📔설명
MODEL : 어떤 목적을 가지고 진짜를 모방한 것
좋은 모델은 목적에 부합하는 모방이라 할 수 있다.
복잡한 현실을 컴퓨터의 표로 담는 것이 된다~
이제부터 복잡한 현실세계의 정보들을 추상화하고 가공하여 데이터베이스로 옮겨보자!
🎐전체 흐름
업무파악 -> 개념적 데이터 모델링 -> 논리적 데이터 모델링 -> 물리적 데이터 모델링📜업무파악
업무파악 : 우리가 할 일이 무엇인지 파악
의뢰한 사람이 어떤 것을 꿈꾸고 있는지 파악하는 단계이다!
- 산출물 :
기획서
컴퓨터 공학이 해결하는 문제는 컴퓨터 자체의 문제를 해결하는 것과 현실의 문제를 해결하는 것으로 나뉜다.
전자는 DB를 만드는 사람, 후자는 DB를 이용해 현실의 문제를 해결하는 사람.
꿈꾸는 것을 UI로 그려보는 것이 좋다!
ovenapp이라고 카카오에서 만든 것이 있다.
새로운 프로젝트를 만들어보자!
이 프로젝트는 UI가 어떻게 구성될지를 만들어보는 사이트라 생각하면 좋을 것 같다!
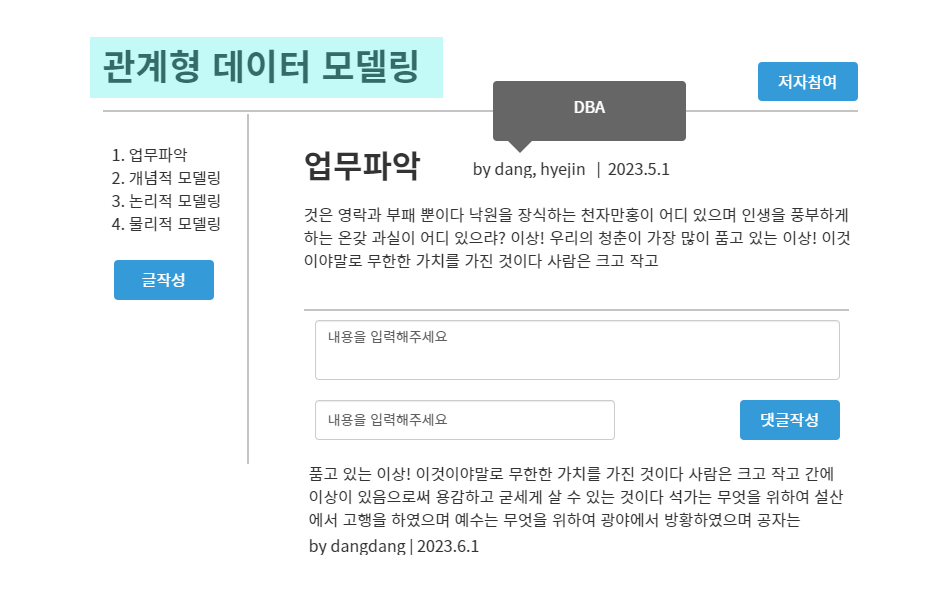
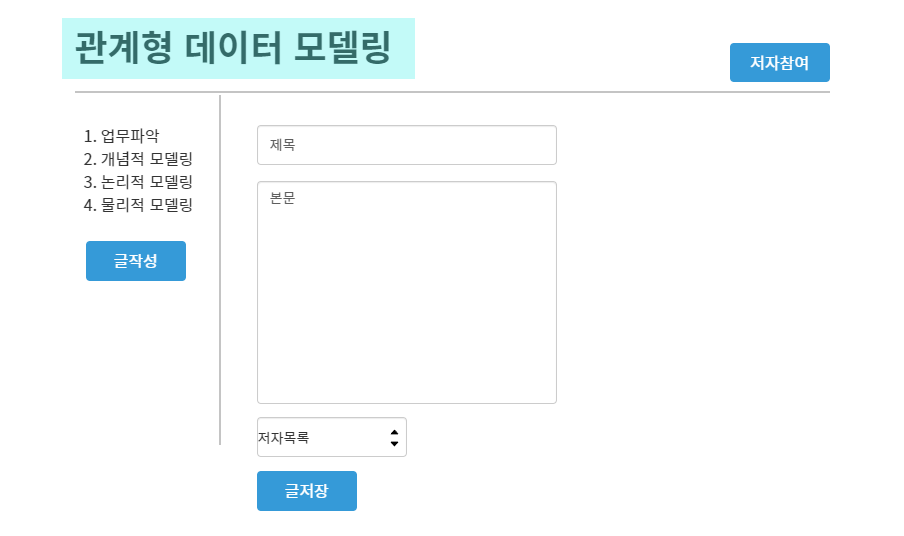
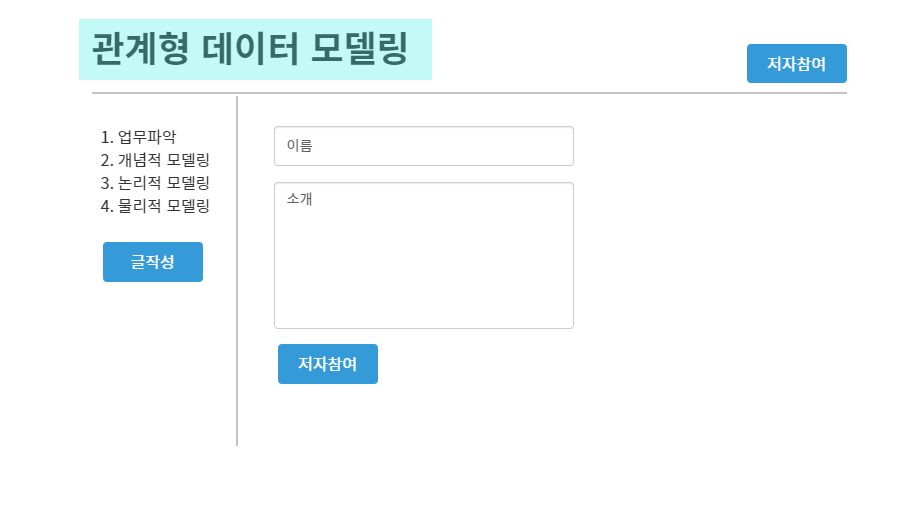
UI는 위와 같아질 것이다!
🧾개념적 데이터 모델링
개념적 데이터 모델링 : 현실의 업무를 뜯어서 개념을 찾아내는 단계
내가 하고자 하는 일에는 어떠한 개념들이 있고, 각각의 개념들은 어떻게 서로 상호작용 하고 있는지 생각하는 단계
- 산출물 :
ERD
개념적 모델링은 관계형 데이터 모델링의 핵심이다!
