Parse Trees and Derivations
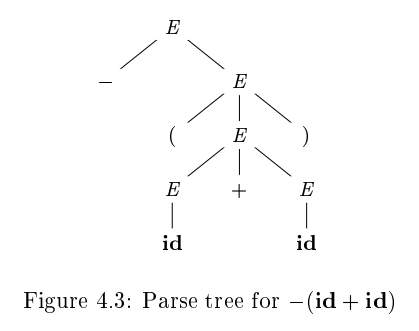
-
대충 요런 느낌. leaf node를 왼쪽부터 순서대로 읽어가면 sentential이 나온다. 이를 or of the tree라고 부른다.
-
derivation과 parse tree 사이의 관계
- consider any derivation , where is a single nonterminal .
- 결국 이 derivation은 inductively하게 parse tree를 구성하면 만들 수 있다.
-
BASIS : 의 tree는 라고 쓰인 single node이다.
-
INDUCTION

-
위 방법은 derivation들과 parse tree간의 다대일 관계를 만들게 된다.
-
leftmost 또는 rightmost derivations은 parse tree와 일대일 대응 관계를 가지고 있다.
-> 나름 쉽게 증명가능.
Ambiguity
- 둘 이상의 parse tree를 만드는 sentence가 존재하면 그 grammar를 하다고 말한다.
- 다른 말로, 둘 이상의 leftmost derivation이나 rightmost derivation을 통해서 같은 sentence를 만들 수 있는 경우 grammar를 ambiguous하다고 한다. (위 문장과 동치)
- ex)
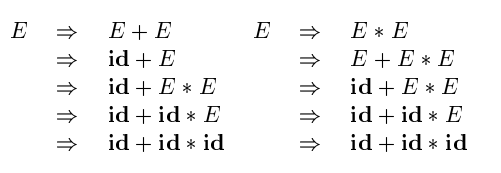
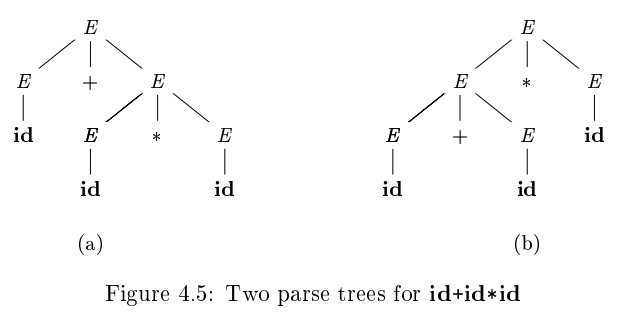
Verifying the Language Generated by a Grammar
-
grammar 가 language 을 generate한다는 것을 증명하는 방법
- 에 의해 만들어지는 모든 string이 의 원소임을 보인다.
- 모든 의 원소가 에 의해 만들어질 수 있다.
-
Example 4.12) Consider the following grammar:
-
: every sentence derivable from is balanced.
- induction 사용 : "n번 derive를 통해 나온 sentence는 balanced이다."
- BASIS : The basis is . -> 1번 derive를 통해 나온 sentence는 밖에 없고, 이는 당연히 balanced이다.
- INDUCTION : assume that all derivations of fewer than steps produce balanced sentences. 그리고 정확히 n step을 거친 leftmost derivation을 고려해 보자. (어떤 derivation이든 간에 leftmost derivation으로 유도가 가능하다.) 그러한 derivation은 다음과 같은 형태이다 :와 의 derivation은 step보다 더 적다. 그러므로 inductive hypothesis에 의해서 , 는 balanced이다. 그러므로 string 또한 balanced이다.
- induction 사용 : "n번 derive를 통해 나온 sentence는 balanced이다."
-
: every balanced string is derivable from .
use induction on the length of a string.- BASIS : If the string is of length 0, it must be , which is balanced.
- INDUCTION : Note that every balanced string has even length.
induction hypothesis : 길이가 보다 작은 모든 balanced string이 로부터 derivable하다고 가정하자.
길이 인 balanced string 를 고려하자.
는 당연히 (로 시작할 것이다.
를 같은 수의 (와 )를 갖고 있는 shortest nonempty prefix of 라고 하자.
그러면 로 쓸 수 있고, 와 는 각각 balanced인 길이 보다 작은 string이므로 induction hypothesis에 의해 각각은 로 부터 derivable하다.
결국가 되어 로 부터 derivable하다.
Context-Free Grammars Versus Regular Expressions
- 모든 regular expression은 grammar로 표현이 가능하지만, 반대는 불가능하다.
- 즉, 모든 regular language는 context-free language이지만, 반대는 아니다.
- 예를 들어, regular expression (ab)abb와 grammar
는 $abb$로 끝나는 같은 language를 표현한다. - NFA가 의미하는 것과 동일한 language를 표현하는 grammar를 만드는 방법이 존재한다.
- NFA의 각 state 에 대해 nonterminal 를 만든다.
- state 가 input 에 대해 state 로의 transition이 존재하면, production 를 추가한다. 만약 state 가 input 에 대해 state 로 한다면, production 를 추가한다.
- 만약 가 accepting state라면, 을 추가한다.
- 만약 가 start state라면, 를 grammar의 start symbol로 정한다.
- 반대로, language 는 grammar로는 표현이 가능하지만 regular expression으로는 표현이 불가능하다.
- 이 grammar로 표현이 가능한 이유
- 귀류법으로 증명 : 이 regular expression으로 표현이 가능하다고 가정. 그러면 이를 개의 state를 가진 DFA 가 표현가능하다고 할 수 있다.
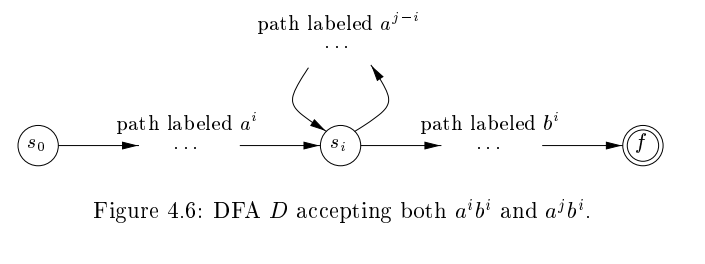
- 위 사진을 보면 더 이해가 잘 된다.
- k보다 더 큰 을 생각해 보자. 그러면 이 녀석은 a만 해도 n번의 이동을 할 텐데, 애초에 state 수가 k보다 더 크므로 언젠간 같은 state를 지나게 될 것이고, 그 state를 처음으로 지났을 때 번 움직인 것이라고 하고, 다시 지났을 때를 번 움직인 것이라고 하자. 그리고 그 state를 라고 하자.
- 또한 에 포함되므로 state에서 final state까지 를 통해서 가는 어떤 경로가 존재할 것이다.
- 그렇다면 결국 만큼 움직인 후 state에서 final state로 만큼 움직여서 갈 수 있으므로 또한 의 원소가 되는데, 이는 의 정의에 모순이 된다.
- 그러므로 은 regular expression으로 표현이 불가능하다.
- 이 grammar로 표현이 가능한 이유
- 정리
- "finite automata cannot count" : b를 보기 전에 a의 숫자를 count해야 하는 경우 동작 못함.
- "grammar can count two items but not three"

공부 내용 저장소