
면접 단골 질문인 브라우저에 URL 입력시 어떻게 되는지에 대한 답변을 정리해보자.
자세한 내용보다는 흐름 중심으로 작성해보았다.
그러면 레츠고!
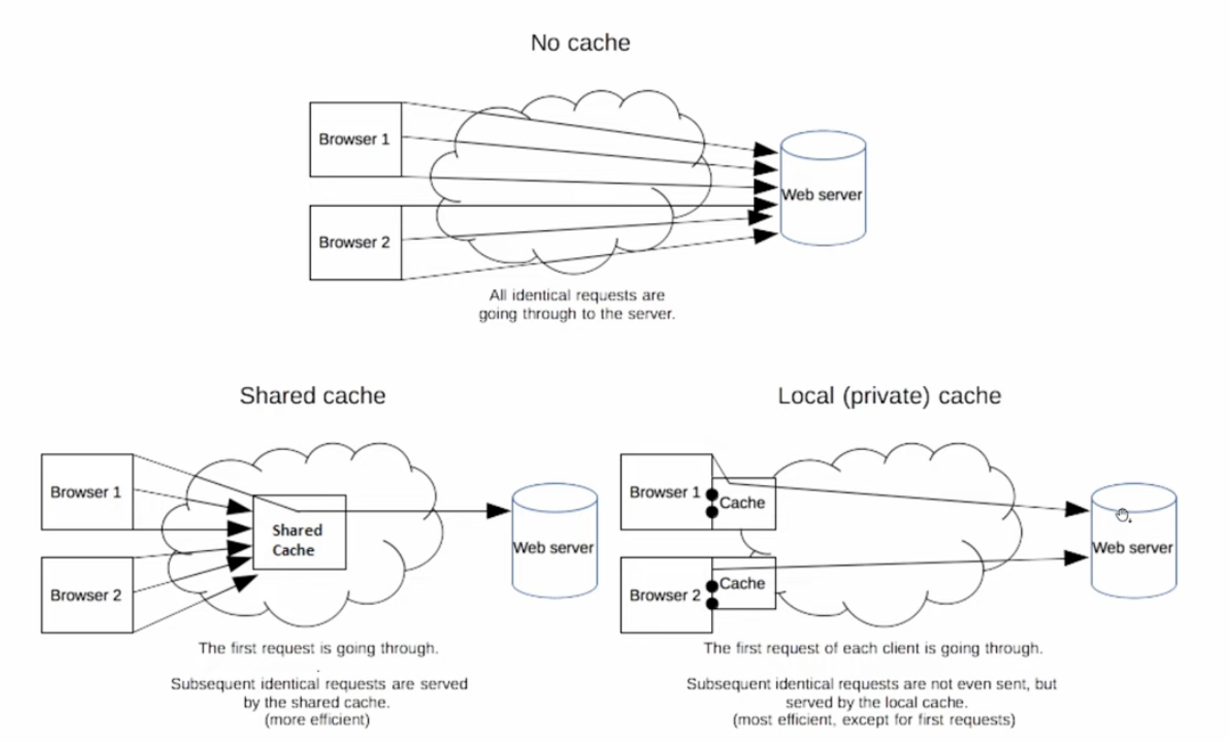
1. Redirect & Cache
- 우선 리다이렉트 여부 확인하여 필요시 해당 위치로 리다이렉트
- 캐시에 데이터가 있는지 확인
- 브라우저 캐시 (쿠키, 로컬/세션 스토리지 등을 포함한 브라우저에 저장된 private 캐시)
- 공유 캐시 (보통 리버스 프록시 서버 - Nginx)
2. DNS 질의 전 (DNS Cache)
-
필요없는 DNS 통신을 피하기 위해 OS는 host 파일과 캐시를 먼저 확인해본다.
-
hosts 파일을 가장 먼저 찾아봄
- 호스트 파일에 이미 서버의 이름과 IP주소가 존재하면 네임서버에 질의 X
- 이러한 호스트 파일을 해킹해 가짜 사이트로 유도되는 공격도 있음 (Pharming)
-
OS가 로컬 PC의 DNS Cache 를 먼저 확인해본다. IP가 있으면 질의 X
- ipconfig/displaydns
- linux은 nslookup
-
브라우저에도 DNS Cache가 있다
- chrome://net-internals/#dns
- chrome://net-internals/#dns
-
3. DNS 질의
- hosts 파일, 캐시에 모두 도메인네임에 대한 IP가 없는 경우 DNS 통신을 통해 IP를 알아온다.
