행렬 분해
행렬 분해
- 메모리 기반 협조 필터링에 비해 구현 관점에서 다소 복잡하지만 추천 성능은 좋다
- 행렬 분해라는 용어는 넓은 범위를 나타내며 문헌에 따라 행렬 분해라는 용어가 전혀 다른 바법을 가리키는 경우도 존재
- 추천 시스템에서의 행렬분해는 넓은 의미에서 평갓값 행렬을 저차원의 사용자 인자 행렬과 아이템 인자 행렬로 분해하는 것을 나타낸다.
- 사용자와 아이템을 100차원 정도의 저차원 벡터로 표현하고 그 벡터의 내적값을 사용자와 아이템의 상성으로 한다
- SVD, NMF, MF, IMF, BPR, FM 행렬 분해등이 있다.
- 행렬 분해 방법을 실무에서 사용할 때는 '결손값 취급', '평갓값이 명시적인가 암묵적인가'라는 관점이 중요
평갓값이 명시적인 경우
- 평갓값이 명시적이라는 것은 Movielens 데이터와 같이 사용자가 아이템에 대해 명싲적으로 평가한 데이터를 말한다.
- 이런 구조로부터 얻은 데이터의 경우 사용자가 명시적으로 평가를 한것이기 때문에 품질이 높다
-
평갓값 행렬이 주어졌을 때, 영화를 XY 좌표의 2차원 벡터로 표현을 한다면, X 축을 액션 정도, Y축을 판타지 정도라는 축으로 한다면 액션과 판타지에 적합한 영화들은 오른쪽 위에 위치할 것이다.
-
사용자의 경우에도 액션 정도가 높은 판타지 영화를 좋아하는 경우 오른쪽 위에 위치할 것이다.
-
하지만 예시처럼 사람이 각 차원에 의미를 부여하는 것이 아니고 데이터를 통해 자동으로 축을 구축한다.
-
또한 차원이 사람이 이해하기 쉬운 축이 되는 경우도 있지만 사람이 해석하기 어려운 축이 만들어 질 수도 있다.
특잇값 분해
- 특잇값 분해(SVD) Singular Value Decomposition
- 결손된 부분에 0또는 평균값을 대입하고 특잇값 분해를 통하여 차원을 줄일 수 있다.
평갓값 행렬 R을 다음과 같이 P,S,Q로 분해한다
사용자의 행렬 와 아이템의 행렬 를 얻을 수 있다.
- 특잇값 분해의 경우 추가로 설명을 할 예정-
특잇값 분해의 경우 결손값을 0으로 채우기 때문에 추천 서능이 나쁘다. 0을 대입하는 것은 사용자가 그 아이템에 대해 싫어한다고 의사 표시한 것과 같다.
-
하지만 평갓값이 결손되있는 것은 사용자가 아직 평가를 하지 않은 것이지 해당 아이템을 좋아할 수도 있다.
-
또한 Sparse한 행렬이기 때문에 RMSE등의 지표도 나빠질 수 도 있다.
-
예측 평갓값의 상대적인 값에는 의미가 있으며 무작위로 추천할 때보다 성능이 좋다.
-
또한 SVD에는 잠재 인자 수라는 중요한 파라미터가 있으며 이를 변화시키면 예측 정확도가 바뀌니다.
-
잠재 인자수가 높을 수록 원래 행렬을 복구할 때 충분한 표현력을 갖기 때문에 예측 정확도가 좋아진다.
-
한편 잠재인자수가 너무 높을 경우 오버피팅될 가능성 존재
-
일반적으로 잠재 인자수 는 수십~수배으로 설정한다.
비음수 행렬 분해
-
비음수 행렬 분해(NMF) Nonnegative Matrix Factorization
-
SVD는 행렬 분해 후 행렬에 대한 음수값을 취하는 경우가 있지만 NMF는 행렬 분해 시 사용자와 아이템 각 벡터의 요소가 0 이상이 되는 제약을 추가한다.
