<목차>
1.group by 를 이용한 집계
2.rollup 을 이용한 집계
3.cube 를 이용한 집계
4.grouping sets 를 이용한 집계
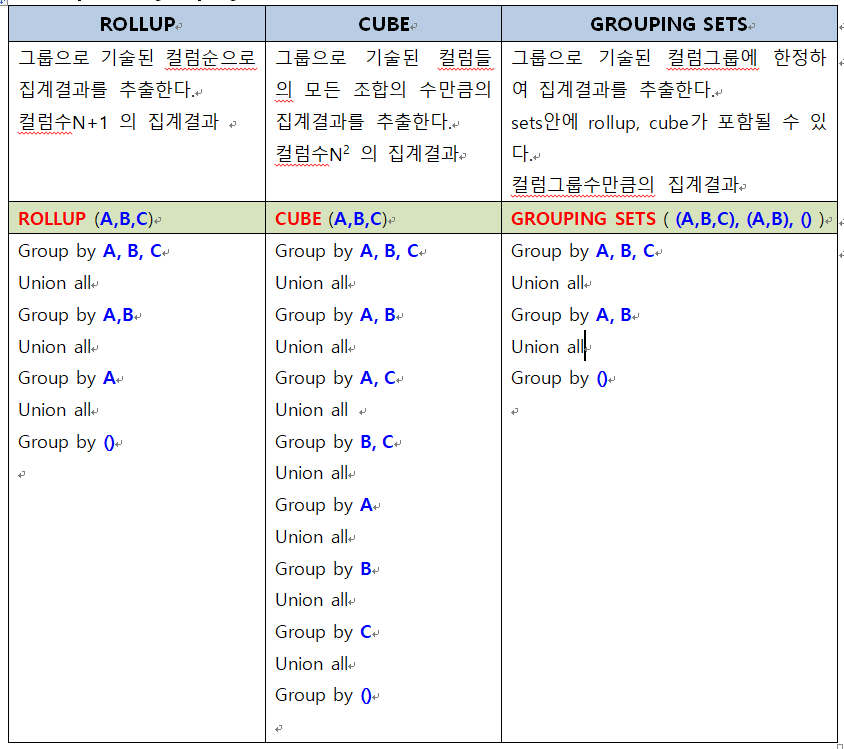
5.rollup-cube-grouping sets 비교
6.pivot
7.unpivot
집계함수[AVG(), COUNT(), MAX(), MIN() and SUM()]를 이용하여 집계정보를 표현시 여러가지 방법으로 구현할 수 있는데 DBMS에서 제공하는 각 함수별 특징을 이용하여 원하는 형태의 집계를 적절하게 구현할 수 있도록 살펴보자
예제를 ORACLE에서 직접수행하기 위하여 간단한 데이터를 만들어본다.
CREATE TABLE sales (
sale_id INT PRIMARY KEY,
sale_date DATE,
product_id VARCHAR(10),
sales_amount DECIMAL(10, 2)
);
INSERT INTO sales (sale_id, sale_date, product_id, sales_amount) VALUES (1, '2023-01-15', 'A', 1000.00);
INSERT INTO sales (sale_id, sale_date, product_id, sales_amount) VALUES (2, '2023-02-20', 'B', 1500.00);
INSERT INTO sales (sale_id, sale_date, product_id, sales_amount) VALUES (3, '2023-03-10', 'A', 800.00);
INSERT INTO sales (sale_id, sale_date, product_id, sales_amount) VALUES (4, '2023-04-05', 'C', 1200.00);
1.group by 를 이용한 집계
-설명 : 테이블 T의 컬럼중에서 c1,c2,c3를 그룹으로 집계한다.
group by 를 이용하면 웬만한 집계정보는 구현할 수 있다.
개인적으로는 rollup,cube보다는 더 많이 사용하고 있는데 활용하기에 따라서 필요한 형태로 가공이 쉬운 장점이 있다.

select col1, col2,
sum(decode(substr(bill_month,-2),'01', bill_amt)) as M01,
...
sum(decode(substr(bill_month,-2),'12', bill_amt)) as M12
from table_name
where col3 = '조건'
and bill_month between '202301' and '202312'
group by col1, col2
order by col1, col2
;위 쿼리는 2023년의 월별 매출을 집계하는 간단한 쿼리이다.
아래는 실제 쿼리를 만들어보았다.
select PRODUCT_ID,
sum(decode(to_char(sale_date,'MM'),'01', SALES_AMOUNT)) as M01,
sum(decode(to_char(sale_date,'MM'),'02', SALES_AMOUNT)) as M02,
sum(decode(to_char(sale_date,'MM'),'03', SALES_AMOUNT)) as M03,
sum(decode(to_char(sale_date,'MM'),'04', SALES_AMOUNT)) as M04,
sum(decode(to_char(sale_date,'MM'),'05', SALES_AMOUNT)) as M05,
sum(decode(to_char(sale_date,'MM'),'06', SALES_AMOUNT)) as M06,
sum(decode(to_char(sale_date,'MM'),'07', SALES_AMOUNT)) as M07,
sum(decode(to_char(sale_date,'MM'),'08', SALES_AMOUNT)) as M08,
sum(decode(to_char(sale_date,'MM'),'09', SALES_AMOUNT)) as M09,
sum(decode(to_char(sale_date,'MM'),'10', SALES_AMOUNT)) as M10,
sum(decode(to_char(sale_date,'MM'),'11', SALES_AMOUNT)) as M11,
sum(decode(to_char(sale_date,'MM'),'12', SALES_AMOUNT)) as M12
from sales
where to_char(sale_date,'YYYYMM') between '202301' and '202312'
group by PRODUCT_ID
order by PRODUCT_ID
;
간단히 월별 합계를 내고자 한다면 아래쪽에서 배우게 될 grouping sets를 이용하여 "()" 를 추가만하면 된다.
group by grouping sets ( PRODUCT_ID, () )
2.rollup 을 이용한 집계

