📔설명
INDEX MERGE SCAN을 알아보고, 일반 트리구조와 비트맵 인덱스의 차이를 알아보자.
그리고, INDEX BITMAP MERGE SCAN을 알아보자!
🍔INDEX MERGE SCAN
: 여러개의 인덱스를 같이 사용해 하나의 인덱스만 사용했을 때보다 테이블 액세스를 줄이는 인덱스 스캔 방법
- and_equal 힌트
--col1의 인덱스 사용
select /*+ gather_plan_statistics index(emp2 emp2_col1) */
count(*)
from emp2
where col1='A' and col2='D';위의 쿼리에서, col1에는 'A'가 많이 들어있다.
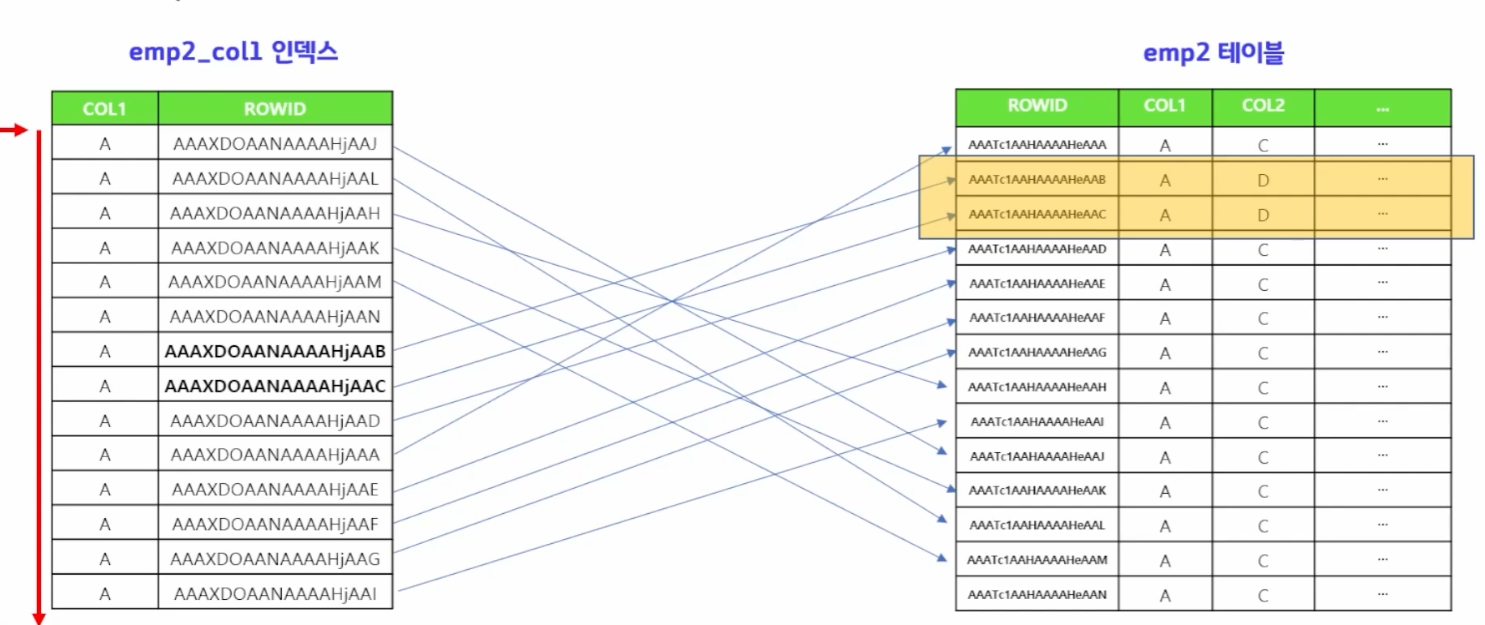
create index emp2_col1 on emp2(col1);
create index emp2_col2 on emp2(col2);위와 같은 상황일 때, col1 인덱스도 있고, col2 인덱스도 존재한다.
