
공통 세션으로 진행된 데이터베이스에 대한 전반적인 개념과
ERD를 통해 스타벅스 홈페이지 모델링을 간략하게 팀으로 진행해보았다.
모델링을 하다보니 개념이 좀 어려웠지만,
하나하나 연결되어 있다는 점이 신기하게 느껴졌다! 🙂
복습하며 세부 개념들을 다시 한 번 익혀보자!
1. 데이터베이스란?
-
데이터 : 숫자 ,단어, 이미지, 영상 등의 형태로 된 의미단위
-
데이터베이스 : 컴퓨터 시스템에 저장된 정보나 데이터 등을 모두 모아놓은 집합
우리에게 필요한 데이터를 가득 모아놓은 베이스!
Database Management System 으로 제어, 관리한다.데이터베이스를 사용하는 이유?
-
데이터를 오랜기간 저장, 보존하기 위해
(필요한 자료를 계속 보존_메모리에 보존하면 오래 보존되지 않음) -
데이터를 체계적으로 보존하고 관리하기 위해
(원하는 자료를 쉽게 읽어낼 수 있어야 의미가 있는 정보).- 데이터 파이프라인 시스템 :
사내 db 및 파일 시스템, 외부 db, api등에서 다양한 데이터를 적절히 처리하여
에어비앤비 서비스를 위한 데이터 허브에 저장하는 일련의 데이터 흐름
data source (extract - transform - load) => data warehouse
- 데이터 파이프라인 시스템 :
2. 관계형 데이터베이스 (RDBMS -
relational database management system)
- 관계형 데이터 모델에 기초를 둔 데이터베이스 시스템.
- 모든 데이터는 2차원 테이블로 표현할 수 있음
- column(열) 테이블의 각 항목 , row (행) : 실제 값
- 테이블의 각 row는 저만의 고유키가 있다. (primary key)
각 row는 다른 row와 겹치지 않는 하나의 데이터만 지칭할 수 있는 고유키를 가지고 있다.
primary key를 통해 특정 로우를 찾거나 인용할 수 있음. - 관계형 데이터베이스란 : 테이블들이 서로 상호 관련성을 가지고 연결되어 있다는 의미
각각의 테이블들이 완전히 독립적이지 않고 서로 연관된 사이
2-1. 관계 유형
- 일대일(One to One):
하나의 A 테이블데이터는 오로지 하나의 B테이블 데이터로 연결된다.
foreign key : 외래키. 테이블간의 관계를 연결지을 때 사용함. 참조하는 컬럼은 pk값(primary key)

: User 테이블에 id를 넣어 각각의 이름을 부여하고,
Identification numbers 테이블의 주민번호와 id를 통해 연결시킨다.
해당내용을 도식화해서 표현하면?
