[JPA / Querydsl] NoOffset을 사용한 조회 쿼리 성능 개선, BooleanExpression 사용하기
팀 프로젝트에서 검색 조건에 따라 방의 정보를 리턴하는 api를 작성해야했다.
검색 조건에 따른 방을 read하는 동적 쿼리작성 및 동시에 페이징해와야하는 쿼리였는데, 성능 개선과 코드 가독성을 위한 내용을 정리해보았다.

아이템
- NoOffset 적용
- BooleanBuilder→ BooleanExpression 으로 코드 변경
📌 1. NoOffset을 활용한 조회 쿼리 성능 개선
아래는 noOffset이 적용되지 않은 기존의 Slice를 리턴하는 코드이다.
추가적으로 Page를 사용하지 않고 Slice를 사용한 이유로는, Slice는 Page와 달리 추가 page가 있는지에 대한 정보 확인을 위한 count 쿼리가 추가적으로 발생하지 않아 성능적으로 이점을 가져갈 수 있다.
@Override
public Slice<RoomSearchResponseDto> findRoomCustom(RoomSearchRequestDto req, Pageable pageable) {
List<RoomSearchResponseDto> content = jpaQueryFactory.select(Projections.constructor(RoomSearchResponseDto.class,
room.id,
member.memberId,
member.nickname,
room.title,
room.description,
room.link,
room.roomImage,
room.mcount,
room.capacity,
room.isLocked,
room.password,
room.constraints,
room.type, room.createdAt)).distinct().
from(room)
.innerJoin(member).on(room.manager.memberId.eq(member.memberId))
.leftJoin(roomKeyword).on(roomKeyword.room.eq(room))
.leftJoin(keyword).on(roomKeyword.keyword.eq(keyword))
.where(
eqKeyword(req.getSearchKeyword()),
isLocked(req.getIsLocked()),
eqConstraints(req.getConstraints()),
eqKeywordIds(req.getKeywordIds()),
eqType(req.getType()),
btwMcount(req.getMinMcount(), req.getMaxMcount()),
btwCapacity(req.getMinCapacity(), req.getMaxCapacity()))
.orderBy(makeOrder(req))
.offset(pagable.getOffset())
.limit(pageable.getPageSize() + 1) // 1개를 더 가져온다
.fetch();
boolean hasNext = content.size() > pageable.getPageSize(); // 뒤에 더 있는지 확인
content = hasNext ? content.subList(0, pageable.getPageSize()) : content; // 뒤에 더 있으면 1개 더 가져온거 빼고 넘긴다
return new SliceImpl<>(content, pageable, hasNext);
}코드가 길지만 우리는 이 부분만 집중해서 보면 된다
.offset(pagable.getOffset())
.limit(pageable.getPageSize() + 1) // 1개를 더 가져온다
.fetch();
boolean hasNext = content.size() > pageable.getPageSize(); // 뒤에 더 있는지 확인
content = hasNext ? content.subList(0, pageable.getPageSize()) : content; // 뒤에 더 있으면 1개 더 가져온거 빼고 넘긴다
return new SliceImpl<>(content, pageable, hasNext);Pagable에서 offset, pageSize를 가져오고 pageSize보다 1개 더 크게 데이터를 가져온다.
해당 데이터 값이 pageSize + 1만큼 모두 가져왔다면 뒤에 데이터가 더 남아있다는 뜻으로,
hasNext를 true로 설정하여 SliceImpl을 반환한다.
끝으로, content는 1개 더 가져온 데이터를 제외한 페이지 크기만큼의 데이터를 반환한다.
📌 그렇다면 NoOffset이란 무엇일까?
