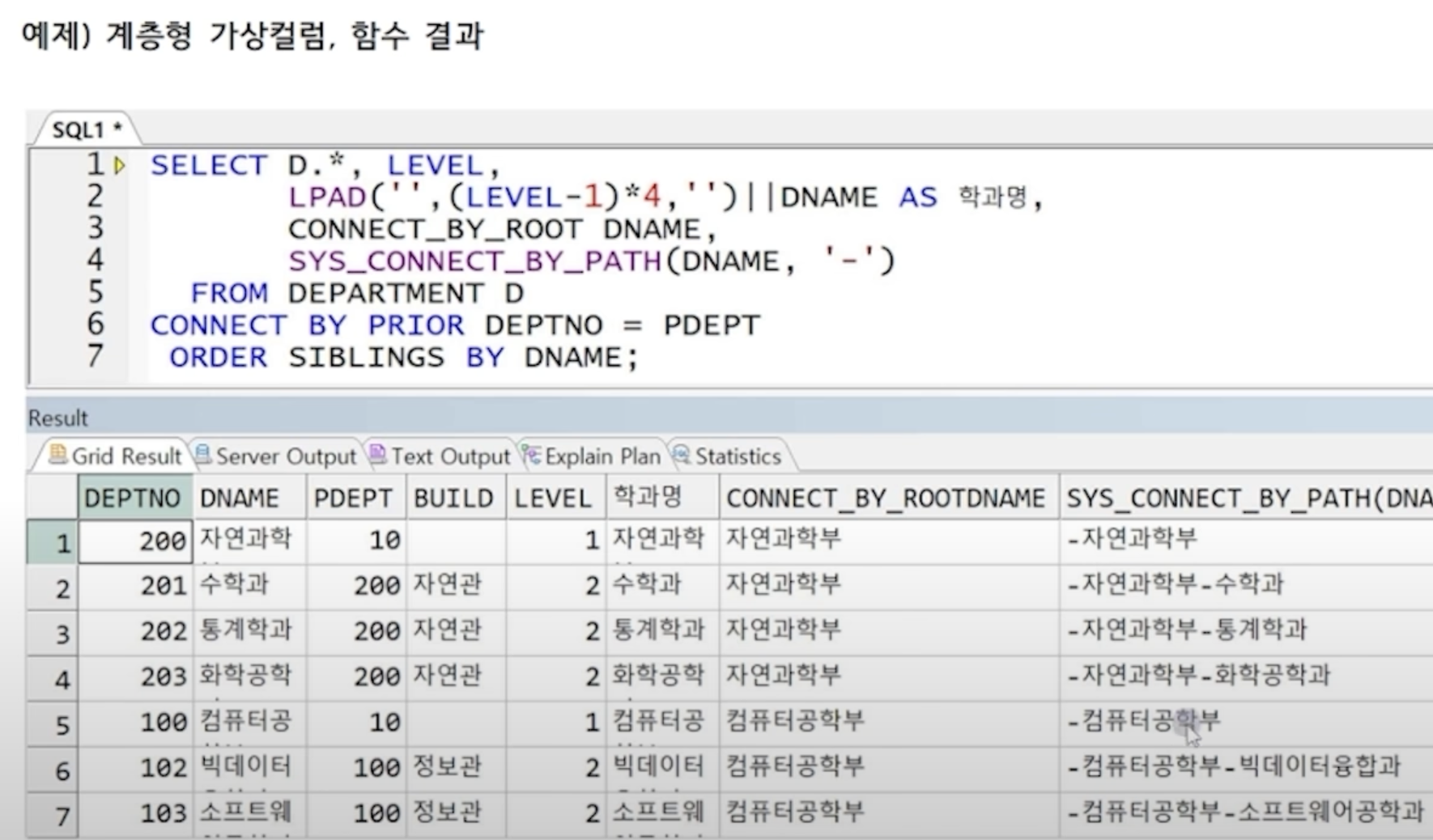
SELECT D.*, LEVEL
FROM DEPT2 D
START WITH PDEPT IS NULL
CONNECT BY PRIOR DCODE = PDEPT;계층형 질의 가상 컬럼
- LEVEL
- 각 DEPTH를 표현 (시작점부터 1) - CONNECT_BY_ISLEAF
- LEAF NODE(최하위 노드) 여부 (1: 참, 0: 거짓)
계층형 질의 가상 함수
- CONNECT_BY_ROOT 컬럼명
- 루트노드의 해당 컬럼명의 값이 출력 - SYS_CONNECT_BY_PATH(컬럼, 구분자)
- 이어지는 경로 출력 - ORDER SIBLINGS BY 컬럼
- 같은 LEVEL일 경우 정렬 수행