개념적 모델링은 현실에서 개념을 추출하는 일종의 필터를 제공해준다.
그리고, 개념에 대해서 다른사람들과 대화하게 해주는 언어로서 작용한다.
이것을 가능하게 해주는 것이 Entity Relationship Diagram이다.
ERD는 현실을 3개의 관점으로 바라볼 수 있게 해준다.
- 정보(속성)
- 그룹(엔터티)
- 관계
ERD는 매우 쉽게 표로 전환할 수 있다!
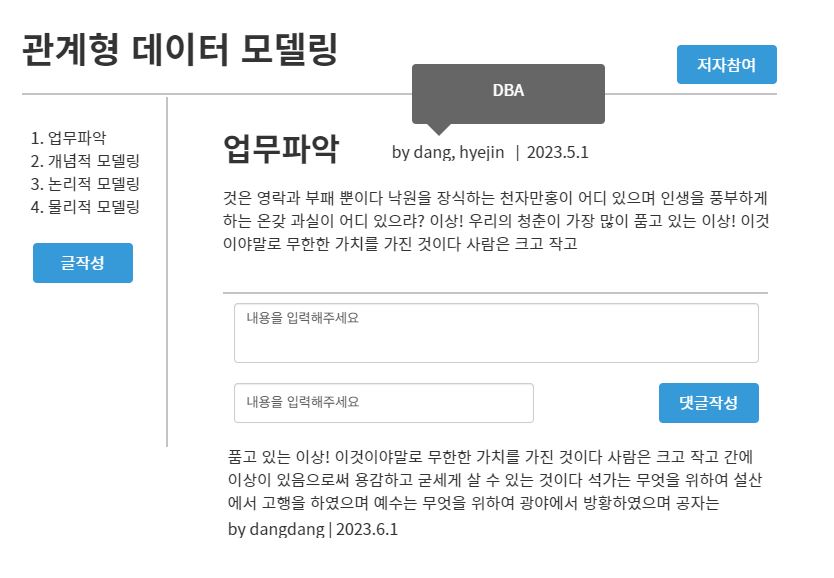
우리가 만들려고 하는 업무에 보면 많은 정보가 있다.
글제목, 저자 이름, 댓글 내용 등등등.. 서로 연관된 정보를 묶어주는 틀을 먼저 정하자!
글, 저자, 댓글
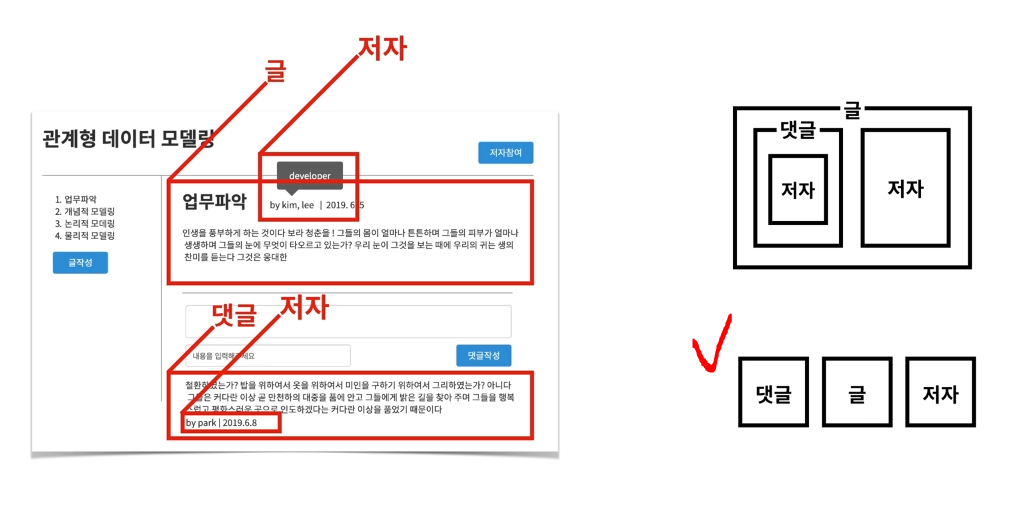
우리는 RDB를 배우는 것이기 때문에, 두번째로 선택하는 것이 좋다!
왜냐하면, RDB는 내포관계를 허용하지 않기 때문이다!
또한 한 테이블에 저렇게 저장하면, 중복되는 데이터도 많이 발생하게 된다.
즉, 주제에 따라서 테이블을 쪼개야 한다.
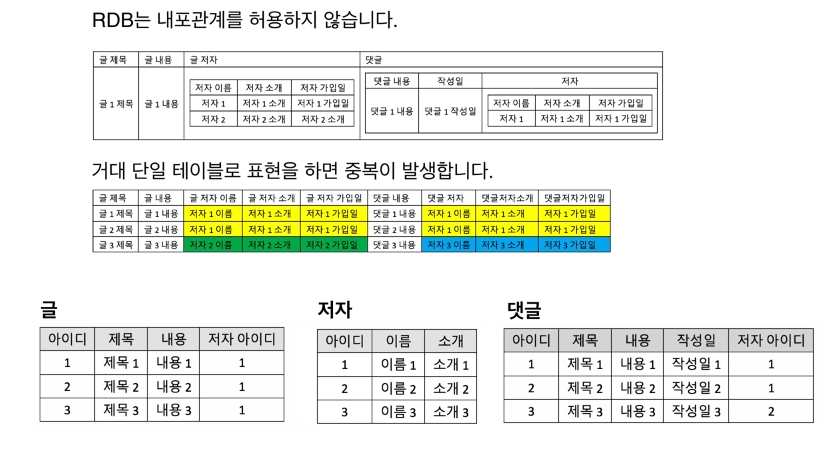
이렇게 표를 쪼개게 되면, 주제에 따른 속성들을 그룹핑 할 수 있다.
만약, 글에 대한 정보만 필요하다면 글에 대한 표만 조회해서 컴퓨터의 자원을 아낄 수 있다!
제일 좋은 건 JOIN할 때 이다!
위에 찾아낸 엔티티는 나중에 테이블로 변경이 된다.
글이라는 데이터는 실제 데이터가 아니고, 제목, 생성일, 본문 등의 정보를 그룹핑 한 것이 글이라는 엔터티가 된다. 이것을 속성이라고 하고 컬럼이 된다.
튜플은 행이 된다!
