📔설명
표준 조인, 집합 연산자, DCL 계층형 질의, 그룹 함수, 서브쿼리, 윈도우 함수, 절차형 SQL, 집합 연산자에 대해 알아보자!
✨순수 관계 연산자(SELECT, PRODUCT, JOIN, DIVIDE)
SELECT->WHERE절PROJECT->SELECT절(Natural)JOIN->JOIN연산DIVIDE-> 현재 사용X
😀표준 조인(Standard JOIN)
STANDARD JOIN : ANSI JOIN, 표준 조인으로 불리며 모든 벤더별로 돌아가는 표준 JOIN 쿼리
INNDER JOIN
- JOIN
조건에충족하는 데이터만출력 ON절에조건적어야 함
select s.col1, t.col1, t.col2
from study s inner join test t
on s.col1=t.col1;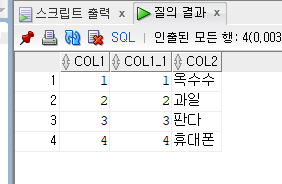
OUTER JOIN
- JOIN
조건에충족하는 데이터가 아니어도 출력
-
LEFT OUTER JOIN
-왼쪽에 표기된 테이블의 데이터는무조건 출력되는 JOIN
-오른쪽테이블에 데이터가 없는 행은 값이NULL로 출력 -
RIHGT OUTER JOIN
-오른쪽에 표기된 테이블의 데이터는무조건 출력되는 JOIN
-왼쪽테이블에 데이터가 없는 행은 값이NULL로 출력 -
FULL OUTER JOIN
-왼쪽, 오른쪽테이블의 데이터가모두 출력(중복값 제거 합집합)
NATURAL JOIN
A테이블과B테이블에서같은 이름을 가진 컬럼들이모두 동일한 데이터를 가지고 있을 경우 JOIN- MS-SQL 지원 X
- Oracle에서는
USING조건절을 이용해서같은 이름을 가진 컬럼중원하는 컬럼만 JOIN에 이용 가능
단,USING절로 정의된 컬럼 앞에는SELECT절에서 별도의Alias나테이블명X ON절 사용 불가공통 컬럼앞에OWNER 명을 붙이면 에러 발생
ex)SELECT D.DEPT_NO FROM EMP NATURAL JOIN DEPT D;
select * from test natural join study;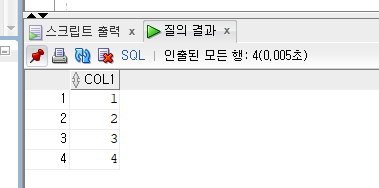
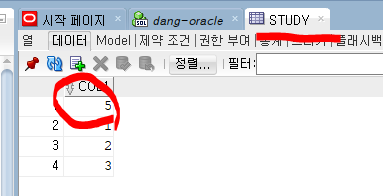
select * from test natural join study;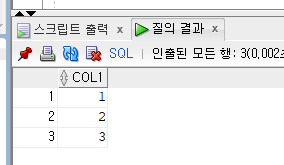
ex ) USING
SELECT CAST, GENDER, a.job as r_job, b.job as i_job
from run a join infinite b
using (CAST, GENDER);CAST와 GENDER만 같은 이름에 같은 내용이면 natural join 된다!