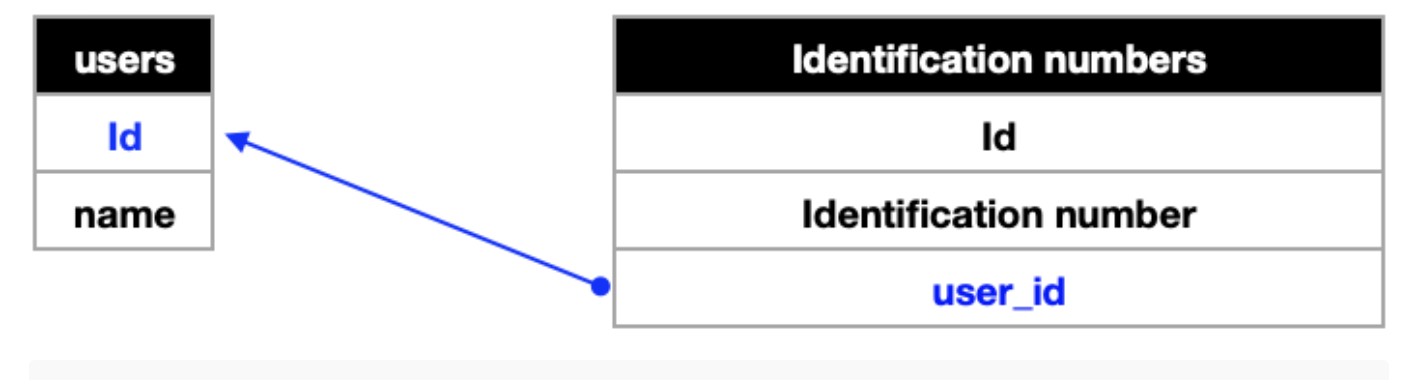
- 일대다 (One to Many):
하나의 A 테이블의 데이터는 B테이블의 여러 데이터와 연결됨
ex)
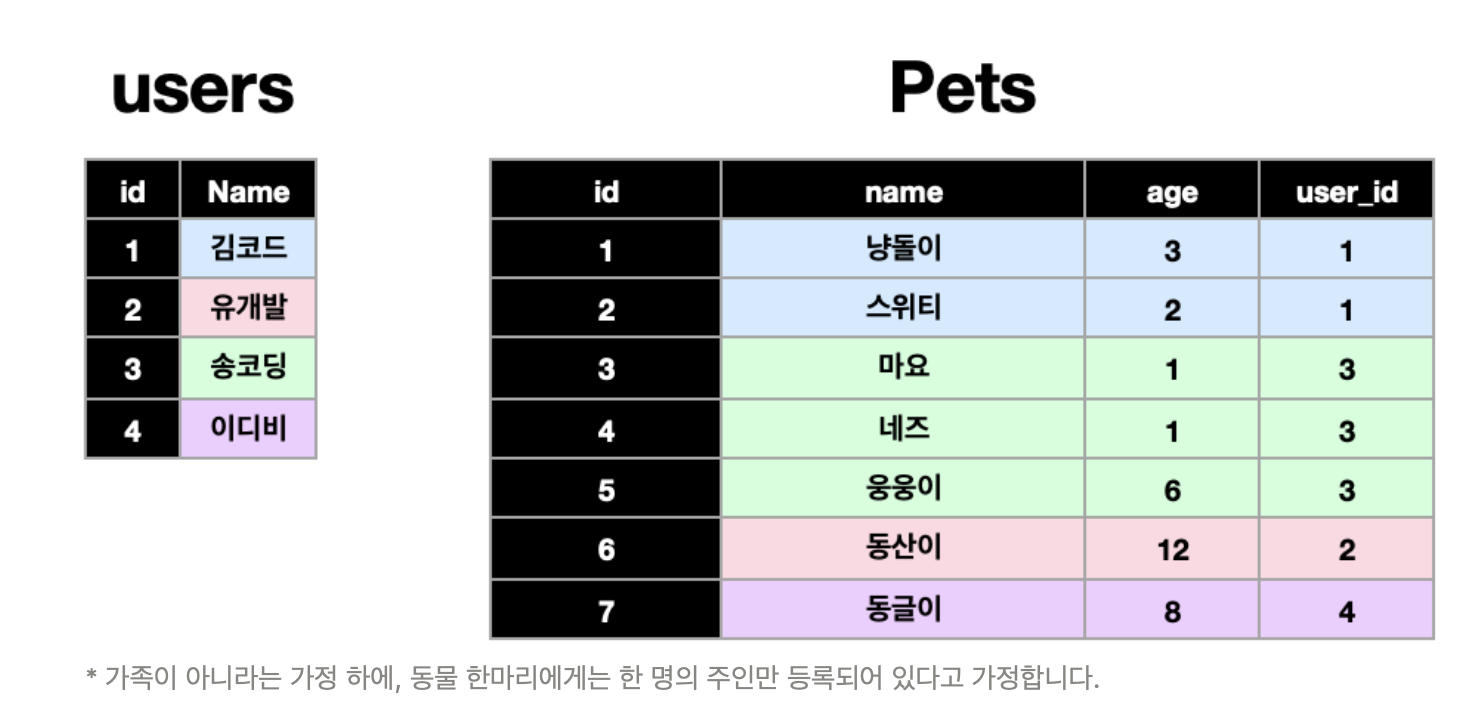
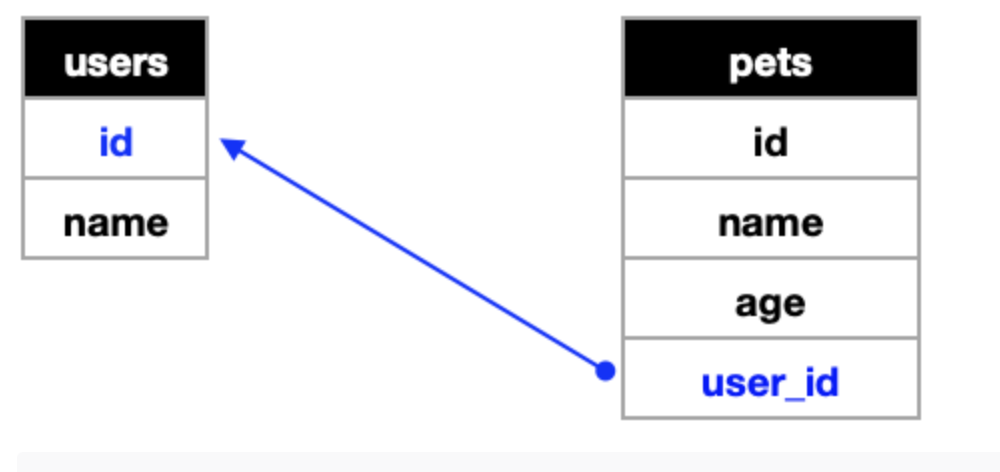
: user id 를 통해 강아지의 주인을 찾을 수 있고,
이 user table의 id 값은 여러 row에 적용되므로 일대다 관계이다!
