네트워크란
-
노드들이 데이터를 공유할 수 있게 하는 디지털 전기 통신망의 하나이다.
-
즉 분산되어 있는 컴퓨터를 통신망으로 연결한 것을 말한다.
-
네트워크에서 여러 장치들은 노드 간 연결을 사용하여 서로에게 데이터를 교환한다.
-
노드 : 네트워크에 속한 컴퓨터 또는 통신 장비를 뜻하는 말
네트워크 분류
1. 개인 영역 네트워크 (PAN)
- 비교적 작은 지리적 범위 내에서 개인적인 기기 간에 통신 및 데이터 공유를 위한 네트워크 형태를 말한다.
- 각종 블루투스, NFC와 같은 기술들을 활용하여 형성된다. 이러한 기술을 이용하여 스마트폰, 노트북, 태블릿, 헤드셋 등의 기기들이 서로 연결되어 데이터를 공유하거나 서비스를 이용할 수 있다.
2. 근거리 네트워크 (LAN)
- 가까운 거리에 위치한 비교적 소규모의 네트워크를 말한다.
- 사무실, 가정 등과 같이 지리적으로 제한된 공간에서 네트워크로 연결한 것을 말한다.
3. 도시 지역 네트워크 (MAN)
- LAN보다는 큰 규모를 가지지만 WAN보다는 지리적으로 작은 규모의 네트워크를 말한다.
- DSL 전화망, 케이블 TV 네트워크를 통한 인터넷 서비스 제공이 대표적인 예이다.
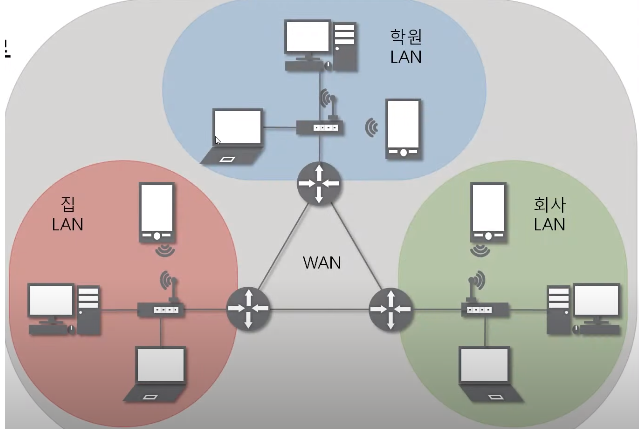
4. 광역 네트워크 (WAN)
- 두 개 이상의 근거리 네트워크 지역(LAN)에 걸쳐 연결하는 것을 말한다.
- 인터넷 서비스 제공자(ISP)로부터 제공받은 회선을 이용해 네트워크를 구축할 수 있다.
네트워크 토폴로지
- 네트워크의 요소들을 물리적으로 연결해 놓은 것 또는 연결 방식을 의미한다.
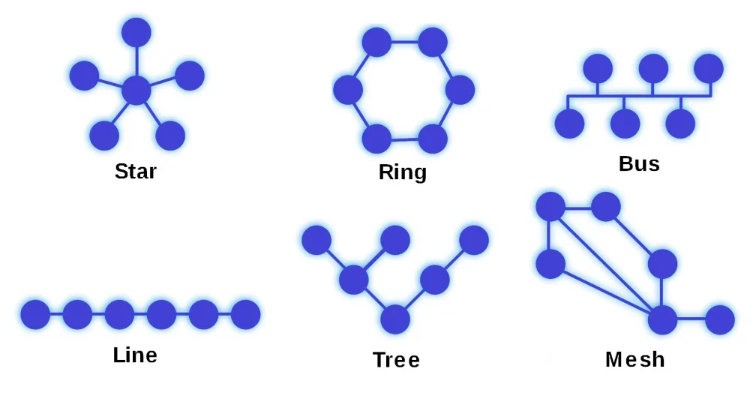
1. 버스형
특징
- 네트워크 상의 모든 장치가 하나의 케이블로 연결되어 있다.
- 케이블에 연결되어 있는 하나의 노드가 전송하면 그것이 브로드캐스트 되어 다른 모든 노드가 수신할 수 있다.
장점
- 설치가 간단하고 케이블 비용이 적게 든다.
단점
- 케이블에 장애가 발생하면 전체 네트워크가 멈추게 되며, 복구하는데 시간과 비용이 많이 든다.
- 데이터를 동시에 양방향으로 보낼 수 없다.
2. 스타형
특징
- 네트워크 중앙에 위차한 노드가 모든 노드를 연결한다.
장점
- 각각의 노드는 중앙 허브왕 연결되어 있어서 노드 하나에 장애가 발생하더라도 나머지 네트워크는 여향을 받지 않는다.
- 중앙 노드만이 다른 노드와의 통신을 제어하므로 데이터 충돌을 방지할 수 있다.
단점
- 중앙 노드에 문제가 생기면 전체 네트워크가 마비된다.
- 최초로 네트워크를 구성할 때 소요되는 비용과 노력이 든다.
3. 트리형
특징
- 부모-자식 계층 구조로 연결되어 있어서 계층적인 네트워크에 적합하다.
장점
- 확장이 용이하며, 관리나 네트워크 확장이 쉽다.
- 여러 컴퓨터를 분리하거나 우선순위를 부여할 수 있다.
단점
- 중앙에 트래픽이 집중되어 병목현상이 발생할 수 있다.
- 중앙의 장치에 문제가 생기면 전체 네트워크에 장애가 발생한다.
4. 메쉬형
특징
- 중앙에서 제어하는 장치 없이 모든 노드가 점 대 점으로 상호 연결한 구조이다.
- n(n-1)/2개의 물리적 채널이 필요하다.
장점
- 모든 메시지를 전용선으로 보내기 때문에 원하는 수신자만 받을 수 있다. 따라서 보안에 유리하다.
- 특정 노드의 장애가 발생하더라도 전체 시스템에 영향을 주지 않는다. 일부 회선에 장애가 발생하면 다른 경로를 통하여 데이터를 전송하면 된다.
단점
-
구성이 복잡하고 많은 케이블이 필요하다.
-
새로운 노드 투가시 비용부담이 발생한다.
5. 링형
특징
- 좌우의 인접한 노드와 연결되어 잇는 단 반향 전송 형태이다.
- 한번에 하나의 컴퓨터에 데이터를 전송하기 때문에 충돌이 발생하지 않는다.
장점
- 구조가 단순하여 설치와 재구성이 쉽고, 장애가 발생해도 복구 시간이 빠르다.
- 각 노드는 바로 이웃하는 장치에만 연결되어 있고, 장치를 추가하거나 삭제할 때 연결선 두 개만 움직이면 된다.
