
bouquet 동적쿼리 작성중에 검색 조건에 에 해당하는 꽃을 가져오는 과정에서 겪은 문제와 해결 방법을 남겨본다. 이 방법이 모든 서비스에 범용적으로 적용되는 방법은 아니나, 서비스의 특성을 고려하며 구상한 방법임을 염두해주시길 바란다 :)
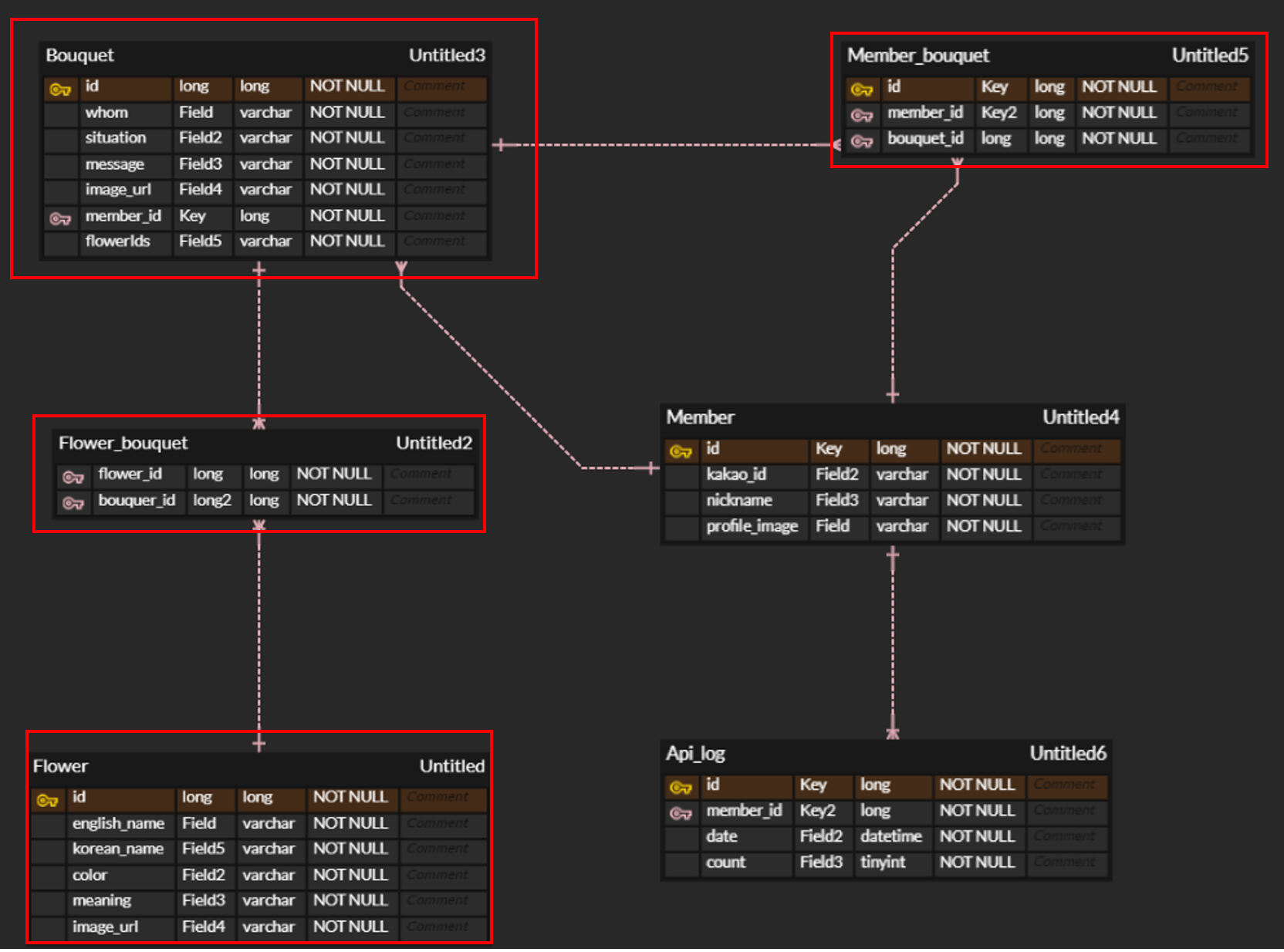
간단한 서비스 설명
사용자가 전달하고 싶은 메세지를 전달하면, 이를 반영하여 적절한 꽃말을 가진 꽃다발을 만들어주는 서비스를 기획했다. 이 때, 꽃다발은 최대 3개의 꽃 종류가 포함될 수 있다.
다른 사람들이 만든 꽃다발 리스트를 검색하는 쿼리를 작성하는 도중 문제상황을 마주했다.