CROSS JOIN(Cartesian Product)
A테이블과B테이블사이에JOIN 조건이 없는 경우,조합할 수 있는 모든 경우출력카티션 곱이라고 함속성: 두 테이블의 속성 수합행: 두 테이블의행x행
select * from author cross join test;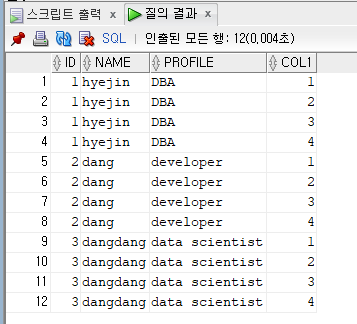
😎집합 연산자
UNION연산->UNIONINTERSECTION연산->INTERSECTDIFFERENCE연산->MINUS/EXCEPTPRODUCT연산->CROSS JOIN
UNION ALL
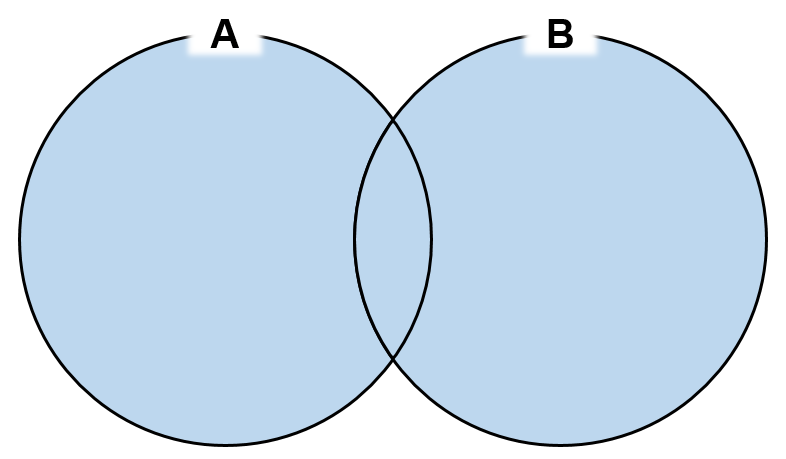
- 각 쿼리 결과 집합의
합집합 중복된 행도그대로 출력
UNION
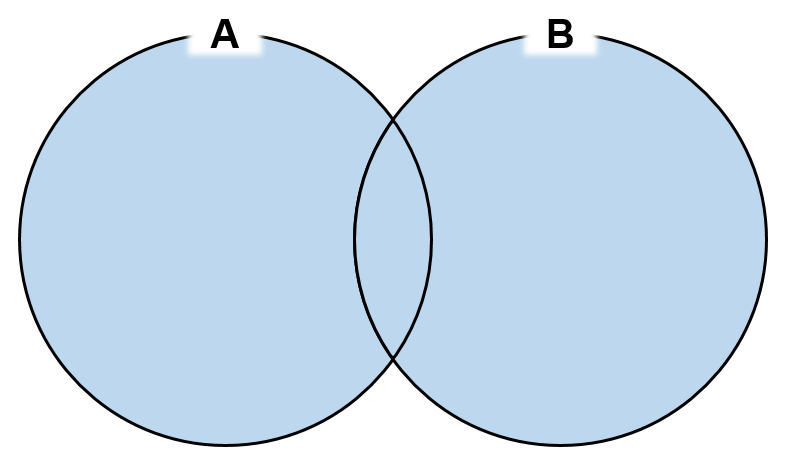
- 각 쿼리 결과 집합의
합집합 중복된 행은한 줄로 출력- 중복된 행 없을 때는
union사용하는 것이union all보다 성능상 불리
->데이터베이스 내부적으로 중복된 행 제거 과정을 거치므로
INTERSECT
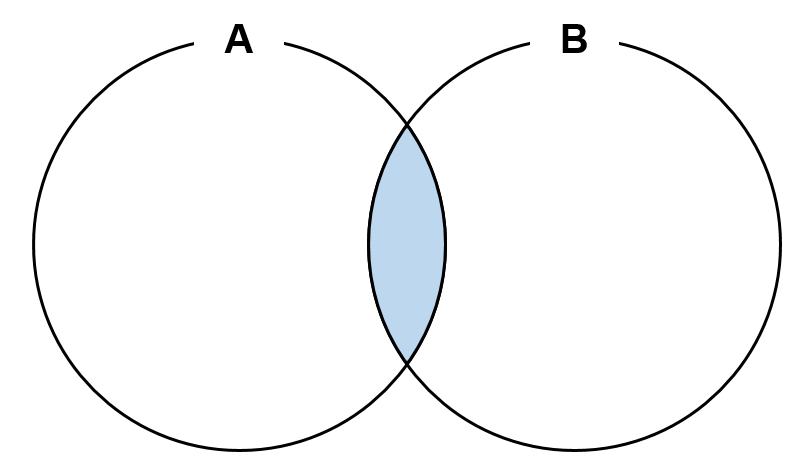
- 각 쿼리 결과 집합의
교집합 중복된 행은한 줄로 출력
MINUS/EXCEPT

앞에 있는 쿼리 결과 집합에서뒤에 있는 쿼리의 결과 집합을 뺀차집합중복된 행은한 줄로 출력NOT EXISTS또는NOT IN연산으로 구현 가능
🏌🏻♀️계층형 질의(계층 쿼리)
- 테이블에
계층 구조를 이루는 컬럼이 존재시계층 쿼리를 이용해 데이터 출력 계층형 데이터:동일 테이블에계층적으로상위와하위데이터가 포함된 데이터계층 쿼리에서정렬을 위해선형제들끼리 정렬하는ORDER SILBLINGS BY절을 사용MSSQL에서의계층형 질의문은CTE(Common Table Expression)을재귀 호출함으로써 계층 구조 전개MSSQL에서 계층형 질의문은앵커 멤버를 실행하여기본 결과 집합을 만들고이후 재귀 맴버를 지속적으로 실행PRIOR키워드는SELECT, WHERE절에서도 사용 가능Oracle의 계층형 질의문에서WHERE절은모든 전개를 진행한 후의필터 조건
connect by prior 자식=부모; --순방향 전개
connect by prior 부모=자식; --역방향 전개select level,
sys_connect_by_path('['||cate_type||']'||cate_name,'-') as path
from cate
start with parent_cate is null
connect by prior cate_name=parent_cate;
LEVEL: 현재의depth. 루트 노드는1SYS_CONNECT_BY_PATH(컬럼, 구분자):루트노드부터현재노드까지의 경로 출력START WITH: 경로 시작 루트노드 생성. 계층 구조 전개 시작 위치 지정CONNECT BY:루트로부터자식 노드를 생성해주는 절. 조건에 만족하는 데이터 없을 때 까지 노드 생성PRIOR:바로 앞의부모 노드 값반환. 현재 읽은 칼럼 지정
select level, cate_type, cate_name, parent_cate,
connect_by_root cate_name as root,
connect_by_isleaf as leaf
from cate
start with parent_cate is null
connect by prior cate_name=parent_cate;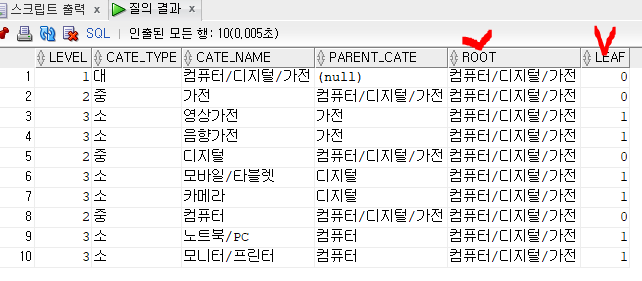
