📍 메모리 관리
▶︎ 메모리 관리
- 운영체제의 대표적인 할 일 중 하나가 메모리 관리이다. 컴퓨터 내의 한정된 메모리를 극한으로 활용해야 하는 것이다.
▶︎ 가상 메모리
-
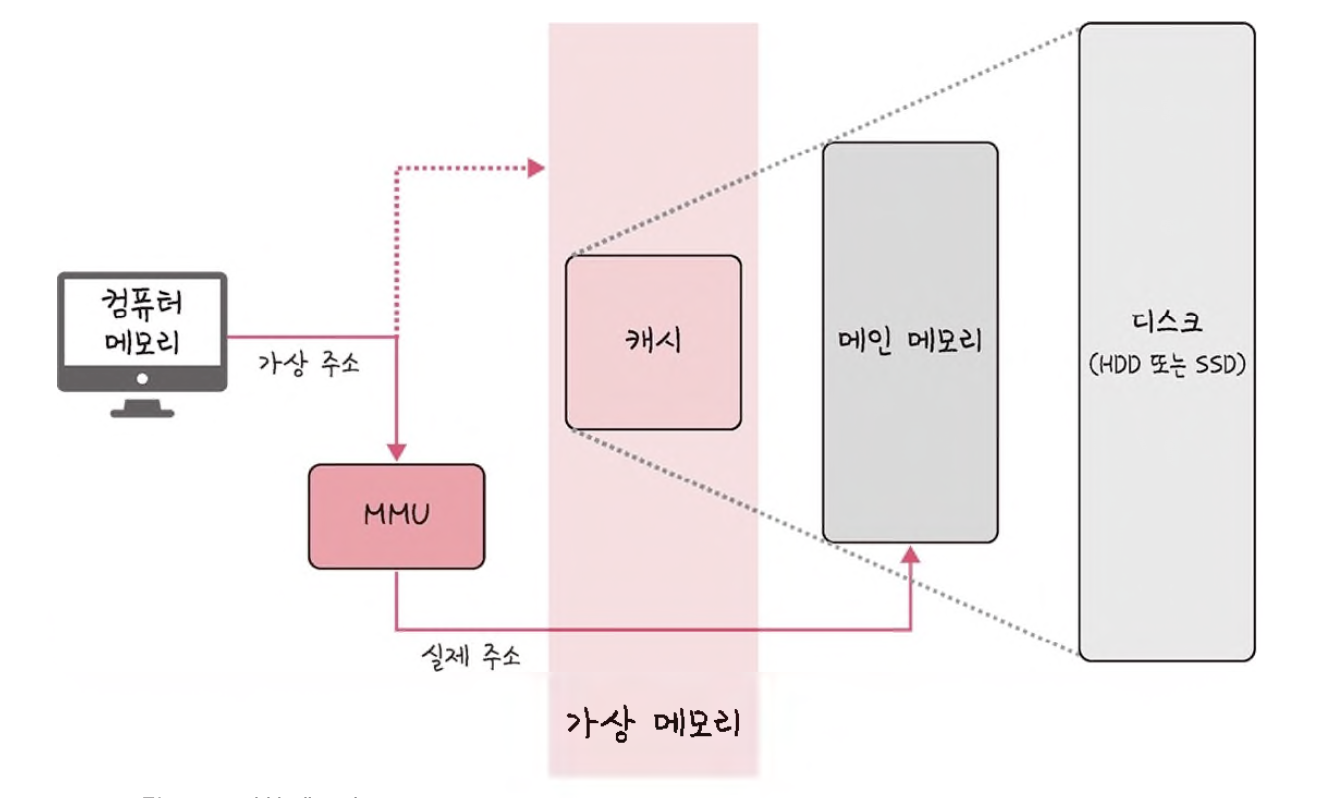
가상 메모리는 메모리 관리 기법의 하나로 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 이를 사용하는 사용자들에게 매우 큰 메모리로 보이게 만드는 것을 말한다.
-
가상적으로 주어진 주소를 가상 주소(logical address)라고 하며, 실제 메모리상에 있는 주소를 실제 주소(physical address)라고 한다.
-
가상 주소는 메모리관리장치(MMU)에 의해 실제 주소로 변환되며, 사용자는 실제 주소를 의식할 필요 없이 프로그램을 구축할 수 있다.