문제 상황
-
검색 조건에 맞는 꽃다발이 아닌, 꽃을 가져오는 문제
-
bouquet 검색 조건이 flower임으로 flower를 join해야 했는데, 단순하게 flower.koreanName.contains(searchKeyword)이라고 해버리면 아래와 같은 문제가 발생한다
-
해당 키워드(searchKeyword)를 가진 꽃을 가진 “꽃다발”을 가져오는 것이 아닌, 검색조건을 만족하는 “꽃다발과 꽃” 정보를 담은 레코드를 가져오게 된다. 따라서 꽃다발이 1번이고 이를 이루는 꽃이 2,3,4인데 검색 조건에 해당하는 꽃이 2,4번이면 3번 꽃에 대한 정보는 가져오지 못하게 된다.
-
-
페이징 & 쿼리 수 문제
-
정확한 페이징을 위해서는 bouquet 엔티티를 가져와야 했는데, 이럴 경우 모든 bouquet 엔티티마다 해당하는 꽃 id를 가져오기 위해 별도 쿼리를 select한 엔티티 수 만큼 날려야 했다.
-
원래는 bouquet 테이블에 필드로 꽃 id를 비정규화하여 가지고 있을까까지 생각했으나, 어자피 검색 조건에 꽃의 정보가 들어가있기 때문에 join되는 레코드 수를 줄이기 위해 꽃 id만 가지는 것은 무의미하다고 판단했다.
-
또한 정보의 불일치가 있을 수도 있으며, 최대한 SQL문과 알고리즘으로 해결하고자 했다.
-
해결 방법
-
서브 쿼리 사용하여 해결
-
알고리즘으로 해결
-
bouquet - flowerId 정보를 모두 가진 dto를 가져오도록 하되 꽃다발당 최대 3개의 꽃만 들어있다는 점을 이용하여 페이지 사이즈 * 3의 레코드 가져와 어플리케이션 내에서 직접 페이징
-
lastIndex 필드 사용하여 다음 요청 시 (무한스크롤) 정확한 offset을 주어 다음 데이터 가져올 수 있도록함
-
hasNext도 구현
-
위 방법으로 추가 쿼리를 날리지 않고 한방쿼리로 페이지네이션 해결
-
전체 쿼리
@Override
public BouquetSliceResponse searchRelevantBouquet(BouquetListRequestDto req, Pageable pageable) {
JPAQuery<BouquetFlowerDto> query = jpaQueryFactory
.select(Projections.constructor(
BouquetFlowerDto.class,
bouquet.member.memberId,
bouquet.bouquetId,
bouquet.whom,
bouquet.situation,
bouquet.message,
bouquet.imageUrl,
bouquet.createDateTime,
flowerBouquet.flower.flowerId))
.from(bouquet)
.leftJoin(bouquet.flowerBouquets, flowerBouquet)
// 여기서 flowerBouquet.flower join할 필요 없다 (id만 필요하니까)
.leftJoin(bouquet.memberBouquets, memberBouquet).distinct()
.where(eqKeyword(req));
switch (req.getOrderBy()) {
case LIKE:
// flowerId도 PK임으로 groupBy 조건에 넣어줘야함
query.groupBy(bouquet.bouquetId, flowerBouquet.flower.flowerId)
.orderBy(memberBouquet.bouquet.count().desc(), bouquet.createDateTime.desc());
break;
case RECENT:
query.orderBy(bouquet.createDateTime.desc());
break;
default:
query.orderBy(bouquet.createDateTime.desc());
}
int pageSize = pageable.getPageSize();
List<BouquetFlowerDto> content =
query.offset(req.getLastIndex())
.limit(pageSize * MAX_FLOWER_COUNT + 1)
.fetch();
return makeResponse(content, req, pageable);
}
private BouquetSliceResponse makeResponse(List<BouquetFlowerDto> content, BouquetListRequestDto req, Pageable pageable) {
List<BouquetSearchDto> list = new ArrayList<>();
int count = 0;
for (BouquetFlowerDto dto : content) {
log.info("bouquet Id : {}", dto.getBouquetId());
if (!makeBouquet(dto, pageable.getPageSize(), list)) break;
count++;
log.info("count : {}", count);
}
boolean hasNext = content.size() >= count;
int lastindex = req.getLastIndex() + count;
return new BouquetSliceResponse(new SliceImpl<>(list, pageable, hasNext), lastindex);
}
// Response에 담을 BouquetDto를 만든다
public boolean makeBouquet(BouquetFlowerDto dto, int pageSize, List<BouquetSearchDto> list) {
// 새로운 bouquet Id면 페이지 사이즈보다 크지는 않은지 확인하고
// 이미 존재하는 bouquet Id면 flowerIds list에 꽃 id만 추가만 해준다
BouquetSearchDto innerBouquet = null;
for (BouquetSearchDto bouquet : list) {
if (Objects.equals(bouquet.getBouquetId(), dto.getBouquetId())) {
innerBouquet = bouquet;
break;
}
}
if (innerBouquet == null) {
