📔설명
INDEX SKIP SCAN을 알아보고, table full scan과의 차이를 알아보자
🍔INDEX SKIP SCAN
INDEX SKIP SCAN
: 결합 컬럼 인덱스의 첫 번째 칼럼이 where 조건에 존재하지 않아도 인덱스를 이용할 수 있는 방식
실습 전에 tablespace를 먼저 만들어주자.
create tablespace ts01
datafile 'c:\\sqlstudy\\ts01.dbf' size 500m;
--500메가 크기의 테이블스페이스를 생성create index emp_deptno_job on emp(deptno, job);
select deptno, job, rowid
from emp
where deptno>0;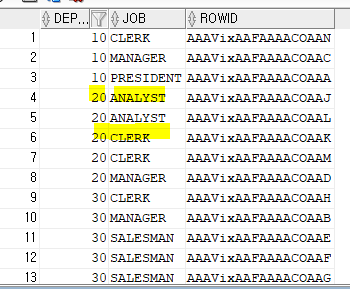
결합 인덱스를 생성하고, 인덱스를 확인해보면 위처럼 deptno 순으로 정렬되고, 그 안에서 다시 job의 asc 순으로 정렬된 것을 확인할 수 있다.
🥩결합 컬럼 인덱스 첫번째 컬럼이 where절에 없을 때
full table scan으로 실행된다- 결합 컬럼 인덱스가
select절에서 사용되기 위해선 결합 컬럼 인덱스의 첫번째 컬럼이 where절 검색조건으로 있어야 함
select /*+gather_plan_statistics */ ename, deptno, sal
from emp
where job='MANAGER';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
where절에 job이 있는데, emp_deptno_job 인덱스에선 두번째 컬럼이기 때문에 어쩔 수 없이 full table scan을 할 수 밖에 없다.
그 전에 메모리를 초기화 시켜주자! 이전에 수행했던 SQL과 관련된 정보들을 메모리속에서 지우고 새롭게 데이터를 불러오기 위해서이다.
select /*+ gather_plan_statistics index_ss(emp emp_deptno_job) */
ename, deptno, job
from emp
where job='MANAGER';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
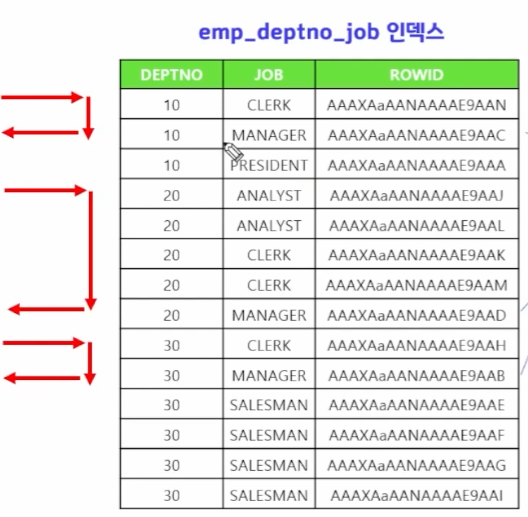
위 처럼 적으면 바로 직업이 MANAGER인 사원을 찾을 순 없지만, 부서번호 10번부터 쭉 읽다가 MANAGER를 찾으면, 테이블 액세스를 하고 그 다음은 스킵한다.
또 20번을 쭉 읽고 MANAGER를 찾고 또 30번에서 MANAGER를 찾고 스킵을 하는 것이다.
🥯결합 컬럼 인덱스 첫번째 컬럼이 범위 조건인 경우
=조건이 아니라 between ~ and~와 같은 경우이다.
결합 인덱스 첫번째 컬럼이 범위 조건이라면, 결합 컬럼 인덱스를 사용하더라도 index range scan 성능이 느릴 수 있다.
create index emp_sal_job on emp(sal,job);
select sal, job, rowid
from emp
where sal>=0; --인덱스 구조 확인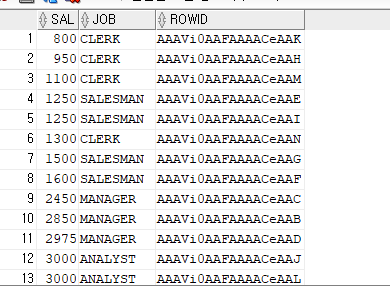
select /*+ gather_plan_statistics index(emp emp_sal_job) */ ename, sal, job, deptno
from emp
where sal between 950 and 4500
and job='MANAGER';
범위가 너무 넓기 때문에 검색 성능이 느려지게 된다.