CONNECT_BY_ROOT 컬럼:루트 노드의 주어진컬럼값 반환CONNECT_BY_ISLEAF:가장 하위 노드인 경우1반환, 그 외에는0
select level,
sys_connect_by_path('['||cate_type||']'||cate_name,'-') as path
from cate
start with cate_type='소'
connect by cate_name=prior parent_cate;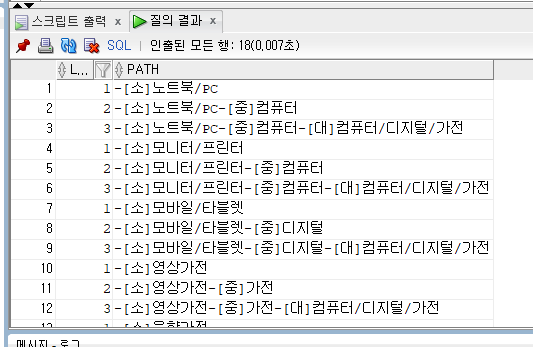
👀셀프 조인(SELF JOIN)
한 테이블 내에연관이 있는두 개의 컬럼이 존재할 경우 수행- 나 자신과의 조인
같은 테이블이 두번 이상 등장하므로Alias반드시 표기 필요
ex) 쇼핑몰 상품의 카테고리가 대-중-소

select a.cate_type, a.cate_name, b.cate_type, b.cate_name
from cate a, cate b
where a.cate_name=b.parent_cate
and a.cate_type='대';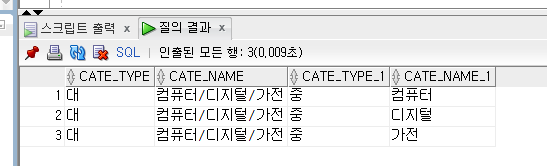
select a.cate_type, a.cate_name, b.cate_type, b.cate_name, c.cate_type, c.cate_name
from cate a, cate b, cate c
where a.cate_name=b.parent_cate
and b.cate_name=c.parent_cate;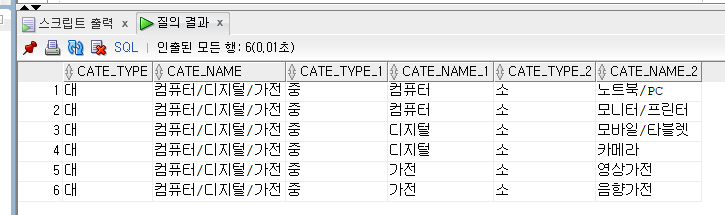
📯서브쿼리(Subquery)
서브쿼리 정의
서브쿼리(subquery) : 하나의 쿼리 안에 존재하는 또 다른 쿼리
밖의 쿼리:메인 쿼리안에 있는 쿼리:서브 쿼리메인 쿼리의컬럼이 포함된 서브쿼리를연관 서브쿼리, 메인 쿼리의 컬럼이 포함되지 않은 서브쿼리를비연관 서브쿼리라고 함다중 행 서브쿼리:IN절과 함께 사용 (=과 함께 사용 불가)SELECT절:스칼라 서브쿼리FROM절:인라인 뷰WHERE절, HAVING절:중첩 서브쿼리
서브쿼리 사용시 주의사항
- 서브쿼리를
괄호로 감싸서 사용 - 서브쿼리는
단일 행또는복수 행비교 연산자와 함께 사용 가능 단일 행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관 없다.서브쿼리에서는ORDER BY를 사용하지 못한다.- ORDER BY절은
select절에 오직한 개만 올 수 있기 때문에 메인쿼리의 맨 마지막 문장에order by위치.
스칼라 서브쿼리(Scalar Subquery)
SELECT절에 위치컬럼이 올 수 있는 대부분 위치에 사용 (update 문의 set절, order by절)컬럼 대신 사용되므로반드시 하나의 값만을 반환해야 함(하나의 컬럼만)
select m.product_id,
(select s.product_name
from product s
where s.product_id=m.product_id) as product_name,
m.member_id,
m.content
from product_review m;
--error
select m.product_id,
(select s.product_name, s.price
from product s
where s.product_id=m.product_id) as product_name,
m.member_id,
m.content
from product_review m;