단점
- 하나의 노드에 문제가 발생하면 전체 네트워크를 사용할 수 없다.
- 노드를 재설정하거나 추가 또는 제거하기 위해서는 절차가 복잡하고, 전체 네트워크를 중단해야 된다.
네트워크 통신방식
1. 유니캐스트
- 서버와 클라이언트 간의 일대일(1:1) 통신방식을 말한다.
- 데이터는 목적지 주소를 가진 단일 수신자에게 보내진다.
- 자신의 MAC 주소와 목적지 MAC 주소가 동일하다면 전송된 데이터를 수신하고, 일치하지 않으면 해당 프레임은 버린다.
- 웹 브라우징, 이메일 전송 등에 사용된다.

2. 멀티캐스트
- 그룹 내의 여러 수신자에게 동시에 데이터를 전송하는 방식이다.
- 유니캐스트 처럼 반복해서 보낼 필요가 없고, 브로드캐스트와 같이 전송받을 필요가 없는 노드에 보내지 않아도 된다.
-IPTV, 온라인 동영상 스트리밍 등에 사용된다.

3. 브로드캐스트
- 서버와 클라이언트 간의 일대 모두(1:모두)로 통신방식을 말한다.
- 브로드캐스트 주소는 FF-FF-FF-FF-FF-FF 로 미리 정해져 있다.
- 불특정 다수에게 전송되는 서비스라서 수신을 원치 않는 노드도 수신하게 되므로 네트워크 성능이 저하를 가져올 수 있다.

4. 애니캐스트
- 여러 개의 대상 중에 가장 가까운 대상하고 데이터를 전송하는 방식이다.
- 유니캐스트는 출발지와 목적지가 모두 하나이지만 애니캐스트는 같은 목적지 주소를 가진 서버가 여러 대여서 통신 가능한 다수의 후보군이 있다.

프로토콜
- 컴퓨터 및 네트워크 간에 통신하기 위해 정의된 규칙과 규약의 집합이다.
OSI 모델, TCP/IP 모델
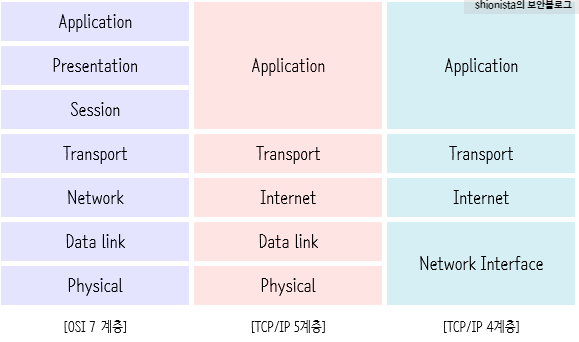
1. OSI 7 Layer 모델
- OSI 모델은 표준 프로토콜을 사용하여 다양한 통신 시스템이 통신할 수 있도록 국제표준화기구에서 만든 개념 모델이다.
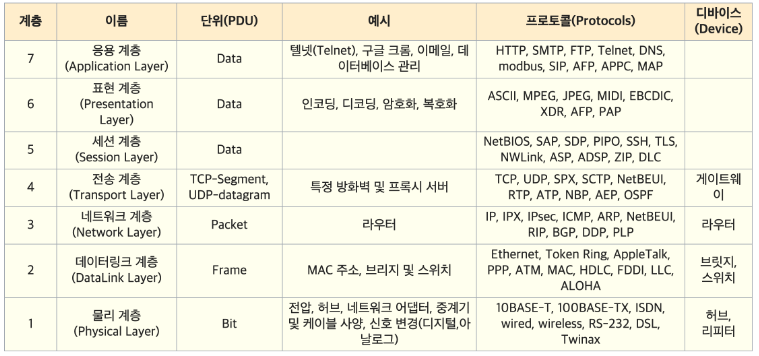
1-1. 물리 계층
- 네트워크에서 데이터를 전기 신호 또는 광신호로 변환하여 전송하는 역할을 담당한다.
1-2. 데이터 링크 계층
- 물리 계층에서 받은 정보를 잘못된 정보 없이 안정라게 전달하는 역할을 한다.
- 데이터의 프레임화, 물리 주소(MAC 주소)를 이용한 통신, 오류 검출 등의 기능을 수행한다.
1-3. 네트워크 계층
- 데이터 패킷의 전송 경로를 결정하는 역할을 한다.
- 주요 프로토콜로는 IP가 있으며, 패킷의 출발지와 목적지를 식별하게 해준다.
- 네트워크 내의 여러 라우터를 통한 패킷의 경로를 관리 및 패킷 손실, 중복, 지연 등의 문제를 처리한다.
A. IP
- 네트워크 계층에서 프로토콜로, 두 장치 간의 패킷 전송을 담당한다.
- IP는 네트워크상에서 컴퓨터(노드)를 식별하기 위해 부여된 위치주소다.
- IP는 네트워크 주소와 호스트 주소로 구분되며 하나의 네트워크 상에 여러 호스트 주소가 있을 수 있다.
- IP는 32비트 2진수로 표현이 가능하며 2^32개가 IP가 가질 수 있는 최대 갯수이다.
- IP의 각 자릿수(8비트 2진수 혹은 10진수 3자리)를 옥텟이라 부르며 dot(.)으로 구분한다.
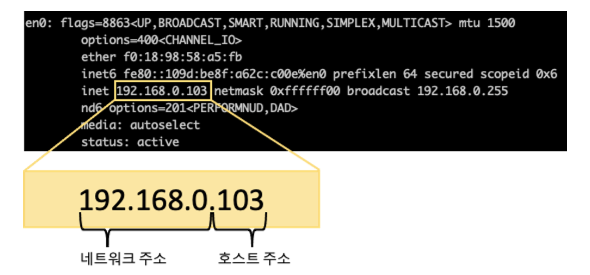
B. IPv4

IPv4는 3자리 숫자가 4마디로 표기되는 방식이다. 각 마디는 옥텟(octet)이라고 부른다. 위 주소는 내부적으로 32비트, 각 마디당 8bit로 처리된다. 예를 들어 192.168.123.123은 11000000.10101000.1111011.1111011으로 표시된다.
B-1. IPv4 클래스
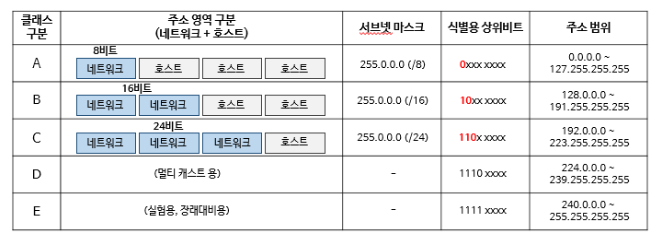
- Class A
-
하나의 네트워크가 가질 수 잇는 호스트 수가 가장 많은 클래스
-
IP주소를 바이너리로 표시할 때 맨 앞자리수가 항상 0인 경우
0xxx xxxx. xxxx xxxx. xxxx xxxx. xxxx xxxx
-
0.0.0.0 ~ 127.255.255.255 까지 를 A클래스라 한다.