옵티마이저에게 인덱스 힌트를 주지 않고, 확인해보면

emp2_col1 인덱스를 사용한 것을 알 수 있다.
col1을 위와 같이 사용하면 너무 넓게 스캔한다.
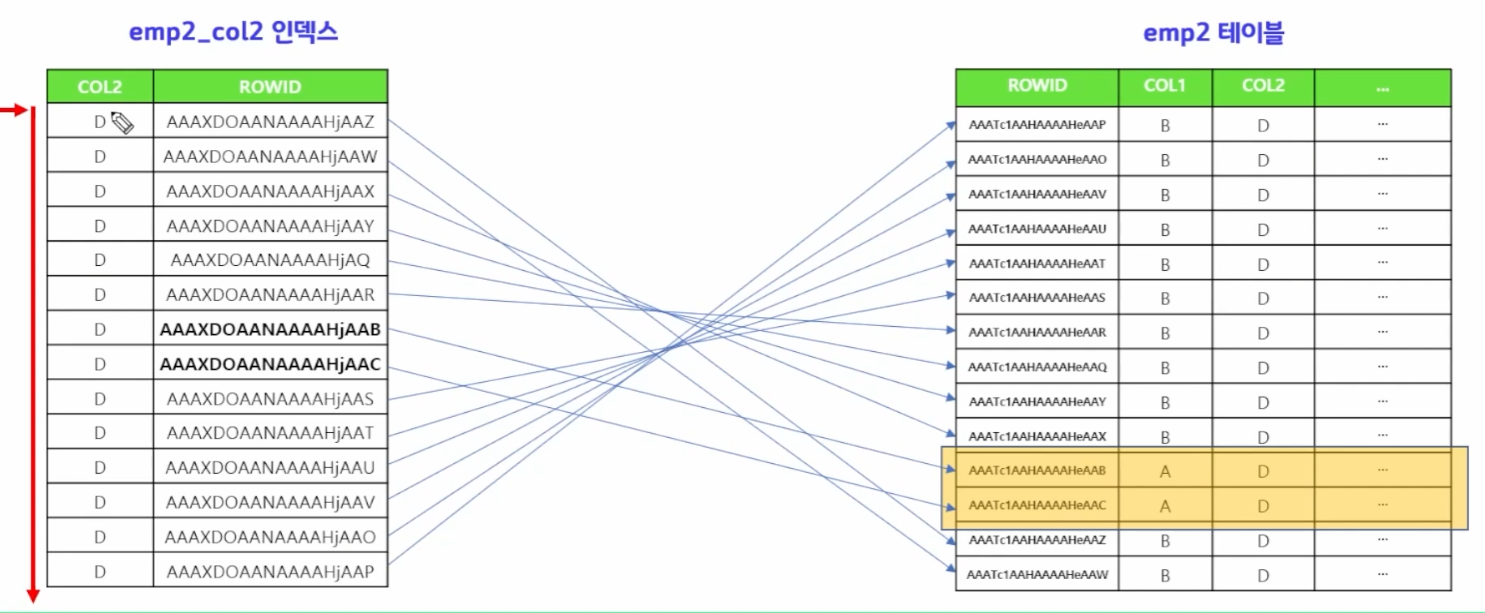
그러므로, col2의 인덱스를 보면 col2에도 D가 많다.
또한, 계속 테이블 액세스를 해야한다는 점이 문제점이다.