☑️ pet table의 user column은 user table의 id를 참조한다.
- 다대다 (Many to Many):
하나의 A 테이블 데이터는 B 테이블의 여러 데이터와 연결될 수 있음.
- 정규화 작업을 거침
- 컬럼의 데이터가 중복되어 여러 열이 됨.
-서로 다른 테이블의 여러데이터와 연결될 때는 두 테이블에 속한 데이터의 조합을 입력하기 위한
중간 테이블이 생성됨! - 테이블의 행 하나에는 딱 하나의 데이터만 들어가야한다.
ex)
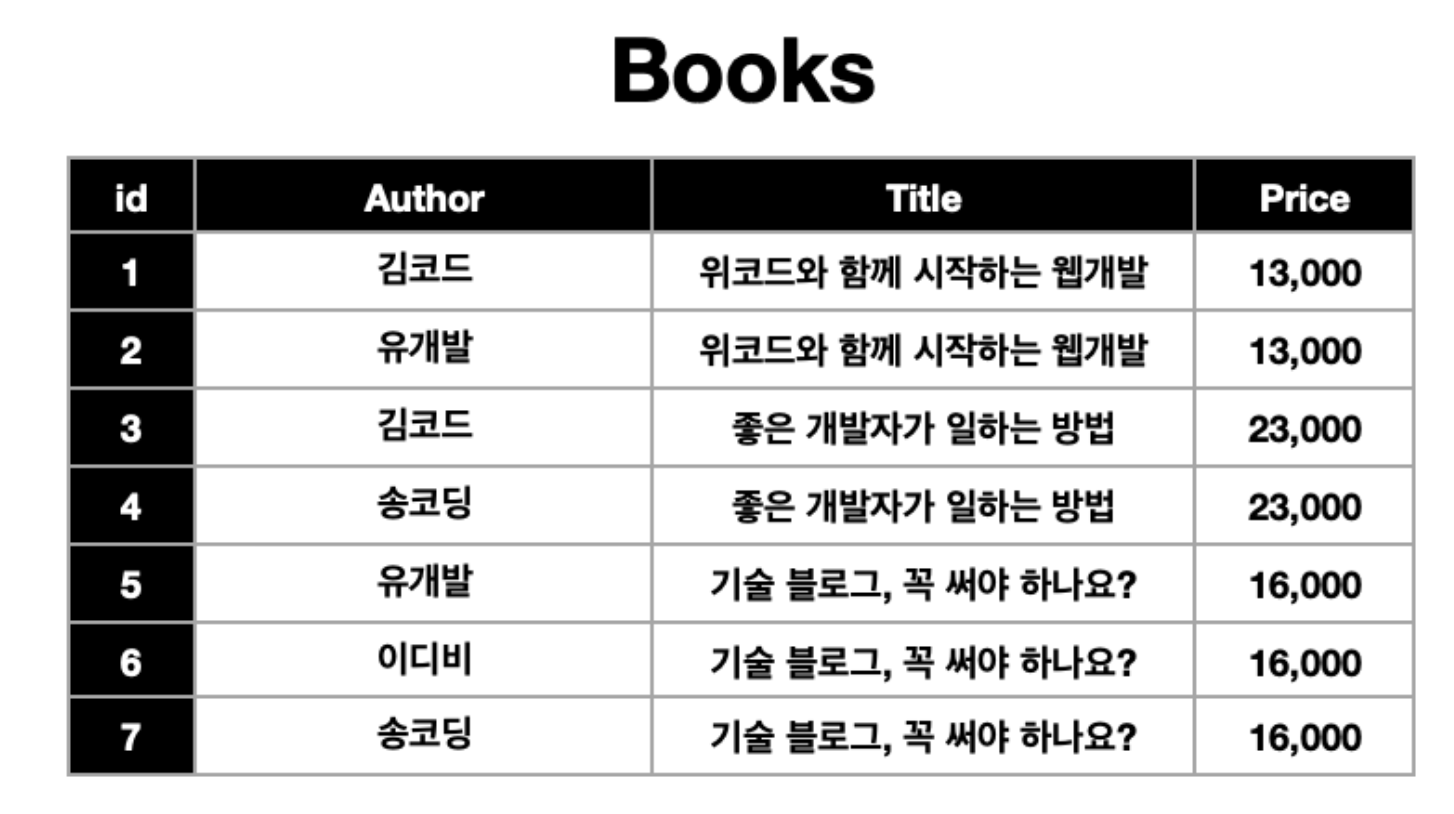 ☑️ 문제점
☑️ 문제점- 똑같은 데이터가 너무 많다. (author, title, price)
: 책 한권이 늘어날 때 마다 작가의 수에 맞춰 똑같은 데이터를 여러번 저장해주어야 하는 문제가 발생
=>foreign key를 통해 문제 해결!
foreign key는 중복된 데이터를 획기적으로 줄여준다!