SELECT to_char(sale_date,'YYYY') AS sales_year,
to_char(sale_date,'MM') AS sales_month,
product_id,
SUM(sales_amount) AS total_sales
FROM sales
GROUP BY ROLLUP ( to_char(sale_date,'YYYY'), to_char(sale_date,'MM'), product_id )
;SALES_YEAR | SALES_MONTH | PRODUCT_ID | TOTAL_SALES
-----------|-------------|------------|------------
2023 | 01 | A | 1000
2023 | 01 | NULL | 1000
2023 | 02 | B | 1500
2023 | 02 | NULL | 1500
2023 | 03 | A | 800
2023 | 03 | NULL | 800
2023 | 04 | C | 1200
2023 | 04 | NULL | 1200
2023 | NULL | NULL | 4500
NULL | NULL | NULL | 4500
3.cube 를 이용한 집계

SELECT to_char(sale_date,'YYYY') AS sales_year,
to_char(sale_date,'MM') AS sales_month,
product_id,
SUM(sales_amount) AS total_sales
FROM sales
GROUP BY CUBE ( to_char(sale_date,'YYYY'), to_char(sale_date,'MM'), product_id )
;
SALES_YEAR | SALES_MONTH | PRODUCT_ID | TOTAL_SALES
-----------|-------------|------------|------------
NULL | NULL | NULL | 4500
NULL | NULL | A | 1800
NULL | NULL | B | 1500
NULL | NULL | C | 1200
NULL | 01 | NULL | 1000
NULL | 01 | A | 1000
NULL | 02 | NULL | 1500
NULL | 02 | B | 1500
NULL | 03 | NULL | 800
NULL | 03 | A | 800
NULL | 04 | NULL | 1200
NULL | 04 | C | 1200
2023 | NULL | NULL | 4500
2023 | NULL | A | 1800
2023 | NULL | B | 1500
2023 | NULL | C | 1200
2023 | 01 | NULL | 1000
2023 | 01 | A | 1000
2023 | 02 | NULL | 1500
2023 | 02 | B | 1500
2023 | 03 | NULL | 800
2023 | 03 | A | 800
2023 | 04 | NULL | 1200
2023 | 04 | C | 12004.grouping sets 를 이용한 집계

SELECT to_char(sale_date,'YYYY') AS sales_year,
to_char(sale_date,'MM') AS sales_month,
product_id,
SUM(sales_amount) AS total_sales
FROM sales
GROUP BY GROUPING SETS ( (to_char(sale_date,'YYYY'), to_char(sale_date,'MM')),
(to_char(sale_date,'YYYY')),
(product_id),
()
)
;SALES_YEAR | SALES_MONTH | PRODUCT_ID | TOTAL_SALES
-----------|-------------|------------|------------
2023 | 01 | NULL | 1000
2023 | 02 | NULL | 1500
2023 | 03 | NULL | 800
2023 | 04 | NULL | 1200
2023 | NULL | NULL | 4500
NULL | NULL | A | 1800
NULL | NULL | B | 1500
NULL | NULL | C | 1200
NULL | NULL | NULL | 45005.rollup-cube-grouping sets 비교