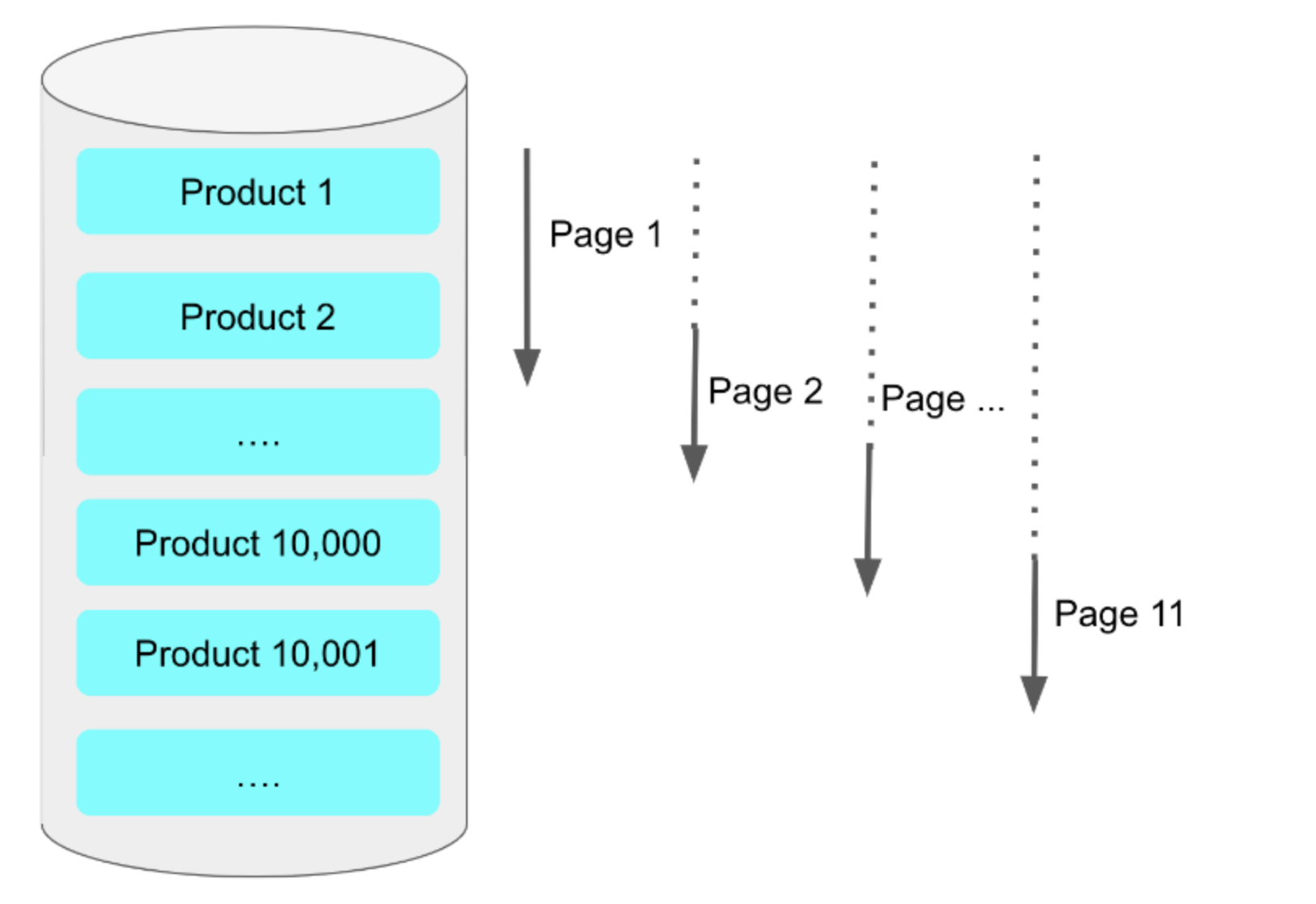
출처 : https://jojoldu.tistory.com/528
offset 10000
limit 20만약 위와 같은 조건을 가지는 예시에서 크기가 1000개인 11번 페이지를 읽어야 한다고 가정해보자.
이를 위해 우리는 10020개의 컬럼을 읽어야 하며, 이 중 10000개의 컬럼은 불필요하게 탐색을 하게 되는 것이다.
그리고 그림에서 알 수 있듯이, 뒤에있는 페이지를 탐색할 수록 불필요한 컬럼을 읽음으로서 성능은 더욱 떨어지게 될 것이다.
즉 NoOffset에 대해서는 아래와 같이 정리할 수 있다.
🧑🏫 " NoOffset은 offset의 불필요한 컬럼 탐색을 스킵하여 조회 시작 부분을 인덱스로 빠르게 찾아 필요한 페이지의 정보만 select해오는 방법이다. "
구현하는 방법으로는 조회 조건문에 맨 처음에 PK로 제한 조건을 거는 것인데,
이는 PK가 클러스터 인덱스로 조회 시작 지점을 빠르게 찾을 수 있다.
querydsl 코드에서 offset 을 제거하고 where절에 roomId보다 작은 값들을 찾으면 된다.
여기서 작은 값인 이유는 해당 정보가 id에 대하여 내림차순으로 정렬되어있기 때문이다.