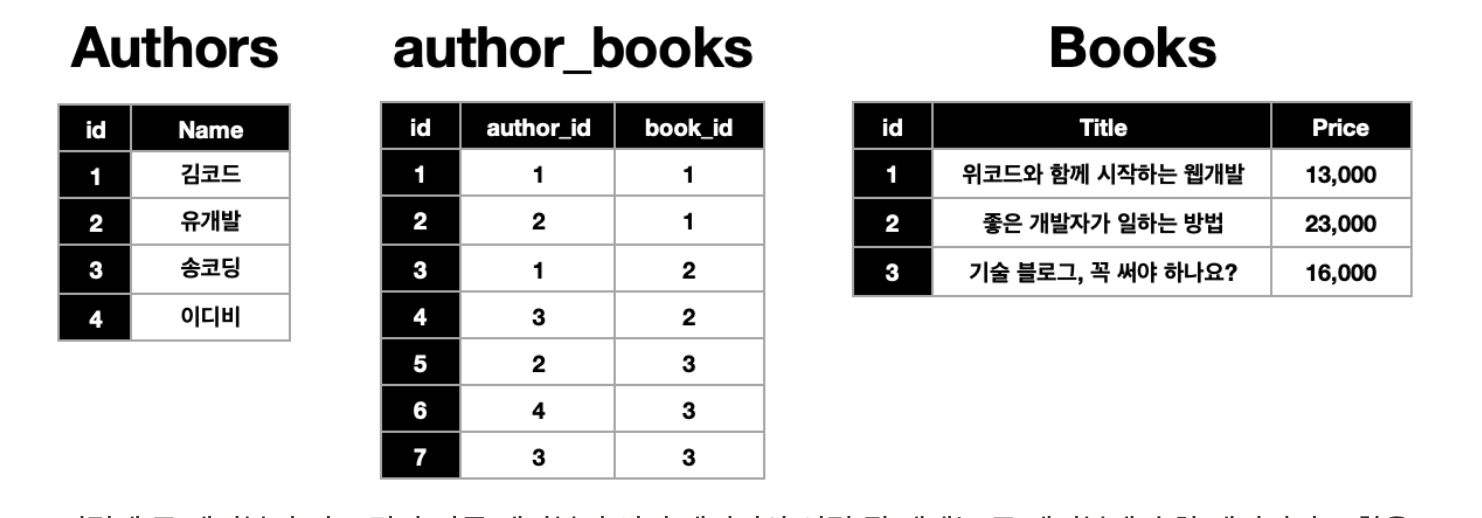
- 똑같은 데이터가 너무 많다. (author, title, price)
- 중간 테이블을 도식화해서 표현하면?

3. 테이블과 테이블 연결하기
-
foreign key를 통해 연결한다! -
one to one 예에서 user_profiles table의 user_id column은 user table에 걸려있는 외부키라 지정한다.
즉, 데이터베이스에게 유저 아이디값은 유저 테이블의 아이디 값이며, 유저 테이블의 id 칼럼에 존재하는 값만 생성할 수 있다. -
user table에 없는 id 값이 user_id에 지정되면 에러가 발생한다.
테이블을 왜 연결하는가?
-
테이블 하나에 모든 정보를 넣으면 동일한 정보들이 불필요하게 중복되어 저장됨.
더 많은 디스크를 차지하며, 잘못된 데이터가 저장될 가능성이 높아짐 -
여러 테이블에 나누어 저장한 후 필요한 테이블끼리 연결시키면 문제가 사라진다!
서로 같은 데이터지만 부분적으로만 내용이 다른 데이터가 생기는 문제가 없어짐
=> Normalization (정규화)
4. ERD 기본 사용법
-
모델링 이전 엑셀을 활용해 대략적인 그림을 그리고 시작하면 수월하다 🙂
-
데이터베이스 타입 : Mysql
-
테이블 상단 : 테이블 이름 기재해줌!
실제 테이블엔 엑셀에서 미리 구현해놓은 테이블의 column이 name으로 들어감✅ Type
- INTI : 정수형 데이터
- VARCHAR : 캐릭터 데이터 저장할 때 사용하는 타입
(비밀번호와 같이 데이터가 많이 들어갈 수 있는 항목에는 글자수 제한을 늘려줄 수 있음) - PK : Primary Key
- AI : Auto Increment. 데이터가 생길 때마다 자동으로 증가하는 값에만 체크.