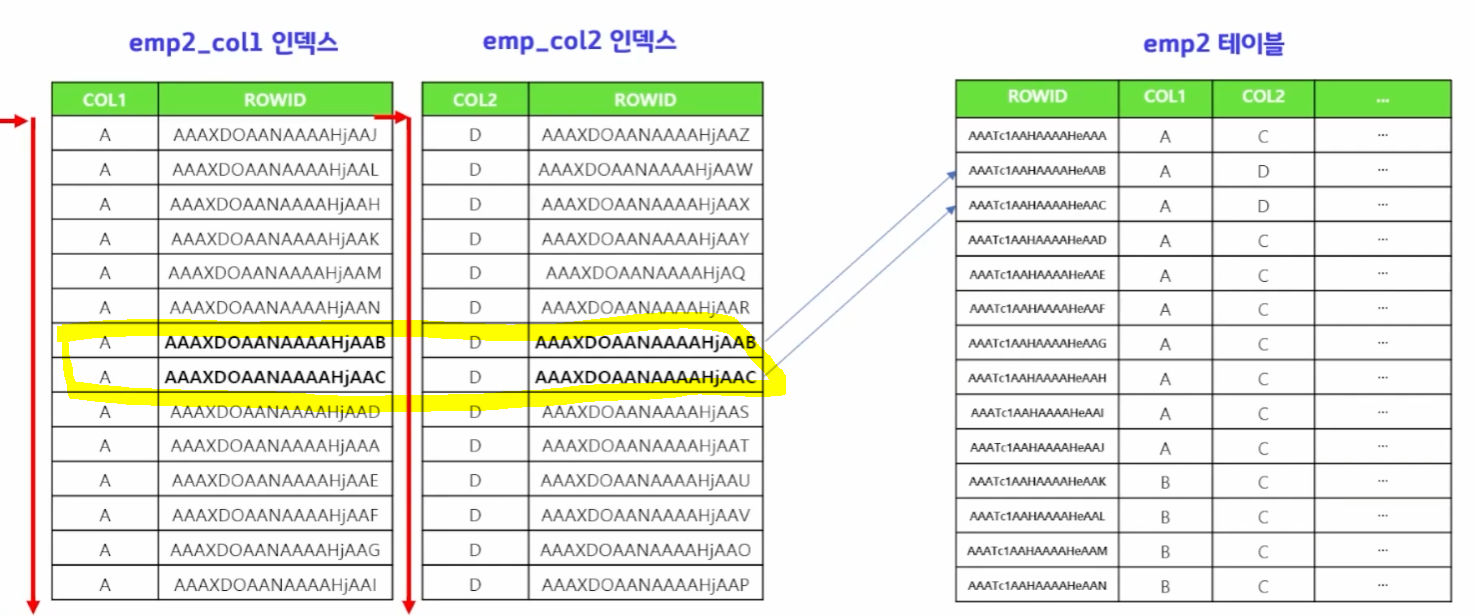
이를 보완할 방법이 index merge scan을 하면 된다.
select /*+ gather_plan_statistics and_equal(emp2 emp2_col1 emp2_col2) */
count(*)
from emp2
where col1='A' and col2='D';두 인덱스를 같이 스캔하는데, 두 데이터를 동시에 만족하는 ROWID에 대해서만 테이블 액세스를 하러 간다.
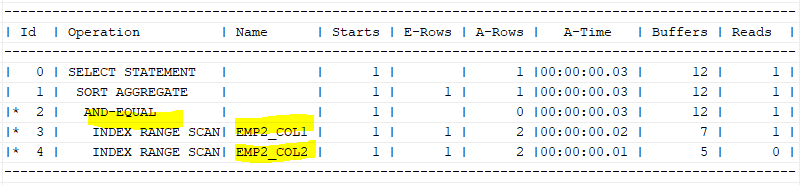
🍿INDEX BITMAP MERGE SCAN
: 일반 인덱스를 크기가 아주 작은 비트맵 인덱스로 변환하고, 비트맵 인덱스들을 하나로 합쳐 스캔하는 방법
- index_combine 힌트
인덱스를 비트맵 인덱스로 자동으로 변환해서 사용할 수 있다!
select /*+ gather_plan_statistics index_combine(emp2 emp2_col1 emp2_col2_ */
count(*)
from emp2
where col1='A' and col2='D';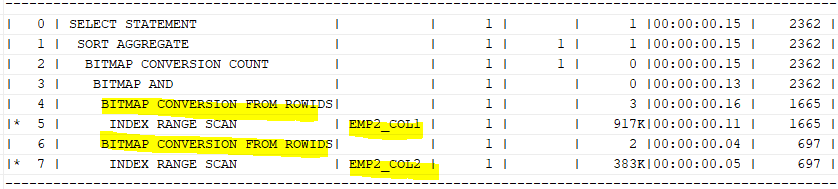
비트맵 인덱스로 바꿨으므로, 이전 인덱스보다 더 빠르게 인덱스를 읽을 수 있다.
