📔설명

프로세스 한 개가 처리하는 것 보다 여럿이 함께 처리하면 실행 시간이 단축될 수 있다.
✨병렬도
- 오라클의 병렬처리는
힌트를 통해수동으로 지정해야 병렬처리 가능
select /*+ full(oi) parallel(oi 2) */ count(*)
from ord_item oi
where ord_dt between '20120101' and '20120331';- 옵티마이저가 스캔 방식을
인덱스 스캔으로 결정하면병렬 힌트를 사용X
=>full(oi)힌트를 주는 이유 parallel 힌트를 사용시병렬로 읽을 테이블과병렬도지정

일반적으로 2라고 지정하면, 위 사진처럼 2개의 프로세스가 나누어 처리한다.
하지만, 지정한 병렬도의 2배수가 생성되는 경우가 있다.
엄청난 양의 책을 가나다순으로 정리한다고 생각했을 때 절반정도 나눈 다음, 상자 두 개에 하나는 A~M 다른 하나는 N~Z까지 나누어 담고 각각 상자를 각자 정렬한 후 정렬된 책을 하나로 합치는 것이 효율적이다.
이렇게 보면 두명의 사람이 두 번의 작업을 했다. (담는 작업, 정렬하는 작업)
- 오라클은 분배하는 작업, 정렬하는 작업 수행 시
지정한 병렬도의2배에 해당하는 프로세스 생성
🎩데이터 재분배
- 병렬 프로세스로 데이터 처리시
각각의 프로세스는데이터 공유X
ex) 동영상 재생과 워드 프로그램은 각각 데이터와 메모리를 공유하지 못하는 것 - 각각의 프로세스가 더 효율적으로 처리할 수 있도록
할당 받은 데이터를 다시 분배
select /*+ gather_plan_statistics full(oi) parallel(oi 2) */
ord_dt, item_id, sum(ord_item_qty)
from ord_item oi
where ord_dt between '20120101' and '20120331'
group by ord_dt, item_id;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST +PARALLEL'));
p->p:프로세스가두 배로 생성, 프로세스간 통신은제곱만큼 발생
먼저, Query Coordinator가 임의로 분리해 P000과 P001 프로세스가 생성되고, 그 프로세스에서 조건에 맞게 필터링을 한다.
그 후 P->P로 P002와 P003 프로세스에게 전달을 하며 해당 프로세스는 GROUP BY 작업을 수행한다.
그다음 P->S를 통해 결과 집합을 모아 최종 결과집합을 만든다.
위의 실행계획에서 분배 방식은 HASH이며, 최종 결과 집합으로 만들어질 때 (p->s), 먼저 처리된 순서대로 결과 집합이 만들어짐(QC(RAND))
select /*+ gather_plan_statistics full(o) parallel(o 2) */ *
from ord o
where ord_dt between '20120101' and '20120331'
and shop_no='SH0001'
order by ord_no;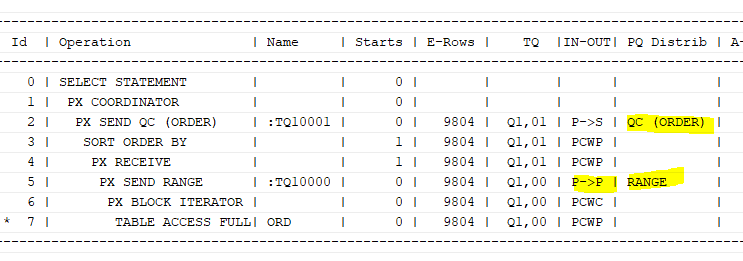
order by에서도 재분배가 발생한다.
재분배가 발생하면, 병렬도의 두 배 프로세스를 생성한다.