-
네트워크 주소는 1.0.0.0과 126.0.0.0까지로 규정되어 있다.
-
호스트 갯수는 2^24 - 2
- Class B
-
IP주소를 바이너리로 표시할 때 맨 앞자리수가 항상 10인 경우
10xx xxxx. xxxx xxxx. xxxx xxxx. xxxx xxxx
-
128.0.0.0 ~ 191.255.255.255까지를 B클래스라 한다.
-
네트워크 범위는 10xx xxxx. xxxx xxxx 에서 x가 가질 수 있는 경우의 수이다(2 ^ 14)개
-
호스트 범위는 뒤의 xxxx xxxx. xxxx xxxx 에서 x가 가질 수 있는 경우의 수이다.(2 ^ 16) -2개
⇒ 네트워크 및 브로드캐스트 주소사용으로 2개를 호스트 주소에서 제외해야 한다.
- class C
-
IP주소를 바이너리로 표시할 때 맨 앞자리 수가 항상 110으로시작한다.
110x xxxx. xxxx xxxx. xxxx xxxx. xxxx xxxx
-
192.0.0.0 ~ 223.255.255.255 까지를 C클래스라 한다.
-
네트워크 범위는 110x xxxx.xxxx xxxx.xxxx xxxx 에서 x가 가질 수 있는 경우의 수이다(2 ^ 21)개
-
호스트 범위는 뒤의 xxxx xxxx 에서 x가 가질 수 있는 경우의 수이다.(2 ^ 8) -2개
⇒ 네트워크및 브로드캐스트 주소사용으로 2개를 호스트 주소에서 제외해야 한다.
C. IPv6
- IPv4는 32bit의 이진수로 이루어져있지만, IPv6 주소체계는 총 128bit로 각 16bit씩 8자리로 각 자리는 :(콜론)으로 구분하고 있다.
C-1. IPv6 개념 및 특징
- IP주소의 부족 현상을 해결하기 위한 차세대 IP주소체계
- IPv4의 주소 공간을 4배 확장한 것으로 128bit 체계의 16진수로 표기하며, 4개의 16진수를 콜론(:)으로 구분
- IPv4에서는 옵션 필드의 구성이 제한적인데 비해 IPv6에서는 확장헤더를 이용하여 IPv4보다 훨씬 다양하고 안정된 옵션을 사용할 수 있음
- 라우터의 부담을 줄이고, 네트워크 부하를 분산시킴
- 보안, 인증, 라벨링, 데이터 무결성, 데이터 비밀성 제공
- 특정 흐름의 패킷들을 인식하고, 확장된 헤더에 선택사항들을 기술할 수 있음
- IPv6 종류: 유니캐스트, 애니 캐스트, 멀티 캐스트
C-2. IPv4와 IPv6의 주요 차이점
-
보안강화
IPv6는 보안을 염두에 두고 구축되었기에 기밀성, 인증 및 데이터 무결성을 제공. IPv4 구성 요소인 인터넷 제어 메시지 프로토콜(ICMP)은 맬웨어를 전달할 가능성이 있으므로 회사 방화벽에서 이를 종종 차단한다. 반면 IPv6 ICMP 패킷은 IPSec를 사용해 훨씬 더 안전하고 손쉽게 이를 막을 수 있다. -
지리적 제한 없음
IPv4 주소와 달리 IPv6 주소는 전 세계 어느 곳에서도 사용할 수 있다. IPv4 주소의 50%는 생성될 때 미국에서 사용하는 용도로 예약되었다. -
보다 효율적인 라우팅
IPv4 헤더는 길이가 가변적이지만 IPv6에는 일관된 헤더가 있다. 즉, 이러한 주소로 라우팅하기 위한 코드가 더 간단해지고 하드웨어 처리도 덜 필요하다. 이는 결과적으로 IPv6는 더 나은 서비스 품질과 사용자 경험을 갖게 되는 것을 뜻한다. -
끝과 끝 연결
기술자들은 IP 주소 부족을 해결하기 위해 네트워크 주소 변환(NAT) 방법을 만들었다. 하지만 IPv6는 모든 장치에 대해 충분한 IP 주소를 생성하므로 NAT가 더 이상 필요하지 않게 되었다. 이제 각 장치가 인터넷에 연결되어 웹사이트와 직접 통신할 수 있게 되었다. -
자동 구성
IPv6의 가장 좋은 기능 중 하나는 상태 비상태 유지 자동 저장 구성일 것이라고 한다. 이를 통해 장치는 서버 없이도 자체 IP주소를 할당할 수 있다. 대신 사용자가 소유한 모든 휴대폰, 태블릿 또는 노트북에 고유한 장치의 MAC 주소를 사용하여 IP주소가 생성된다. 이렇게 하면 동일한 네트워크에 연결된 장치가 서로를 더 쉽게 검색할 수 있다
D. 네트워크 주소와 브로드캐스트 주소란?
- IP 주소에는 네트워크 주소와 브로드캐스트 주소가 있는데, 이 두 주소는 컴퓨터나 라우터가 자신의 IP로 사용하면 안 되는 주소이다.
