코딩 테스트를 완벽 마스터하기 위해 프로그래머스 모든 문제를 풀어보는 중입니다. (사실 코테 때문이라기 보다는 알고리즘 푸는 것이 제일 즐겁습니다.. 잠깨기 최고에요)
그 중 오늘 풀어본 2020년 카카오 공채 문제 하나를 가지고 와봤습니다. 문제 자체는 어렵지 않으나 중복 쿼리에 대한 Map을 활용한 캐싱을 활용하는 과정에서 성능 개선이 되는지 확인하는 과정이 흥미로워서 가지고 와봤습니다.

https://school.programmers.co.kr/learn/courses/30/lessons/60060
문제는 그렇게 어렵지 않습니다.
포인트는 아래와 같습니다.
-
검색 쿼리는 접두사, 접미사 형태로만 주어진다.
따라서 접미사인 경우 쿼리를 반대로 뒤집으면 접두사인 쿼리와 형태가 동일해진다. -
각 단어 가사 길이는 1만 이하이고, 전체 가사 단어 길이의 합은 1000만 이하이다.
-
실제로 쿼리당 모든 단어를 찾을 필요가 없다.
쿼리 길이와 다른 단어는 볼 필요가 없음으로 맵으로 단어 길이를 key로 가진 map을 만들어주면 된다. -
맵에 단어를 정렬된 형태로 저장하면 이분탐색 (binary / paramatic search) 으로 적절한 단어를 빠르게 찾을 수 있다.
그러나 1번에서 접미사 형태로 주어지면 쿼리를 뒤집어야 함으로 단어도 뒤집힌 형태의 map을 한 개 더 만들어주면 된다.
따라서 핵심 알고리즘으로 map과 정렬, 이분탐색을 활용하였고,
쿼리에 만족하는 단어들의 범위를 구하기 위해 총 3번의 이분탐색을 진행하였습니다.
- binarySearch로 쿼리에 해당하는 단어 idx 탐색, 없으면 바로 0 리턴.
- binarySearchLeft로 쿼리에 해당하는 단어의 왼쪽 범위 idx 계산
- binarySearchRight로 쿼리에 해당하는 단어의 오른쪽 범위 idx 계산
- 오른쪽 범위 idx - 왼쪽 범위 idx + 1 리턴
다른 풀이를 보면 trie를 활용하였던데, 저는 실제 단어 값이 아닌, 쿼리가 가져올 수 있는 단어의 갯수만 확인하는 것임으로, 굳이 모든 노드마다 자식 노드들에 대한 카운트 값을 가지고 있을 필요가 없다고 생각되어 이분탐색을 활용하여 풀이하였습니다. 아래 실행 결과를 보면 이분탐색이 많은 데이터에 대해 더 효율적인 것을 알 수 있습니다.
정답 코드
import java.util.*;
/**가사 검색
* 알고리즘 : 이분 탐색, 맵
* 핵심 아이디어 :
* 0. 단어와 쿼리 갯수는 10만, 단어의 길이 자체가 1만 이하로 / 해당 단어가 쿼리에 적절한지 비교하는 경우는 O(N)으로 들어가도, 단어 탐색은 log(N)으로 해결해야 한다 -> 이분 탐색
* 0.1 단어 갯수가 10만으로 Nlog(N)만에 정렬이 가능하긴 하다. 그리고 단어 길이별로 나눌 것임으로 정렬하는데 시간이 덜들 것이다.
*
* 1. 쿼리는 접두사나 접미사 1가지로만 들어옴으로, 비교로직은 앞에서부터 (접두사를) 검사하는 방식으로 하되, 접미사로 쿼리가 들어오면 쿼리를 뒤집는다.
* 2. 이에 맞추어 words도 단어 길이에 따라 일반 단어와 뒤집힌 단어, 2가지를 저장해둔다 (frontMap, backMap) 따라서 key가 단어의 길이가 된다.
* 3. 쿼리가 정방향이면 frontMap에서, 쿼리가 접미사이면 뒤집어서 backMap에서 탐색한다.
* 4. map에서 단어 길이에 해당하는 key에서 단어 리스트를 받아와 쿼리에 적절한 단어가 있는지 이분탐색으로 찾는다. 없으면 바로 0을 반환한다.
