상권데이터를 이용해 서울특별시의 각 구마다 몇 개의 치킨집이 있는지를 파악하고자 데이터 전처리하는 과정이다.
import pandas as pd
commercial = pd.read_csv('./data/commercial.csv')
1. 데이터의 컬럼명 보기
list()를 통해 데이터프레임의 컬럼명들을 알 수 있다.
list(commercial), len(list(commercial))
2. 유니크값 확인하기 groupby
'상가업소번호'가 데이터의 각 상가의 유니크값인지 확인하기 위해 상가업소번호로 groupby한 다음 다른 컬럼을 세었을 때 상가업소마다 하나씩밖에 없는지를 다음과 같이 확인한다. (강의에선 다른 컬럼으로 했는데 '경도'로 바꾸어서 해보았다)
commercial.groupby('상가업소번호')['경도'].count().sort_values(ascending=False)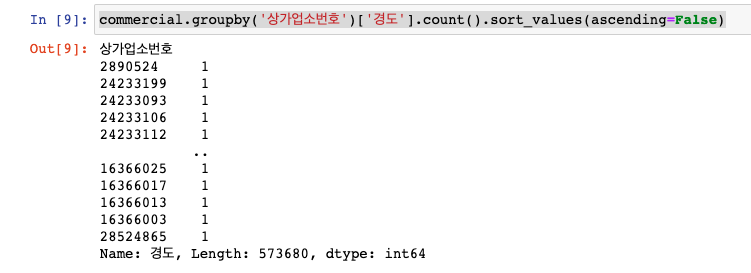
만약 유일하지 않은 값으로 groupby하여 같은 처리를 했을 경우
commercial.groupby('상권업종소분류명')['행정동명'].count().sort_values(ascending=False)
이와 같이 한식/백반/한정식에 해당하는 행정동명 데이터를 다 카운트해서 해당하는 분류명 데이터가 38133개 있음을 알 수 있다.
3. set 을 이용해 중복없이 목록보기
우리는 치킨집을 찾기 위해 '상권업종소분류명'이 어떻게 되어있는지, 그 중에 치킨집은 뭐라고 입력되어있는지 찾기 위해 상권업종소분류명을 아래와같은 방법으로 set을 이용하여 중복없이 목록으로 정리했다
category_range = set(commercial['상권업종소분류명'])
category_range, len(category_range)
무려 709개의 소분류명이 있었고, 맨 아래에서 '후라이드/양념치킨'이라는 분류명을 찾을 수 있었다.
(709개를 살펴보면서 치킨을 찾기는 어려우므로 Ctrl(command)+F 를 이용해 치킨같은 키워드를 찾자.)
4. 주소에서 '시'와 '구' 정보를 추출하기
str.split() 문자열 쪼개서 새로운 열을 생성하여 넣기
이제 우리는 서울시에 있는 치킨집들만 골라서, 자치구별로 치킨집 수를 알아보고 싶다. 그런데 우리의 로우데이터에는 딱 '시'나 '구'에 해당하는 정보가 없다. 대신 '도로명주소'와 '도로명'이라는 두개의 컬럼이 있는데, '도로명주소'는 상세주소까지, '도로명'은 광역시, 구, 도로명 까지만 정보가 들어있다. 상세주소까지는 필요없으므로 '도로명'컬럼을 가지고 주소 중 '구'에 해당하는 정보만 따로 들어있는 컬럼을 만들어보자.
commercial[['시','구','상세주소']] = commercial['도로명'].str.split(' ',n=2,expand=True)
# str.split() 을 통해 문자열을 쪼갠다.
# (*필수)첫번째 파라미터로 무엇을 기준으로 쪼갤 것인지 넣었다. ' ' 를 넣은 것은 띄어쓰기, 즉 스페이스를 기준으로 쪼개겠다는 뜻
# 두번째 파라미터로 n=2, 몇번 쪼갤지 넣었다. 두 번의 공백을 쪼개서 총 3개의 문자열로 나뉘어진다.(3개 컬럼에 나누어 넣을 것이므로 반드시 3개로 쪼개어져야함을 이 파라미터를 통해 보장해주어야하는 것 같다. 만약 n=1을 넣어 2개로 쪼갠다면 맨 앞에 서울특별시와 그 다음 전체 문자열로 나누어진다.)