데이터의 구조
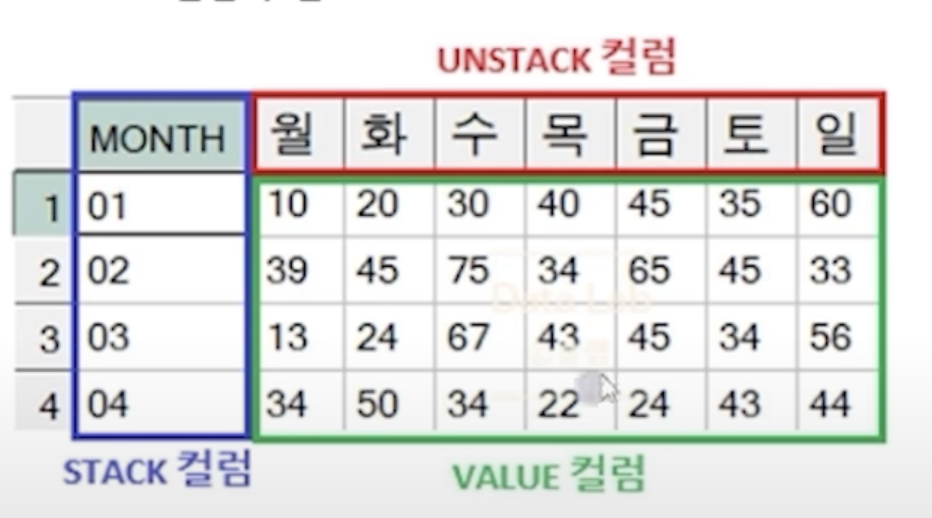
LONG DATA (Tidy data)
- 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조
- RDBMS의 테이블 설계 방식
- 다른 테이블과의 조인 연산이 가능한 구조
WIDE DATA (Cross table)
- 행과 컬럼에 유의미한 정보 전달을 목적으로 작성하는 교차표
- 하나의 속성값이 여러 컬럼으로 분리되어 표현
데이터 구조 변경
PIVOT : LONG -> WIDE
- 교차표를 만드는 기능
- STACK, UNSTACK, VALUE 컬럼의 정의
- FROM 절에 STACK, UNSTACK, VALUE 컬럼명만 정의 필요