보통 ID에 체크!! - Null : 해당 Column에 빈 값을 허용하는가? 허용하면 체크
- Tinyint : 0 또는 1값 (True - False를 대신해 사용)
- FK : Foreign key. 마우스를 갖다대고 쭉 끌어 참조하고 있는 Column으로
가져가 연결해주어야 함 - Logical Name : Column의 닉네임
- Demical ( 총 숫자 갯수, 소수점 갯수 )
5. 스타벅스 모델링 팀과제 수행하기
✔️ 최종 제출 과제
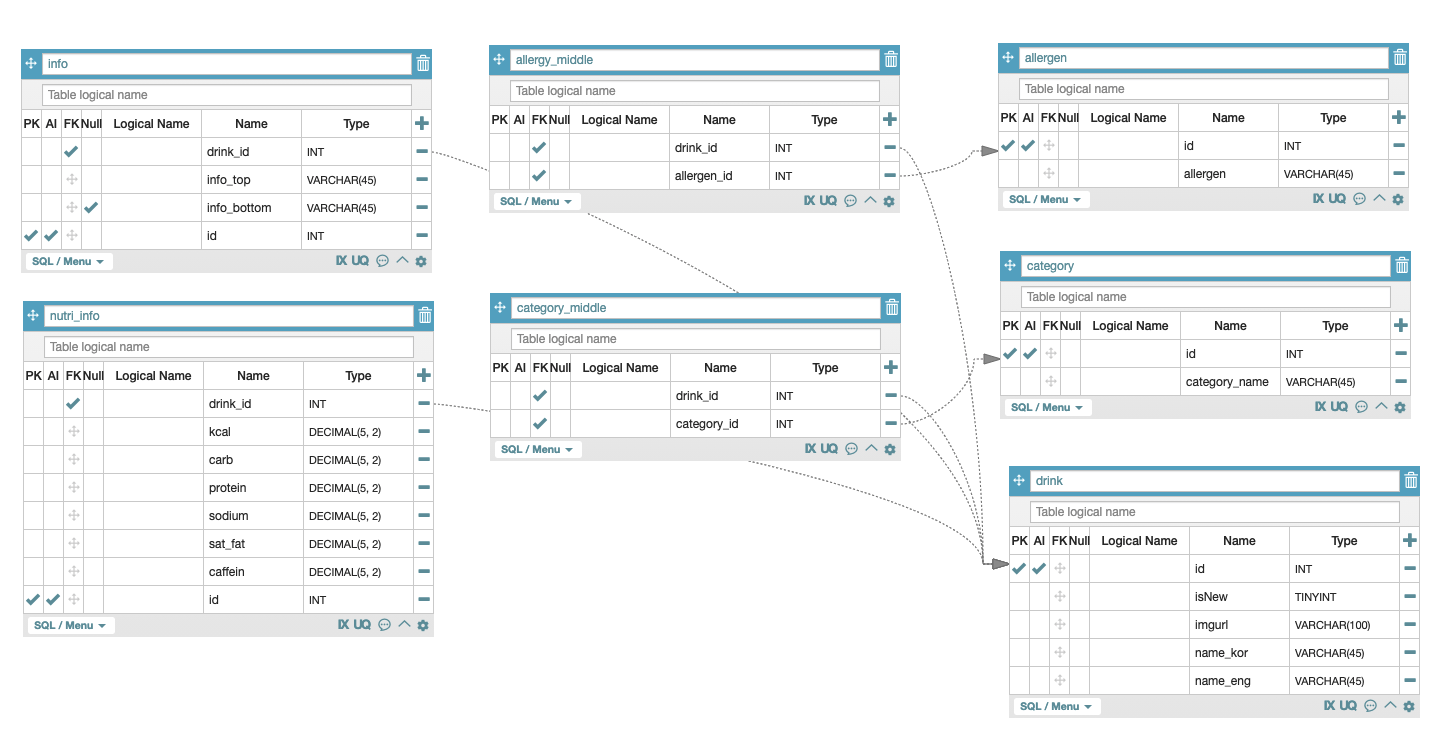
✔️ 멘토님 작성 모델링
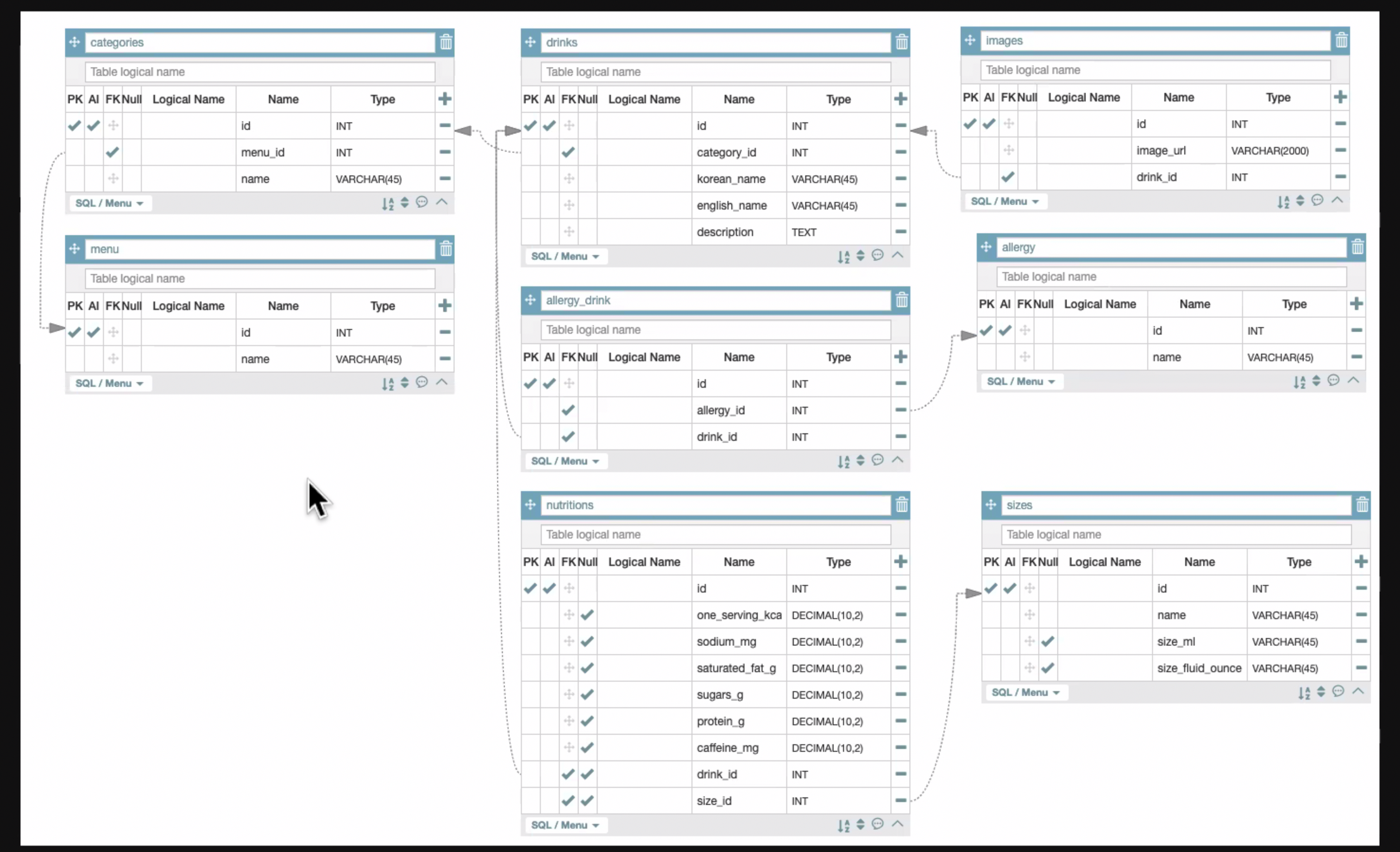
5-1. 모델링 관련 배운 내용
-
모델링 : 최상위부터 계층을 나누고 테이블을 세팅하는 것이 좋다!