# 세번째 파라미터로 넣은 expand=True 를 통해 쪼개진 문자열들을 좌측 dataFrame의 컬럼으로 바로 넣어줄 수 있게 된다고 한다.
# 그리고 쪼개진 문자열을 넣을 dataFrame의 컬럼명을 좌측에 현재 우리가 다루고 있는 dataFrame에다 list로 넣어준다.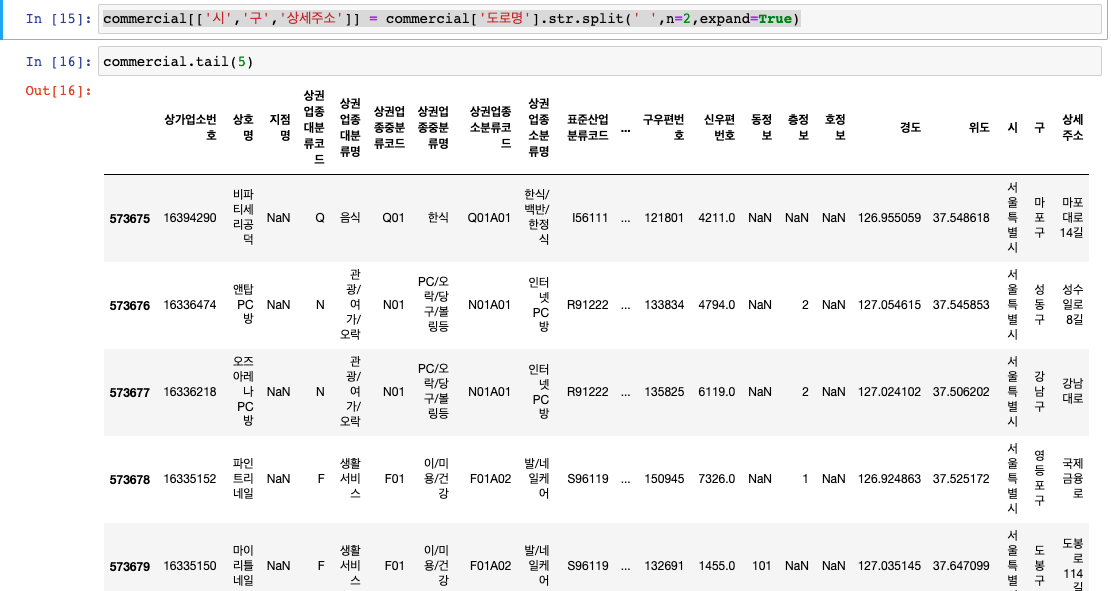
제일 오른쪽에 보면 '시', '구', '상세주소'라는 전에 없던 컬럼 3개가 생겨있고 거기에 '도로명'의 값으로 있던 문자열을 스페이스(띄어쓰기, 공백)를 기준으로 쪼갠 값들이 순서대로 하나씩 들어갔음을 볼 수 있다.
( .tail(5)는 데이터의 맨 마지막 5줄(행,row)만 출력해준다 )
5. '서울특별시' 데이터만 남기기 - 특정 조건에 해당하는 데이터만 추출하기
이제 우리는 우리 데이터에서 서울특별시에 주소지를 두고 있는 데이터만 남기려고 한다.
seoul_data = commercial[ commercial['시'] == '서울특별시']
seoul_datacommercial['시'] 를 통해 commercial이라는 data frame에서 시라는 컬럼의 값들만 가져올 수 있는데, 위와 같이 commercial[ commercial['시'] == '서울특별시'] 라고 쓰면 commercial이라는 data frame에서 commercial['시']의 값이 서울특별시인 모든 행row들의 모든 컬럼값을 가져온다.
조건을 여러 개 달고 싶으면 아래와 같이 조건들 각각을 소괄호로 묶은 뒤 중간에 and(&)나 OR(|)에 해당하는 연산자를 넣어준다.
commercial[ (commercial['시'] == '서울특별시') | (commercial['시'] == '부산광역시') ] # OR조건
commercial[ (commercial['시'] == '부산광역시') & ( commercial['구'] == '남구') ] # AND조건 다시 돌아와서, 위의 seoul_data에서 정말 서울특별시의 데이터만 남았나 확인(검증)해본다.
city_type = set(seoul_data['시'])
city_type
seoul_data라는 data frame 내의 데이터 중 '시'라는 컬럼값의 중복을 제거한 집합을 뽑아보니 서울특별시라는 값밖에 없음을 알 수 있다.
