paper_review
1.Attention is All you need
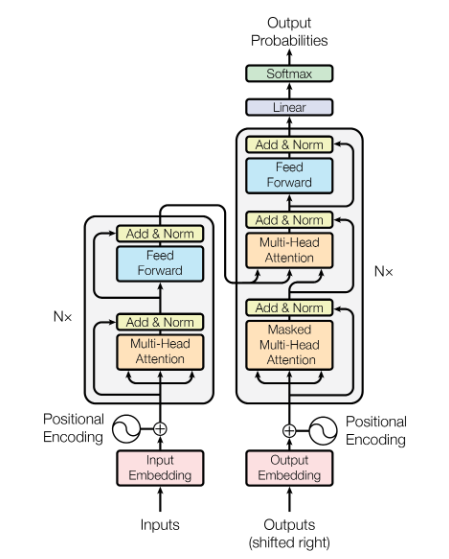
abstract 대부분의 모델들이 인코더와 디코더로 이루어진 복잡한 RNN모델 혹은 CNN모델로 생성이 되고는 했다 그 중 어텐션 메커니즘으로 이루어진 모델이 좋은 성능을 보였다. 오직 어텐션 메커니즘만 사용한 Transformer를 만들었다 Introduction
2.Dropout: a simple way to prevent neural networks from overfitting
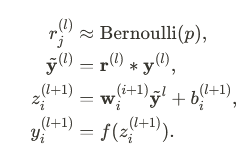
Deep Neural Network 의 Regularization 방법인 Dropout 을 제시한 논문입니다.학습 과정에서 일부 Node 를 제외(Drop)하는 것 만으로 Overfitting 을 방지할 수 있는 단순한 방법을 제시했습니다.Dropout 이전에도 ove
3.Deep Learning of Representations: Looking Forward

https://arxiv.org/abs/1305.0445딥 러닝 알고리즘을 훨씬 더 큰 모델과 데이터 세트로 확장하고, 잘못된 컨디셔닝 또는 로컬 최소값으로 인한 최적화의 어려움을 줄입니다.보다 효율적이고 강력한 추론 및 샘플링 절차를 설계하고 관찰된 데이터의
4.Editing Factual Knowledge in Language Models
https://arxiv.org/abs/2104.08164언어 모델에 저장된 지식 중 일부를 수정하고 나머지 지식을 보존할 수 있는 KnowledgeEditor방법론을 제안했습니다. 지식을 외부에 저장했던 기존의 Knowledge Bases (KBs)와는 달리
5.Generating Text with Recurrent Neural Networks
https://web.archive.org/web/20211224075156id\_/https://icml.cc/2011/papers/524_icmlpaper.pdf이 논문에서는 LSTM 기반 모델을 사용하여 단어 수준 언어 모델링 문제를 다루며, 순
6.Language Models are Few-Shot Learners
https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf대규모 텍스트 코퍼스에서 사전 학습된 GPT-3 언어 모델을 사용하여, Few-shot 학습을 통해
7.PPT: Pre-trained Prompt Tuning for Few-shot Learning
img사전학습된 언어 모델을 미세조정(fine-tuning; FT)하는 연구는 많은 발전을 이룩해왔고, 우수한 성능을 보여주었습니다. FT에는 크게 두가지 방법이 있는데, 첫번째로는 task-specific head가 사전학습된 모델 위에 추가되어 전체 모델을 task
8.Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting
https://arxiv.org/pdf/1912.09363.pdf여러 날을 예측하는 Multi-Horizon Forecasting 시계열 데이터는 복잡한 입력들을 포함하는데 그러한 것들에는 시간에 따라 변하지 않는 변수(이 논문에서는 Static Covaria
9.Training Language Models to Follow Instructions with Human Feedback
https://arxiv.org/abs/2203.02155다양한 대형언어모델이 다양한 NLP task를 풀기 위해 모델에 prompt를 줄 수 있습니다. 특히, task에 대한 몇 개의 예제를 함께 주는 prompt가 흔하게 쓰입니다. 하지만, 이러한 모델들은
10.Transformers: State-of-the-Art Natural Language Processing
https://arxiv.org/pdf/1910.03771.pdfTransformers는 자연어 처리 분야를 혁신적으로 발전시킨 오픈소스 라이브러리로, Transformer 아키텍처와 효과적인 사전 학습을 통해 다양한 작업을 위한 고용량 모델을 만들었습니다.이
11. Very Deep Convolutional Networks for Large-Scale Image Recognition (VGG)
https://arxiv.org/abs/1409.15563x3 convolution filter를 가진 network을 이용해 깊이를 증가시킨 모델을 평가합니다.깊이를 16-19 layer로 늘려 이전 모델들보다 개선됨을 보여줍니다.백서에서는 ConvNet 아