--correct
select m.product_id,
(select s.product_name
from product s
where s.product_id=m.product_id) as product_name,
(select s.price
from product s
where s.product_id=m.product_id) as price,
m.member_id,
m.content
from product_review m;인라인 뷰(Inline View)
FROM절에 위치테이블명이 올 수 있는 위치에 사용서브쿼리의 결과가 마치 실행 시에동적으로 생성된 테이블인 것 처럼 사용 가능- 인라인 뷰는
SQL 문이 실행될 때만임시적으로 생성되는동적인 뷰이기 때문에, 해당 정보가 DB에 저장X
select m.product_code,s.product_name, s.price,m.meber_id, m.content
from product_review m,
(select product_code, product_name, price from product) s
where m.product_code=s.product_code;중첩 서브쿼리(Nested Subquery)
WHERE절과HAVING절에 사용
메인 쿼리와의 관계
비연관 서브쿼리(un-correlated subquery):서브쿼리내에메인 쿼리컬럼존재 X
select name, job, birthday, agency_code
from ent
where agency_code = (select agency_code
from agency
where agency_name='dang');2.연관 서브쿼리(Correlated subquery) : 서브쿼리 내에 메인 쿼리 컬럼 존재
select order_no, drink_code, order_cnt
from cafe_order a
where order_cnt = (select max(order_cnt)
from cafe_order b
where b.drink_code=a.drink_code);반환하는 데이터 형태
1. 단일 행 서브쿼리(Single Row) : 서브쿼리가 항상 1건 이하의 데이터 반환
단일행 비교 연산자(=,<,>,<=,>=,<>)와 함께 사용
select * from product
where price=(select max(price) from product);2.다중 행 서브쿼리(Multi Row) : 서브쿼리가 여러 건(2건 이상)의 데이터 반환
다중행 비교 연산자(IN,ALL,ANY,SOME,EXISTS)와 함께 사용
select * from product
where product_code in (select product_code from product_review);3.다중 컬럼 서브쿼리(Multi Column) : 서브쿼리가 여러 컬럼의 데이터 반환
MSSQL에서 지원X
select * from employees
where (job id,salary) in (select job_id, max_salary
from jobs
where max_salary=10000);👓뷰(View)
- 특정
SELECT 문에이름을 붙여서재사용이 가능하도록 저장해놓은오브젝트 테이블처럼 사용 가능가상테이블실제데이터 저장 X, 해당 데이터를 조회해오는select문만 가지고 있음실제 데이터를 저장하고 있는 뷰를 생성하는 기능을 지원하는DBMS도 존재
뷰 생성
create or replace view 이름 as