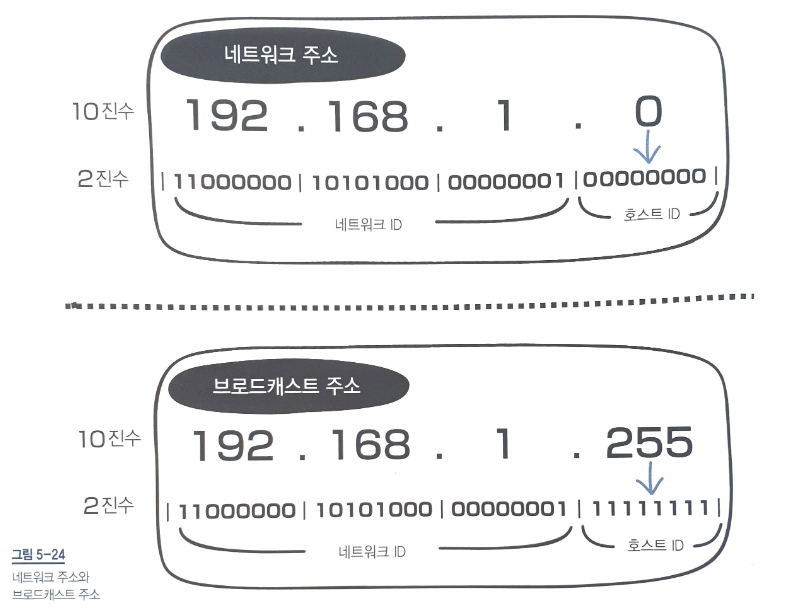
호스트 ID가 10진수고 첫 번째 숫자가 0이면 네트워크 주소
호스트 ID가 10진수고 마지막 숫자가 255면 브로드캐스트 주소
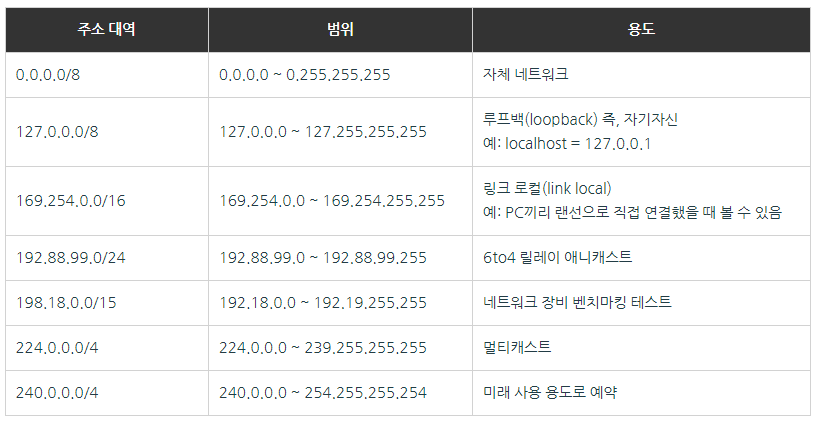
E. 특수 네트워크 대역
F. 서브넷이란?
- A 클래스 네트워크는 호스트 ID가 24비트여서 IP 주소를 1677만 7214개 사용할 수 있다고 했다.
- 그 많은 수의 컴퓨터가 브로드캐스트 패킷을 전송하면 모든 컴퓨터에 패킷이 전송되고 네트워크가 혼잡해진다.
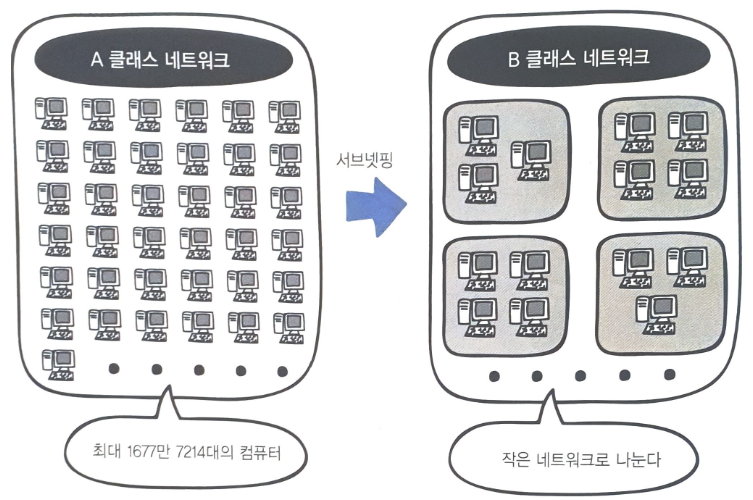
- 그림과 같이 A 클래스의 대규모 네트워크를 작은 네트워크로 분할하여 브로드캐스트로 전송되는 패킷의 범위를 좁힐 수 있다.
- 이렇게 하면 더 많은 네트워크를 만들 수 있어서 IP 주소를 더 효과적으로 활용할 수 있다.
네트워크를 분할하는 것을 서브넷팅(subneting)이라고 하고, 분할된 네트워크를 서브넷(subnet)이라고 한다.
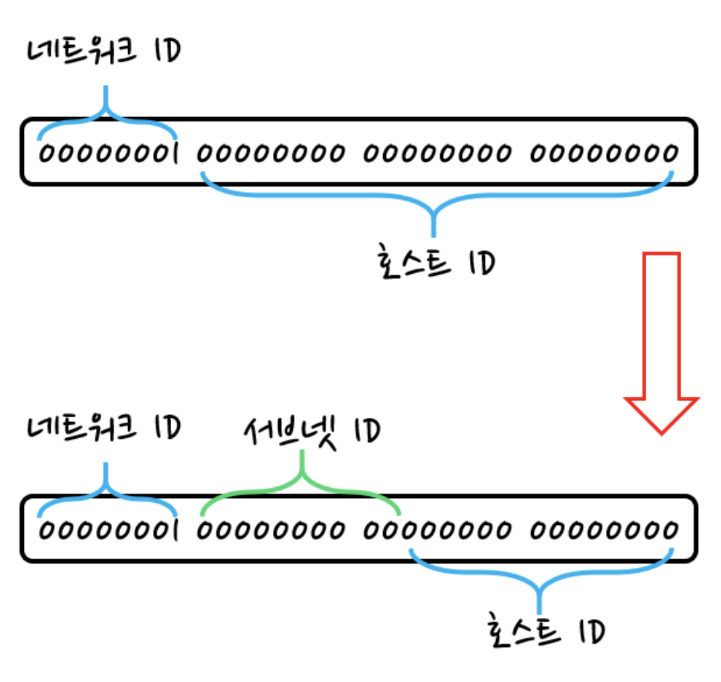
- 네트워크 ID가 8비트고, 호스트 ID가 24비트인 상태를 서브넷팅하여 작은 네트워크로 분할하는 것.
- 그러면 호스트 ID에서 비트를 빌려 서브넷으로 만들 수 있다
F-1. 서브넷 마스크란?
- IP 주소를 서브넷팅하면 어디까지가 네트워크 ID고 어디부터가 호스트 ID인지 판단하기 어렵다. 그럴 때 서브넷 마스크라는 값을 사용한다.
서브넷 마스크는 네트워크 ID와 호스트 ID를 식별하기 위한 값이다.
32비트의
A 클래스의 서브넷 마스크는 11111111 00000000 00000000 00000000 = 255.0.0.0
B 클래스의 서브넷 마스크는 11111111 11111111 00000000 00000000 = 255.255.0.0
C 클래스의 서브넷 마스크는 11111111 11111111 11111111 00000000 = 255.255.255.0
- 프리픽스(prefix) 표기법으로도 사용할 수 있다.
- 프리픽스 표기법은 서브넷 마스크를 슬래시(/비트 수)로 나타낸 것을 말한다. 예를 들어 255.255.255.0은 /24가 된다.