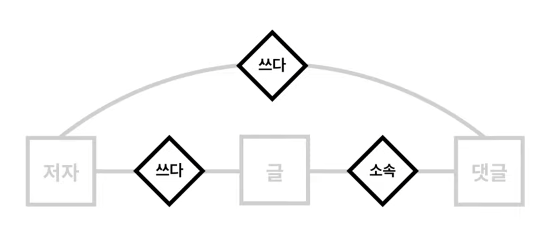
글과 저자는 서로 쓰다라는 관계를 가지고 있다.
그리고 글과 댓글은 서로 소속하다로 이루어지고
저자와 댓글도 쓰다로 관계가 이루어진다.
즉, 연관성을 표현해준 것이다.
자세한 건 위에 올린 게시글 내용을 보면 좋을 것이당!
ERD를 그리기 위해서
사이트에 들어가자!
엔터티 추출
읽기에서는 찾기 어렵지만, 쓰기화면에서 보면
저자화면, 글화면, 댓글 화면을 보면 엔티티를 추출하기 쉽다.
쓰기 화면에서 추출된 엔터티는 글 , 저자, 댓글 이다.
엔터티 배치
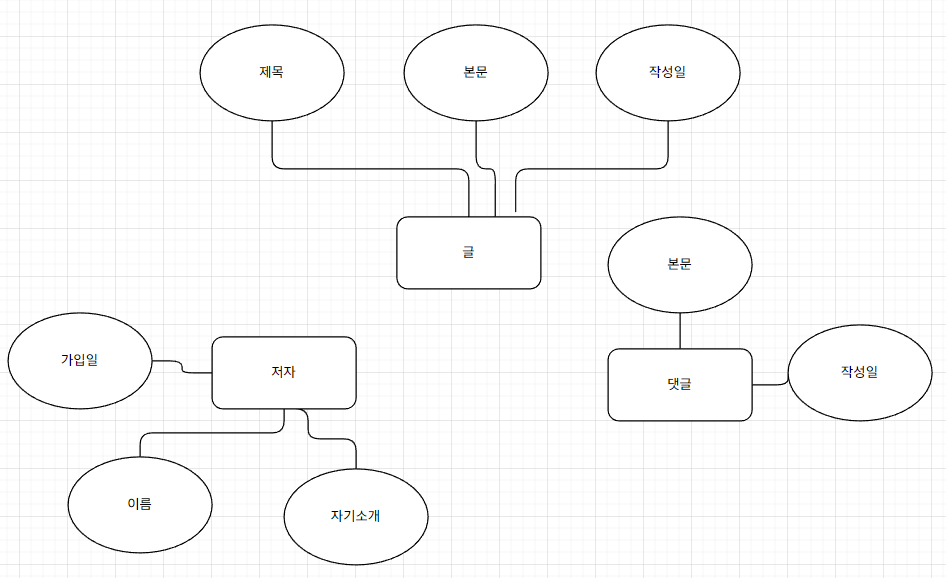
속성 정의
저자들만이 댓글을 작성할 수 있도록 변경하자.
그러면 댓글 입력 시, 내용 밑에는 작성자의 명을 선택할 수 있게 선택상자로 바꿔야 한다.
식별자 지정
기본키가 아닌 후보키들은 대체키라고 한다.
글ID라는 인조 식별자를 추가해주자.
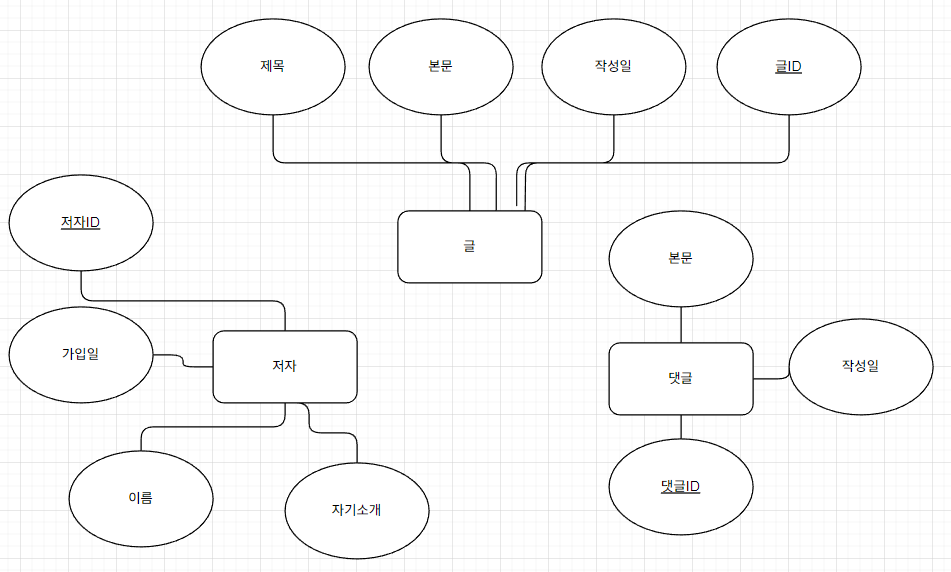
관계 설정
글과 댓글사이에 관계가 있고, 저자와 글 사이에 관계가 있고,
저자와 댓글사이에 관계가 있다.