select 컬럼들
from 테이블;
--ex
create or replace view dept_mem as
select a.depart_id,
a.depart_name,
b.first_name,
b.last_name
from depart a
left outer join employees b
on a.depart_id=b.depart_id;뷰 삭제
drop view dept_mem;뷰 특징
보안성:보안이 필요한 컬럼을 가진 테이블일 경우,해당 컬럼을 제외한 별도의 뷰를 생성하여 제공함으로써 보안 유지독립성:테이블 스키마가 변경되었을 경우어플리케이션은 변경하지 않고관련 뷰만 수정.테이블 구조가 변경되어도뷰를 사용하는응용 프로그램은 변경하지 않아도 된다.편리성:복잡한 쿼리 구문을뷰 명으로 단축시킴으로써가독성을 높이고편리하게 사용 가능.복잡한 질의를 뷰로 생성함으로써 관련 질의를단순하게 작성할 수 있으며, 해당 형태의 sql문을 자주 사용할 때뷰를 이용하면 편리하게 사용 가능투명성X-- 내부적으로 뷰를 생성하는 sql을 볼 수 없기 때문
📚그룹 함수
그룹 함수 정의
그룹 함수: 데이터를GROUP BY하여나타낼 수 있는 데이터를 구하는 함수집계 함수(count, sum, avg, max, min)과소계 함수(rollup, cube, grouping sets)ROLLUP함수는인수의 순서에 따라결과 달라짐CUBE/GROUPING SETS함수는 인수의 순서가 바뀌어도같은 결과일반 그룹 함수를 사용하여CUBE, GROUPING SETS, ROLLUP과 같은 결과 추출 가능- 대상 컬럼 중
집계된 컬럼 이외의 대상 컬럼 값은 NULL값 반환
select ~~
from ~~~
group by rollup(~~) --or group by cube(~~) etc..ROLLUP
소그룹 간 소계및총계계산 함수ROLLUP(A,B): A, B로 그룹핑, A로 그룹핑, 총합계
CUBE
소그룹 간 소계및총계를다차원적으로 계산rollup이일방향 소계라면,cube는 조합할 수 있는모든 그룹에 대한 소계집계CUBE(A,B,C): A,B,C로 그룹핑, A,B로 그룹핑, B,C로 그룹핑, A,C로 그룹핑, A로 그룹핑, B로 그룹핑, C로 그룹핑, 총합계- rollup 함수에 비해
시스템에 많은 부하 발생 - 결합 가능한 모든 값에 대하여
다차원집계를 생성 - 결과에 대한 정렬이 필요한 경우
order by절에 명시적으로정렬 칼럼 표시
GROUPING SETS
특정 항목에 대한소계계산인자값으로rollup이나cube사용 가능grouping sets(a,b,()): A로 그룹핑, B로 그룹핑, 총합계grouping sets(a,rollup(b,c)): a로 그룹핑, b,c로 그룹핑, b로 그룹핑,총합계group by와union all을 이용하여 동일한 결과 출력 가능- 인수의 순서가 바뀌어도
동일 결과
GROUPING
ROLLUP, CUBE, GROUPING SETS등과 함께 사용되며소계를 나타내는ROW 구분- 이전까지는
그룹핑 기준 칼럼 제외모두null로 표현하였지만, 원하는 위치에 원하는 텍스트 출력 가능 소계가 계산된ROW에서는GROUPING 함수 결과값이1, 나머지는0
select order_dt,
grouping(order_dt),
count(*)
from order
group by rollup(order_dt)
order by order_dt;총합계만 order_dt가 null로 출력되고 grouping은 1로 출력된다.