-
가상 메모리는 가상 주소와 실제 주소가 매핑 되어 있고 프로세스의 주소 정보가 들어 있는 '페이지 테이블'로 관리된다. 이때 속도 향상을 위해 TLB를 쓴다.
→ TLB : 메모리와 CPU 사이에 있는 주소 변환을 위한 캐시이다. 페이지 테이블에 있는 리스트를 보관하며 CPU가 페이지 테이블까지 가지 않도록 해 속도를 향상시킬 수 있는 캐시 계층이다.
▶︎ 스와핑
-
가상 메모리에는 존재하지만 실제 메모리인 RAM에는 현재 없는 데이터나 코드에 접근할 경우 페이지 폴트가 발생한다.
-
이때 메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮기고 하드디스크의 일부분을 마치 메모리처럼 불러와 쓰는 것을 스와핑이라 한다.
-
이를 통해 마치 페이지 폴트가 일어나지 않은 것처럼 만든다.
▶︎ 페이지 폴트
- 프로세스의 주소 공간에는 존재하지만 지금 이 컴퓨터의 RAM에는 없는 데이터에 접근했을 경우 발생한다. 페이지 폴트와 그로 인한 스와핑은 다음 과정으로 이루어진다.
-
CPU는 물리 메모리를 확인하여 해당 페이지가 없으면 트랩을 발생해서 운영체제에 알린다.
-
운영체제는 CPU의 동작을 잠시 멈춘다.
-
운영체제는 페이지 테이블을 확인하여 가상 메모리에 페이지가 존재하는지 확인하고, 없으면 프로세스를 중단하고 현재 물리 메모리에 비어 있는 프레임이 있는지 찾는다. 물리 메모리에도 없다면 스와핑이 발동된다.
-
비어 있는 프레임에 해당 페이지를 로드하고, 페이지 테이블을 최신화한다.
-
중단되었던 CPU를 다시 시작한다.
→ 페이지
: 가상 메모리를 사용하는 최소 크기 단위
→ 프레임
: 실제 메모리를 사용하는 최소 크기 단위
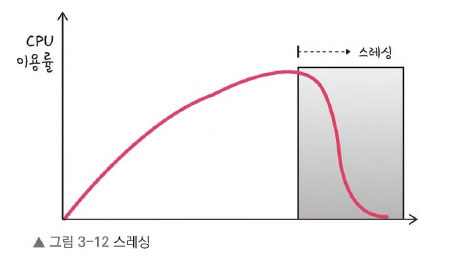
▶︎ 스레싱
-
스레싱(thrashing)은 메모리의 페이지 폴트율이 높은 것을 의미하며, 이는 컴퓨터의 심각한
성능 저하를 초래한다. -
스레싱은 메모리에 너무 많은 프로세스가 동시에 올라가게 되면 스와핑이 많이 일어나서 발생한다. 페이지 폴트가 일어나면 CPU 이용률이 낮아진다.
-
CPU 이용률이 낮아지게 되면 운영체제는 가용성을 더 높이기 위해 더 많은 프로세스를 메모리에 올리게 된다.
-
이와 같은 악순환이 반복되며 스레싱이 일어난다.
작업 세트
- 작업 세트(working set)는 프로세스의 과거 사용 이력인 지역성(locality)을 통해 결정된 페이지 집합을 만들어서 미리 메모리에 로드하는 것이다. 미리 메모리에 로드하면 탐색에 드는 비용을 줄일 수 있고 스와핑 또한 줄일 수 있다.
PFF (Page Fault Frequency)
- 페이지 폴트 빈도를 조절하는 방법으로 상한선과 하한선을 만드는 방법이다. 만약 상한선에 도달한다면 프레임을 늘리고 하한선에 도달한다면 프레임을 줄이는 것이다.
▶︎ 메모리 할당
- 메모리에 프로그램을 할당할 때는 시작 메모리 위치, 메모리 할당 크기를 기반으로 할당하는데, 연속 할당과 불연속 할당으로 나뉜다.
연속 할당
-
메모리에 연속적으로 공간을 할당하는 것을 말한다.
