📔설명
조인 문법과 방법을 알아보고, NESTED LOOP JOIN을 알아보자!
🍔조인 문법과 방법
조인 문법
- 오라클 조인 문법 (equi, non equi, outer, self join)
- ANSI 문법 (on, using, left/right/full join, cross join)
조인 방법
- nested loop join
- sort merge join
- hash join
🍺NESTED LOOP JOIN
: 순차적 반복 조인
선행 테이블의처리 범위를하나씩 액세스하며, 그 추출된 데이터로연결할 테이블을 조인하는 방식
select e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno;위의 sql에서 emp 테이블이 선행 테이블이고, dept가 inner 테이블 (후행 테이블) 이다.
- 데이터가
작은테이블을먼저 읽는것이 좋은 성능을 보인다.
emp테이블을 먼저 읽고, dept로 조인을 하면 14번을 총 조인하게 된다.
하지만, dept테이블이 선행이라면 deptno=10인 것을 emp 테이블에서 한번에 읽고, .. 해서 총 4번만 조인을 하면 된다.
조인 순서를 정하기 위해 힌트를 사용해줘야 한다.
- leading(선행 후행) use_nl(후행)
select /*+ gather_plan statistics leading(e d) use_nl(d) */
e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno;테이블 별칭을 썼기 때문에 힌트 안에도 테이블 별칭으로 적어줘야 한다.
앞에 나오는 emp를 선행 테이블(driving table), 뒤는 후행 테이블(driven table)이라고 한다.
만약, 조인 조건이 있을 때 테이블 순서는 어떻게 될까?
select e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno
and e.ename='SCOTT';emp->dept가 더 성능이 좋아진다. SCOTT는 한 행이므로 한번만 조인 시도를 하면 되기 때문이다.
select /*+ gather_plan_statistics */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));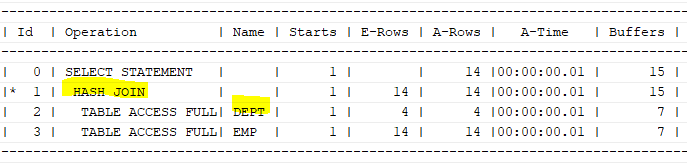
따로 힌트를 주지 않았을 땐, 옵티마이저가 hash join을 하고, dept를 먼저 사용하는 것을 확인할 수 있다.
이제 힌트를 사용해서 확인해보자!
select /*+ gather_plan_statistics leading(e d) use_nl(d) */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));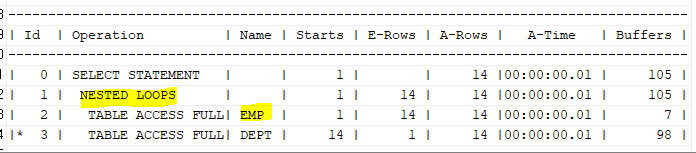
emp를 먼저 읽고 nl 조인을 해보았더니 버퍼도 많이 읽고 성능이 안좋아졌다.
ordered use_nl(d)또한leading(e d) use_nl(d)와 같이from절에 기술한 순서대로 테이블을 읽는다
select /*+ gather_plan_statistics ordered use_nl(e) */ e.ename, e.sal, d.loc
from dept d, emp e
where e.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));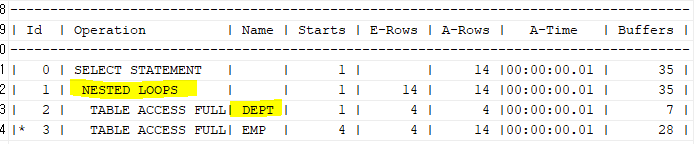
버퍼의 개수도 확 많이 줄었다.