- PIVOT 절에 UNSTACK, VALUE 컬럼명 정의
- PIVOT 절 IN 연산자에 UNSTACK 컬럼값을 정의
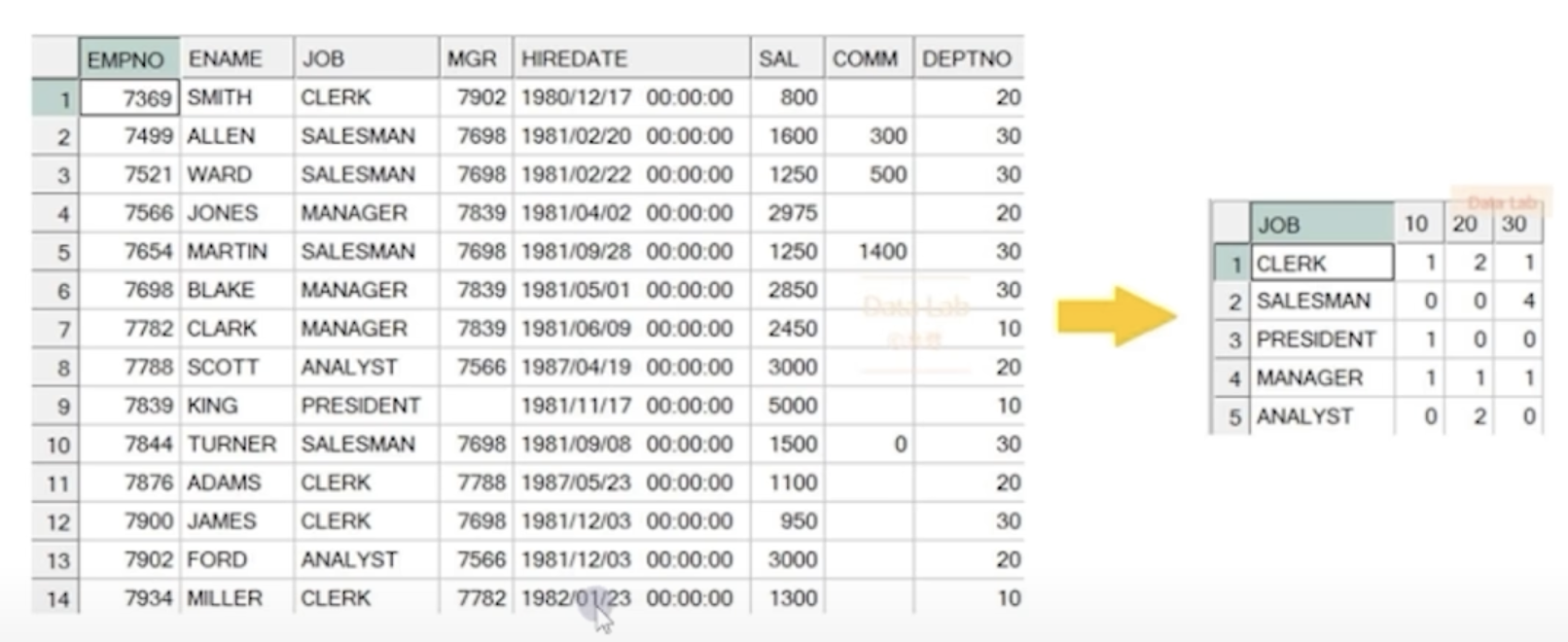
SELECT *
FROM 테이블명 또는 서브쿼리
PIVOT (VALUE 컬럼명 FOR UNSTACK 컬럼명 IN (값1, 값2, 값3));UNPIVOT : WIDE -> LONG
- STACK 컬럼 : 이미 UNSTACK 되어있는 여러 컬럼을 하나의 컬럼으로 STACK시 새로 만들 컬럼 이름 (사용자 정의)
- VALUE 컬럼 : 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할때 새로 만들 컬럼명 (사용자 정의)