if (list.size() >= pageSize) return false;
list.add(new BouquetSearchDto(dto));
} else {
innerBouquet.addFlowerId(dto);
}
return true;
}
private BooleanExpression eqKeyword(BouquetListRequestDto req) {
if (req.getType() == null) return null;
return switch (req.getType()) {
case NAME -> bouquet.bouquetId.in(JPAExpressions
.select(bouquet.bouquetId).distinct()
.from(bouquet)
.leftJoin(bouquet.flowerBouquets, flowerBouquet)
.where(flowerBouquet.flower.flowerId.in(
JPAExpressions
.select(flower.flowerId)
.from(flower)
.where(flower.koreanName.contains(req.getSearchKeyword())))));
case MEANING -> bouquet.bouquetId.in(JPAExpressions
.select(bouquet.bouquetId).distinct()
.from(bouquet)
.leftJoin(bouquet.flowerBouquets, flowerBouquet)
.where(flowerBouquet.flower.flowerId.in(
JPAExpressions
.select(flower.flowerId)
.from(flower)
.where(flower.meaning.contains(req.getSearchKeyword())))));
case TEXT -> bouquet.whom.contains(req.getSearchKeyword())
.or(bouquet.situation.contains(req.getSearchKeyword()))
.or(bouquet.message.contains(req.getSearchKeyword()));
};
}Join
- join 과정에서 flower의 PK만 필요하지 다른 정보가 필요하지 않기 때문에 flowerBouqet과 flower를 join하지 않았다.
JPAQuery<BouquetFlowerDto> query = jpaQueryFactory
.select(Projections.constructor(
BouquetFlowerDto.class,
bouquet.member.memberId,
bouquet.bouquetId,
bouquet.whom,
bouquet.situation,
bouquet.message,
bouquet.imageUrl,
bouquet.createDateTime,
flowerBouquet.flower.flowerId))
.from(bouquet)
.leftJoin(bouquet.flowerBouquets, flowerBouquet)
// 여기서 flowerBouquet.flower join할 필요 없다 (id만 필요하니까)
.leftJoin(bouquet.memberBouquets, memberBouquet).distinct()
.where(eqKeyword(req));Where
-
기존 방식으로 그냥 flower의 꽃말이나 꽃 이름만을 비교하면 해당 키워드를 가진 꽃을 가진 “꽃다발”을 가져오는 것이 아닌, 검색조건을 만족하는 “꽃다발과 꽃” 정보를 담은 레코드를 가져오게 된다.
-
따라서 꽃다발이 1번이고 이를 이루는 꽃이 2,3,4인데 검색 조건에 해당하는 꽃이 2,4번이면 3번 꽃에 대한 정보는 가져오지 못하게 된다.
bouquetId || flowerId
1 2 (검색조건 만족)
1 3 (검색조건 불만족) => 못가져옴
1 4 (검색조건 만족)의도한 결과 : bouquetId : 1, flowerId : 2,3,4
실제 결과 : bouquetId : 1, flowerId : 2,4- subQuery를 사용하여 검색 조건에 해당하는 flowerId 들에 해당하는 bouquetId 들에 해당하는 bouquet들만 가져오도록 하였다. 즉 서브쿼리가 2번 발생하게 됨으로 실제로는 쿼리가 3번 발생하는 것이다!
- 참고로 서브쿼리에서 쓰는 “flower”는 위에 join 문에서 사용한 alias가 아니다.
case NAME -> bouquet.bouquetId.in(JPAExpressions
.select(bouquet.bouquetId).distinct()
.from(bouquet)
.leftJoin(bouquet.flowerBouquets, flowerBouquet)
.where(flowerBouquet.flower.flowerId.in(
JPAExpressions
.select(flower.flowerId)
.from(flower)
.where(flower.koreanName.contains(req.getSearchKeyword())))));
Ordering
-
like를 groupBy로 orderBy하기 위해서는 bouquetId와 flowerId 모두 기준으로 groupBy 해주어야 한다.
-
이후 memberBouquet의 count 기준으로 desc 해주면 다운로드 순으로 정렬할 수 있게 된다!
switch (req.getOrderBy()) {
case LIKE:
// flowerId도 PK임으로 groupBy 조건에 넣어줘야함
query.groupBy(bouquet.bouquetId, flowerBouquet.flower.flowerId)
.orderBy(memberBouquet.bouquet.count().desc(), bouquet.createDateTime.desc());
break;
case RECENT:
query.orderBy(bouquet.createDateTime.desc());
break;
default:
query.orderBy(bouquet.createDateTime.desc());
}Pagination
보통의 정상적인 방법으로 하지는 않았다.
이유는 뽑은 부케마다 꽃정보를 확인하기 위해 쿼리문을 1개씩 추가로 날리고 싶지 않았기 때문.