🧀3개 이상의 테이블 조인시
select /*+ leading(s e d) use_nl(e) use_nl(d) */ e. ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno
and e.sal between s.losal and s.hisal;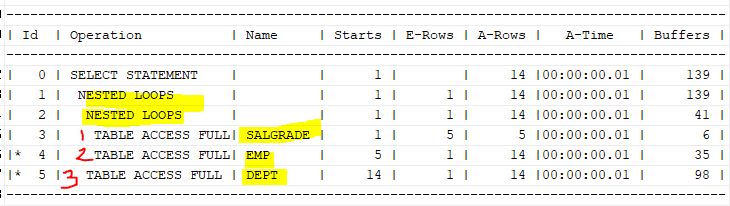
위와 같은 쿼리면, salgrade->emp시 조인을 5번, emp->dept시 조인을 14번 한다.
select /*+ leading(d e s) use_nl(e) use_nl(s) */ e. ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno
and e.sal between s.losal and s.hisal;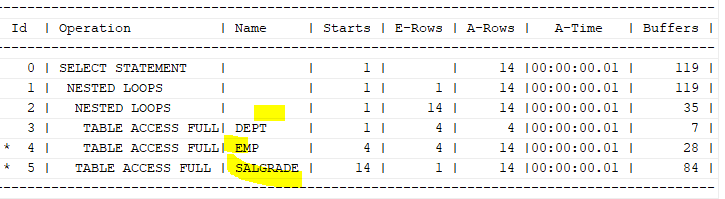
dept->emp시 4번 조인을 하고, emp->salgrade시 14번을 조인시도 한다.
여기서, 검색 조건이 있을 때 조인 순서를 확인해보자.
select /*+ leading(e d s) use_nl(d) use_nl(s) */ e. ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno
and e.sal between s.losal and s.hisal
and e.ename='SCOTT';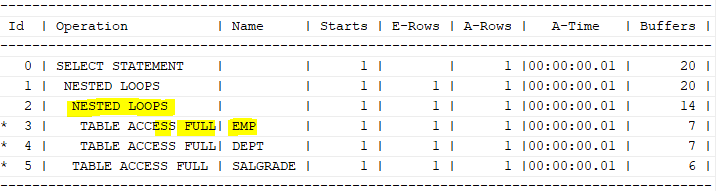
emp에서 SCOTT 하나의 행과 dept를 조인하므로 1번만 조인시도 한다.
또, SCOTT의 sal과 salgrade를 조인시도 1번 한다.
검색 조건이 여러개 있을 때 조인순서를 확인해보자!
select /*+ leading(d e s) use_nl(e) use_nl(s) */ e. ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno
and e.sal between s.losal and s.hisal
and s.grade in (3,4)
and d.loc='DALLAS';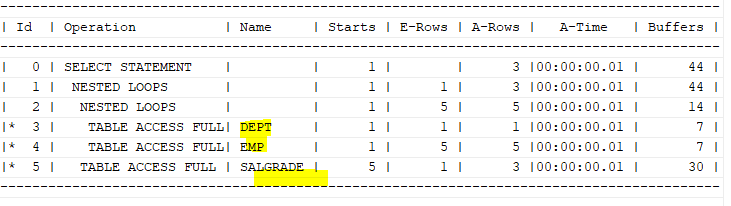
salgrade를 먼저 읽는다면 2번 조인시도를 한다.
그렇지만, dept 테이블을 먼저 읽는다면 1번만 조인시도를 하면 된다.
☕인덱스가 있을 때 테이블 조인시
이때까진 인덱스가 없었을 때, 우리는 조인 순서만 정할 수 있었다!
select /*+ gather_plan_statistics leading(d e) use_nl(e) */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));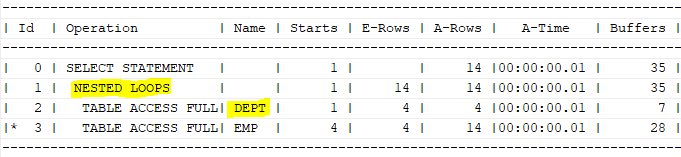
하지만, dept 테이블에서 emp를 읽을 때 부서번호에 인덱스가 없어서 full table scan을 할 수 밖에 없었다.