- 값1, 값2...: 실제 UNSTACK이 되어있는 컬럼 이름들
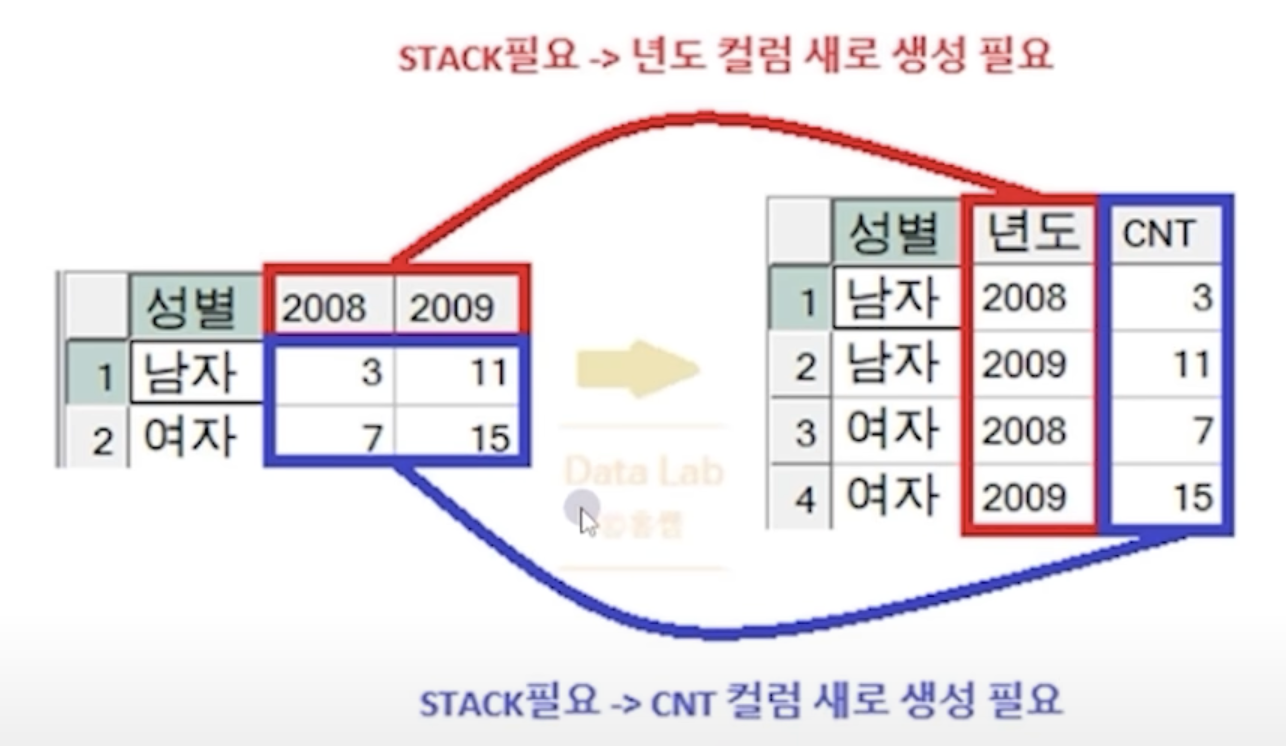
SELECT *
FROM 테이블명 또는 서브쿼리
UNPIVOT (VALUE 컬럼명 FOR STACK 컬럼명 IN(값1,값2..));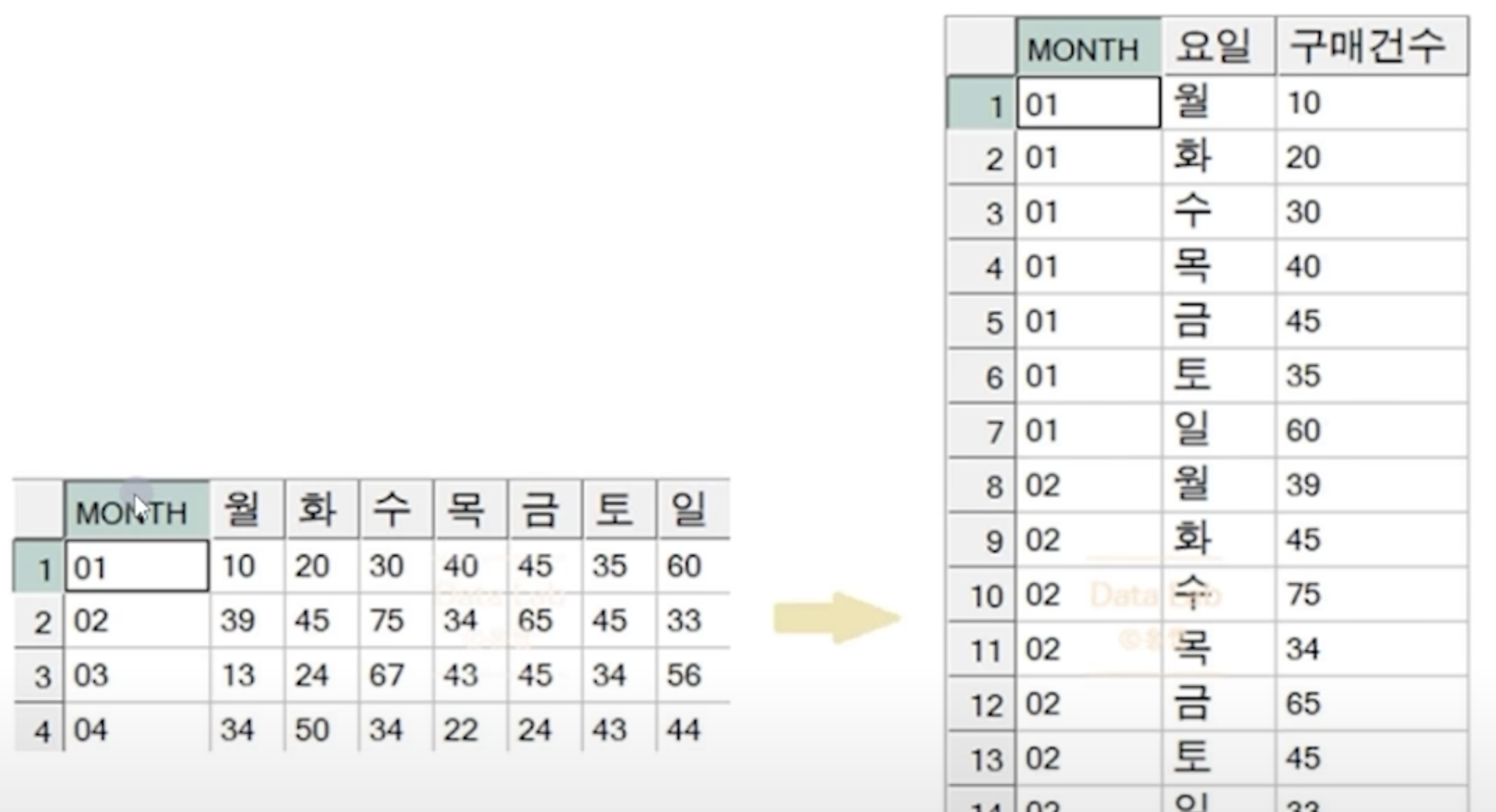
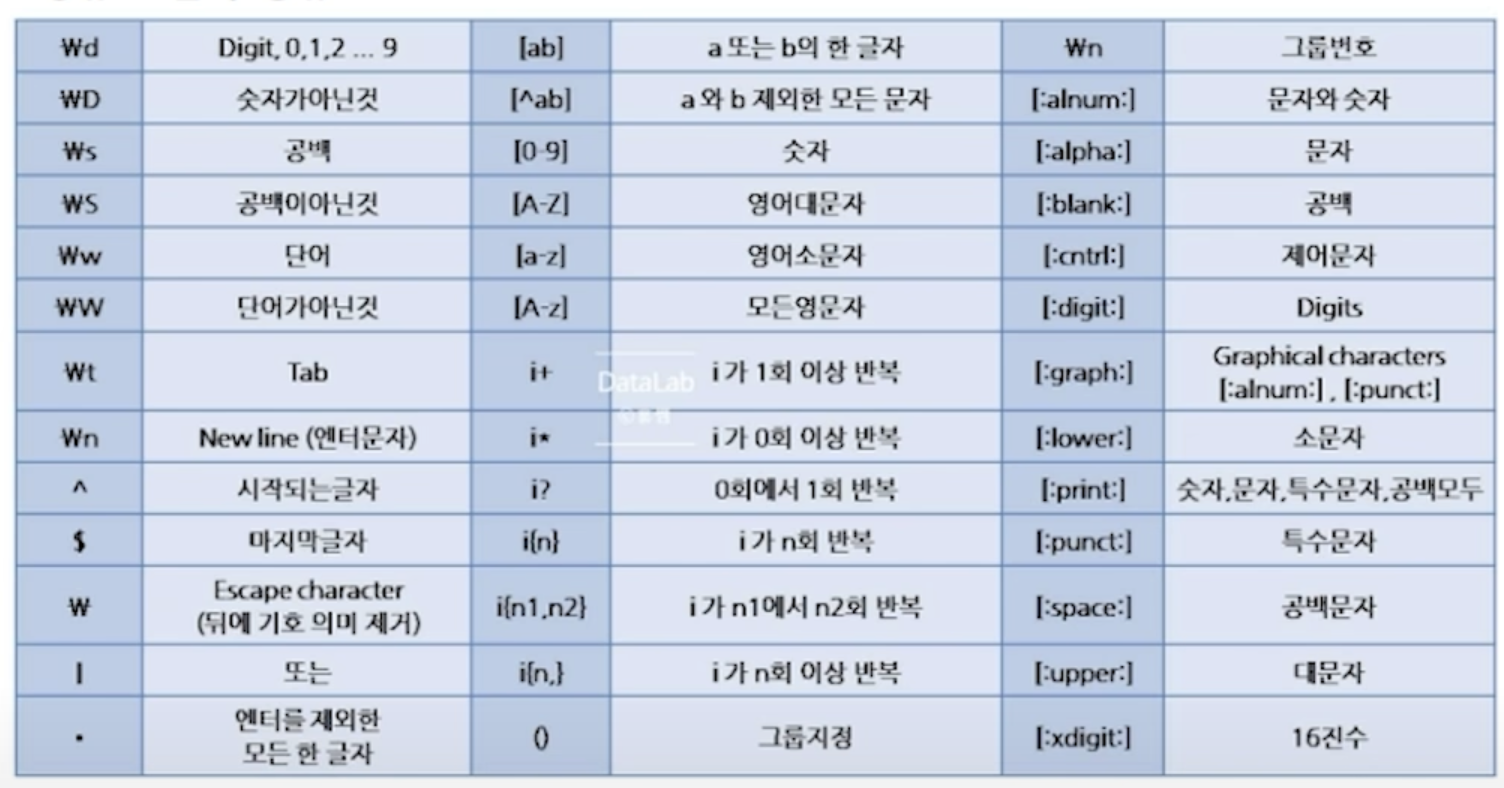
정규표현식
- 문자열의 공통된 규칙을 보다 일반화 하여 표현하는 방법
- 정규표현식 사용 가능한 문자함수 (regexp_replace, regexp_substr...)
정규표현식 종류
REGEXP_REPLACE
- 정규식 표현을 사용한 문자열 치환 기능