-
그 제약에 따라 각 사용자나 아이템의 벡터 해석 특성이 향상된다. 하지만 결손값을 0으로 채워서 적용하는 경우가 많아 일반적으로 추천 성능이 좋지않다.
-
예측 정확도 관점에서 SVD나 NMF는 피하고 다음 알고리즘 사용을 권장
명시적인 평갓값에 대한 행렬 분해
- 행렬 분해 (MF) Matrix Factorrization는 SVD와 달리 결손값을 메꾸지 않고 관측된 평갓값만 사용해 행렬 분해하는 바법을 나타내는 경우가 많다.
- 넷플릭스사가 개최한 평갓값을 예측하는 대회에서 MF를 사용하는 방법으로 좋은 성과를 거뒀음
- MF는 대규모 데이터에서도 고속으로 계산할 수 있는 개선된 방법이 존재하여 스파크나 빅쿼리 등에서도 구현되고 있다.
- Surprise 라이브러이에서는 SVD라는 이름으로 MF가 구현되어 있다.
- MF 에서는 SVD나 NMF에 비해 관측된 평갓값만 사용하므로 해당 영화에 부여된 평가수가 적더라도 평갓값이 높으면 해당 영화를 추천하는 경향이 존재
- Surprise에서는 biased라는 파라미터가 있으며 사용자와 아이템의 편향함 포함여부를 선택할 수 있고 하이퍼파라미터 튜닝을 통하여 찾아갈 수 있다.
암묵적인 평갓값에 대한 행렬 분해
암묵적인 평갓값이란 상품 상세 페이지 클릭이나 동영상 시청 등 사용자가 명시적으로 평가하지 않은 사용자 행동 이력을 의미한다.
- 실무에서 추천 시스템을 만들 때는 명시적인 평갓값보다 암묵적인 평갓값 데이터를 얻기 쉬우므로 암묵적인 평갓값이 자주 사용된다.
- 명시적인 평갓값에는 별 1개나 별 5개와 같이 평갓값이 한쪽으로 쏠리는 편향도 있어 학습이 잘안되는 경우도 많아 암묵적인 평갓값을 많이 사용
- 암묵적인 평가의 특징의 경우 '음수의 예가 없다','클릭 수 등과 같이 평갓값을 가질 수 있는 범위가 넓다', '노이즈가 많다'등을 들 수 있음
BPR
- 암묵적이 평갓값을 사용한 다른 방법으로 Bayesian Personalized Ranking (BPR)이 있다.
- BPR에서는 사용자 u, 암묵적으로 평가한 아이템 i, 관측되지 않은 아이템 j라는 3가지 데이터를 기반으로 학습해 나간다.
- 실무에서 사용할 때는 관측되지 않은 아이템이 많아 이들을 모두 사용하는 것은 어려우므로 관측되지 않은 아이템 j의 샘플링 방법을 잘 선택해야 한다.
- 단순히 모든 아이템에서 동일하게 샘플링하는 방법, 출현 횟수에 따라 샘플링하는 방법, 클릭했지만 구입하지 않은 아이템으로 필터링해서 샘플링하는 방법등 여러가지 샘플링 방법이 있음
FM
-
지금까지의 방법은 평갓값만 사용하는 방법이다. 하지만 평갓값뿐 아니라 사용자나 아이템의 속성정보를 사용해 추천 시스템의 성능을 향상시킬 수 있다.
-
이 방법은 사용자나 아이템의 속성 정보를 사용함으로써 신규 아이템이나 사용자에 대해 추천이 불가능한 콜드 스타트 문제에도 대응할 수 있다는 장점이 존재
-
Factorization Machines FM은 매우 유명하며 널리 사용됨
-
FM에서 입력 데이터 형식은 지금까지와 다르다
-
FM에서는 1개의 평가를 1행으로 표시한다.