나머지에서는 다 0으로 출력
select case grouping(order_dt)
when 1 then 'total' else order_dt
end as order_dt,
count(*)
from order
group by rollup(order_dt)
order by order_dt;총 합계가 TOTAL로 출력
select case grouping(order_dt)
when 1 then 'all dates' else order_dt
end as order_dt,
case grouping(order_item)
when 1 then 'all items' else order_item,
count(*)
from order
group by rollup(order_dt,order_item)
order by order_dt;order_dt 그룹핑 시 order_item은 all items로 나오고,
전체 합계시에는 (all dates, all items)로 나온다.
TOP
ex ) 테이블에서 급여가 높은 2명을 내림차순으로 출력, 같은 급여를 받는 사원은 같이 출력
select top(2) with ties ename, sal
from emp
order by sal desc;🌆윈도우 함수 - 다중행 함수
OVER키워드와 함께 사용Partition과Group By구문은 의미적으로 유사Partition구문이 없으면전체 집합을 하나의 Partition으로 정의하는 것과 동일- 윈도우 함수 처리로 인해 결과 건수는
동일 - 윈도우 함수 적용 범위는
Partition을 넘을 수 없다.
윈도우 함수 종류
| 함수 | 종류 |
|---|---|
| 순위 함수 | rank, dense_rank, row_number |
| 집계 함수 | sum,max,min,avg,count |
| 행 순서 함수 | first_value,last_value,lag,lead |
| 비율 함수 | cum_dist, percent_rank, ntile, ratio_to_report |
순위 함수
1.RANK()
- 순위를 매기면서
같은 순위 존재시 존재하는 수 만큼 다음 순위 건너뜀 ORDER BY를 포함한QUERY문에서 특정 칼럼에 대한순위를 구하는 함수.- 동일한 값에 대해서는 동일한 순위 부여
--날짜별 주문 건수 카운트해서 순위
select order_dt, count(*),
rank() over(order by count(*) desc) as rank
from order
group by order_dt;
--출력
1
2
3
4
5
6
7
7
7
10--부서별로 급여가 높은 사원부터 순위
select first_name, last_name, depart_id, salary,
rank() over(partition by depart_id order by salary desc) as rank
from employees;
2.DENSE_RANK()
- 순위를 매기면서
같은 순위가 존재하더라도다음 순위를 건너뛰지 않고이어서 매긴다 - 동일한 순위를 하나의 건수로 취급
--날짜별 주문 건수 카운트해서 순위
select order_dt, count(*),
dense_rank() over(order by count(*) desc) as dense_rank
from order
group by order_dt;
--출력
1
2
3
4
5
6
7
7
7
8
3.ROW_NUMBER()
- 순위를 매기면서
동일한 값이라도각기 다른 순위 부여 - 동일한 값이라도 고유한 순위 부여
집계 함수
1.SUM()
- 데이터의
합계구하는 함수 range옵션은동일한 데이터가 있을 경우모두 합한 값출력
-- 데이터의 누적값 구함
select stu_name, subject, score,
sum(score) over (partition by stu_name
order by subject desc
range unbounded preceding) as total
from sqld;
--order by절에 sum컬럼 명시시 누적합 집계
--하지만, 전체 학생들의 점수 누적 합
select stu_name, subject, score,
sum(score) over (order by score desc) as total
from sqld;
2.MAX()
- 데이터의
최댓값구하는 함수
--과목별 최대 점수 받은 사람
select stu_name,subject, score
from (select stu_name, subject,score,
max(score) over(partition by subject) as max_score
from sqld)
where score=max_score;
3.MIN()
- 데이터의
최솟값구하는 함수
4.AVG()
- 데이터의
평균값구하는 함수
5.COUNT()
- 데이터의
건수구하는 함수
select stu_name, subject, score,
count(*)over (partition by subject) as pass
from sqld
where result='pass';
--과목별 본인보다 점수가 높거나 "같은" 건수 카운트
select stu_name, subject, score,
count(*)over (partition by subject
order by score desc
range unbounded preceding) as high
from sqld;
--출력
1
2
3
4
5
1
2
3
5 --밑과 동일값
5 --본인도 카운트 하기 때문
행 순서 함수
order by뒤에는 꼭 범위를 명시해주자!