* 5. 있다면 그 단어 idx를 기준으로 왼쪽 boundady, 오른쪽 boundary를 각각 이분탐색으로 찾는다. (단어당 최악의 경우 총 3회 탐색)
*
* 기타 :
* 1. 단어는 중복이 없으나 쿼리는 중복이 있음으로 캐시를 고려할 수 있으나, 테스트 결과 읽기 요청이 그렇게 많지 않아서 효과는 미비했다. 오히려 캐시를 사용한 경우가 더 오래걸린 경우도 존재
* */
class 가사_검색 {
public int[] solution(String[] words, String[] queries) {
int[] answer = new int[queries.length];
// 인풋
Map<Integer, List<String>> frontMap = new HashMap<>();
Map<Integer, List<String>> backMap = new HashMap<>();
for (String word : words){
int len = word.length();
frontMap.putIfAbsent(len, new ArrayList<>());
frontMap.get(len).add(word);
backMap.putIfAbsent(len, new ArrayList<>());
backMap.get(len).add(new StringBuilder(word).reverse().toString());
}
// 정렬
for (List<String> list :frontMap.values()){
Collections.sort(list);
}
for (List<String> list :backMap.values()){
Collections.sort(list);
}
// 캐시
// Map<String, Integer> cache = new HashMap<>();
// 쿼리
for (int i = 0; i < queries.length; i++) {
String query = queries[i];
// if (cache.containsKey(query)) {
// answer[i] = cache.get(query);
// continue;
// }
if (query.charAt(0) != '?') answer[i] = find(query, frontMap);
else answer[i] = find(new StringBuilder(query).reverse().toString(), backMap);
// cache.put(query, answer[i]);
}
return answer;
}
private int find(String query, Map<Integer, List<String>> frontMap) {
List<String> list = frontMap.get(query.length());
if (list == null) return 0;
int found = binarySearch(query, list);
if (found == -1) return 0;
return binarySearchRight(query, list, found) - binarySearchLeft(query, list, found) + 1;
}
private int binarySearchRight(String query, List<String> list, int l) {
int r = list.size()-1;
int rightIdxBoundary = l;
while(l <= r){
int mid = l + (r-l) / 2;
int res = compare(list.get(mid), query);
if (res == 0) {
rightIdxBoundary = mid;
l = mid+1;
} else if (res == 1) {
r = mid-1;
} else {
l = mid+1;
}
}
return rightIdxBoundary;
}
private int binarySearchLeft(String query, List<String> list, int r) {
int l = 0;
int leftIdxBoundary = r;
while(l <= r){
int mid = l + (r-l) / 2;
int res = compare(list.get(mid), query);
if (res == 0) {
leftIdxBoundary = mid;
r = mid-1;
} else if (res == 1) {
r = mid-1;
} else {
l = mid+1;
}
}
return leftIdxBoundary;
}
private int binarySearch(String query, List<String> list) {
int l = 0;
int r = list.size()-1;
int foundIdx = -1;
while(l <= r){
int mid = l + (r-l) / 2;
int res = compare(list.get(mid), query);
if (res == 0) {
foundIdx = mid;
break;
} else if (res == 1) {
r = mid-1;
} else {
l = mid+1;
}
}
return foundIdx;
}
private int compare(String word, String query){
for (int i = 0; i < word.length(); i++) {
if (query.charAt(i) == '?') return 0; // 쿼리에 해당하는 단어면 0 반환
if (word.charAt(i) > query.charAt(i)) return 1; // 쿼리보다 뒷단어면 1
else if (word.charAt(i) < query.charAt(i)) return -1; // 쿼리보다 앞단어면 -1
}
return 0;
}
}캐시 활용이 필요한가?
그런데 잠깐, 코드를 잘 보면 캐시를 활용하였으나 주석 처리한 부분이 있습니다.
// 캐시
// Map<String, Integer> cache = new HashMap<>();
// 쿼리
for (int i = 0; i < queries.length; i++) {
String query = queries[i];
// if (cache.containsKey(query)) {
// answer[i] = cache.get(query);
// continue;
// }
if (query.charAt(0) != '?') answer[i] = find(query, frontMap);
else answer[i] = find(new StringBuilder(query).reverse().toString(), backMap);
// cache.put(query, answer[i]);
}
쿼리하는 과정에서 이미 쿼리한 이력이 있으면 바로 캐싱해둔 값을 반환해버리는 코드가 주석처리 되어있습니다.
