기본 구조
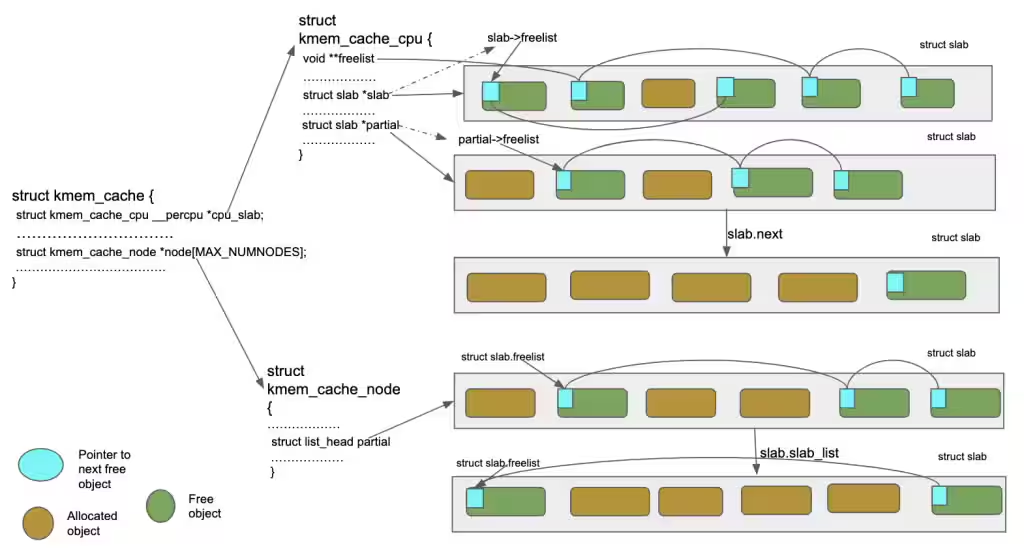
사실 설명하는 것 보다 이 그림이 더 이해하는 데에 도움이 많이 될 듯.
동작 원리
alloc
여러 가지 케이스 별로 어떻게 할당되는지가 나뉘게 되는데,
기본적으로 메모리의 할당은 항상 active slab에서 이루어진다.
FASTPATH
per-cpu lockless freelist가 free object 를 가지고 있는 경우에 해당.
per-cpu lockless freelist에서 할당되고 끝난다.
어떠한 lock도 걸지 않기 때문에 FASTPATH 이다.
cmpxchg for 2 words가 활성화 되어있지 않다면 이 방법을 사용할 수 없다.
SLOWPATH 1
만약 per-cpu lockless freelist가 비어있고, active slab의 freelist는 비어있지 않은 경우에 해당.
할당은 active slab의 freelist에서 일어나고, 해당 freelist가 per-cpu lockless freelist로 이동하게 된다.
이 과정에서 preemption이 disable 되어야 하고, kmem_cache_cpu.lock을 사용하기 때문에 SLOWPATH 1 이 된다.
아래의 다른 방법들에 비해서는 빠르기 때문에 SLOWPATH 중 가장 빠르다.
질문 : 어차피 같은 slab에서 일어나는 동작인데 왜 object는 per-cpu lockless freelist 와 slab의 freelist 로 나누어서 담기는가?
답변 : active slab을 사용하는 cpu가 free 할 경우 lockless freelist에 담기지만, 만약 다른 cpu가 해당 slab의 object를 free 할 경우에는 slab의 freelist에 담기게 된다.
SLOWPATH 2
per-cpu lockless freelist, active slab의 freelist가 모두 비어있는 경우, 그리고 per-cpu partial slab list은 비어있지 않는 경우에 해당.
per-cpu partial slab list의 제일 앞에 있는 slab이 active slab이 되고, 그 slab의 freelist가 per-cpu lockless freelist로 옮겨지게 된다. 그 후 per-cpu lockless freelist에서 할당이 된다.
SLOWPATH 1 의 경우에 더해서, partial slab list의 관리도 더불어 이루어져야 하기 때문에 SLOWPATH 2이다.
SLOWPATH 3
per-cpu slabs가 freelist를 가지고 있지 않은 경우에 해당.
per-node partial slab list에서 할당된다.
per-node partial slab list에 slab가 채워지는 과정
full slab이 empty / partial 이 되었을 경우, per-cpu partial list에 먼저 채워지게 되는데, 만약 이미 꽉 차 있는 경우 per-node partial list에 채워지게 된다.
per-node partial slab list에서 탐색할 때에는 가장 가까운 node 부터 탐색이 이루어진다.
찾고 난 후, 해당 freelist에서 할당되고, 그 slab은 active slab이 된다.
여기서 끝나지 않고, per-node partial slab list 에서 slab을 가져다가 per-cpu partial slab list에 옮겨놓는다. (per-cpu partial slab list가 꽉 찰 때까지)
SLOWPATH 4
slab cache에 어떠한 free object가 없는 경우.
buddy allocator에 의해 할당받은 메모리를 이용해서 새로운 slab을 만들고, 이를 active slab으로 만든다.
free
아래 4가지 경우로 나눌 수 있다.
per-cpu active slab
두 가지 경우로 나뉜다.
- free하는 주체가 active slab이 속한 cpu인 경우
per-cpu lockless freelist에 담긴다. - 아닌 경우
per-cpu active slab의 freelist에 담긴다.
두 가지 경우 모두 cmpxchg for 2 words가 지원된다면 어떠한 lock도 필요하지 않다.
per-cpu / per-node partial slab list
- free된 이후에도 partial slab인 경우 -> 그냥 free하고 끝.
- empty slab이 되는 경우
- slab의 min_partial보다 작아진다 -> empty인 상태로 남아있게 된다.
- slab의 min_partial보다 크거나 같다 -> free되고(buddy allocator 담당) partial slab list로 부터 제거된다.
full slab
우선적으로 per-cpu partial slab list에 담긴다.
이 경우, kmem_cache_cpu.lock 만 필요하다.
만약 가득 차 있다면, per-cpu partial slab list에 있는 slab들은 unfrozen 상태가 되어 per-node partial slab list로 옮겨지게 되고, 새로운 partial slab이 per-cpu partial slab list로 옮겨지게 된다.
이 경우, kmem_cache_node.list_lock이 사용되게 된다.
Reference