순서는 5->4->7->6->3->2->1->0 이다.
🌲일반적인 tree 구조 인덱스
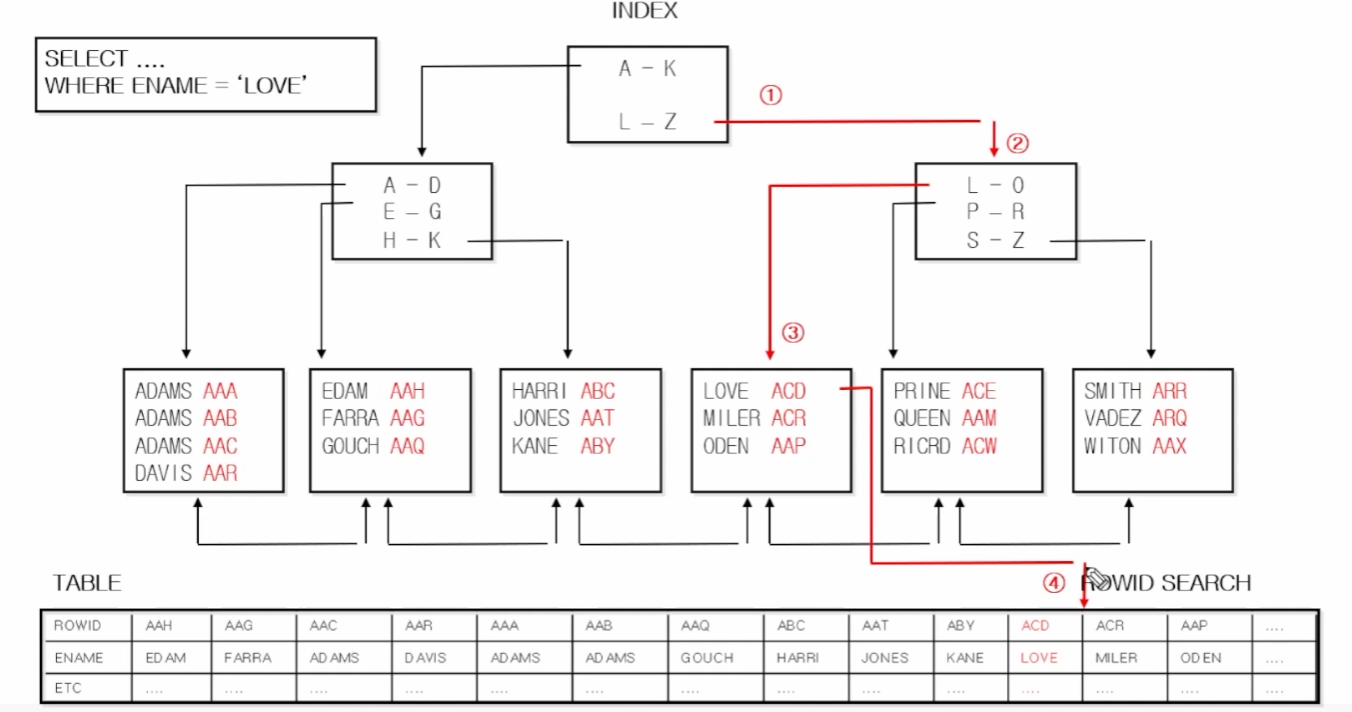
일반 인덱스를 비트맵 인덱스로 변환하게 되면, 크기가 작아짐
그리고, 작아진 비트맵 인덱스 각각을 다시 합쳐(merge) 비트맵 인덱스로 만든다.

MSSQL DBA 신입