분배는 range 방식으로 진행하며 최종 결과 집합이 만들어질 때 정렬 되면서 만들어진다. (QC(ORDER))
🧶인덱스 스캔 vs 테이블 풀 스캔 vs 병렬 수행
--1. 인덱스 스캔
select /*+ gather_plan_statistics */
ord_dt, item_id, sum(ord_item_qty)
from ord_item oi
where ord_dt between '20120101' and '20120331'
group by ord_dt, item_id;
--2. 테이블 풀 스캔
select /*+ gather_plan_statistics full(oi) */
ord_dt, item_id, sum(ord_item_qty)
from ord_item oi
where ord_dt between '20120101' and '20120331'
group by ord_dt, item_id;
--3. 병렬 수행
select /*+ gather_plan_statistics full(oi) parallel(oi 2) */
ord_dt, item_id, sum(ord_item_qty)
from ord_item oi
where ord_dt between '20120101' and '20120331'
group by ord_dt, item_id;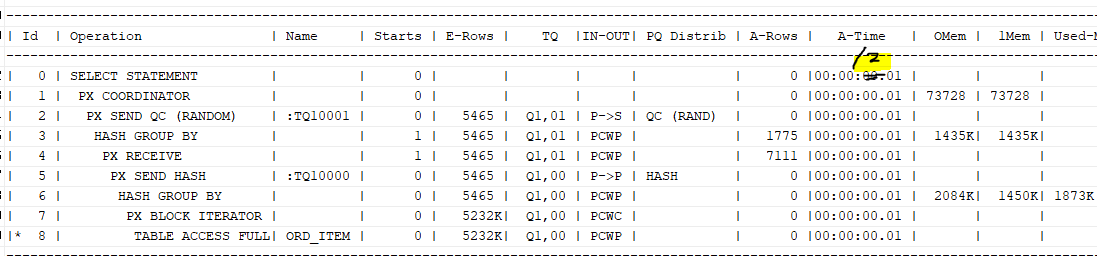
위의 실행계획들을 보면, 단일 테이블에서는 병렬 수행 효과가 생각보다 낮다는 것을 알 수 있다.
파티션이 되어 있을 때 더 좋은 성능을 낸다.
select /*+ gather_plan_statistics full(oi) */
substr(ord_dt,1,6) ord_mm, item_id, sum(ord_item_qty)
from ord_item_list oi
where 1=1
and ord_ym between '201201' and '201206'
and ord_dt between '20120101' and '20120630'
group by substr(ord_dt,1,6), item_id;
select /*+ gather_plan_statistics full(oi) parallel(oi 2) */
substr(ord_dt,1,6) ord_mm, item_id, sum(ord_item_qty)
from ord_item_list oi
where 1=1
and ord_ym between '201201' and '201206'
and ord_dt between '20120101' and '20120630'
group by substr(ord_dt,1,6), item_id;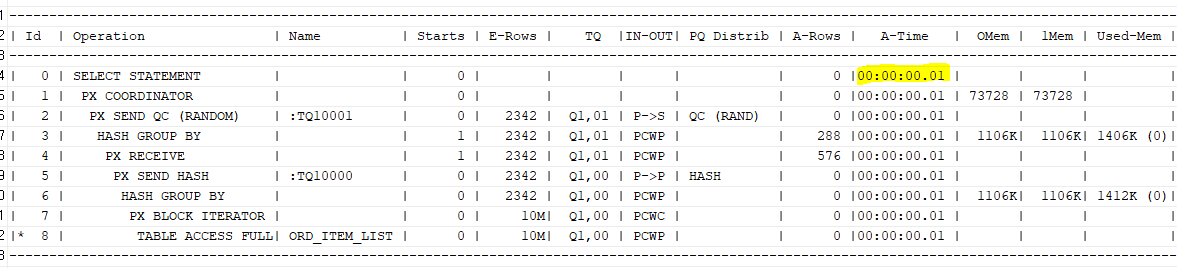
💎병렬 해시 조인과 파티션 와이즈 조인
- 병렬 프로세스로 조인 수행시, 가장 많이 사용하는 조인 방식은
해시 조인
-> 병렬로 테이블 읽을 때테이블 풀 스캔을 진행하는데, 이 대용량 데이터를 인덱스 없이NL 조인을 수행하거나소트 머지 조인으로 정렬하기 버겁기 때문
두 테이블 모두 파티션 테이블
병렬 프로세스로 조인 수행시 각 프로세스에서 처리할 데이터는 상호 배타적이다. 각 프로세스는 서로 데이터를 공유할 수 없기 때문이다.