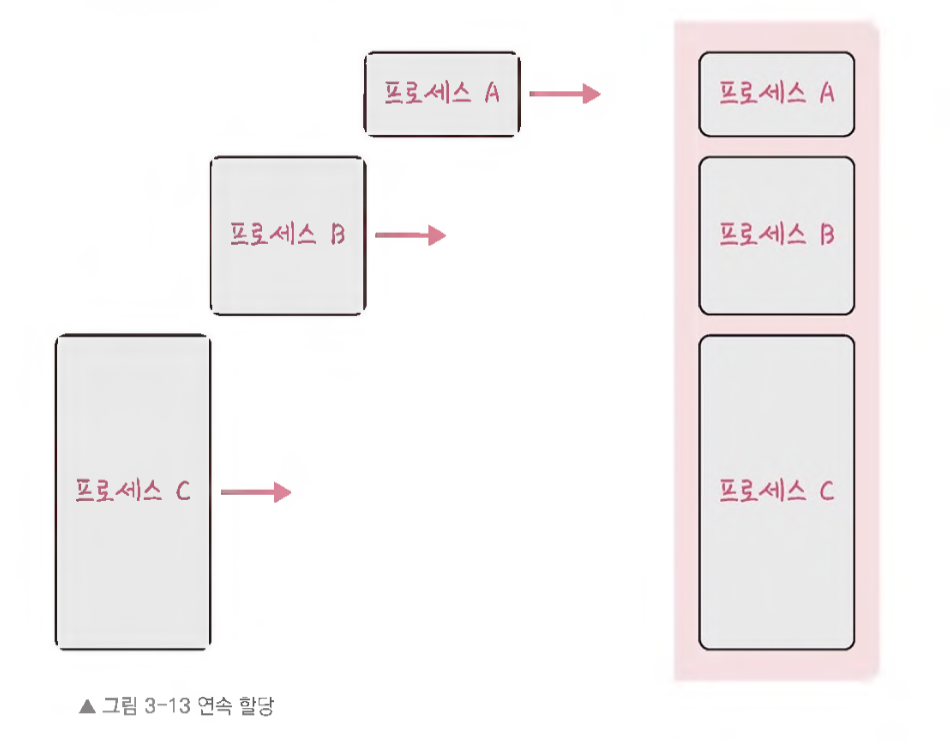
-
이와 같이 프로세스 A, 프로세스 B, 프로세스 C가 순차적으로 공간에 할당하는 것을 볼 수 있다.
-
이는 메모리를 미리 나누어 관리하는 고정 분할 방식과 매 시점 프로그램의 크기에 맞게 메모리를 분할하연 사용하는 가변 분할 방식이 있다.
고정 분할 방식 (fixed partition allocation)
-
메모리를 미리 나누어 관리하는 방식이며, 메모리가 미리 나뉘어 있기 때문에 융통성이 없다.
-
내부 단편화가 발생한다.
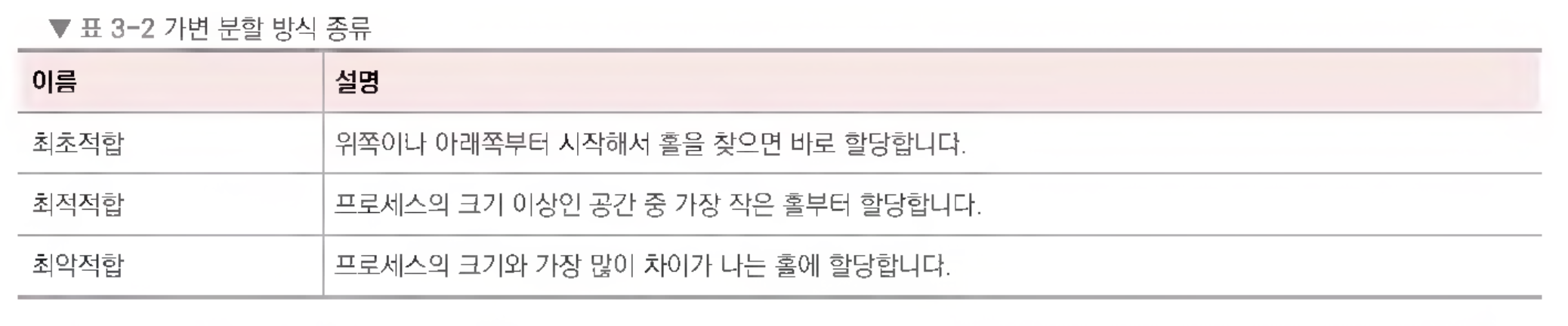
가변 분할 방식 (variable partition allocation)
-
매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용한다.