-
행렬은 평갓값 X 특징량 수가 된다.
-
특직량은 사용자 ID를 원-핫 인코딩한것과 아이템 ID를 원-핫-인코딩한 것, 사용자와 아이템의 속성 정보등의 보조 정보를 연결한 것이된다.
-
FM의 좋은 점은 특징량끼리의 조합도 고려할 수 있다.
- 예를 들어 영화 추천의 경우 사용자 나이와 성별의 조합은 중요한 특징량이 될 수 있다.
- FM의 경우 나이와 성별을 나타내는 예를 넣어두는 것만으로 해당 조합을 고려할 수 있다.
자연어 처리 방법에 대한 추천 시스템의 응용
- 토픽 모델 LDA나 word2vec 등 자여녀어 처리 분야에서 제안된 부분을 추천 시스템에 응용할 수 있다.
- 자연어 처리 분야에서 제안된 것으로 상품 설명문이나 사용자 리뷰를 분석함으로써 콘텐츠 기반 추천으로 비슷한 상품을 찾을 수 있다.
- 이 방법들을 사용자의 행동 이력에 적용함으로써 협조 필터링 기반 추천도 가능
토픽 모델
- '야구', '축구'등의 단어는 스포츠 관련 기사에 자주 사용되고 '선거', '세금'등의 단어는 정치 기사에서 자주 사용된다.
- 문장 토픽에 따라 사용되는 빈도가 다르다.
- 토픽 모델에서 하나의 문장은 여러 토픽으로 구성되며 각 토픽에서 단어가 선택되어 문장이 구성되는 것을 모델화 한다.
- 잠재 디리클레 할당 모델은 토픽 할당에 디리클레 분포를 사전 분포로 가정해 베이즈 추정을 한 모델이다.
LDA를 사용한 콘텐츠 기반 추천
- LDA를 사용하여 콘텐츠 기반 추천을 하려면 줄거리 문장을 LDA에 입력하여, 공포, 연애와 같은 주제가 나타나고 각 문장에 토픽의 벡터가 할당된다.
- 벡터를 사용하여 코사인 유사도 등의 거리 계산을 함으로써 각 서저 사이의 유사도를 측정할 수 있다.
- 이를 활용하여 고나련 아이템 추천 시스템을 만들 수 있다.
LDA를 사용한 협조 필터링 추천
-
사용자의 구입 이력이나 열림 이력 등의 행동 이력 데이터는 다음처럼 표현 가능
User1 : [item1, item41, item23, item4]
User2 : [item52, item3, item1, item9] -
각 아이템을 단어로 보고 사용자가 행동한 아이템의 집합을 문장으로 보면 LDA를 적용할 수 있다.
-
출력된 결과는 각 토픽별 아이템 분포와 각 사용자별 주제가 된다.
-
'토픽 1은 item23이 0.3, item4가 0.2'와 같은 아이템 분포와 'User1은 토픽 1 : 0.8, 토픽 2: 0.1' 같은 결과가 나옴
-
이 벡터를 통하여 User1은 토픽 1의 성분이 강하므로 토픽 1에서 나오기 쉬운 아이템을 추천할 수 있다.
-
아이템에 대해서도 각 토피에서의 출현 확률을 나열한 벡터를 만들어 코사인 유사도 등을 사용해 유사도를 계산할 수 있으므로 관련 아이템을 추천할 수 있다.
-
행동 이력에 LDA를 적용해 얻을 수 있는 장점은 추천 시스템을 만드는 목적 외에도 탐색적 데이터 분석(EDA)로 사용자나 아이템에 대한 이해도를 높일 수 있다.
-
행동 이력을 기반으로 각 아이템을 모아주기 때문에 상품의 설명문만 언뜻 보면 다른 것처럼 보여도 사실 함께 구입되기 쉬운 아이템을 알 수 있다.