F-2. 서브네팅
- 네트워크를 더 작고 효율적인 부분으로 나누는 프로세스이다. 대형 네트워크를 여러 개의 작은 네트워크, 서브넷으로 분할함으로써 IP 주소 공간을 더 효율적으로 사용할 수 있다.
- IP 주소를 2진수로 표현한다.
- 서브 마스크를 2진수로 표현한다.
- AND 연산으로 네트워크 주소를 알아낸다.
- 호스트 부분을 모두 1로 변경하여 브로드캐스트 주소를 알아낸다.
- 사용 가능한 IP 주소 범위를 파악한다. 서브넷팅한 네트워크 주소 +1은 사용 가능한 가장 작은 IP 주소이다.
- 브로드캐스트 주고 -1은 사용 가능한 가장 큰 IP 주소이다.
F-3. CIDR
- 클래스 기반 네트워킹을 대체하기 위해 개발된 방식으로, 더욱 유연한 IP 주소 할당을 가능하게 한다.
- 슬래시(/) 뒤에 숫자를 사용하여 네트워크 부분의 비트 수를 표현한다. (ex: 192.168.56.0/24)
- 슬래시(/) 뒤에 오는 숫자는 네트워크 부분의 비트 수를 나타낸다. 이 비트 수는 해당 네트워크에서 호스트를 구분하는 데 사용된다.
- 예를 들어, "192.168.56.0/24"는 24비트가 네트워크를 나타내고 나머지 8비트가 호스트를 나타낸다는 의미이다.

F-4. VLSM (Variable Length Subnet Mask)
- VLSM은 IP 주소를 서로 다른 크기의 서브넷으로 나눌 때 사용하는 네트워크 설계 기술
- 기존의 고정 길이 서브넷 마스크(Subnet Mask)와는 달리, VLSM은 서로 다른 서브넷에 다양한 크기의 IP 주소 범위를 할당
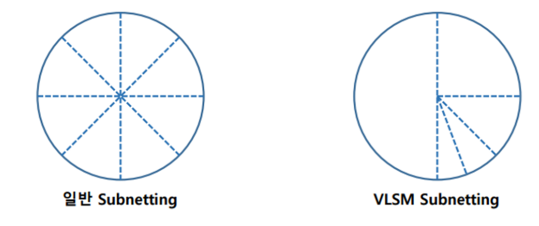
F-5. CIDR & VLSM 비교

G. 공인 IP란?
-전 세계에 유일하게 할당받은 하나의 IP
- ISP(Internet Service Provider)로부터 제공받는 IP로 외부에 공개된 IP 주소
- 인터넷 상에 연결된 서로 다른 네트워크 상의 컴퓨터끼리 접근할 때 사용
- 해킹의 위험이 존재하기 때문에 방화벽 or 보안 프로그램 설치 필요
G-1. 사설 IP란?
-로컬 IP, 가상 IP라고도 불리며, 외부에서 접근할 수 없는 IP
- IPv4 주소 부족 현상을 해결하기 위해 로컬 네트워크 상, PC나 장치에 할당
- 일반가정 or 회사 내부에서 사용하는 목적
- 라우터/공유기를 통해 사설 IP 할당
- 사설 IP만으로 외부에서 접근 불가
사설 IP 대역
A 클래스: 10.0.0.0 ~ 10.255.255.255
B 클래스: 172.16.0.0 ~ 172.31.255.255
C 클래스: 192.168.0.0 ~ 192.168.255.255
G-2. NAT란?
-NAT는 Network Address Translation의 약자로 네트워크 주소를 변환하는 기술이다.
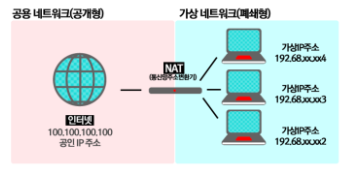
위 그림을 보면 네트워크의 흐름을 이해할 수 있겠지만 다음과 같이 진행된다.
내부로 들어오는 경우
공인 IP > NAT를 통해 공인 IP to 사설 IP로 변환 > 사설 IP
외부로 나가는 경우
사설 IP > NAT를 통해 사설 IP to 공인 IP 변환 > 공인 IP
NAT를 통해 얻는 이점은 외부와 통신하는 관점에서 내부 사설 IP를 노출하지 않아도 되기 때문에 보안에 유리하다는 점이다.
1-4. 전송 계층
- 네트워크 계층이 데이터를 전달받아 이를 세그먼트로 분할하고, 이를 목적지까지 안전하게 전송하는 역할을 한다.
- 통신 세션을 관리하며, 에러 복구와 흐름 제어 기능을 담당한다.
- 가장 대표적인 전송 게층의 프로토콜은 TCP, UDP가 있다.
A. TCP
- 네트워크 상에서 데이터를 안정적으로 전송하기 위한 프로토콜 중 하나이다. TCP는 신뢰성 있는 연결을 제공하며, 데이터의 순서를 보장하고 오류 복구를 수행한다.
- 하나의 송신 측과 하나의 수신 측이 통신하는 1:1 통신이다.(point-to-point)
- 서버와 클라이언트간에 데이터를 신뢰성 있게 전달하기 위해 만들어진 프로토콜이다.
- 데이터를 전송하기 전에 데이터 전송을 위한 연결을 만드는 연결지향 프로토콜이다.
- TCP 연결은 어떻게?
- TCP 연결을 맺을 때는 3-ways handshake를 사용하게 되고 연결을 끊을 때는 4 ways handshake를 사용한다
A-1. 3 way handshake
-
TCP/IP 프로토콜을 이용해서 통신을 하는 응용프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 말한다.