문제 조건을 보면 가사 단어는 중복되지 않으나, 검색 키워드는 중복될 수 있다고 합니다. 따라서 처음에는 같은 검색 키워드만 10만개가 주어지는 경우 캐싱을 활용하면 효율적으로 문제를 해결할 수 있겠다는 생각이 들었습니다.
그러나 만약 중복 없이 다양한 검색 쿼리가 주어진다면 캐시를 확인하고 저장하는 과정에서 오히려 성능에 악영향을 줄 수도 있지 않을까요? 무엇보다 검색 쿼리와 가사 단어가 둘다 10만개로, 검색쿼리의 갯수가 압도적으로 많은 것도 아닙니다.
실제 상황이라면 특정 단어를 검색하는 경우가 많을 것이고, 캐싱을 레디스와 같은 별도의 key-value DB에 TTL을 관리하여 저장할 수 있을 것입니다만, 해당 문제에서는 굳이 활용을 해야하는지 고민이 되었습니다. 이는 테스트 케이스 형태에 큰 영향을 받을 것 같았습니다.
따라서 테스트를 해보았습니다.
테스트
-
캐싱을 사용하지 않았을 때
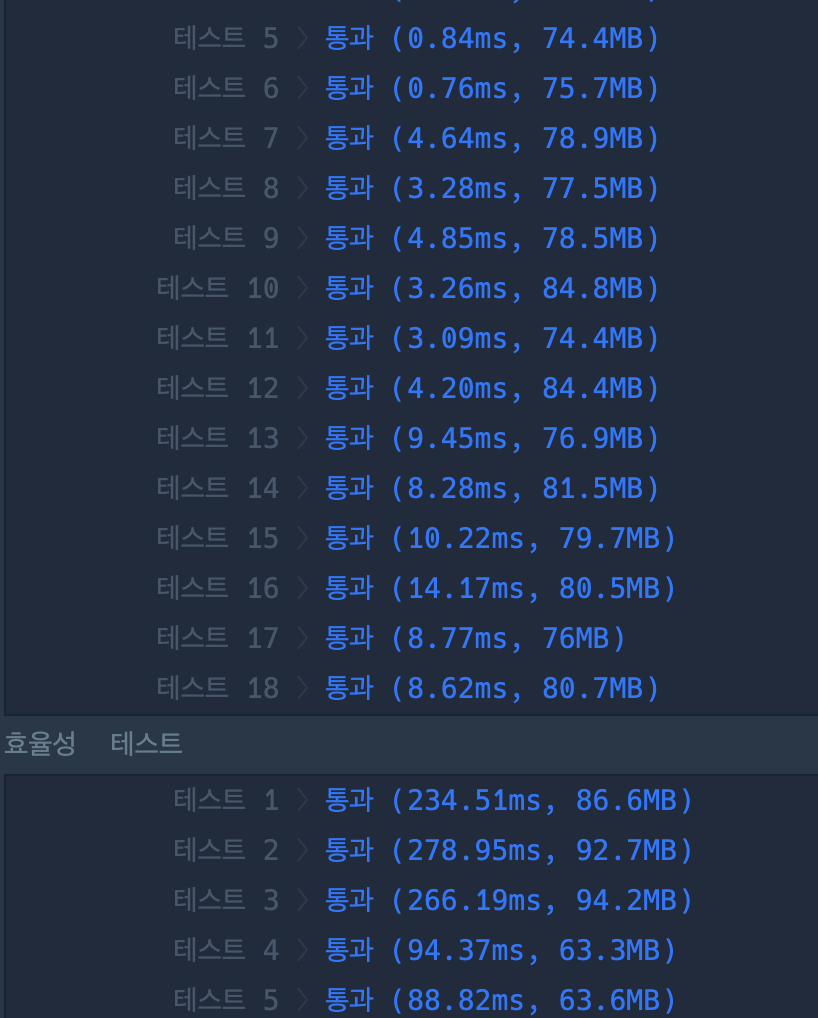
-
캐싱을 사용 하였을 때
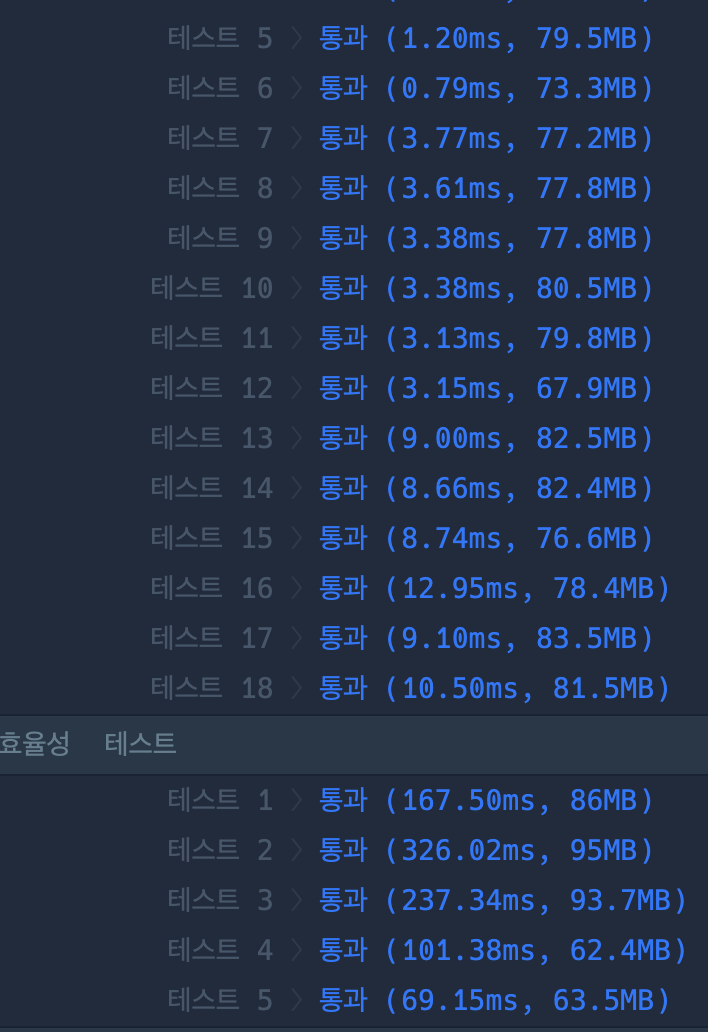
예상 대로 해당 문제에서는 그닥 효과가 좋지 않았습니다..