파티션 와이즈 조인(Partition Wise Join)
: 각 프로세스가 조인을 위해 데이터 쌍을 만드는 작업
-- 단일 프로세스로 처리
select /*+ gather_plan_statistics full(o) full(oi) use_hash(oi) */ count(*)
from ord_list o, ord_item_list oi
where o.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;
필요한 파티션만 읽었기 때문에, 블록 수가 감소되었다.
-- 병렬 처리
select /*+ gather_plan_statistics full(o) parallel(o 2) full(oi) parallel(oi 2) use_hash(oi) pq_distribute(oi none none) */ count(*)
from ord_list o, ord_item_list oi
where o.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;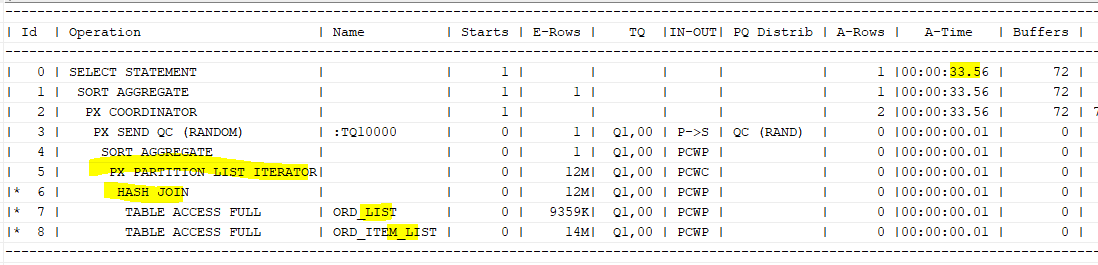
풀 파티션 와이즈 조인
: 파티션끼리 조인이 되는 것
- 풀 파티션 와이즈 조인이 가능한 경우,
병렬로 수행시데이터 재분배 과정X(P->P 없음) PQ_DISTRIBUTE힌트를 사용해 옵티마이저가 다른 판단을 못하도록 함
위의 SQL에서 두 테이블 모두 파티션 키 컬럼(ord_ym)이 조인에 참여한다.
조인해야 할 파티션끼리 짝지어 주면, 서로 다른 프로세스의 데이터는 조인 가능성이 없기 때문
두 테이블 모두 파티션 테이블(해시 파티션)
-- 서브 파티션으로 해시 파티션이 있을 경우
select /*+ gather_plan_statistics full(o) full(oi) use_hash(oi) */ count(*)
from ord_list_hash o, ord_item_list_hash oi
where o.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;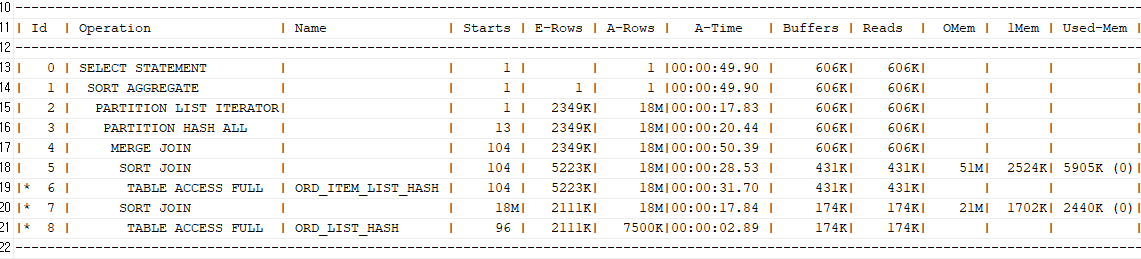
select /*+ gather_plan_statistics full(o) parallel(o 2)
full(oi) parallel(oi 2) use_hash(oi) pq_distribute(oi none none) */ count(*)
from ord_list_hash o, ord_item_list_hash oi
where o.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;
모두 PGA 사용량이 다른 SQL문에 비해 낮아진다.