관계명
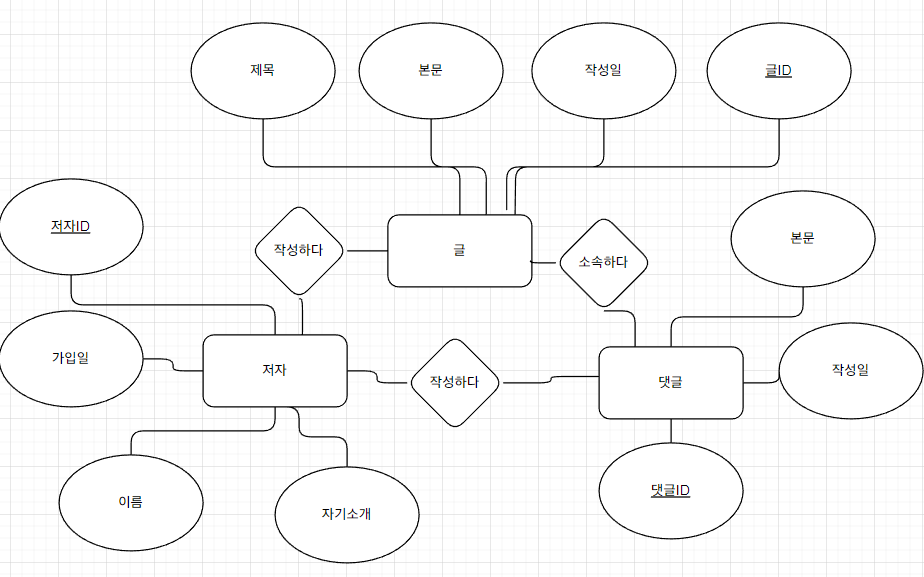
관계 참여도 (관계 차수)
Cardinality
1:1 관계
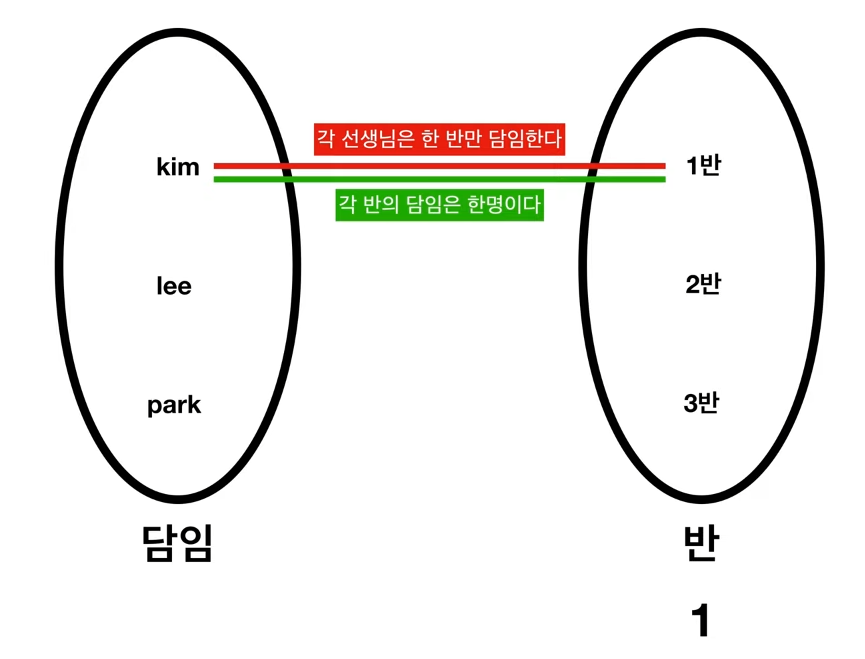
각 담임은 한개의 반을 담당할 수 있고, 각 반의 담임은 한명이다.
1:M관계
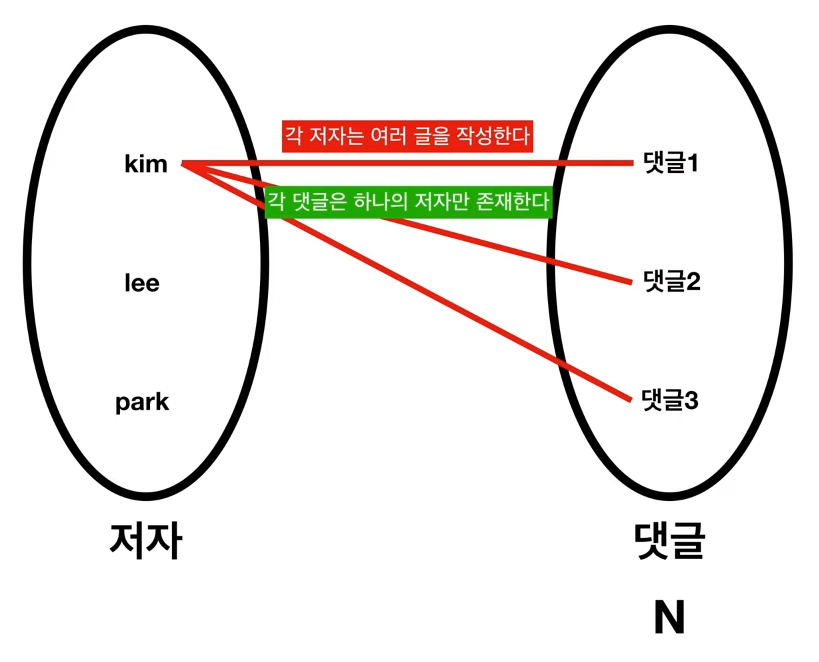
각 저자는 여러개의 댓글을 작성할 수 있고, 각 댓글은 저자가 한명이다.
M:N 관계
하나의 글을 여러명이 편집할 수 있다고 생각해보자.
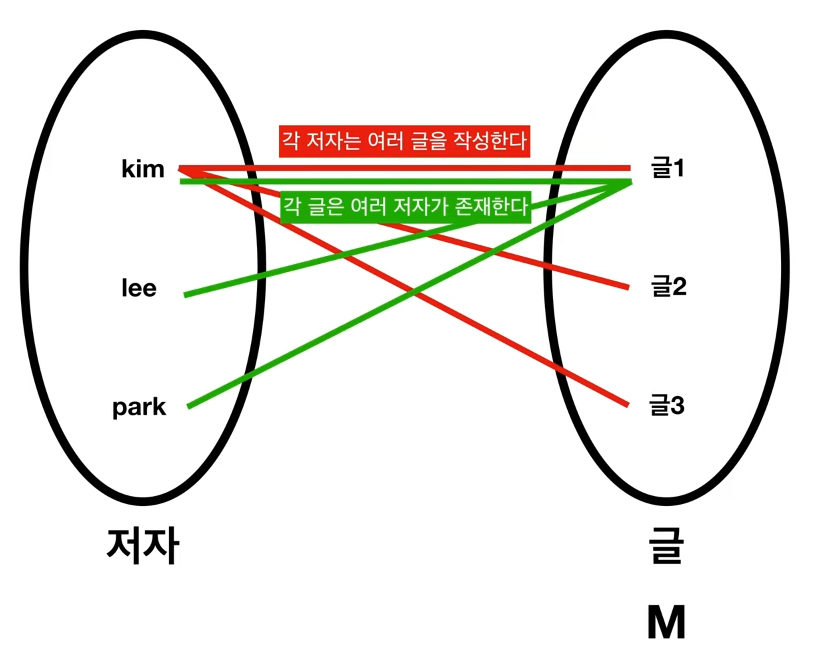
각 저자는 여러개의 글을 작성할 수 있고, 각 글은 여러명의 저자가 존재한다.(편집가능)
관계필수/선택 여부
Optionality
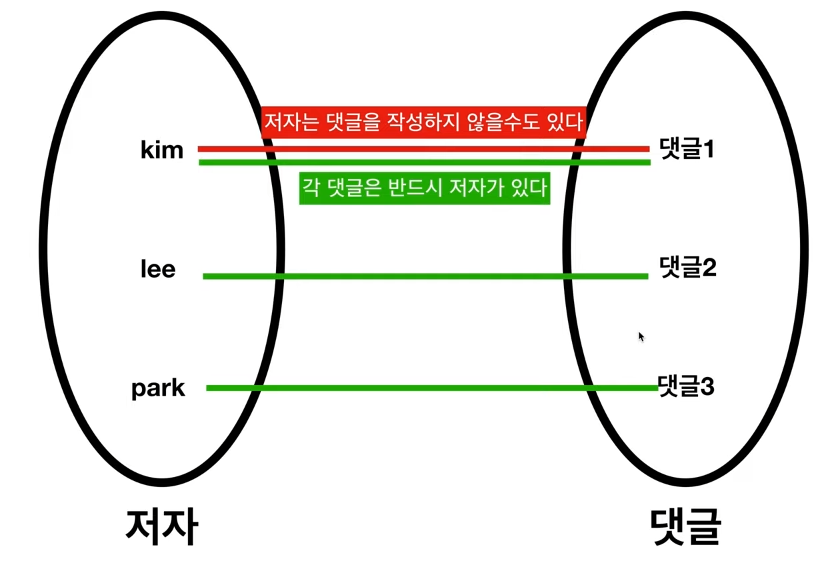
저자는 댓글을 작성하지 않을 수도 있다.(선택) 즉, 저자에게 댓글은 Optional 이다. (O로 표시)
댓글이 존재한다면, 반드시 저자를 가지고 있어야 한다. (필수 -|로 표시)
글은 댓글을 가질 수 있거나 여러개 가질 수 있다!