(대상, 찾을문자열, [바꿀문자열], [검색위치], [발견횟수], [옵션])
바꿀문자열 생략 시 문자열 삭제
검색위치 생략 시 1
발견횟수 생략 시 0 (모든)
옵션
c : 대소를 구분하여 검색
i : 대소를 구분하지 않고 검색
m : 패턴을 다중라인으로 선언 가능
//ID에서 숫자 삭제
SELECT ID,
REGEXP_REPLACE(ID, '\d', ''),
REGEXP_REPLACE(ID, '[[:digit:]]', '')
FROM PROFESSOR;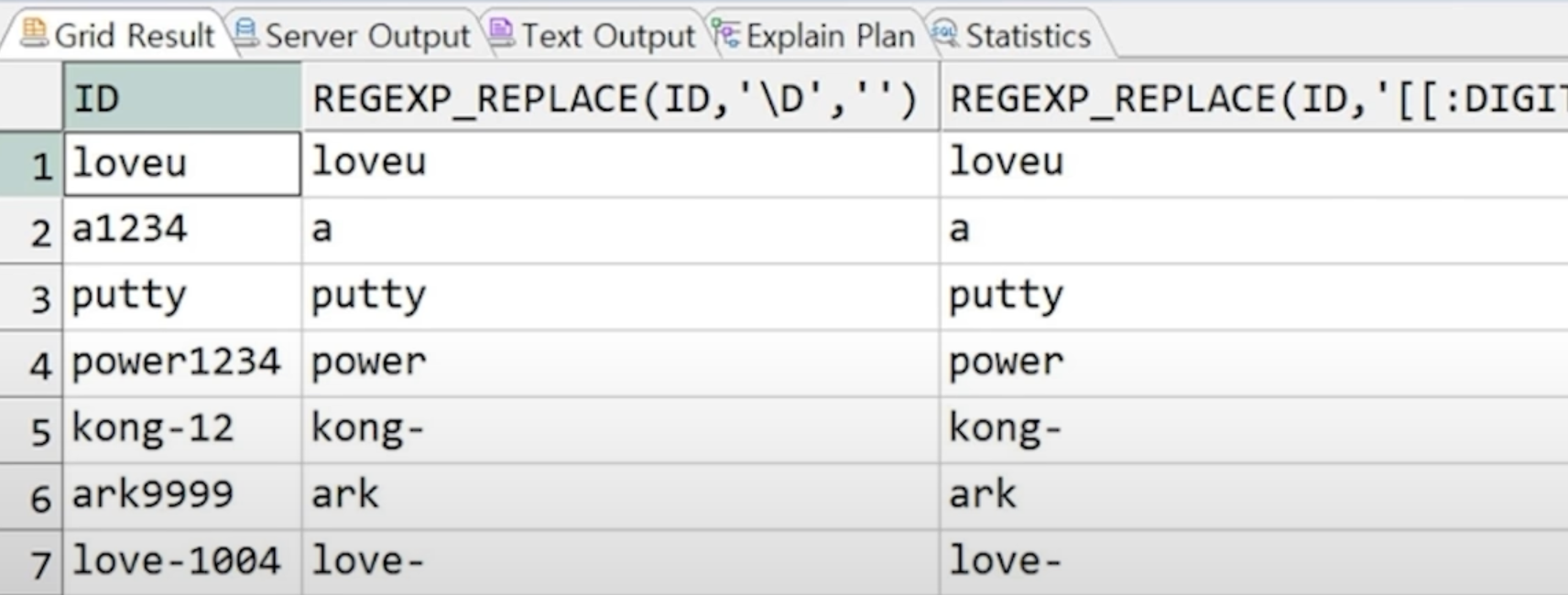
//ID에서 특수기호 삭제
SELECT ID
EXGEXP_REPLACE(ID, '\w', '') AS RESULT1,
EXGEXP_REPLACE(ID, '\w|_', '') AS RESULT2,