보통 테스트케이스에서는 캐시를 사용한 것이 오히려 성능이 좋지 않았고,
효율성 테스트에서도 2번 테케에서는 캐시 사용한 경우가 더 느렸습니다.
아무래도 검색 쿼리 숫자가 적고, 중복 쿼리가 적을 수 있음으로, 알고리즘 문제에서는 특별한 상황이 아니면 중복이 있을 수 있다고 무작정 캐싱을 적용하는 것은 좋지 않을 수도 있을 것 같습니다.
오늘의 결론
캐싱을 적용하는 것이 항상 효율적이지는 않다.
실제 서비스에서
- 캐시 ↔ DB간 데이터 정합성
- 캐시
- 이외 캐시 운영 비용
물론 해당 알고리즘 문제에서는 데이터가 쿼리하는 중간에 추가될 일이 없어 데이터 정합성 문제를 고려할 필요가 없고, 캐시와 DB에서의 데이터 접근 속도가 같은 어플리케이션 내에서 동일했기 때문에 전혀 적절한 비교는 아닙니다 ~
다만 알고리즘 문제에서 이를 적용해보려고 했고, 생각보다는 효과가 좋지 않았다는 내용을 공유해보고 싶었습니다!
번외로 다른 사용자들의 trie 풀이
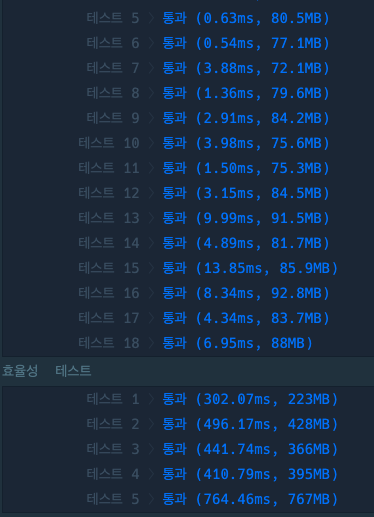
연습을 위해 trie로 다시 한번 풀어보는 것도 좋겠습니다!