-
내부 단편화가 발생하지 않고 외부 단편화는 발생할 수 있다.
-
이는 최초적합(first fit), 최적적합(best fit), 최악적합(worst fit)이 있다.
→ 내부 단편화 (Iternal fragmentation)
: 메모리를 나눈 크기보다 프로그램이 작아서 들어가지 못하는 공간이 많이 발생하는 현상
→ 외부 단편화 (external fragmentaion)
: 메모리를 나눈 크기보다 프로그램이 커서 들어가지 못하는 공간이 많이 발생하는 현상
→ 홀 (hole)
: 할당할 수 있는 비어 있는 메모리 공간
불연속 할당
-
메모리를 연속적으로 할당하지 않는 불연속 할당은 현대 운영체제가 쓰는 방법으로 불연속 할당인 페이징 기법이 있다.
-
메모리를 동일한 크기의 페이지(4KB)로 나누고 프로그램마다 페이지 테이블을 두어 이를 통해 메모리에 프로그램을 할당하는 것
-
페이징 기법 외에 세그멘테이션, 페이지드 세그멘테이션이 있다.
-
페이징은 동일한 크기의 페이지 단위로 나누어 메모리의 서로 다른 위치에 프로세스를 할당한다. 홀의 크기가 균일하지 않은 문제가 없어지지만 주소 변환이 복잡해진다.
세그멘테이션 (segmentation)
-
페이지 단위가 아닌 의미 단위인 세그먼트로 나누는 방식이다.
-
프로세스는 코드, 데이터, 스택, 힙 등으로 이루어지는데, 코드와 데이터 등 이를 기반으로 나눌 수도 있으며 함수 단위로 나눌 수도 있음을 의미한다.
-
공유와 보안 측면에서 좋으며 홀 크기가 균일하지 않은 문제가 발생한다.
페이지드 세그멘테이션 (paged segmentaion)
- 공유나 보안을 의미 단위의 세그먼트로 나누고, 물리적 메모리는 페이지로 나누는 것을 말한다.
▶︎ 페이지 교체 알고리즘
- 메모리는 한정되어 있기 때문에 스와핑이 많이 일어난다. 스와핑이 많이 일어나지 않도록 설계되어야 하며 이는 페이지 교체 알고리즘을 기반으로 스와핑이 일어난다.
오프라인 알고리즘 (offline algorithm)
-
먼 미래에 참조되는 페이지와 현재 할당하는 페이지를 바꾸는 알고리즘이며, 가장 좋은 방법이다.
-
그러나 미래에 사용되는 프로세스를 알 수 없기 때문에 사용할 수 없는 알고리즘이다.
-
다른 알고리즘과의 성능 비교에 대한 기준을 제공한다.
FIFO (First In First Out)
- 가장 먼저 온 페이지를 교체 영역에 가장 먼저 놓는 방법을 의미한다.
LRU (Least Recentle Used)
-
참조가 가장 오래된 페이지를 바꾼다.
-
오래된 것을 파악하기 위해 각 페이지마다 계수기, 스택을 두어야 하는 문제점이 있다.