-
마케팅이나 상품 개발에도 도움이 될 수 있다.
word2vec
- '단어의 의미는 그 주변 단어에 따라 결정된다'라는 가설이 있다. -> 분포가설
'서점에서 산 OO를 읽어보니 재미있었다'
'책', '단어', '서적'등이 있다
이 단어들은 같은 문맥에서 나오는 경우가 많고 단어의 의미도 비슷하다. - 이러한 분포 가설을 기반으로 단어의 의미를 벡터로 표현하는 방법 중 하나가 word2vec이다.
word2vec을 사용한 콘텐츠 기반 추천
- 온라인 쇼핑 사이트에서 서적을 추천하는 것에 대해 생각할 때, 서적의 줄거리에 나오는 단어의 벡터 평균을 해당 서적의 벡터로 간주한다.
- 각 서적들의 벡터간 유사도를 계산함으로써 관련 아이템을 추천할 수 있다.
- 단어의 평균만 구한다면 자주 나오는 단어와 특징적인 단어가 동등하게 취급되므로 특징적인 단어의 영향도가 희박한 벡터가 되어버린다.
- tf-idf와 같은 방법을 사용해 해당 문제에 특징적인 단어만 추출해서 평균 벡터를 얻는 방법, tf-idf의 가중치를 사용해 벡터를 계산하는 방법 등을 사용한다. 이 밖에도 SWEM이라는 방법에서는 단어의 평균 벡터가 아니라 각 차원의 최댓값과 최솟값을 추출한 최대 벡터나 최소 벡터를 결합하여 문자의 벡터로 간주한다.
- word2vec을 발전시킨 것으로 doc2vec이라는 방법이 있다.
- doc2vec은 단어를 벡터화할 뿐아니라 문장 자체에도 벡터를 부여하기에 하이퍼 파라미터를 적절하게 조정한다면 word2vec보다 여러 태스크에서 높은 성능을 발휘한다.
word2vec을 사용한 협조 필터링 추천(item2vec)
-
사용자가 열람하거나 구매하는 등의 행동 이력을 word2vec에 적용하는 방법에 관해 설명하겠다.
-
이 방법은 item2vec, prod2vec이라 불리며 구현이 간단하고 추천 성능이 높아 야후, 에어비앤비 등의 기업에서 사용됨
-
LDA의 경우와 마찬가지로 사용자의 행동 이력을 단어의 집합으로 간주하고 word2vec을 적용한다.
-
사용자의 행동한 순서대로 아이템을 나열하는 것이 중요하고, window_size라는 파라미터를 통하여 액션 순서까지 고려해 학습 시킨다.
-
이 벡터를 사용하면 아이템 간 유사도를 계산할 수 있으며 관련 아이템 추천을 구현한다.
-
아이템의 벡터를 사용하면 사용자에게 간단히 추천할 수 있다.
-
아이템의 벡터를 유지하기만 함녀 사용자의 벡터는 벡터의 사칙연산으로 계산이 가능하기 때문에 실시간 온라인 추천등에서 사용된다.
-
아이템을 단어, 사용자의 행동 이력을 문장으로 간주함으로써 자연어 처리 방법을 협조 필터링 형태의 추천으로 적용할 수 있다, BERT 모델을 사용자읭 행동이력에 적용한 사례도 존재
딥러닝
- "Deep Learning for Recommender System" 워큿뵤을 통하여 추천시스템에서 활용되고있다.
딥러닝을 활용한 추천 시스템
- 이미지나 문장 등 비구조 데이터의 특징량 추출기로 활용
- 복잡한 사용자 행동과 아이템 특징량 모델링
이미지나 문장등 비구조 데이터의 특징량 추출기로 활용
- 딥러닝은 이미지 분석이나 자연어 처리 분야에서 많은 모델이 제안되었고 큰 성과를 남겼다.