이미 해시 파티션이 있으므로 해시 조인시 필요한 PGA 공간이 많이 필요하지 않음
두 테이블 중 하나만 파티션 테이블
select /*+ gather_plan_statistics full(o) full(oi) use_hash(oi) */ count(*)
from ord o, ord_item_list oi
where o.ord_dt between '02120131' and '20121231'
and oi.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no;
select /*+ gather_plan_statistics full(o) parallel(o 2) full(oi) parallel(oi 2) use_hash(oi) */ count(*)
from ord o, ord_item_list oi
where o.ord_dt between '02120131' and '20121231'
and oi.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no;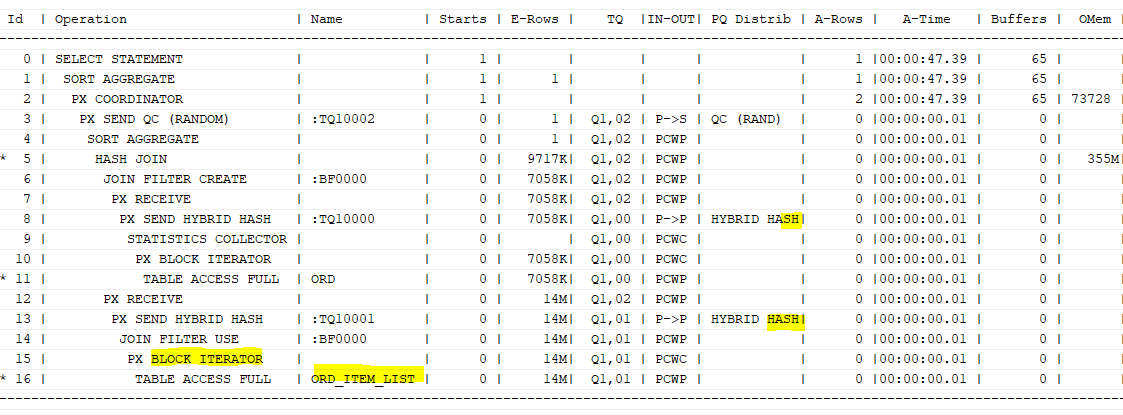
ord_item_list 테이블은 파티션 테이블이다. 하지만 p->p가 뜨는 것을 보아 데이터 재분배가 나타난 것을 알 수 있다.
데이터 재분배가 일어나지 않으려면 파티션 키 컬럼이 조인에 참여해야 한다.
select /*+ gather_plan_statistics full(o) parallel(o 2)
full(oi) parallel(oi 2) use_hash(oi) */ count(*)
from ord o, ord_item_list_hash oi
where o.ord_dt between '02120131' and '20121231'
and oi.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no;ord_item_list_hash 테이블은 ord_no 컬럼이 서브 파티션 키 컬럼으로 설정되어 있다.
재분배가 안나타날 것이라 생각했으나, P->P단계 분배 방식이 BROADCAST 방식으로 나타났다.
select /*+ gather_plan_statistics full(o) parallel(o 2)
full(oi) parallel(oi 2) use_hash(oi) pq_distribute(oi partiton none) */ count(*)
from ord o, ord_item_list_hash oi
where o.ord_dt between '02120131' and '20121231'