아래는 NoOffset을 적용하여 변경된 코드이다.
public Slice<RoomSearchResponseDto> findRoomCustom(RoomSearchRequestDto req, Pageable pageable) {
List<RoomSearchResponseDto> content = jpaQueryFactory.select(Projections.constructor(RoomSearchResponseDto.class,
room.id,
member.memberId,
member.nickname,
room.title,
room.description,
room.link,
room.roomImage,
room.mcount,
room.capacity,
room.isLocked,
room.password,
room.constraints,
room.type, room.createdAt)).distinct().
from(room)
.innerJoin(member).on(room.manager.memberId.eq(member.memberId))
.leftJoin(roomKeyword).on(roomKeyword.room.eq(room))
.leftJoin(keyword).on(roomKeyword.keyword.eq(keyword))
.where(
ltRoomId(req.getPrevRoomId()),
eqKeyword(req.getSearchKeyword()),
isLocked(req.getIsLocked()),
eqConstraints(req.getConstraints()),
eqKeywordIds(req.getKeywordIds()),
eqType(req.getType()),
btwMcount(req.getMinMcount(), req.getMaxMcount()),
btwCapacity(req.getMinCapacity(), req.getMaxCapacity()))
.orderBy(room.id.desc()).
limit(pageable.getPageSize() + 1).
fetch();
boolean hasNext = content.size() > pageable.getPageSize();
content = hasNext ? content.subList(0, pageable.getPageSize()) : content;
return new SliceImpl<>(content, pageable, hasNext);
}
private BooleanExpression ltRoomId(Long prevRoomId) {
if (prevRoomId == null) return null;
return room.id.lt(prevRoomId);
}BooleanExpression을 주어서 직전 페이지의 마지막 MemberId가 존재했다면 그 값을 받아와서 offset 대신 where 절 조건으로 활용하였다.
BooleanExpression에 대한 설명은 뒤에 나오니 참고해주기 바란다.
동일하게 NoOffset을 적용한 getFollowers 메서드로 간단한 테스트를 해보자.
아래는 한 멤버를 팔로우하는 팔로워 정보를 페이징하는 메서드이다.
noOffset을 적용하기 전 후의 성능차이를 비교해보자.
@Override
public Slice<MemberSimpleResponseDto> getFollowers(Pageable pageable, String memberId, String prevMemberId) {
List<MemberSimpleResponseDto> content = jpaQueryFactory.select(Projections.constructor(MemberSimpleResponseDto.class,
member.memberId,
member.nickname,
member.profileImage,
member.feature
)).from(follow)
.join(member)
.on(follow.from.eq(member))
.where( gtMemberId(memberId), // noOffset 적용
follow.to.memberId.eq(memberId)
)
.limit(pageable.getPageSize()+1)
.fetch();
boolean hasNext = content.size() > pageable.getPageSize(); // 뒤에 더 있는지 확인
content = hasNext ? content.subList(0, pageable.getPageSize()) : content; // 뒤에 더 있으면 1개 더 가져온거 빼고 넘긴다
return new SliceImpl<>(content, pageable, hasNext);
}
private BooleanExpression gtMemberId(String prevMemberId) {
if (prevMemberId == null) return null; // prevMember가 주어지지 않으면 null로 where 조건 무시됨
return member.memberId.gt(prevMemberId); //마지막으로 리턴된 prevMemberId 다음부터 탐색
}⌨️ 테스트 코드
매우 간단하게 System.currentTimeMillis()로 검사하였다. 유저당 팔로우 수를 10000명으로 설정하여 테스트하였다.
@Test
@Transactional
void noOffset(){
Long srt = System.currentTimeMillis();
Slice<MemberSimpleResponseDto> legacy = followService.getFollower(FollowerRequestDto.builder().pageNo(99).pageSize(100).build(), "멤버10000");
log.info("legacy : {}",System.currentTimeMillis() - srt);
assertThat(legacy.getContent().size()).isEqualTo(100);
Long srt2 = System.currentTimeMillis();
Slice<MemberSimpleResponseDto> noOffset = followService.getFollower(FollowerRequestDto.builder().pageNo(99).pageSize(100).prevMemberId("멤버9801").build(), "멤버10000");
log.info("noOffset : {}",System.currentTimeMillis() - srt2);
assertThat(noOffset.getContent().size()).isEqualTo(100);
}⌨️ 테스트 결과
2024-01-23T16:23:45.197+09:00 INFO 16816 --- [ main] c.a.c.member.service.FollowServiceTest : legacy : 482ms
2024-01-23T16:23:45.199+09:00 INFO 16816 --- [ main] c.a.c.member.service.FollowServiceTest : noOffset : 2ms 정밀한 결과는 절대 아니지만, 아래 결과를 보면 약 240배 가량 성능이 개선된 것을 확인할 수 있다.
이는 pk 기준으로 제일 뒤의 값을 조회하였음으로 더욱 크게 성능차이가 날 수 있다.
📌 2. 다이나믹 쿼리 BooleanBuilder → BooleanExpression 로 수정하기
Querydsl에서는 where 조건문에 파라미터가 null이라면 조건절에서 무시된다.
이를 활용하여 다이나믹 쿼리를 작성할 수 있는데 방법은 크게 2가지가 있다.