- 지금까지 콘텐츠 기반 추천 시스템에서는 이미지, 음악, 동영상, 텍스트에 관해 카테고리 정보나 태그 정보를 기반으로 추천을 수앵하여서 추천 시스템의 정확도가 좋지 않았음
- 스포티파이에서는 곡조가 비슷한 음악을 추천하고, 인스타그램에서는 분위기가 비슷한 이미지를 추천한다.
- 딥러닝을 사용하면 콜드 스타트 문제를 해결할 수 있다.
복잡한 사용자 행동과 아이템 특징량 모델링
추천 시스템에서 딥러닝의 장점
- 비선형 데이터 모델링
- 시계열 데이터 모델링
비선형 데이터 모델링
- 행렬 분해를 딥러닝화 한 Neural Collaborative Filtering
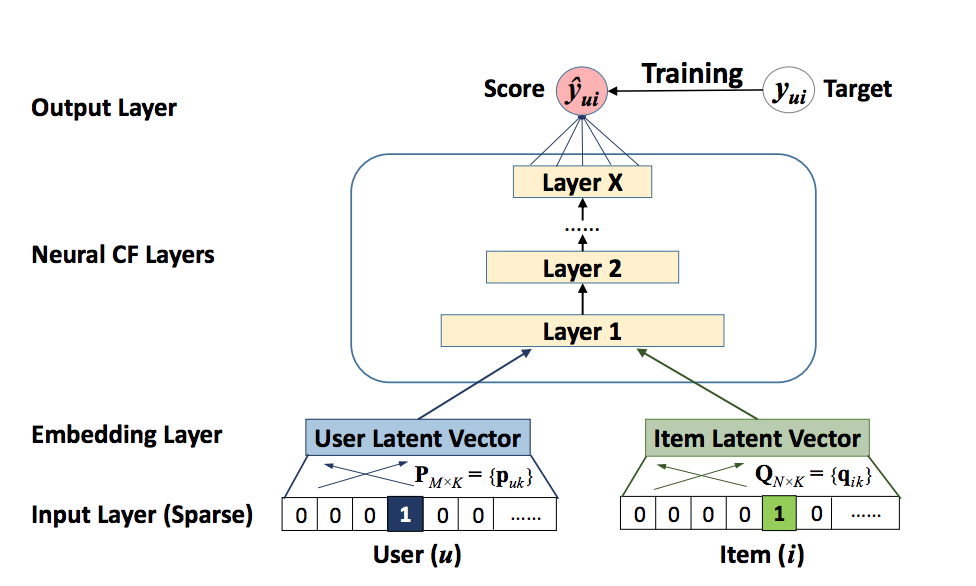
-
신경망이 여러층으로 구성되어 있어 사용자와 아이템의 복잡한 데이터를 학습할 수 있으며 기존 행렬 분해보다 높은 예측 정확도를 얻을 수 있다.
-
DeepFM은 Factorization Machines를 딥러닝화한 방법
-
아이템이나 사용자의 특징량에 대해 특징량 엔지니어링이 필요없으며 그대로 모델에 입력할 수 있다.
-
모델 안에서는 고차원의 각 특징량 조합도 학습해준다.