댓글은 하나의 글에 포함되며, 반드시 글을 가지고 있어야 한다.
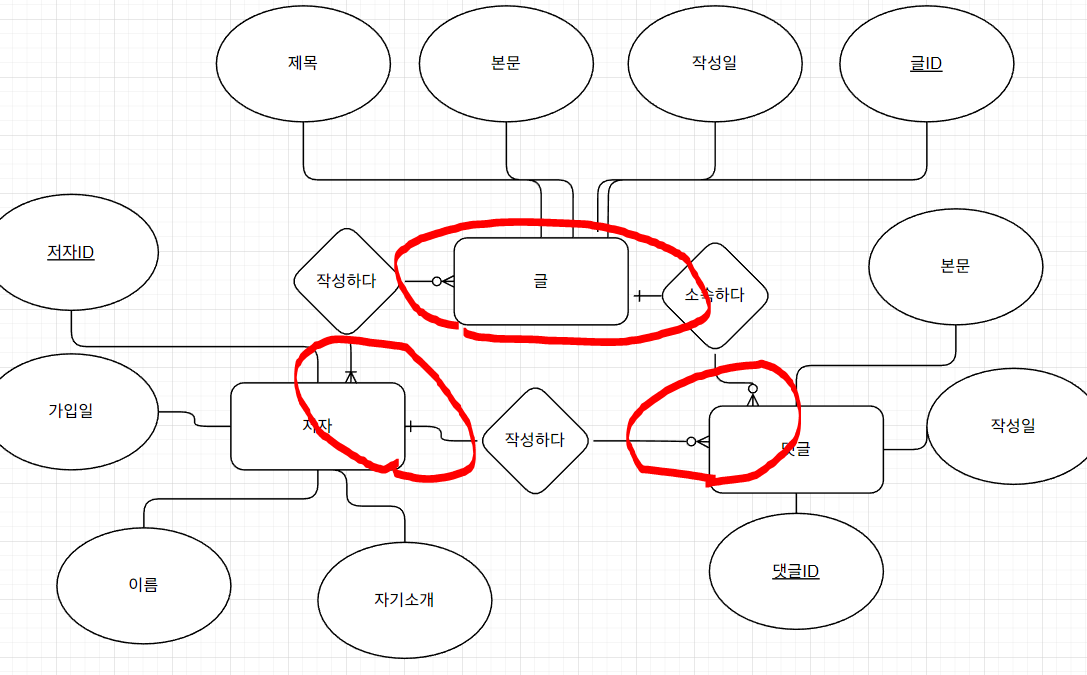
관계차수와 필수/선택을 하면, 이렇게 나온다!!
여기 들어가면 쉽게 알 수 있게 만들어두셨다!
🎫논리적 데이터 모델링
논리적 데이터 모델링 : 개념을 관계형 데이터 베이스에 맞게 구성을 하는 단계
RDB의 패러다임에 맞는 표로서 우리가 생각한 개념을 전환
Mapping Rule : ERD를 통해 표현한 내용을 관계형 DB에 맞는 형식으로 전환할 때 사용할 수 있는 방법론
엔티티->테이블
속성->컬럼
관계->PK,FK테이블 및 컬럼 생성
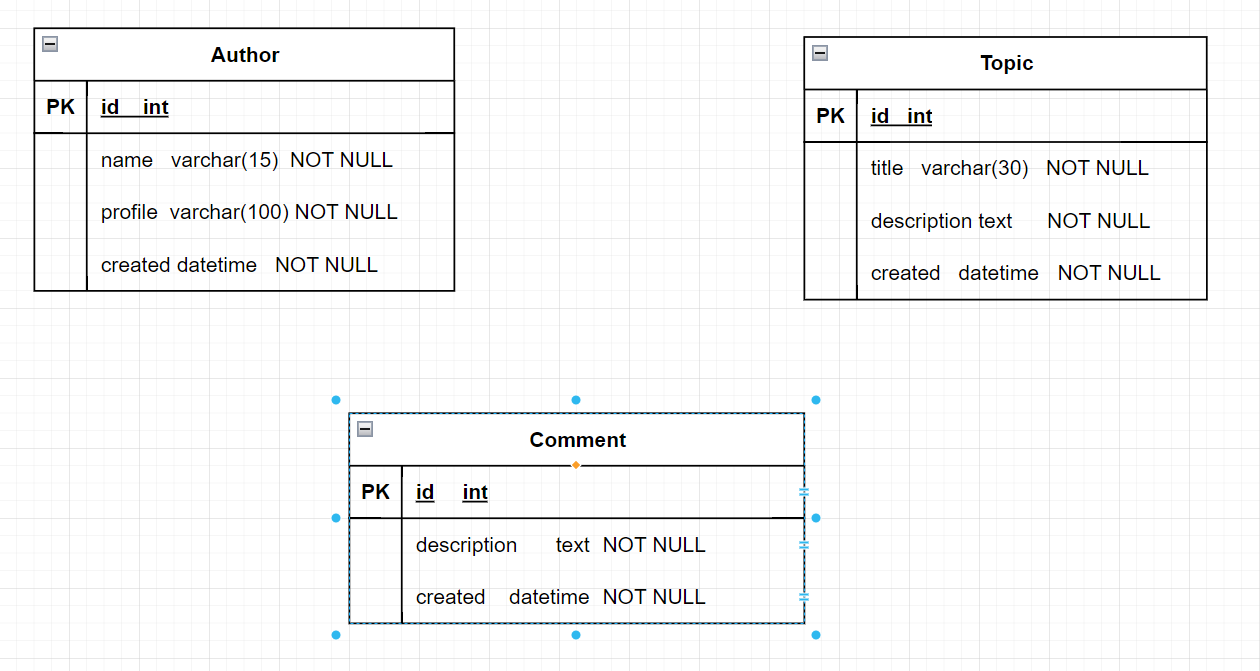
먼저 PK 까지 지정해줬다.