and oi.ord_ym between '201201' and '201212'
and o.ord_no=oi.ord_no;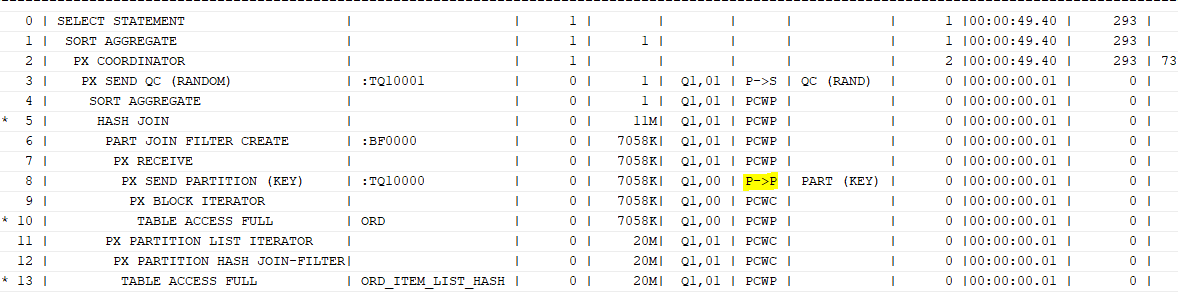
pq_distribute 힌트
- 파티션 테이블을 적절하게 분배하지 못할 경우 사용
- 해당 힌트를 이용해 실행계획 고정
- 조인을 하기 전, 데이터를 어떻게 분배할지 결정 가능
PQ_DISTRIBUTE(inner 테이블, outer 테이블 분배 방식, inner 테이블 분배 방식)- 분배 방식 종류 : none, partition, hash, broadcast
ex) pq_distribute(b, hash, hash) : inner테이블은 b이고, 두 테이블 모두 해시 방식으로 분배
pq_distribute(b, partition, none) : inner테이블은 b이고, a테이블 분배 방식을 b 테이블 파티션으로 나눈 방식과 동일하게 분배
위의 sql에서 pq_distribute(oi partition none)은 inner 테이블이 ord_item_list_hash 테이블이고, outer 테이블을 inner테이블 해시 파티션 할 때의 기준으로 ord 테이블 데이터를 분배하도록 한다.
마지막 none 옵션은, 이미 outer 테이블에서 inner 테이블이 구성된 방식으로 분배한다 하였기 때문에, 아무것도 하지 않도록 하는 것이다.
부분 파티션 와이즈 조인(Partial Partition Wise Join)
: 한 쪽은 이미 파티션된 테이블과 조인하는 경우
-파티션 테이블이라도 무조건 재분배가 발생 안하는 것은 아님
재분배는파티션을 만든 것과 같은기준
두 테이블 모두 파티션이 아닌 경우
select /*+ gather_plan_statistics full(o) full(oi) */ count(*)
from ord o, ord_item oi
where o.ord_dt between '02120131' and '20121231'
and o.ord_no=oi.ord_no;
select /*+ gather_plan_statistics full(o) parallel(o 2) full(oi) parallel(oi 2) use_hash(oi) */ count(*)
from ord o, ord_item oi
where o.ord_dt between '02120131' and '20121231'
and o.ord_no=oi.ord_no;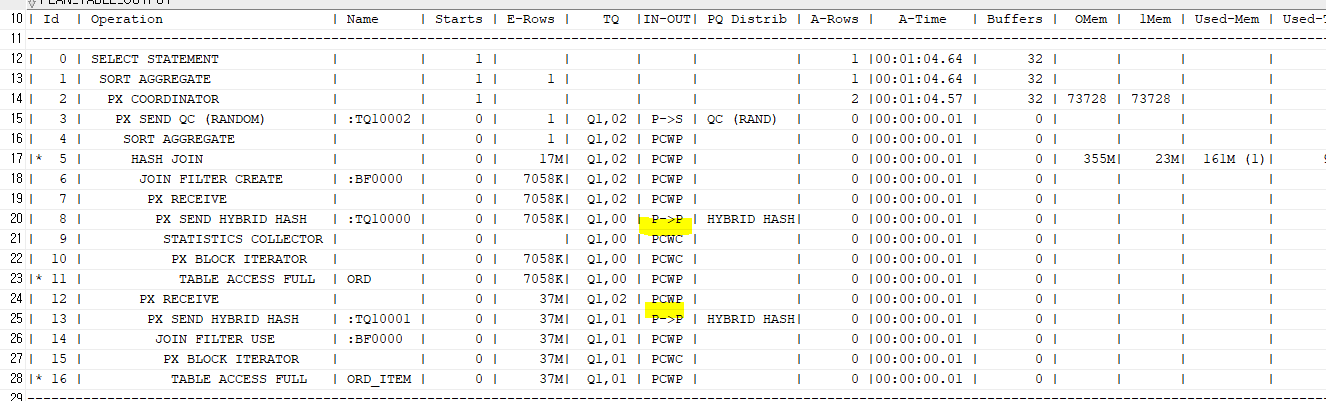
p->p 과정을 통해 재분배를 하였다. 위의 실행계획에서는 두 테이블 모두 재분배가 발생했다.