() : 전체 합계를 의미합니다.
6.pivot
크로스탭 보고서를 작성하기 위해 행을 열로 전환하는 방법을 보여줍니다

Select "*" 의 "*"는 피봇처리된 컬럼들을 의미하므로 원시 table_name 에 있는 컬럼이 아니라는 것을 기억하자. 즉 집계함수결과와 pivot 대상컬럼의 결합(alias를 정의한경우)으로 이루어진 이름들 목록인것이다.
다시 말하면 최종 피봇으로 조회된 컬럼들이다.
따라서 조회시 원치않는 컬럼은 FROM절의 테이블에서 이미 서브쿼리로 정제되어 출력에 필요한 컬럼만을 조회하여야한다는 것이다. 정제하지 않으면 모든 컬럼이 출력되므로 원하는 출력이 나오질 않는다.
pivot_clause 절은 집계함수(count,sum,avg,max,min)만 기술되어야한다. 집계함수간 결합이나 NVL등으로 변형도 허용되지 않는다.
아래는 테스트를 위한 테이블생성과 데이터생성문입니다.
CREATE TABLE ORDER_STATS (
CATEGORY_NAME VARCHAR2(20),
STATUS VARCHAR2(20),
ORDER_ID NUMBER,
BILL_AMT NUMBER,
O_CNT NUMBER,
U_AMT NUMBER);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('CPU','Canceled',67,96000,3,32000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('CPU','Canceled',69,64000,2,32000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('CPU','Shipped',74,160000,5,32000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Mother Board','Shipped',75,390000,6,65000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Video Card','Pending',68,123000,3,41000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Video Card','Shipped',76,82000,2,41000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Video Card','Pending',78,410000,10,41000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Storage','Pending',91,540000,15,36000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Storage','Shipped',89,144000,4,36000);
insert into ORDER_STATS (CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT,U_AMT) values ('Shipped','Shipped',82,324000,9,36000);
SELECT *
FROM (SELECT CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT
FROM ORDER_STATS)
PIVOT(
COUNT(ORDER_ID) AS ORD
FOR CATEGORY_NAME
IN (
'CPU' CPU,
'Video Card' VideoCard,
'Mother Board' MotherBoard,
'Storage' Storage
)
)
ORDER BY STATUS
;
약어(alias)를 정의하면 헤더이름에 아래와 같은 형식으로 자동으로 표현됩니다.
pivot_in_clause alias || '-' || pivot_clause alias
이 이름들이 select 절의 * 안에 포함되는것이다. 즉, FROM 절의 테이블의 컬럼이름이 아니라는 것이다.
집계함수를 여러 개 사용하는 경우 :
SELECT *
--STATUS,CPU_ORD,CPU_CNT,CPU_AMT,VIDEOCARD_ORD--,VIDEOCARD_CNT,VIDEOCARD_AMT,MOTHERBOARD_ORD,MOTHERBOARD_CNT,MOTHERBOARD_AMT,STORAGE_ORD,STORAGE_CNT,STORAGE_AMT
FROM (select CATEGORY_NAME,STATUS,ORDER_ID,BILL_AMT,O_CNT from ORDER_STATS)
--FROM ORDER_STATS
PIVOT(
COUNT(ORDER_ID) AS ORD,
SUM(O_CNT) AS CNT,
SUM(BILL_AMT) AS AMT
FOR CATEGORY_NAME
IN (
'CPU' CPU,
'Video Card' VideoCard,
'Mother Board' MotherBoard,
'Storage' Storage
)
)
ORDER BY STATUS;원시테이블의 U_AMT컬럼은 PIVOT결과에서 포함시키지 않기 위하여
서브쿼리로 정제한 후 PIVOT을 수행하도록 하였습니다.
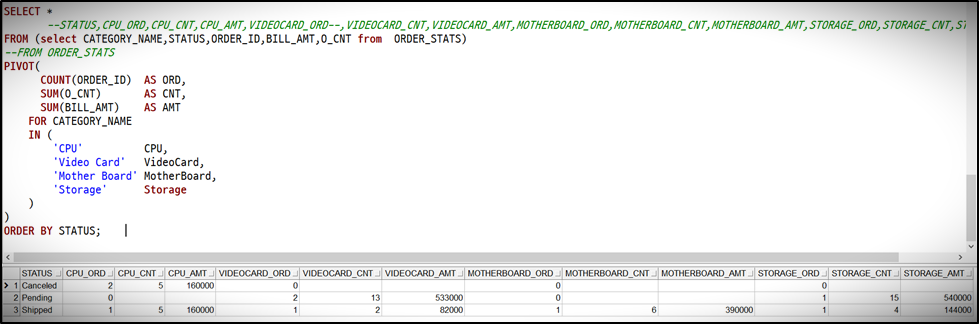
< GROUP BY 와 PIVOT 구현모습 비교>
성능은 어떨지 모르겠으나 코드의 가독성은 GROUP BY가 더 나은것으로 보입니다. 둘다 모두 열로 올릴 값을 모두 기술해줘야하는 공통점이 있습니다.

7.unpivot
열을 행으로 전환하는 방법을 보여줍니다.

아래와 같은 unpivot 대상이 있습니다.
create table order_stats_pivot as
SELECT *
FROM (select CATEGORY_NAME,STATUS,ORDER_ID
from order_stats
)
PIVOT(
COUNT(order_id) as CNT
FOR category_name
IN (
'CPU' CPU,
'Video Card' VideoCard,
'Mother Board' MotherBoard,
'Storage' Storage
)
)
ORDER BY status;이것을 unpivot으로 변환해보겠습니다.
SELECT *
FROM ORDER_STATS_PIVOT
UNPIVOT (
ORDER_CNT
FOR CATEGORY_NAME
IN (CPU_CNT AS 'CPU',
VIDEOCARD_CNT AS 'VIDEOCARD',
MOTHERBOARD_CNT AS 'MOTHORBOARD',
STORAGE_CNT AS 'STORAGE'
)
)
;