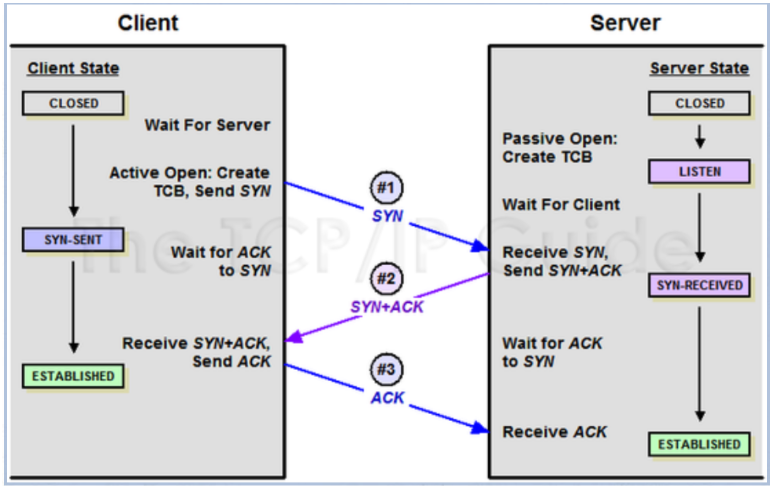
-
클라이언트가 서버에 연결 요청 (SYN)
→ 클라이언트가 초기 시퀀스 번호(seq=0)를 갖는 SYN 패킷을 보냄
→ 서버는 SYN + ACK 패킷으로 응답하고, 초기 시퀀스 번호를 알려줌 -
클라이언트가 응답 및 데이터 요청 (ACK 및 HTTP 요청)
→ 클라이언트가 ACK 패킷을 보내고, HTTP GET 요청을 서버로 전송
→ 클라이언트의 ACK 패킷에는 초기 시퀀스 번호, 확인 응답 번호가 포함됨 -
서버가 응답 및 데이터 전송 (ACK 및 HTTP 응답)
→ 서버가 클라이언트에게 ACK 패킷으로 응답하고, HTTP 응답을 클라이언트로 전송
→ 서버의 ACK 패킷에는 초기 시퀀스 번호, 확인 응답 번호가 포함됨 -
클라이언트가 서버의 응답 확인 (ACK)
→ 클라이언트가 서버의 HTTP 응답에 대한 확인으로 ACK 패킷을 보냄
→ 클라이언트의 ACK 패킷에는 초기 시퀀스 번호, 확인 응답 번호가 포함됨
A-2. 4 way handshake
3way handshake가 연결확립을 위해 진행했다면 4way handshake는 세션을 종료하기 위해 수행되는 절차를 말한다.
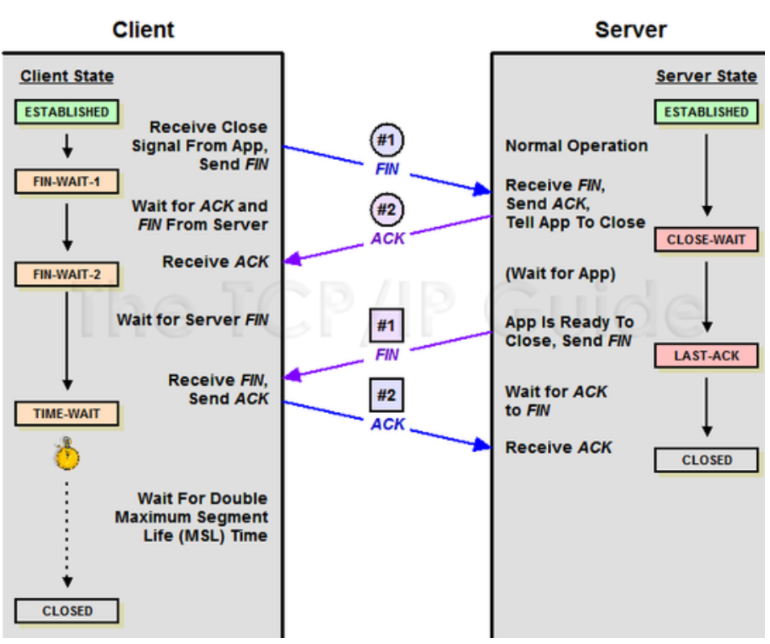
-
[Client -> FIN -> Server]
Client가 연결을 종료하겠다는 FIN플래그를 전송한다. 보낸 후에 FIN-WAIT-1 상태로 변한다.
-
[Server-> ACK -> Client]
FIN 플래그를 받은 Server는 확인메세지인 ACK를 Client에게 보내준다. 그 후 CLOSE-WAIT상태로 변한다. Client도 마찬가지로 Server에서 종료될 준비가 됐다는 FIN을 받기위해 FIN-WAIT-2 상태가 된다.
-
[Server -> FIN -> Client]
Close준비가 다 된 후 Server는 Client에게 FIN 플래그를 전송한다.
-
[Client -> ACK-> Server]
Client는 해지 준비가 되었다는 정상응답인 ACK를 Server에게 보내준다. 이 때, Client는 TIME-WAIT 상태로 변경된다.
TCP는 크게 3가지 제어 기능이 있다.
- 전송되는 데이터의 양을 조절하는 흐름 제어
- 데이터가 유실되거나 잘못된 데이터가 수신되었을 경우 대처하는 방법인 오류 제어
- 네트워크 혼잡에 대처하는 혼잡 제어
B. 흐름제어
- 송신 측과 수신 측의 데이터 처리 속도가 다를 수 있다.
- 송신 측이 빠를 때 수신 측 버퍼가 넘치는 오버플로우 문제가 발생한다.
- 이러한 문제를 줄이기 위해 윈도우 크기로 송신 측의 데이터 전송량을 조절한다.
- 윈도우 크기 : 자신이 처리할 수 있는 데이터의 양
흐름제어에는 크게 두 가지의 방법이 있는데 Stop and wait, Sliding window 방식이 있다.
B-1. Stop and wait
- 단순하게 일정량의 패킷만 보내고 처리했다는 응답이 올 때까지 다음 packet을 보내지않고 기다리는 방식이다.
- 굉장히 원시적인 방법이고 비효율적인 방식이다. 실제로 해당 방식을 사용하지는 않고 아래 기술할 Sliding window를 사용한다.
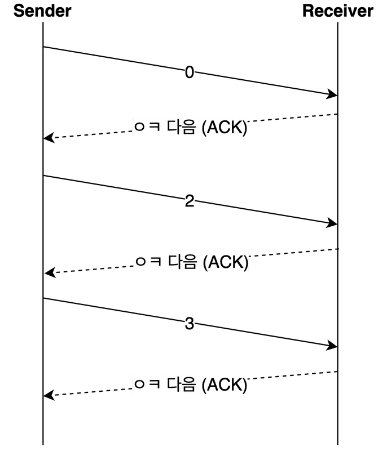
B-2. Sliding window
- 슬라이딩 윈도우는 앞서 Stop and wait와 다르게 수신측이 감당할 수 있는 윈도우의 크기를 피드백해주기 때문에 송신측에서 이를 기준으로 송신을 하는 차이가 있다. 따라서 일일이 ACK를 기다릴 필요 없이 해당 윈도우 크기에 맞춰서 request를 보내주면 되는 것이다.
- 송신 측이 수신 측에서 받은 윈도우 크기를 참고해서 데이터의 흐름을 제어하는 방식
- 수신 측이 한 번에 처리할 수 있는 데이터의 양(윈도우 크기)을 3 way handshake할 때 송신 측에 전달한다.
- 상대방에게 응답을 받지 않아도 범위 내에서 데이터를 보낼 수 있다.
- 패킷의 왕복 시간(RTT)이 크다면 네트워크가 혼잡하다고 생각하여 윈도우 크기를 실제 버퍼의 크기보다 작게 설정한다.