Entity 이름은 대문자가 규칙!!
PK, FK 지정
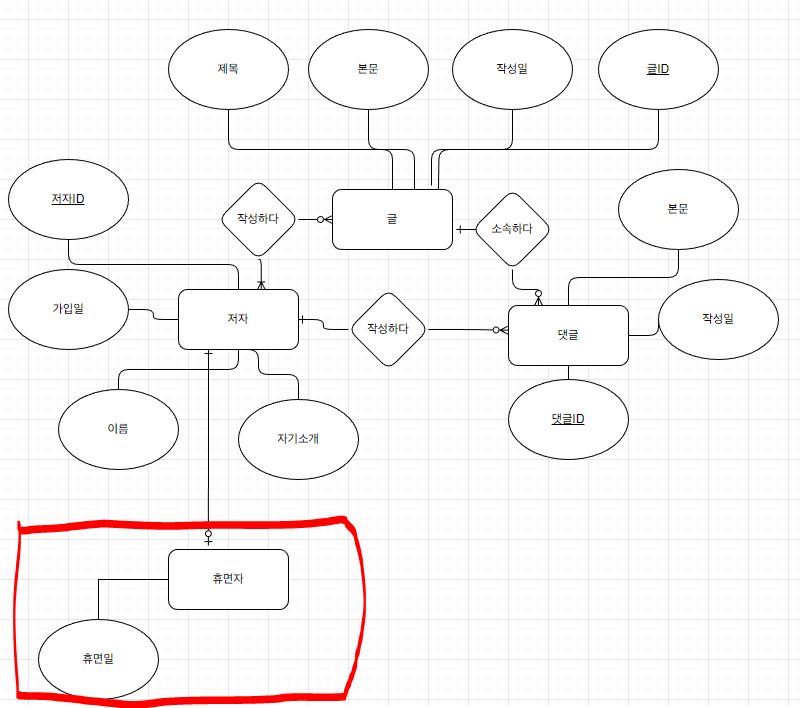
1:1 관계 생성을 위해 휴면 엔터티를 추가로 생성해주었다.
저자는 휴면ID가 없어도 잘 생성되지만, 휴면은 저자ID가 없으면 생성되지 않는다. 이렇게 저자를 부모, 휴면,을 자식테이블이라고 한다.
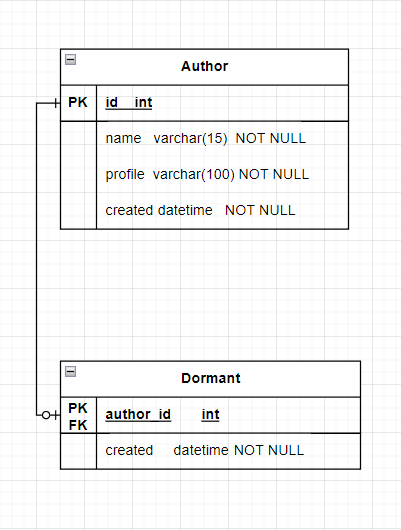
그러므로, 휴면자는 Author의 PK를 FK로 받아와서 저렇게 된다.
그리고, 저자는 휴면하지 않을 수 있으므로 선택관계가 된다.
1:M관계는 하나도 헷갈리지 않는다. 1쪽에 PK, M쪽에 FK를 주면 되기 때문이다.

댓글의 테이블을 저렇게 만들어야 한다. 둘다 각각 author, topic의 PK를 받아온 것이다.
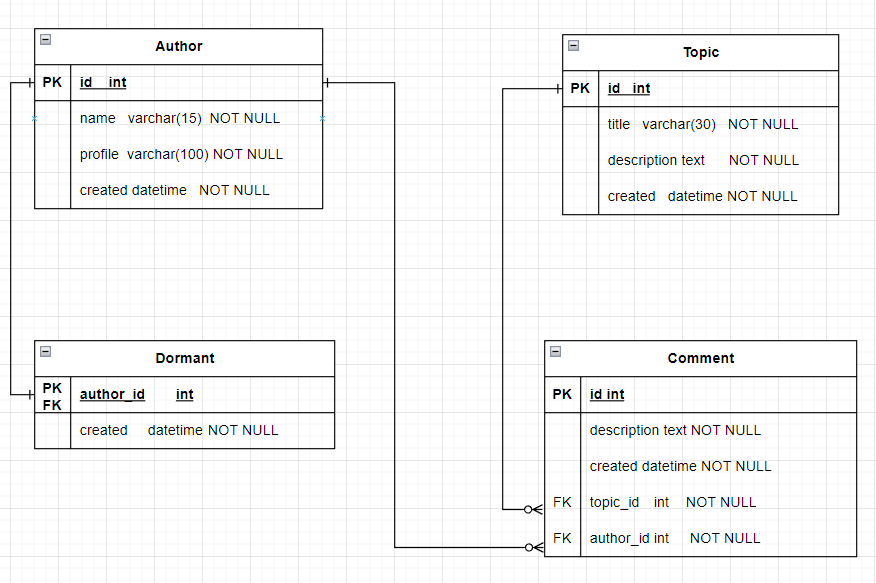
M:N관계는 새로운 테이블을 생성한다. (관계명으로)

이렇게 write와 같은 테이블을 매핑 테이블이라고 한다.
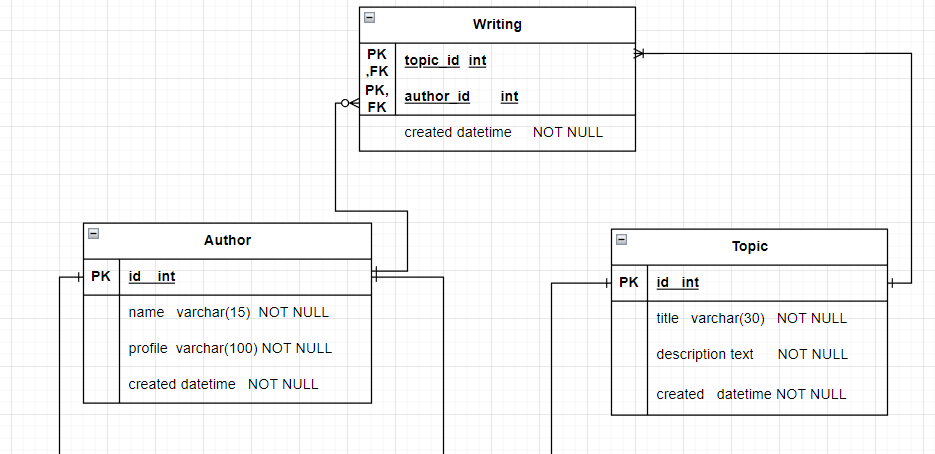
각 Author은 글을 여러개 쓸 수 있고, 쓸 수도 있고 안 쓸 수도 있다.