1.FIRST_VALUE()
- 파티션 별
가장 선두에 위치한 데이터를 구하는 함수 MSSQL에서 지원 X
select stu_name, subject, score,
first_value(score) over(order by score) as first
from sqld;제일 첫 행의 score인 7이 모든 행의 first열에 기록
2.LAST_VALUE()
- 파티션 별
가장 끝에 위치한 데이터를 구하는 함수 MSSSQL에서 지원 X
select stu_name, subject, score,
last_value(score) over(order by score) as last
from sqld;
--출력은 각자의 score로 됨각 row의 score과 동일한 값이 출력된다.
windowing 절의 default가 RANGE UNBOUNDED PRECEDING이기 때문이다.
=> 파티션 범위 : 맨 위 끝 행~현재 행까지
select stu_name, subject, score,
last_value(score) over(order by score
range between unbounded preceding
and unbounded following) as last
from sqld;
3.LAG()
- 파티션 별로
특정 수만큼앞선데이터를 구하는 함수 MSSQL에서 지원XLAG(score,3): 3칸 앞선 행의 값
ex) 7 12 15 16일 때 16에게 7이 lag(score,3)- 두번째 인자값 생략시
default는1
4.LEAD()
- 파티션 별
특정 수만큼뒤에 있는데이터를 구하는 함수 MSSQL에서 지원XLEAD(score,3): 3칸 뒤의 행 값LEAD(sal,3,-1): 만약 null일 경우 세번 째 인자인-1이 나옴
비율 함수
1.RATIO_TO_REPORT
- 파티션 별
합계에서 차지하는비율을 구하는 함수 MSSQL에서 지원X- 자기점수/
sum(행)
2.PERCENT_RANK
- 해당 파티션의
맨 위행을0, 맨아래행을1로 놓고,현재 행이 위치하는 백분위 순위 값을 구하는 함수 MSSQL에서 지원X- Rank-1/count-1
3.CUME_DIST
- 해당 파티션에서의
누적 백분율을 구하는 함수 - 결과값은
0보다크고1보다작거나 같은 값 MSSQL에서 지원X- 현재 행까지의 누적 건수/전체 건수
4.NTILE
- 주어진 수 만큼 행들을
n등분한 후 현재 행에 해당하는 등급 구하는 함수 - 1보다 큰 값 출력 가능
select stu_name, subject,score,
ntile(3) over (order by score desc) as ntile
from sqld;
-- 행이 총 10개라면
1
1
1
1
2
2
2
3
3
3
할당 행 남을 경우 맨 앞의 그룹부터 하나씩 채워짐윈도우 함수 사용 옵션
| 범위 | 뜻 |
|---|---|
| unbounded preceding | 위쪽 끝 행 |
| unbounded following | 아래쪽 끝 행 |
| current row | 현재 행 |
| n preceding | 현재 행에서 위로 n만큼 이동 |
| n following | 현재 행에서 아래로 n만큼 이동 |
| 기준 | 뜻 |
|---|---|
| ROWS | 행 자체가 기준 |
| range | 행이 가지고 있는 데이터 값이 기준 |
ex)
--처음부터 현재 행 까지. ==range unbounded preceding과 같은 의미
range between unbounded preceding and current row;
--현재 행이 가지고 있는 값보다 10만큼 적은 행 부터 현재 행 까지
--==range 10 preceding과 같은 의미
range between 10 preceding and current row;
--현재 행 부터 끝까지
rows between current row and unbounded following;
--현재 행부터 아래로 5만큼 이동한 행 까지
rows between current row and 5 following;
🧶ROWNUM
- 오라클의
ROWNUM은 슈도 컬럼 - 엑셀의 자동 순번 메기기 처럼
위의 행에서 +1이 되기 때문에where rownum=2처럼 건너뛰기 안됨 - 항상
<조건 또는<=조건으로 사용
select rownum, 이름, 국어, 영어, 수학
from (select 이름, 국어, 영어, 수학
from exam_score
order by 국어 desc, 영어 desc, 수학 desc)
where rownum<=5;
-- 점수 상위 5개 뽑아내는 것 !! 꼭 인라인 뷰로 사용하자
--아래는 안됨
select rownum, 이름, 국어, 영어, 수학
from exam_score
where rownum<=5
order by 국어 desc, 영어 desc, 수학desc
--where 절보다 order by는 늦게 실행되기 때문.💨DCL
DCL 정의
DCL(Data Control Language) : 데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어
USER를 생성하고권한을 부여하거나 회수하는 명령어- 다른 이에게 권한 부여할 수 있도록 하는 옵션 :
WITH GRANT OPTION - 부여한 권한 연쇄 삭제 :
CASCADE
USER 관련 명령어
하나의 DB는 여러 개의 USER를 가질 수 있다.