EXGEXP_REPLACE(ID, '[[:punct:]]', '') AS RESULT3
FROM PROFESSOR;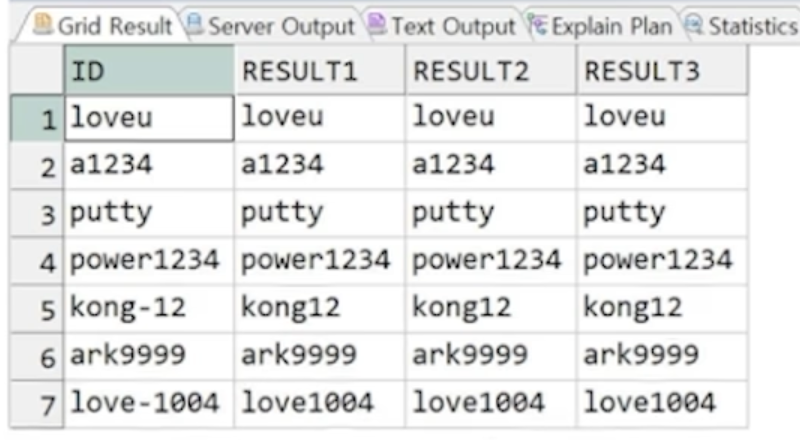
REGEXP_SUBSTR
- 정규식 표현을 사용한 문자열 추출
REGEXP_SUBSTR(대상, 패턴, [검색위치]], [발견횟수], [옵션], [추출그룹])
검색위치 생략 시 1
발견횟수 생략 시 1
추출그룹은 서브패턴을 추출 시 그 중 추출할 서브패턴 번호
// 전화번호를 분리하여 지역번호 추출
SELECT TEL,
REGEXP_SUBSTR(TEL,
'(\d+)\)(\d+)-(\d+)',
1,
1,
null,
1) AS 지역번호