하지만, 토픽은 글이 써져야 생성되는 것이므로, 저렇게 그려져야 한다.
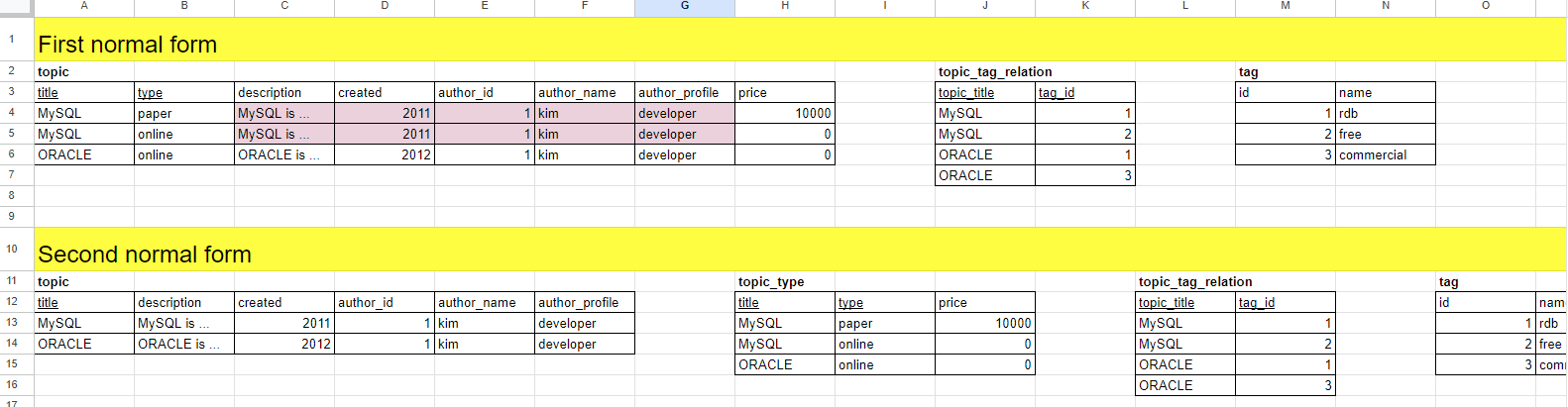
정규화

제 1 정규형 : 속성의 속성값은 원자값이어야 한다.
태그는 여러개의 타이틀을 가질 수 있고, 타이틀은 여러개의 태그를 가질 수 있다.

제 2 정규형 : 부분종속성 제거
중복식별자가 있는 경우, 필요하다.
title이라는 PK 하나에만 종속하고 있는 부분이 있다.
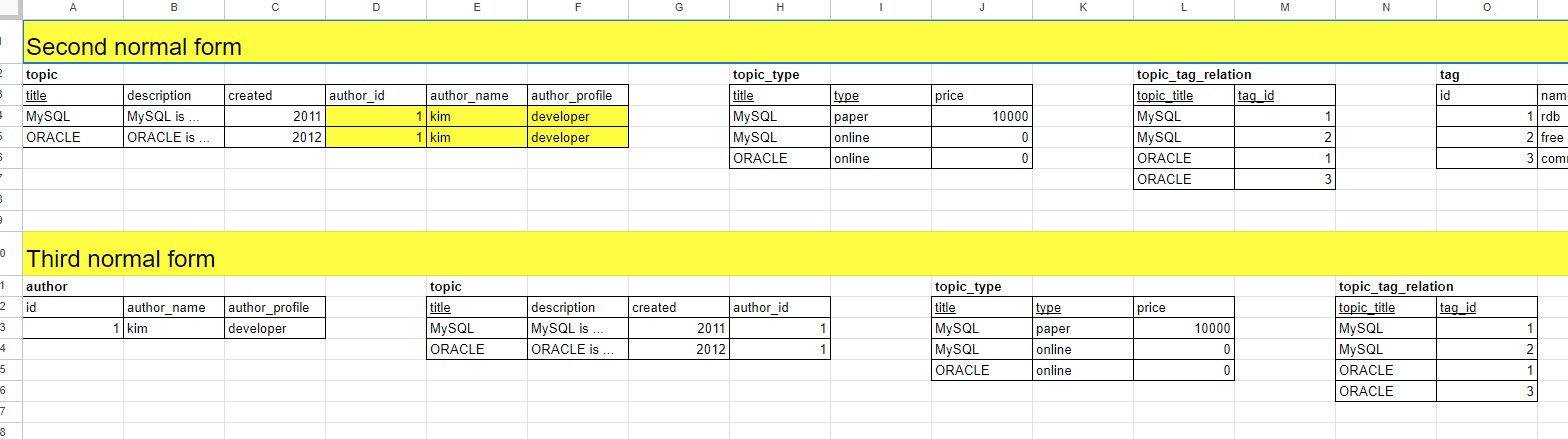
제 3 정규형 : 이행함수종속 제거
author_id에 종속하는 author_name, author_profile이 있다.
💾물리적 데이터 모델링
물리적 데이터 모델링 : 어떤 데이터베이스를 적용하고, 실제 표를 만드는 것
- 산출물 : 표를 생성할 수 있는
SQL코드
성능이 중요하다!
즉, 여러 쿼리가 동작할 때 slow query를 찾는 것이다.
성능을 향상시키기 위한 최후의 보루는 반정규화이다.
반정규화를 찾기 전에 인덱스를 고려해본다. 이것은 조회 성능을 향상시키지만, insert 성능은 감소하게 된다.
아니면, 어플리케이션 영역에서 캐시를 이용해보면 된다.
역정규화(반정규화)
정규화를 통해 만든 표를 성능 또는 개발의 편의성을 위해 구조를 변경하는 것이 반정규화이다.
정규화는 쓰기 성능 향상을 위해 조회 성능이 희생당한다.