이럴 때
select /*+ gather_plan_statistics index_ss(emp emp_sal_job) */ ename, sal, job, deptno
from emp
where sal between 950 and 4500
and job='MANAGER';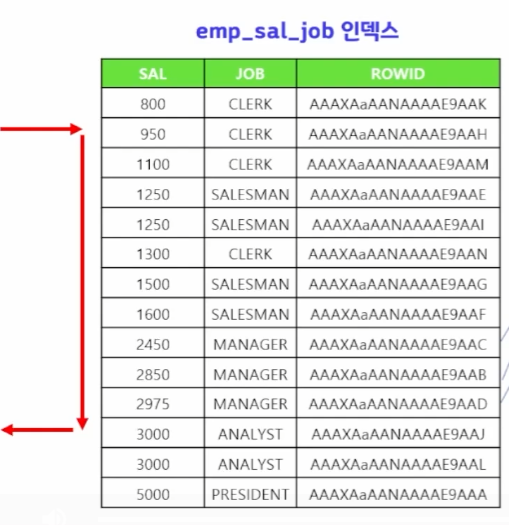

MANAGER까지만 읽고 스킵해버리면 된다.
🍭효과를 높이는 결합 컬럼 인덱스
select ename, sal, job, deptno
from emp
where sal=3000;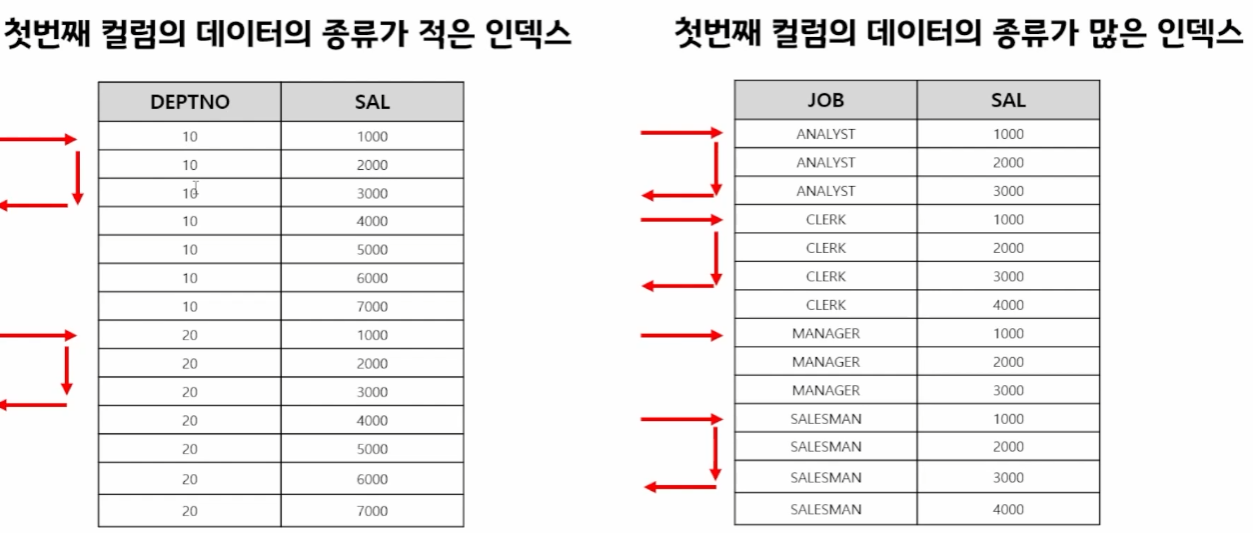
첫번째 컬럼의 데이터 종류가 적은 인덱스 가 좋다.
적은 경우에는 3000 이후부터는 안읽어도 된다.