1.CREATE USER
- 사용자
생성명령어 CREATE USER권한이 있어야 수행 가능
create user 사용자명 identified by 패스워드;2.ALTER USER
- 사용자
변경명령어
--패스워드 변경
alter user 사용자명 identified by 패스워드;3.DROP USER
- 사용자
삭제명령어
drop user 사용자명 [cascade];cascade 옵션 사용 시 사용자명이 생성한 모든 object 함께 삭제
권한 관련 명령어
1.GRANT
- 사용자에게
권한 부여
grant 권한 to 사용자명;2.REVOKE
- 사용자에게
권한 회수
revoke 권한 from 사용자명;ROLE 관련 명령어
ROLE : 특정 권한들을 하나의 세트처럼 묶는 것
ROLE생성
create role 롤명;2.role에 권한 부여
grant 권한 to 롤명;
--ex
grant create table, create user to create_roll;3.role을 사용자에게 부여
grant 롤명 to 사용자명;📟절차형 SQL(PL/SQL)
PL/SQL의 특징
Block구조로 되어있어 각 기능별로모듈화가능- 변수, 상수 등을 선언하여
SQL 문장 간값을 교환 IF, LOOP등 절차형 언어를 사용하여절차적인 프로그래밍이 가능하도록 함DBMS 에러나사용자 정의 에러를 정의하여 사용 가능PL/SQL은Oracle에 내장되어 있으므로Oracle과PL/SQL을 지원하는 어떤 서버로도프로그램 옮기기 가능- 응용 프로그램의
성능 향상 여러 SQL문장을Block묶고한 번에 block 전부를서버로 보내버리기 때문에통신량 줄일 수 있다- 변수, 상수 등을 사용하여
일반 sql 문장을 실행할 때where절의 조건등으로 대입 가능 Procedure내부에 작성된절차적 코드는PL/SQL엔진이 처리하고,일반적인 sql 문장은sql 실행기가 처리- 프로시저 내에서
다른 프로시저 호출시호출 프로시저의 트랜잭션과는별도로PRAGMA AUTONOMOUS_TRANSACTION선언 시 자율 트랜잭션 처리 가능 => 작성자 기준트랜잭션 분할 가능 동적 SQL또는DDL문장 실행 시EXECUTE IMMEDIATE를 사용해야 함SQL을로직과 함께 DB내에 저장해놓은명령문의 집합사용자 정의 함수는 단독적으로 실행되기 보다는다른 SQL문을 통하여 호출되고그 결과를 리턴하는SQL의 보조적인 역할
저장 모듈(Stored Module)
SQL 문장을 DB서버에 저장하여사용자와애플리케이션사이에공유할 수 있도록 만든 일종의SQL 컴포넌트 프로그램독립적으로 실행되거나다른 프로그램으로부터 실행될 수 있는완전한 실행 프로그램
저장 모듈 종류
프로시저(Procedure)사용자 지정 함수(User Defined Function)트리거(Trigger)
트리거
- 특정한 테이블에
DML문이 수행되었을 때,데이터베이스에서자동으로동작하도록 작성된 저장 프로그램 트리거는데이터 무결성, 일관성을 위해서 사용트리거는트랜잭션 제어 불가,TCL 불가트리거는 DB에로그인 하는 작업에도 정의 가능
프로시저 vs 트리거
| 프로시저 | 트리거 |
|---|---|
| CREATE Procedure 문법 사용 | CREATE Trigger 문법 사용 |
| EXECUTE 명렁어로 실행 | 생성 후 자동 실행 |
| COMMIT, ROLLBACK 실행 가능 | COMMIT, ROLLBACK 실행 안됨 |
📌Cursor(커서)
커서 생성
CURSOR 커서이름 IS 커서정의;--커서 생성
OPEN 커서이름; --커서 사용 시작
FETCH 커서이름 INTO 변수; --커서에서 행 데이터를 가져옴. 커서에서 원하는 결과 추출
CLOSE 커서이름; --커서 종료