- FQDN (Fully Qualified Domain Name)
www : 호스트, naver.com : 도메인 - www.naver.com을 입력하면 naver.com 도메인에 속해있는 이름이 www인 컴퓨터의 인터넷 망에 접속하기 위해서는 IP 주소를 알아야 한다
- DNS는 분산형 DB 구조 (+ DDNS)
4. IP 라우팅
- 해당 IP를 기반으로 라우팅
- ARP 과정을 거쳐 실제 서버를 찾음
4. IP 주소로 TCP 연결을 함
- HTTP 통신은 TCP 기반으로 함 (3-way handshake)
5. HTTP 연결하여 콘텐츠 다운로드
- URL 입력시부터 여기까지가 TTFB (Time To First Byte)
6. 브라우저 렌더링
위 내용이 질문에 대한 간단한 흐름이다. 여기서 더 나아가서 CDN과 GSLB에 대해서도 알아보자.
-
CDN (Contents Delivery Network)
- 지리적으로 분산된 여러개의 서버
- 정적 컨텐츠를 사용자 위치 기반 가까운 곳에서 전송함므로써 전송 속도를 높이는 개념 ⇒ 대용량일수록 필요!
- CDN서버는 원본 서버의 정적 파일 복사본들을 캐싱해 놓고 있다
- 방법
- 분산형 DB에 접속자 IP를 저장하여 접속자의 위치를 역추적할 수 있다 (서울이구나!)
- 이 위치를 기반으로 www.naver.com을 사용하기 가장 가까운 서버 IP 주소를 알려준다
- 즉, naver 서버는 1개가 아니라 N 개이다
- 전세계에 네이버 서버는 N개가 있다
- 사용자의 위치에 따라 응답성이 높은 서버로 맵핑 시켜줘야한다
- 캐싱 방법
- static caching (미리 origin 서버의 리소스를 복사, 요청시 무조건 CDN 서버에서 리소스 제공)
- dynamic caching (TTL이 지난 뒤에도 사용이 없으면 리소스 삭제)
- 제공 업체
- Akamai, KT
-
GSLB (Global Server Load Balancing)
- DNS의 발전된 형태
- 왜 쓰는가? ⇒ DNS가 못하는걸 해준다
- 서버의 상태를 알아서 정상적으로 작동하는 서버를 찾아낸다 (Health Check)
- DNS와 같이 Round Robin 형식으로 로드밸런싱을 하나 서버의 트래픽을 분석하면서 지리적으로 근접한 서버를 찾아내어 부하를 분산한다
- 어떻게 구현? 제일 쉬운게 DNS 역할을 하는 시스템을 만듬
- Health Check / FailOver
- 서울 서버가 맛이 갔어! 그러면 부산 서버 IP를 알려준다!
- 사용자는 서버에 문제가 생긴 줄 모른다
- 트래픽이 높으면 다른 곳으로 로드 밸런싱도 해줄 수 있다
- 그러면 로그인 된 상태에서 서울 서버가 다운되어 부산 서버 IP를 제공받게 되었다면, 로그인 세션은 어떻게 유지되는가?
- 고민해봐야 할 문제로군요..
- Health Check / FailOver
-
DNS spoofing?
- 공격대상에게 전달되는 DNS IP 주소를 조작하거나 DNS 서버의 캐시 정보를 조작하여 의도하지 않은 주소로 접속하게 만드는 공격
- 정상적인 URL로 접속해도 가짜 사이트로 들어가게 됨
- 방법
- 스니핑 : DNS 질의에 대한 응답이 오기 전에 가짜 응답을 보내어 실제 응답은 폐기가 됨
- 대응책
- 스니핑 탐지 및 차단
- 중요 사이트의 IP는 hosts 파일에 등록 (DNS보다 우선순위)
참고 사이트

향유하는 개발자