- 통신 과정 중에도 네트워크 혼잡 등의 조건을 통해 윈도우 크기는 유동적으로 설정된다.
C. 혼잡 제어
- 네트워크 내에 패킷의 수가 과도하게 증가하는 현상을 혼잡이라고 한다.
- 혼잡 제어는 혼잡 현상을 방지하고 제거하기 위한 기능이다.
- 흐름 제어는 송신 측과 수신 측의 전송 속도를 다루고, 혼잡 제어는 라우터를 포함한 넓은 범위의 전송 문제를 다룬다.
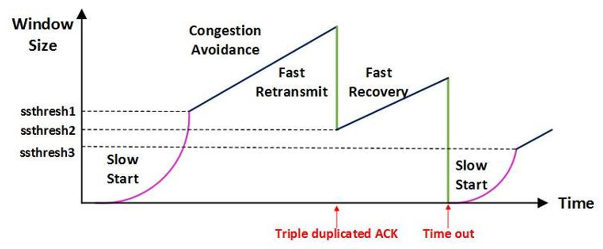
C-1. AIMD (Additive Increase / Multiplicative Decrease)
-
처음에 패킷을 하나씩 보내고 문제가 발생하지 않으면 윈도우 크기를 1씩 증가하는 방법
-
패킷 전송에 실패하거나 일정 시간을 넘으면 패킷 전송 속도를 절반으로 줄인다.
-
네트워크에 늦게 들어온 호스트가 처음에는 불리하지만, 시간이 흐르면서 평형상태로 수렴한다.
단점
-
처음에 전송 속도를 올리는 데 시간이 오래걸린다.
-
네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄인다.
C-2. Slow Start (느린 시작)
- AIMD와 같이 패킷을 하나씩 보내고 문제가 발생하지 않으면 각 ACK 패킷마다 윈도우 크기를 1씩 늘려준다. 즉, 한 주기가 지나면 윈도우 크기는 2배가 된다.
- AIMD와 달리 전송 속도를 지수 함수 꼴로 증가시켜서 윈도우 크기를 더 빠르게 증가시킨다.
- 혼잡이 감지되면 윈도우 크기를 1로 줄인다.
- 처음에는 네트워크 수용량을 예상할 수 있는 정보가 없지만, 한 번 혼잡 현상이 발생한 후에는 네트워크의 수용량을 어느 정도 예상할 수 있다.
- 그래서 혼잡 현상이 발생하는 윈도우 크기의 절반가지는 지수 함수 꼴로 윈도우 크기를 증가시키고 그 이후에는 완만하게 1씩 증가시킨다.
C-3. Fast Retransmit (빠른 재전송)
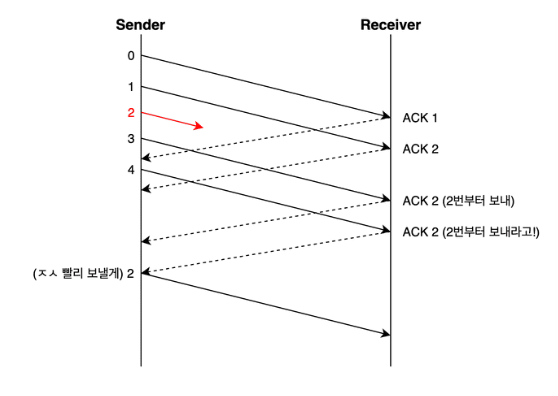
- TCP는 지금가지 받은 데이터 중 연속되는 패킷의 마지막 순번 이후를 ACK 패킷에 실어서 보낸다.
- 그래서 송신 측이 아래처럼 3, 4번을 보내더라도 ACK 2 를 중복해서 받는다.
- 그러면 timeout이 발생하기 전이라도 송신 측은 문제가 되는 2번 패킷을 재전송한다.
- 그리고 혼잡한 상황이라고 판단해서 윈도우 크기를 줄인다.
- 3 ACK Duplicated : 송신 측이 3번 이상 중복된 ACK 번호를 받은 상황
C-4. Fast Recovery (빠른 회복)
- 혼잡한 상태가 되면 윈도우 크기를 1이 아니라 반으로 줄이고, 선형 증가시킨다.
- 혼잡 상황을 한번 겪은 이후로는 AIMD 방식으로 동작한다.
D. 오류 제어
- TCP는 통신 중에 오류가 발생하면 해당 데이터를 재전송한다.
- 즉, 재전송 기반 오류 제어 ARQ(Automatic Repeat Request)를 사용한다.
- 재전송은 비효율적이므로 적을수록 좋다.
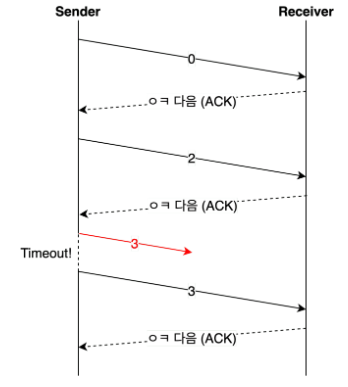
D-1. Stop and Wait
- ACK를 받고 나서 다음 데이터를 보내는 방식이다.
- 일정 시간을 지나 timeout이 발생하면 이전 데이터를 재전송한다.
- 흐름 제어에서의 슬라이딩 윈도우를 사용할 수 없으므로 더 효율적인 ARQ가 필요하다.
D-2. Go Back N
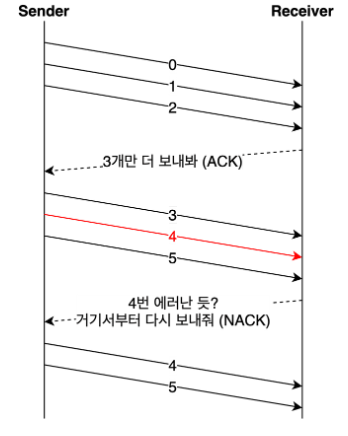
- 연속으로 데이터를 보내다가 오류가 발생한 지점부터 재전송하는 방식이다.
- 아래처럼 4번 데이터에서 에러가 발생했다면 4번 이후의 데이터는 모두 삭제한다.
- 성공적으로 전송된 데이터까지 재전송하기 때문에 조금 비효율적이다.
D-3. Selective Repeat
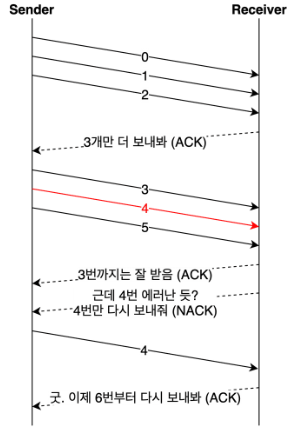
- 오류가 발생한 데이터만 재전송하는 방식이다.