FROM STUDENT;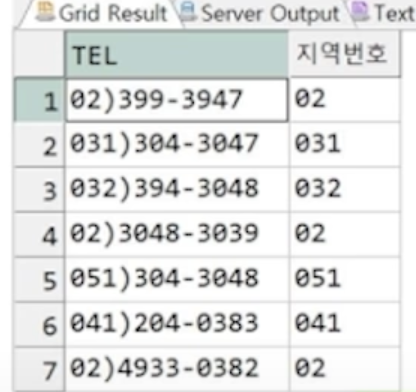
REGEXP_INSTR
- 주어진 문자열에서 특정패턴의 시작 위치를 반환
REGEXP_INSTR(원본, 찾을문자열, [시작위치], [발견횟수])
시작위치 생략 시 처음부터 확인 (기본값 1)
발견횟수 생략 시 처음 발견된 문자열 위치 리턴
// ID 값에서 두 번째 발견된 숫자의 위치
SELECT ID,
REGEXP_INSTR(ID, '\d', 1, 2)
FROM PROFESSOR;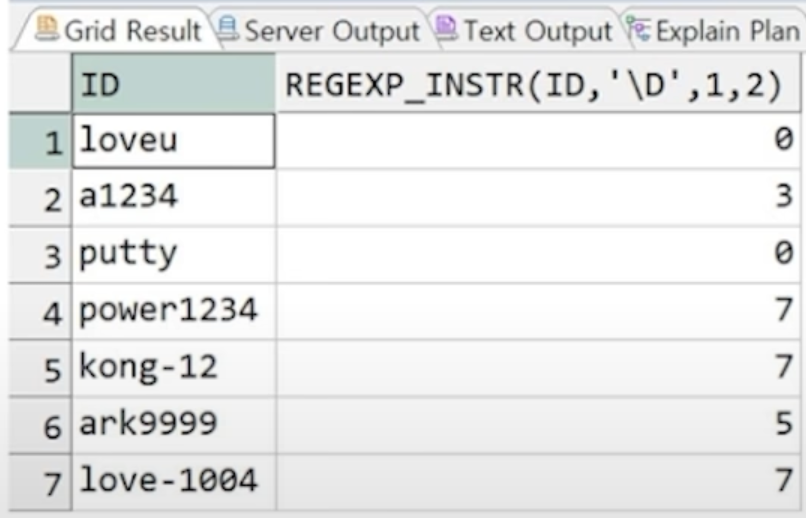
REGEXP_LIKE
- 주어진 문자열에서 특정 패턴을 갖는 경우 반환 (WHERE절 사용만 가능)
REGEXP_LIKE(원본, 찾을문자열, [옵션])
//ID값이 숫자로 끝나는 교수 정보 출력
SELECT *
FROM PROFESSOR
WHERE REGEXP_LIKE(ID, '\d$');REGEXP_COUNT
- 주어진 문자열에서 특정패턴의 횟수를 반환
REGEXP_COUNT(원본, 찾을문자열, 시작위치, [옵션])
// ID값에서의 숫자의 수
SELECT ID,
REGEXP_COUNT(ID, '\d') AS RESULT1, // 한 자리수의 숫자의미
REGEXP_COUNT(ID, '\d+') AS RESULT2 // 연속적인 숫자를 의미
FROM PROFESSOR;홍쌤의 데이터랩
SQLD 2과목 PART2. SQL 활용 완벽 정리 (2024년 신유형 반영) 강의에 대해
공부 및 개인적으로 정리한 글 입니다.