-
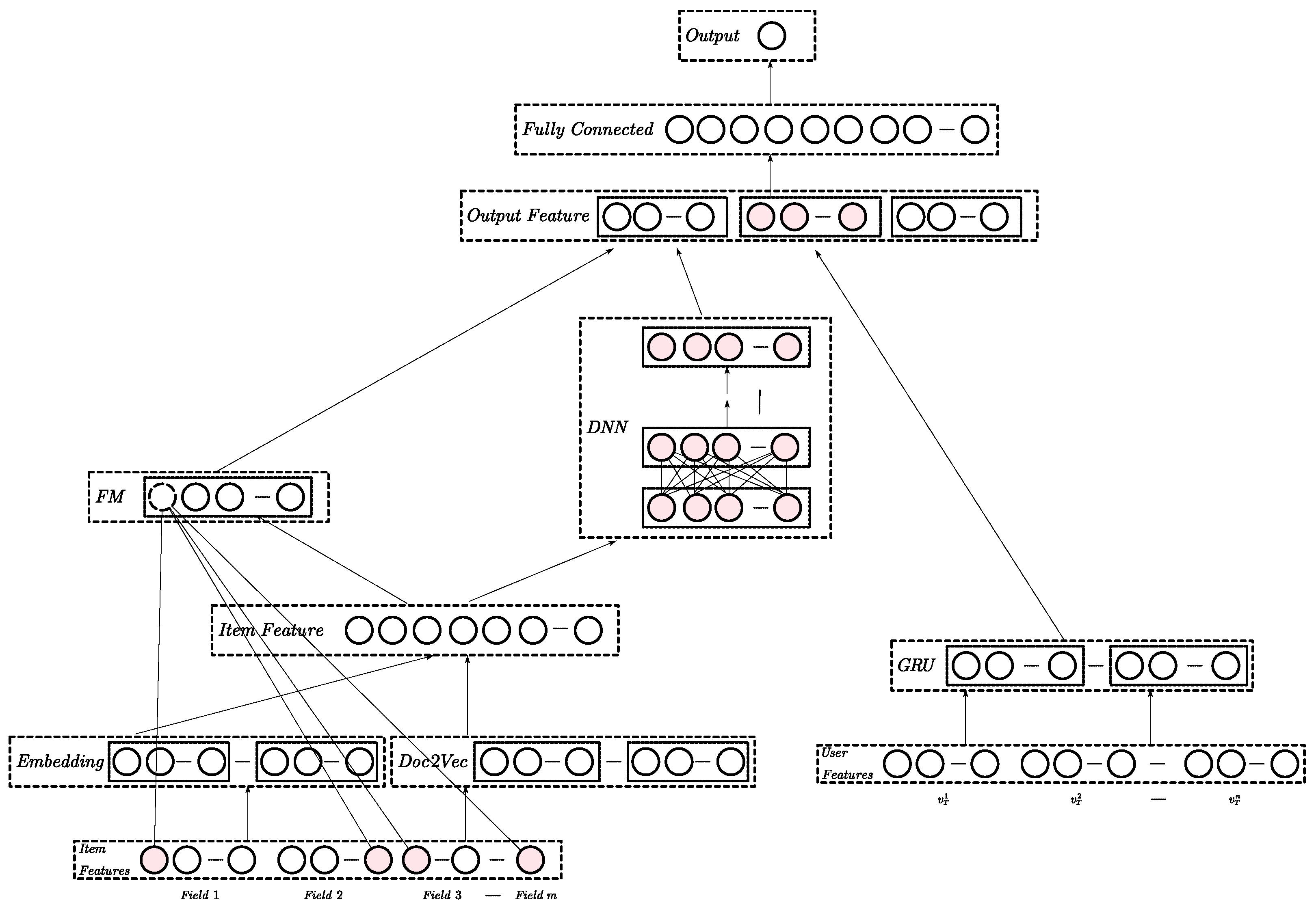
-
Wide and Deep
-
Wide 부분과 Deep 부분의 2개로 구성되어 있다.
-
Wide 부분에서는 아이템이나 사용자의 특징량을 입력으로 하여 1층의 선형 모델을 거친다
-
Deep 부분에서는 Embedding층을 내장해 다층으로 함으로써 보다 일반화된 추상적인 표현을 얻을 수 있다.
-
이 2개를 조합하면 예측 정확도를 높이면서도 다양하게 추천할 수 있다.