- Selective Repeat의 단점은 수신 측 버퍼의 데이터가 순차적이지 않다는 것이다.
- 정렬의 과정이 추가로 필요하고 별도의 버퍼가 필요하다.
- Go Back N과 비교하여 상황에 따라 더 유리한 방법을 선택하면 된다.
E. UDP
- 비연결형, 신뢰성이 없는 전송 프로토콜이다.
- 흐름 제어, 오류 제어 또는 손상된 세그먼트의 수신에 대한 재전송을 하지 않는다.
- 따라서 내용이 전송 중에 손실될 수 있고, 전송되는 세그먼트의 순서가 바뀔 수 있다.
UDP는 TCP보다 간단하고 빠르다. - 흐름 제어를 하지 않기 때문에 전송 속도를 최대한 빠르게 할 수 있다.
F. 잘 알려진 포트 번호
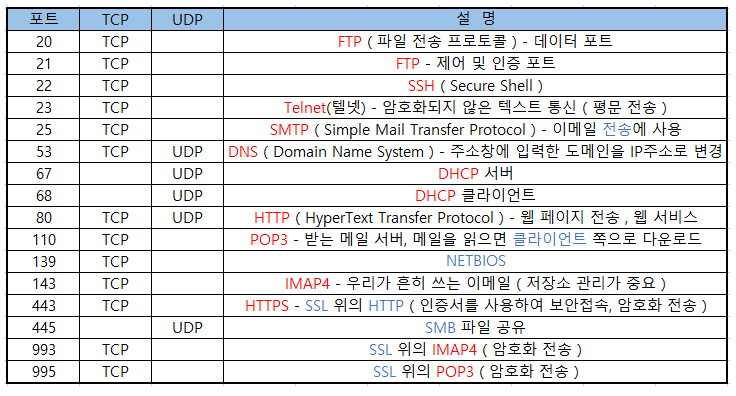
1-5. 세션 계층
- 응용 프로그램 간의 대화를 유지하기 위한 구조 제공 + 이를 처리하기 위해 프로세스들의 논리적 연결을 담당
- 통신 중 연결이 끊어지지 않도록 유지시켜주는 역할을 수행
TCP/IP 세션의 연결 확립/중단/해제, 서션 메세지 전송 기능 수행- 포트 번호를 기반으로 연결
- 송수신을 위한 프로세서들을 서로 논리적으로 연결
- 통신 장치 간 상호작용 + 동갈허룰 제공
- 세션을 종료할 필요가 있을 경우, 적절한 시간을 수신측에게 알려준다.
- Data 단위: 메세지
- 토큰: 두 프로세스 간의 대화를 관리하는 특수 메세지
- 대표적 프로토콜: SSH, TLS
- 전이중 통신/ 반이중 통신/ 단방향 통신이 존재한다.
1-6. 표현 계층
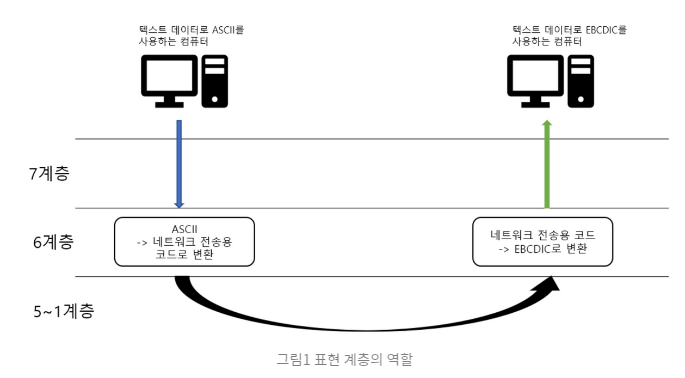
- 표현 계층은 응용 계층과 세션 계층 사이에서 정보를 넘겨주는 역할을 한다.
- 응용프로그램이나 네트워크를 위해 데이터를 ‘표현’하는 부분이다.
- 표현 계층의 변환을 통해 하드웨어/OS에 따른 차이를 없앤 데이터 교환이 가능해진다.
- 암호화, 복호화의 과정이나 압축이 해당 계층에서 처리된다.
- 데이터가 텍스트인지 이미지 파일인지 구분하여 우리가 볼 수 있는 형태로 표현(인코딩, 디코딩)하는게 표현계층의 역할이다.
예를들어 유니코드(UTF-8)로 인코딩 되어있는 문서를 ASCII로 인코딩 된 문서로 변환하려고 할 때 표현 계층에서 변환이 이루어진다.
표현계층의 대표적인 프로토콜
- SSL(디지털 인증서)
- ASCII
- JPEG(이미지)
- MPEG(멀티미디어(비디오, 오디오))
1-7. 응용 계층
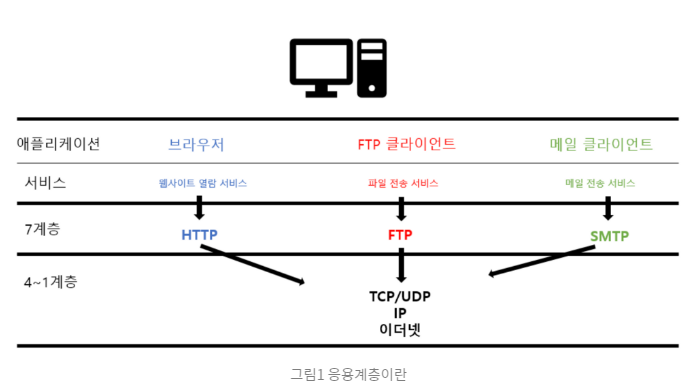
응용계층의 대표적인 프로토콜
- HTTP (인터넷 상에서 정보를 주고받는 프로토콜. 주로 HTML문서를 주고받는데 쓰인다)
- FTP (서버와 클라이언트 사이의 파일을 전송하기 위한 파일 전송 프로토콜)
- SMTP (인터넷에서 이메일을 보내고 받기 위한 우편 전송 프로토콜)
- Telnet (원격 접속을 위해 원격지 서버의 실행창을 얻어내는 프로토콜)
- DNS (도메인 이름을 IP 주소로 변환시켜주는 프로토콜)
- POP3 (이메일 클라이언트가 메일 서버에서 메일 메시지를 가져오는데 사용하는 프로토콜)
- IMAP(이메일 클라이언트와 메일 서버 간에 메일 메시지를 동기화하는 데 사용되는 프로토콜)
- DHCP(네크워크에서 컴퓨터와 장치에 자동으로 IP 주소 및 기타 네트워크 설정을 제공하는 프로토콜)

제목이 조금 더 자극적이었으면 좋겠네요