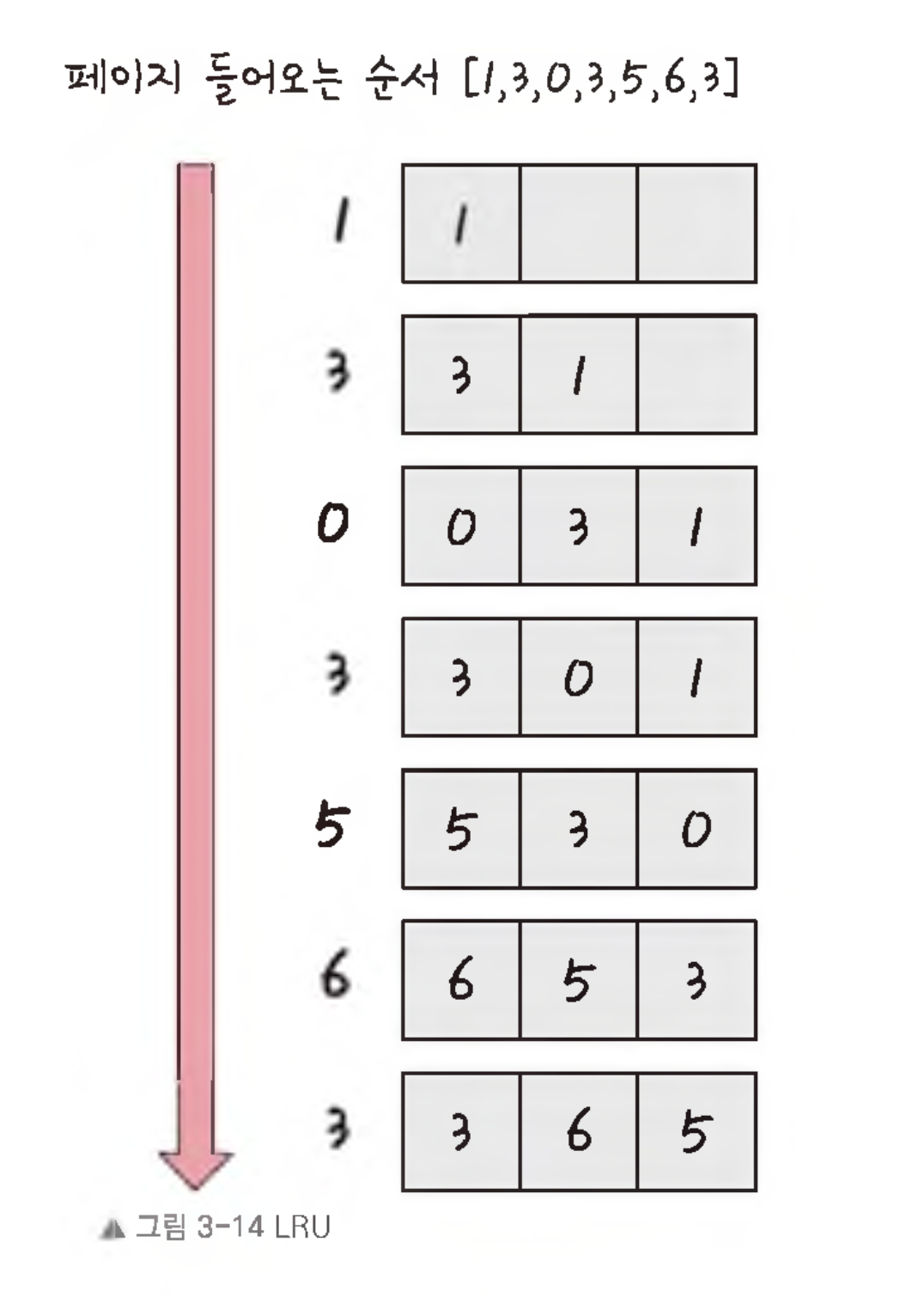
-
그림과 같이 5번째에 5번 페이지가 들어왔을 때 가장 오래된 1번 페이지와 스왑하는 것을 볼 수 있는데 이것이 바로 LRU 방식이다.
-
LRU 구현을 프로그래밍으로 구현할 때는 보통 두 개의 자료 구조로 구현한다.
-
하나는 해시 테이블로 이중 연결 리스트에서 빠르게 찾을 수 있도록 쓴다.
-
다른 하나는 이중 연결 리스트로 한정된 메모리를 나타낸다.
// C++로 LRU 구현
#include <bits/stdc++.h>
using namespace std;
class LRUCache {
list<int> li; // 이중 연결 리스트 (Linked List)는 캐시 항목의 순서를 유지합니다.
unordered_map<int, list<int>::iterator> hash; // 해시 맵은 각 항목을 찾기 위한 빠른 검색을 제공합니다.
int csize; // 캐시의 최대 크기를 나타냅니다.
public:
LRUCache(int n); // 생성자
void refer(int); // 캐시에 데이터를 참조하는 함수
void display(); // 현재 캐시 상태를 출력하는 함수
};
LRUCache::LRUCache(int n) {
csize = n; // 생성자에서 캐시 크기를 초기화합니다.
}
void LRUCache::refer(int x) {
if (hash.find(x) == hash.end()) {
if (li.size() == csize) { // 캐시가 가득 찼을 경우, 가장 오래된 항목을 제거합니다.
int last = li.back(); // 리스트의 끝에서 가장 오래된 항목을 가져옵니다.
li.pop_back(); // 리스트에서 해당 항목을 제거합니다.
hash.erase(last); // 해시 맵에서 해당 항목을 제거합니다.