-
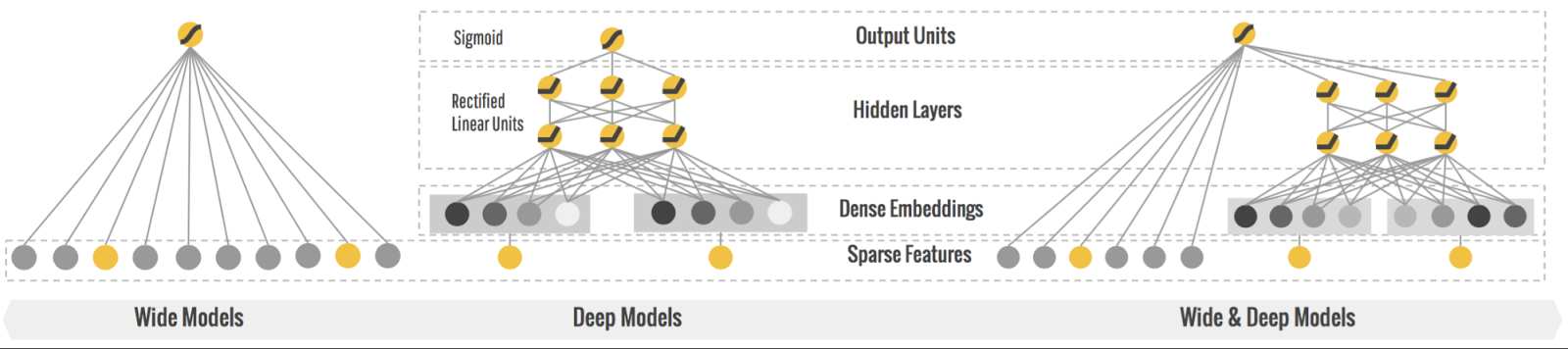
시계열 데이터 모델링
- RNN이나 LSTM을 시작으로 하는 시계열 정보를 다루는데 뛰어난 방법들이 제안되었음
| 자연어 처리 방법 | 추천 알고리즘 |
|---|---|
| RNN | Session-based recommendations with recurrent neural networks |
| word2vec | item2vec: neural item embedding fo collaborative filtering E-commerce in Your Inbox: Product Recommendations at Scale |
| BERT | BERT4REC : Sequential recommendation with bidirectional encoder representations from transformer |
구현
| 라이브러리명 | URL | 설명 |
|---|---|---|
| Recommenders | https://github.com/microsoft/recommenders | 마이크로소프트사 개발한 추천알고리즘 MF나 BPR등 고전적인 방법 부터 최신 딥러닝 추천알고리즘 구현, GPU나 스파크를 사용한 모델까지 제공 |
| Spotlight | https://github.com/maciejkula/spotlight | 파이토치 기반의 추천 알고리즘 라이브러리 딥러닝 뿐아니라 얕은(Shallow)모델도 구축 프로토타입을 작성하기 용이 |
| RecBole | https://recbole.jo/ | 파이토치 기반의 추천 알고리즘 라이브러리, 70개 넘개 구현 |
실무에서의 딥러닝 활용
특징량 추출기로 활용
- 학습 완료 모델을 찾아 자사의 아이템에 적용하고 특징량을 추출한다.
- 각 아이템 이미지에 대해 수백 차원의 벡터를 얻을 수 있고 해당 벡터를 그대로 사용해 비슷한 아이템을 찾아낼 수 있으며 해당 벡터를 아이템의 특징량 중 하나로 사용해 회귀 모델을 적용할 수 있음
예측 모델로 활용
- "Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches" 논문에서 단순한 k-nearest 추천 시스템이 최근 딥러닝 추천 시시템의 대부분 보다 성능이 좋다라는 내용이 있음
- 추천시스템을 도입할 때 먼저 고전적인 방법을 검증한 뒤 딥러닝 사용을 검토해야한다
- 일반적으로 딥러닝으로 설명하기 어려운 과제들도 있으므로 고전적이고 단순한 방법이 오히려 실무에서 활용하기 좋을 수 있음

좋은 글 잘 읽었습니다, 감사합니다.