1. BooleanBuilder
2. BooleanExpression
BooleanBuilder는 if문으로 필요한 부분을 추가하는 방식으로 마이바티스에서 자주 사용하는 방법과 유사하다.
그러나 가독성 방면에서는 BooleanExpression이 유리하기 때문에 해당 방법으로 코드를 리팩토링해보았다.
⌨️ BooleanBuilder (기존 코드)
List<RoomSearchResponseDto> content = jpaQueryFactory.select(Projections.constructor(RoomSearchResponseDto.class,
room.id,
member.memberId,
member.nickname,
room.title,
room.description,
room.link,
room.roomImage,
room.mcount,
room.capacity,
room.isLocked,
room.password,
room.constraints,
room.type)).distinct().
from(room)
.innerJoin(member).on(room.manager.memberId.eq(member.memberId))
.leftJoin(roomKeyword).on(roomKeyword.room.eq(room))
.leftJoin(keyword).on(roomKeyword.keyword.eq(keyword))
**.where(makeBooleanBuilder(req))**
.orderBy(makeOrder(req)).
offset(pageable.getOffset()).
limit(pageable.getPageSize() + 1). // 1개를 더 가져온다
fetch();private BooleanBuilder makeBooleanBuilder(RoomSearchRequestDto req) {
BooleanBuilder builder = new BooleanBuilder();
if (req.getSearchKeyword() != null) {
builder.andAnyOf(
room.title.contains(req.getSearchKeyword()),
room.description.contains(req.getSearchKeyword())
);
}
if (req.getIsLocked() != null)
builder.and(room.isLocked.eq(req.getIsLocked()));
if (req.getMinMcount() != null || req.getMaxMcount() != null) {
builder.and(room.mcount.between(req.getMinMcount(), req.getMaxMcount()));
}
if (req.getMinCapacity() != null || req.getMaxCapacity() != null) {
builder.and(room.capacity.between(req.getMinCapacity(), req.getMaxCapacity()));
}
if (req.getConstraints() != null && !req.getConstraints().isEmpty())
builder.and(room.constraints.in(req.getConstraints()));
if (req.getType() != null)
builder.and(room.type.eq(req.getType()));
if (req.getKeywordIds() != null && req.getKeywordIds().size() > 0){
builder.and(roomKeyword.keyword.id.in(req.getKeywordIds()));
}
return builder;
}⌨️ BooleanExpression (변경 코드)
위 메서드에서 변경된 부분만 가져왔다.
BooleanExpression을 반환하는 메서드명으로 한눈에 where 조건을 확인할 수 있다.
BooleanExpression이 null인 경우 where에서 조건검사시 무시함으로 보다 가독성 좋게 동적쿼리를 작성할 수 있다.
.where(eqKeyword(req.getSearchKeyword()),
isLocked(req.getIsLocked()),
eqConstraints(req.getConstraints()),
eqKeywordIds(req.getKeywordIds()),
eqType(req.getType()),
btwMcount(req.getMinMcount(), req.getMaxMcount()),
btwCapacity(req.getMinCapacity(), req.getMaxCapacity()))
...private BooleanExpression eqKeyword(String keyword){
if(StringUtils.isEmpty(keyword)) return null;
return room.title.contains(keyword)
.or(room.description.contains(keyword));
}
private BooleanExpression isLocked(Boolean isLocked){
if(isLocked == null) return null;
return room.isLocked.eq(isLocked);
}
private BooleanExpression btwMcount(Integer min, Integer max){
if(min == null && max == null) return null;
if (min == null) return room.mcount.lt(max);
if (max == null) return room.mcount.gt(min);
return room.mcount.between(min, max);
}
private BooleanExpression btwCapacity(Integer minCapacity, Integer maxCapacity){
if(minCapacity == null && maxCapacity == null) return null;
if (minCapacity == null) return room.capacity.lt(maxCapacity);
if (maxCapacity == null) return room.capacity.gt(minCapacity);
return room.capacity.between(minCapacity, maxCapacity);
}
private BooleanExpression eqConstraints(List<RoomConstraints> constraints){
if(constraints == null || constraints.isEmpty()) return null;
return room.constraints.in(constraints);
}
private BooleanExpression eqType(RoomType type){
if(type == null) return null;
return room.type.eq(type);
}
private BooleanExpression eqKeywordIds(List<Long> keywordIds){
if(keywordIds == null || keywordIds.isEmpty()) return null;
return roomKeyword.keyword.id.in(keywordIds);
}참조
https://www.youtube.com/watch?v=zMAX7g6rO_Y&t=3s
https://jojoldu.tistory.com/528
https://docs.spring.io/spring-data/jpa/reference/jpa.html
https://www.youtube.com/watch?v=rYj8PLIE6-k&t=5s
https://jojoldu.tistory.com/394