따라서 방법은 아래와 같다.
구현 방법은 아래와 같다
-
꽃다발에 사용되는 꽃의 갯수는 최대 3개이다.
-
따라서 꽃다발을 페이지 수(여기서는 4개로 설정한다면)만큼 요청하게 되면 여기에 사용될 꽃의 갯수는 12개이다.
-
따라서 꽃다발 - 꽃의 조인된 레코드를 13개 가져오면 무조건 꽃다발은 페이지 수보다 많은 5개 이상일 것이다 ⇒ hasNext 확인 가능
(이를 순회하면서 꽃다발의 id 종류가 페이지 수를 넘게 되면 hasNext가 성립하게 된다)
-
리스트를 순회하면서 새로운 꽃다발 id가 나오면 리스트에 꽃다발 dto를 넣고, 여기에 flowerId 필드에 리스트 형태로 저장한다. 만약 기존에 있는 꽃다발 id가 나오면 기존 dto의 flowerId 필드(리스트)에 추가해준다.
-
이 값을 slice에 넣어주고 지금까지 dto로 변환한 꽃다발 - 꽃 레코드의 갯수를 lastIndex 값에 추가해준다.
-
이렇게 되면 다음 요청시 lastIndex부터 offset으로 탐색할 수 있게 된다!
- No Offset은 불가능한가? 불가능하다! ⇒ 정렬 조건이 기본적으로는 PK 내림차순(createDateTime 내림차순임으로 결과적으로 동일)이기는 한 LIKE 순으로 정렬되는 것이 우선될 수 있기 때문이다!
int pageSize = pageable.getPageSize();
List<BouquetFlowerDto> content =
query.offset(req.getLastIndex())
.limit(pageSize * MAX_FLOWER_COUNT + 1)
.fetch();private BouquetSliceResponse makeResponse(List<BouquetFlowerDto> content, BouquetListRequestDto req, Pageable pageable) {
List<BouquetSearchDto> list = new ArrayList<>();
int count = 0;
for (BouquetFlowerDto dto : content) {
log.info("bouquet Id : {}", dto.getBouquetId());
if (!makeBouquet(dto, pageable.getPageSize(), list)) break;
count++;
log.info("count : {}", count);
}
boolean hasNext = content.size() >= count;
int lastindex = req.getLastIndex() + count;
return new BouquetSliceResponse(new SliceImpl<>(list, pageable, hasNext), lastindex);
}
// Response에 담을 BouquetDto를 만든다
public boolean makeBouquet(BouquetFlowerDto dto, int pageSize, List<BouquetSearchDto> list) {
// 새로운 bouquet Id면 페이지 사이즈보다 크지는 않은지 확인하고
// 이미 존재하는 bouquet Id면 flowerIds list에 꽃 id만 추가만 해준다
BouquetSearchDto innerBouquet = null;
for (BouquetSearchDto bouquet : list) {
if (Objects.equals(bouquet.getBouquetId(), dto.getBouquetId())) {
innerBouquet = bouquet;
break;
}
}
if (innerBouquet == null) {
if (list.size() >= pageSize) return false;
list.add(new BouquetSearchDto(dto));
} else {
innerBouquet.addFlowerId(dto);
}
return true;
}쿼리 결과를 확인해보면 잘 가져온다!!
bouquet/list?type=MEANING&searchKeyword=사랑&orderBy=LIKE{
"slice": {
"content": [
{
"bouquetId": 6,
"whom": "사랑하는 남편에게",
"situation": "결혼기념일 5주년",
"message": "우리 앞으로도 남은 시간 함께 잘 살자. 사랑해",
"imageUrl": null,
"memberId": 1,
"flowerId": [
2,
9,
7
]
},
{
"bouquetId": 4,
"whom": "여자친구에게",
"situation": "100일",
"message": "사랑의 메시지를 전하고싶어",
"imageUrl": null,
"memberId": 1,
"flowerId": [
4,
14,
2
]
},
{
"bouquetId": 3,
"whom": "동생",
"situation": "생일",
"message": "축하",
"imageUrl": "testUrl",
"memberId": 1,
"flowerId": [
13,
9,
10
]
},
{
"bouquetId": 2,
"whom": "친구",
"situation": "졸업",
"message": "고생했어",
"imageUrl": "testUrl",
"memberId": 1,
"flowerId": [
2,
1,
6
]
}
],
"pageable": {
"pageNumber": 0,
"pageSize": 4,
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"offset": 0,
"paged": true,
"unpaged": false
},
"size": 4,
"number": 0,
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"numberOfElements": 4,
"first": true,
"last": false,
"empty": false
},
"lastIndex": 12
}이후에는 이 쿼리의 성능 테스트를 진행하고 그 내용을 공유해보고자 한다 :)
참고 자료