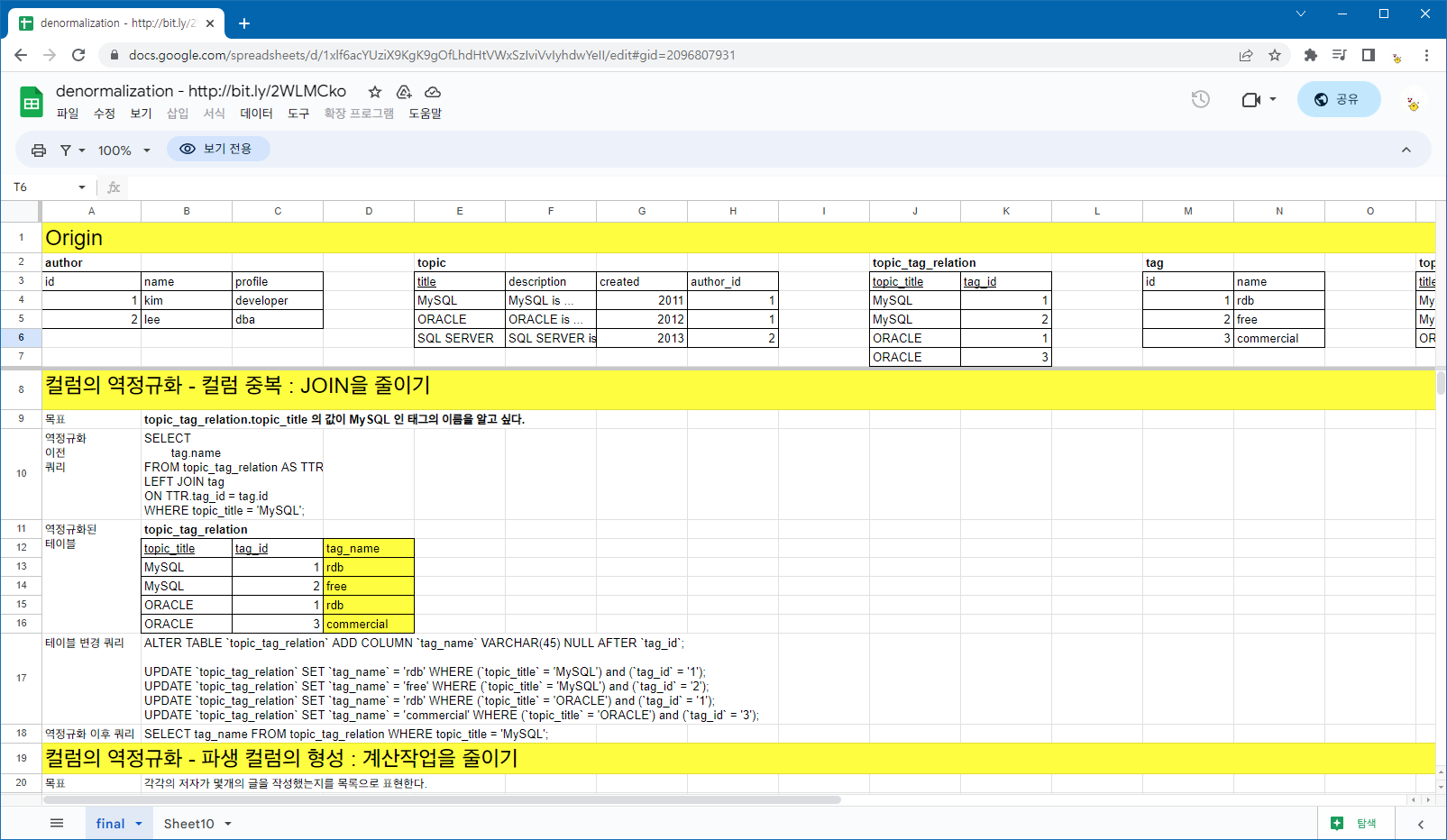
만들어두신 것을 보고, 이해해보도록 하자!
테이블 반정규화
테이블 수직 분할

용량이 큰 description은 topic에 없어서 topic 조회 성능이 올라간다.
DB에 여러 대의 컴퓨터로 데이터베이스를 분산하는 것을 샤딩이라고 한다.
테이블 수평 분할(파티셔닝)
author_id가 만약 1억개라고 치면, 1번부터 1000번까지, 1000번부터 그 이후까지 등으로 테이블을 나눠서 사용할 수 있다.

즉, 테이블 반정규화는 여러 서버로 분산할 때 사용할 수 있다.
컬럼 반정규화
중복 컬럼
JOIN을 줄이자!
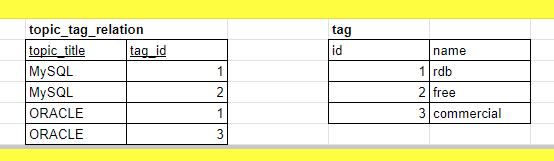
topic_title의 tag 이름을 알고싶다고 해보자.
그러면 조인이 필요하다.
SELECT tag.name;
FROM topic_tag_ralation AS TTR
LEFT JOIN tag
ON TTR.tag_id=tag.id
WHERE topic_title='MySQL';자주 조인하게 되면 성능에 영향이 갈 수 있다.
그러므로, topic_tag_relation테이블 안에 name도 포함해버리는 것이다.

SELECT tag_name FROM topic_tag_relation WHERE topic_title='MySQL';데이터를 아주 빨리 들고 오게 된다.
파생 컬럼
각각의 저자가 몇개의 글을 작성했는지 목록으로 표현한다.
SELECT author_id, count(author_id)
FROM topic
GROUP BY author_id;1번 사람은 2개 적고, 2번 사람은 1개 적었다.
그러나, 이 작업이 굉장히 빈번한 작업이라고 생각해보자.
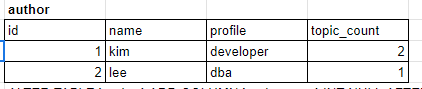
SELECT id, topic_count
FROM author;이렇게 하면 이전과 같은 결과가 나오게 된다!
관계 반정규화
JOIN을 줄여서 지름길을 만드는 것과 비슷하다.
어떤 특정한 저자의 태그 아이디와 태그명을 조회하는 것을 목적으로 해보자.
SELECT tag.id, tag.name FROM topic_tag_relation AS TTR
LEFT JOIN tag ON TTR.tag_id=tag.id
LEFT JOIN topic ON TTR.topic_title=topic.title
WHERE author_id=1;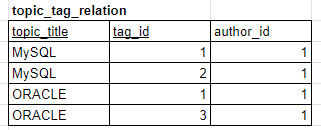
topic_tag_relation에 author_id값을 주면, 조인 횟수가 줄어들게 된다.
SELECT
tag.id, tag.name
FROM
topic_tag_relation AS TTR
LEFT JOIN tag ON TTR.tag_id = tag.id
WHERE TTR.author_id = 1;🕦이후
이후 SQL JOIN에 대해 공부하고,
AWS에 대해 공부해보려고 한다!
