파이썬 패키지 설치하기 (for 윈도우10 Windows10 , 파이참 PyCharm)
파이썬 프로젝트에 패키지가 필요할 때 패키지 설치하는 법.
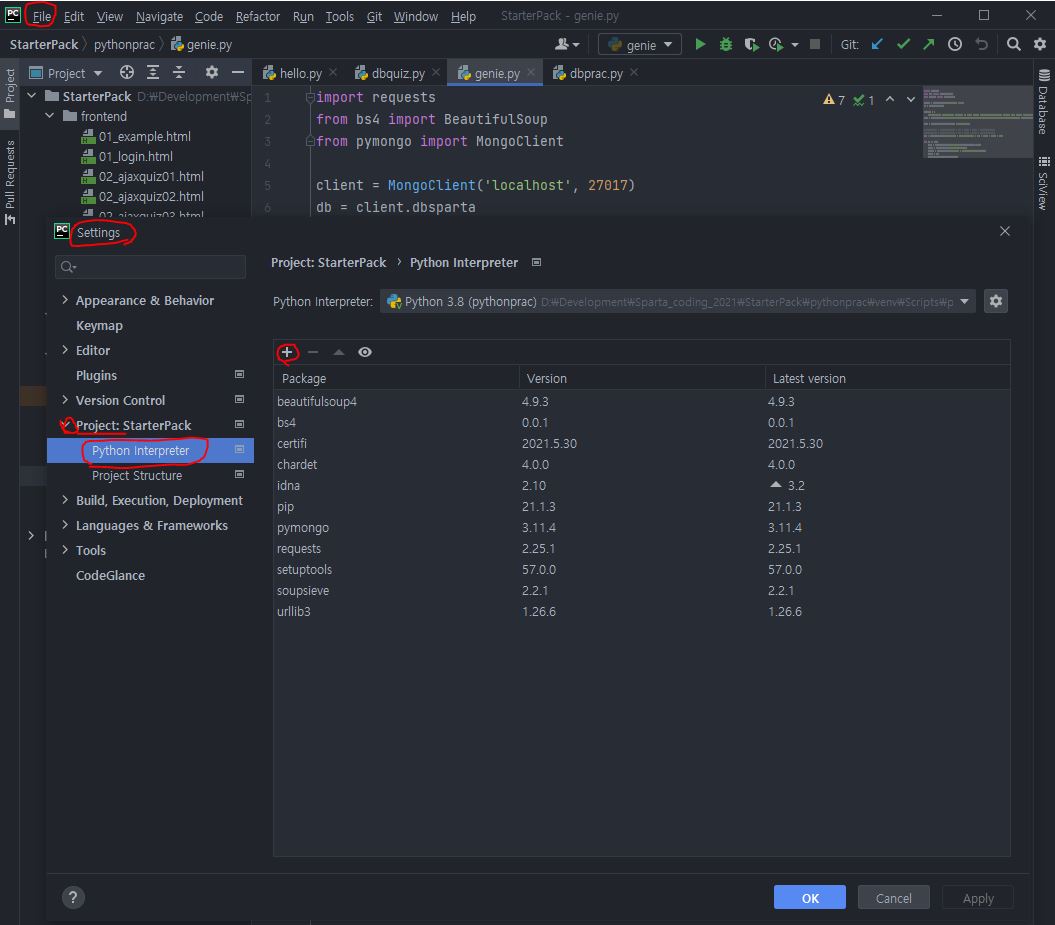
PyCharm 왼쪽 위 File > settings 클릭
settings가 별도 창으로 캡쳐와 같이 뜨면 Project > Python Interpreter 고르고,
현재 프로젝트에 이용하고 있는 인터프리터 파이썬 버전을 고른 뒤 " + "버튼 누르시면 패키지 목록이 나오고 검색할 수 있다.
필요한 패키지 이름을 검색한 뒤 클릭하고 왼쪽 아래 Install 버튼 누르면 끝!
import requests
패키지를 설치했다면 이제 내 코드의 맨 위에 이렇게 import를 해주면 해당 패키지가 코드에서 작동하기 위한 준비가 끝난다.
파이썬 패키지(라이브러리)란?
패키지? 라이브러리?
Python 에서 패키지는 모듈(일종의 기능들 묶음)을 모아 놓은 단위입니다. 이런 패키지 의 묶음을 라이브러리 라고 볼 수 있습니다. 지금 여기서는 외부 라이브러리를 사용하기 위해서 패키지를 설치합니다.
즉, 여기서는 패키지 설치 = 외부 라이브러리 설치!
(출처: 스파르타코딩클럽 강의자료)
requests
스크래핑(크롤링)을 하기 위해 설치한 패키지로, HTTP request를 보내는 기능들을 쓸 수 있게 해주는 패키지다.
그러니까 우리가 웹브라우져에서 다양한 사이트에 접속하는 것은 해당 사이트의 서버에 GET방식(GET method)의 HTTP request, 요청을 보내서 그 응답을 받는 행위다. 브라우져는 그렇게 요청을 보내고 응답을 받고 응답 받아온 데이터를 예쁘게 띄워주는 역할을 수행하는 프로그램인 것이다.