}
} else {
li.erase(hash[x]); // 이미 캐시에 있는 항목이면 해당 항목을 리스트에서 제거합니다.
}
// 참조한 페이지를 캐시의 가장 앞에 추가하고, 해시 테이블에 저장합니다.
li.push_front(x);
hash[x] = li.begin();
}
void LRUCache::display() {
for (auto it = li.begin(); it != li.end(); it++) {
cout << (*it) << " "; // 현재 캐시 상태를 출력합니다.
}
cout << "\n";
}
int main() {
LRUCache ca(3); // 크기가 3인 LRU 캐시를 생성합니다.
ca.refer(1); // 1을 참조하면, 캐시에 [1]이 저장됨
ca.display(); // 출력: 1
ca.refer(3); // 3을 참조하면, 캐시에 [3, 1]이 저장됨
ca.display(); // 출력: 3 1
ca.refer(0); // 0을 참조하면, 캐시가 가득 차서 가장 오래된 1을 제거하고 [0, 3]이 저장됨
ca.display(); // 출력: 0 3
ca.refer(3); // 3을 다시 참조하면, 캐시에서 3을 가장 앞으로 옮김
ca.display(); // 출력: 3 0
ca.refer(5); // 5를 참조하면, 캐시가 가득 차서 가장 오래된 0을 제거하고 [5, 3]이 저장됨
ca.display(); // 출력: 5 3
ca.refer(6); // 6을 참조하면, 캐시가 가득 차서 가장 오래된 3을 제거하고 [6, 5]이 저장됨
ca.display(); // 출력: 6 5
ca.refer(3); // 3을 다시 참조하면, 캐시에서 3을 가장 앞으로 옮김
ca.display(); // 출력: 3 6 5
return 0;
}
/*
1
3 1
0 3
3 0
5 3
6 5
3 6 5
*/NUR
- LRU에서 발전한 NUR(Not Used Recently) 알고리즘이 있다.
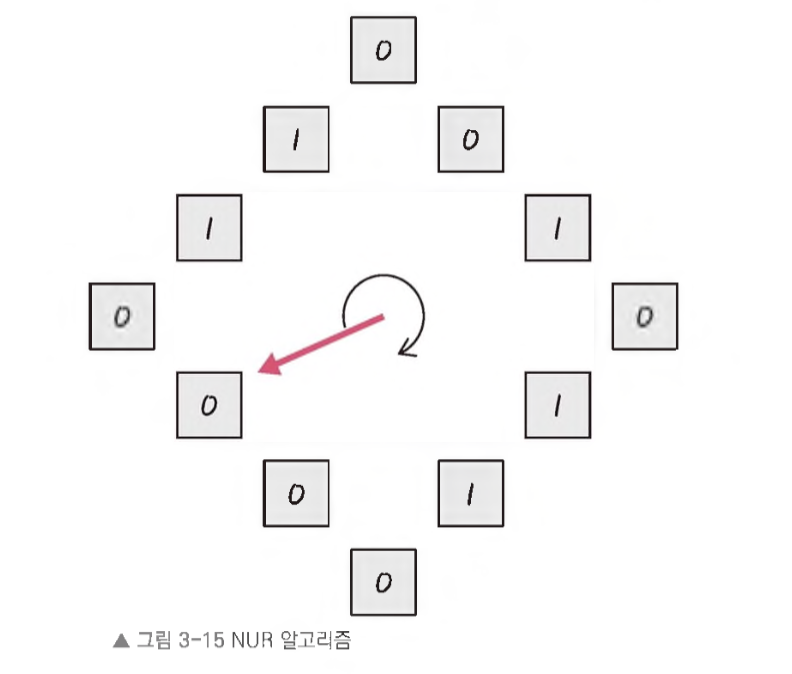
-
일명 clock 알고리즘이라고 하며 먼저 0과 1을 가진 비트를 둔다. 1은 최근에 참조되었고 0은 참조되지 않음을 의미한다.
-
시계 방향으로 돌면서 0을 찾고 0을 찾은 순간 해당 프로세스를 교체하고, 해당 부분을 1로 바꾸는 알고리즘이다.
LFU (Least Frequently Used)
-
가장 참조 횟수가 적은 페이지를 교체한다.
-
즉, 많이 사용하지 않은 것을 교체하는 것이다.