관계를 이해하고 맞춰 데이터를 표현해야 한다. 관계형 데이터베이스임! -
큰 카테고리로부터 - 작은 카테고리 - 데이터 계층 구조를 보며 모델링하기
카테고리 정하고 - 서브카테고리 만들면 메뉴와 카테고리 테이블이 됨 -
엑셀표로 미리 도식화하며 진행하면 좋다!


-
Menu table에 저장되는 데이터 :
음료 푸드 상품 카드 메뉴이야기 (최상위 카테고리) -
Menu table : id 값, 메뉴이름
-
최상위 카테고리를 테이블로 만든다.
-
테이블의 이름은 복수형으로 짓는다. (아이디이름은 아님!)
-
카테고리 테이블 데이터들이 메뉴테이블과 관계를 맺으려면
foreign key를 사용해야함. foreign key를 만들 때는 id로! -
메뉴가 1 나머지들이 다 2 (일대다 관계)
-
drinks 테이블 세부에 내용들을 저장해줌. 자식테이블이므로 카테고리 아이디를 보유.
:카테고리가 1, 음료들이 다. 일대다테이블이 됨.
(콜드브루 - 나이트로 콜드브루, 돌체, 바크콜 등)
ex)
콜드브루 커피 세부내역 (나이트로 콜드브루 등등)의 카테고리 아이디는 1이다.
콜드브루가 가장 상단이므로 블랜디드 (5번), 에스프레소 (2번) 등등등 카테고리 테이블을 참고해서 작성 -
나머지 데이터들을 저장할 테이블들도 만들어주자!
-
이미지 테이블도 별도의 테이블로 분류해주는 것이 좋음.
drink 테이블과 1대 다로 만들어주자
데이터가 늘어날 수 있기에 분류해서 관리하는 것이 좋음
drink_id를 따서 넣어주어야함.
이미지의 url은 개발자도구 - 네트워크 - 태그 확인해서 추출가능 -
Nutrition table은 drink table과 사이즈를 고려하지 않으면 일대일 관계.
사이즈를 고려하면 일대다 테이블로 셋팅하는 것이 좋음! drink id로 연결해주기 -
하나의 알러지가 여러 음료수로 래핑될 수 있고, 하나의 음료수도 여러 일러지와 래핑될 수 있다.
Many To Many다대다 관계! -
drink table과 알러지 테이블의 중간테이블을 만들어 연결시켜줌. id를 통해!
-
신상을 표시할 때는 boolean 타입으로 0,1 으로 표현하는 것이 좋음.
boolean이 없으니,TINYINT로! -
null 값으로 넣으면 신상품에 하나하나 이름을 입력해야하는데,
오타가나면 관리가 쉽지 않고 데이터가 무거워짐 -
pk는 수정없이 사용하게 되는 키이므로 따로 관리해주는 것이 좋다
🔥 느낀 점
처음 세션 시간엔 내용을 이해하기에 급급했고,
팀 과제 시간엔 팀원들의 집단지성에 힘입어 과제를 완성했다.
(좋은 팀원분들을 만나 뚝딱뚝딱 완성할 수 있어서 다행이고 감사했다..)
영상 강의 남았던 부분을 다시 듣고, 세션을 들으며 조금씩 이해가 갔고
아직은 어렵지만 Aquery Tool을 익혀 여러 사이트를 모델링해보면 실력도 늘고
재미가 있겠다는 생각이 들었다. 🙂
우리 팀이 작성한 과제와 멘토님 과제를 다시 살펴보며 개선할 수 있는 사항이 뭐가 있는지
체크해보고 진행해봐야겠다! 차근차근, 복습해보자!
.jpg)