다시 한번 같은 작업을 통해 서울특별시의 데이터 중에서 치킨집 데이터만 따로 저장하고자 한다.
seoul_chicken_data = seoul_data[ seoul_data['상권업종소분류명'] == '후라이드/양념치킨' ]
seoul_chicken_data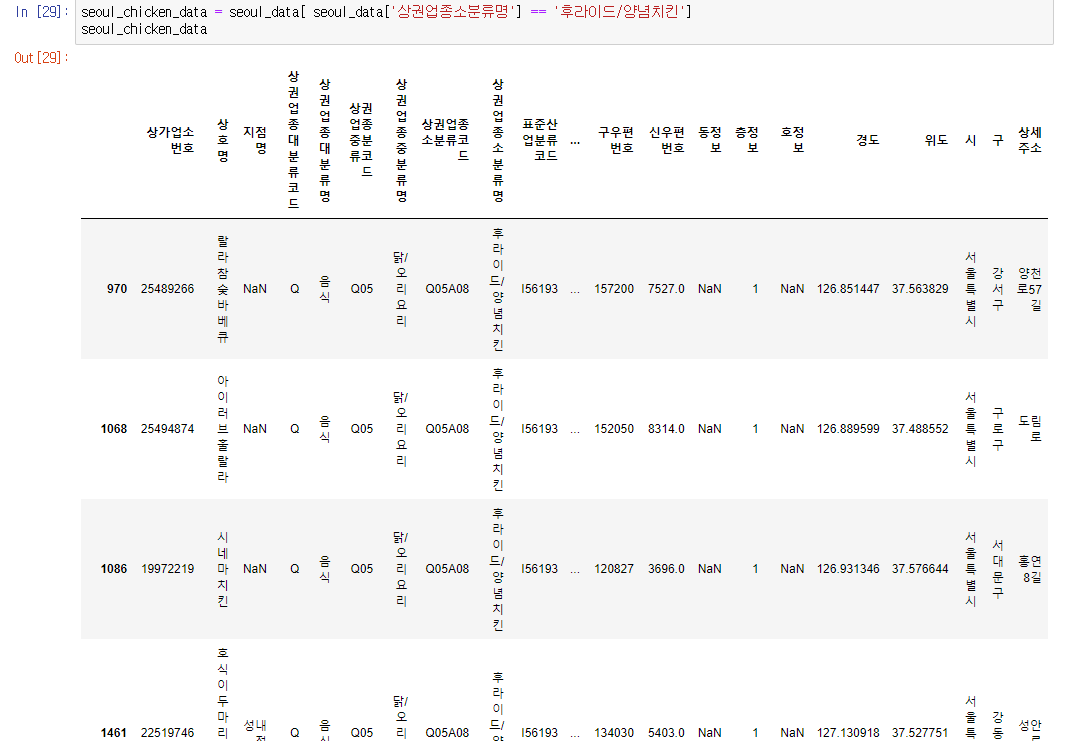
6. 서울의 '구'별(자치구별) 치킨집 수 데이터 만들기
구별로 groupby해서, 숫자를 세면 된다. 뒤에는 '상가업소번호'말고 무엇을 넣어도 상관없다. 경도든, 상권업종소분류명이든, 유니크unique한 데이터만 세는 것이 아니라 그냥 갯수를 세는 것이기 때문.
chicken_by_gu = seoul_chicken_data.groupby('구')['상가업소번호'].count()
chicken_by_gu
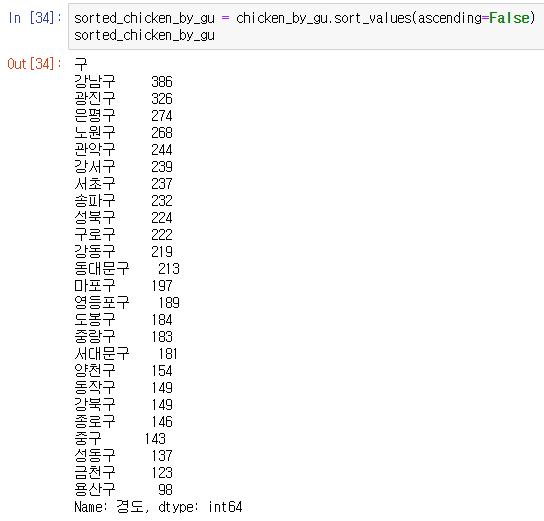
오름차순ascending = False를 넣어서 내림차순으로 정렬해줬다.
sorted_chicken_by_gu = chicken_by_gu.sort_values(ascending=False)
sorted_chicken_by_gu