우리의 파이썬 프로그램에서 어떤 사이트, 웹페이지에 들어가서 정보를 받아오려면 웹브라우져처럼 요청을 보내야한다. 그럴 때 파이썬에서 그 요청을 보내는 코드들을 처음부터 일일이 짜지 않아도 이미 만들어져있는 HTTP 요청을 보내는 기능들이 있다! 그 기능들을 쓰기 위해 설치한 것이 이 패키지다.
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1', headers=headers)requests.get을 통해 해당 주소에 접속하여 웹페이지를 이루고 있는 HTML코드 등의 데이터들을 긁어와 data라는 변수에 저장하는 코드다. headers같은 경우 서버측에 클라이언트인 우리의 정보를 주는 영역인데 마치 웹브라우져를 통해 접속하고 있는 것처럼 꾸며서 보내는 코드라고 이해하면 된다(고 강의에서 말씀해주셨다).
bs4
이렇게 request를 보내 data를 받아왔으면 그 중 우리에게 필요한 것을 잘 꺼내야한다. 대부분의 데이터는 우리에게 필요가 없기 때문이다. 이때를 위해 필요한 것이 bs4 패키지다.
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')다 이해할 순 없지만 어쨌든 위처럼 코딩하면, soup 이라는 변수에 우리가 위 requests.get에서 설정한 주소의 웹페이지의 HTML 페이지 소스코드를 긁어와 예쁘게 넣어준다.(그런 일을 해주는 게 bs4패키지이고 BeautifulSoup이라는 함수다.)
# 왜 bs4 패키지는 requests 패키지와 다르게
import bs4
#가 아니라
from bs4 import BeautifulSoup
#라고 썼을까? 사실
import bs4
#라고 해도 된다. 대신 그렇게 하면 위의 코드에서 'BeautilfulSoup'을 'bs4.BeautifulSoup'이라고 바꿔주어야 코드가 동작한다.
선택자selector를 이용해 필요한 데이터 선택하기
이렇게 가져온 데이터에서 이제 우리에게 필요한 것만 골라내야한다! 어떻게 할까? HTML태그명과 CSS선택자를 이용해 원하는 태그의 원하는 속성값이나 text값을 가져오는 방법을 사용한다.
(아래 설명 및 이미지 출처: 스파르타코딩클럽 강의자료)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################- select / select_one의 사용법을 익혀봅니다.
영화 제목을 가져와보기!
태그 안의 텍스트를 찍고 싶을 땐 → 태그.text
태그 안의 속성을 찍고 싶을 땐 → 태그['속성'] import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text) - beautifulsoup 내 select에 미리 정의된 다른 방법을 알아봅니다 # 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')- 항상 정확하지는 않으나, 크롬 개발자도구를 참고할 수도 있습니다.
1. 원하는 부분에서 마우스 오른쪽 클릭 → 검사
2. 원하는 태그에서 마우스 오른쪽 클릭
3. Copy → Copy selector로 선택자를 복사할 수 있음 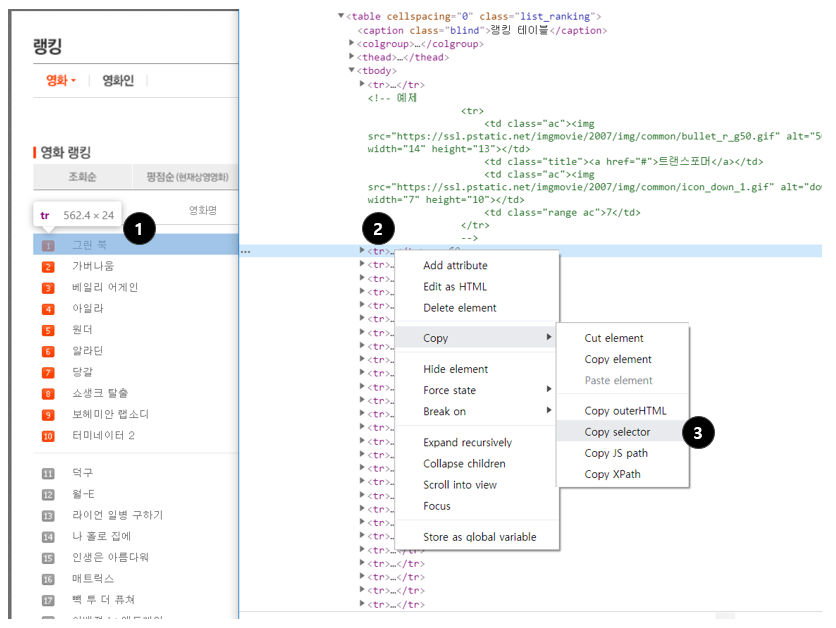
이렇게 아까 저장했던 변수명(여기선 soup)에 .select 함수를 이용해 내가 가져오고 싶은 데이터가 갖고 있는 HTML태그나 CSS선택자들을 잘 넣어서 원하는 데이터가 나올 때까지 print로 찍어보면서 데이터를 잘 뽑으면 된다.
그 다음 이 데이터를 mongoDB에 저장하는 코딩은 다음 글에서