인덱스를 deptno 컬럼에 설정해준다면, deptno는 deptno 인덱스를 읽어서 차례대로 읽어 index range scan을 하면 된다.
create index emp_deptno on emp(deptno);
select /*+ gather_plan_statistics leading(d e) use_nl(e) */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));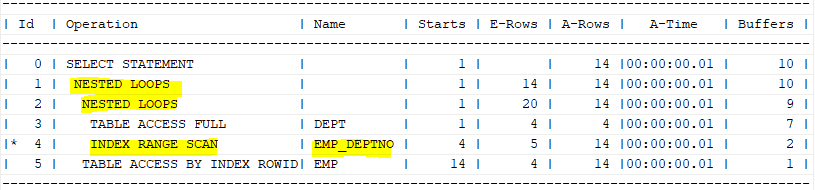
NESTED LOOPS가 두번 나타난 이유는, advanced nested loop join으로, 다음에 emp_deptno 인덱스를 메모리에 올려놓고 다음에 접근하기 때문에 더 성능을 좋게 해준다.
만약, 검색 조건이 있다고 해도, deptno 인덱스를 사용해 접근하는게 더 낫다. 하지만, 우리는 emp테이블을 먼저 읽을 것이기 때문에 dept테이블의 deptno에 인덱스가 있는 것이 낫다.
select /*+ gather_plan_statistics leading(e d) use_nl(d) */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno and e.ename='SCOTT';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));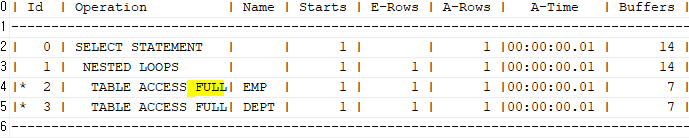
위처럼 해도, 테이블 풀 스캔을 한다. 또한 인덱스를 사용하지 않는다.
그러므로 아래와 같이 인덱스를 추가해줘야 한다.
create index dept_deptno
on dept(deptno);
select /*+ gather_plan_statistics leading(e d) use_nl(d) */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno and e.ename='SCOTT';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));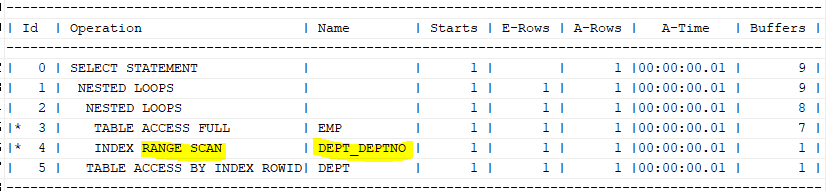
하지만, 검색 조건에 또한 인덱스를 해주면 더 빠르게 된다. ename컬럼에 인덱스를 달아주는 것이다.
검색 조건이 만약 여러개라면, 조인 횟수를 가장 줄여주는 검색 조건에도 인덱스를 걸어보자.
create index emp_deptno on emp(deptno);
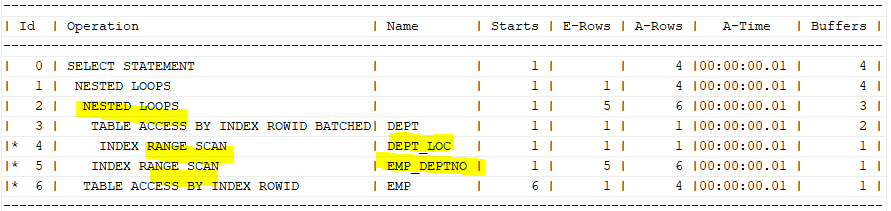
create index dept_loc on dept(loc);
select /*+ gather_plan_statistics leading(d e) use_nl(e)
index(dept dept_loc) index(emp emp_deptno) */
e. ename, e.sal, d.loc
from emp e, dept d
where e.deptno=d.deptno and e.job='SALESMAN' and d.loc='CHICAGO';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));위에서는 dept_loc 인덱스를 추가로 생성하고, emp_deptno 인덱스를 통해 테이블을 액세스 하면 된다.