주문 테이블을 적당히 나눠 읽고, 주문상품 테이블도 적당히 나누어 읽는 것이다.
다이내믹 파티션 와이즈 조인(Dynamic Partition Wise Join)
: 양쪽 테이블에서 재분배가 일어나는 경우
두 테이블 중 한쪽 테이블 결과 건수가 매우 적은 경우
-- 작은 테이블 데이터를 양쪽에 전송
select /*+ gather_plan_statistics full(o) parallel(o 2)
full(oi) parallel(oi 2) pq_distribute(oi broadcast none) */ count(*)
from ord_list o, ord_item_list oi
where o.ord_ym between '201201' and '201212'
and o.shop_no='SH0001'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;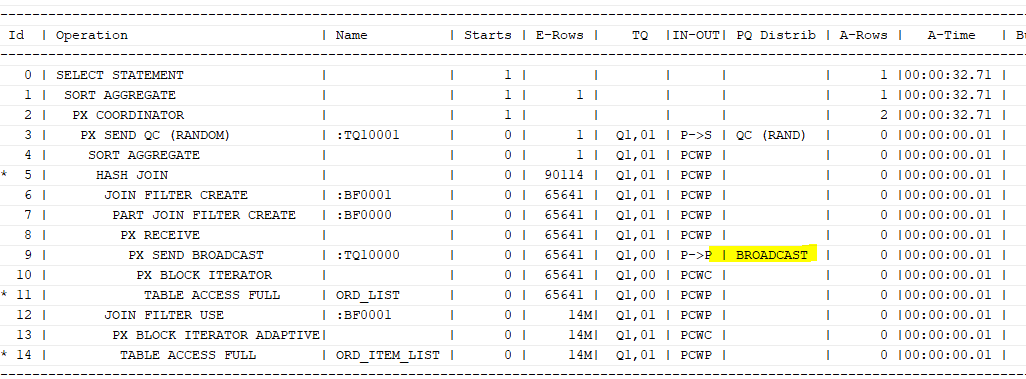
-- 큰 테이블 데이터를 양쪽에 전송
select /*+ gather_plan_statistics full(o) parallel(o 2)
full(oi) parallel(oi 2) pq_distribute(oi none broadcast) */ count(*)
from ord_list o, ord_item_list oi
where o.ord_ym between '201201' and '201212'
and o.shop_no='SH0001'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;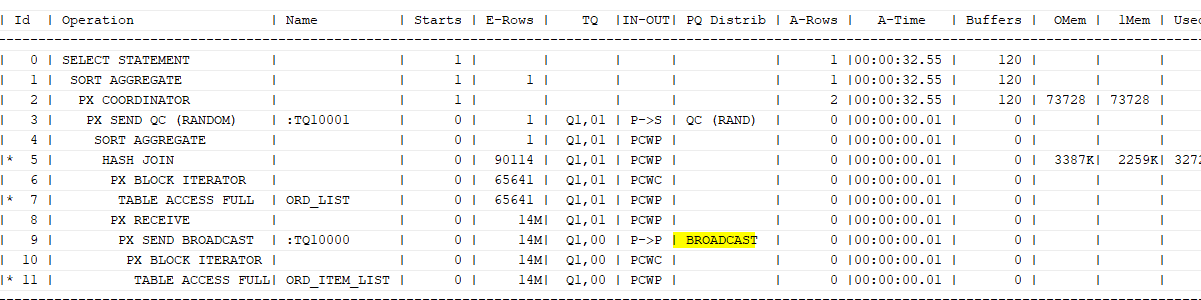
ord_list의 결과 데이터가 매우 적기 때문에 ord_list 결과를 ord_item_list쪽으로 보내는 것이 더 빠르다.
broadcast
: 한 쪽 테이블의 결과 건수가 매우 적을 때, 데이터 재분배를 위해 전체 데이터를 모든 프로세스에 보내는 방식
🏈병렬 NL 조인
- 병럴처리시 해시 조인보다 NL조인이 더 유리한 경우도 있다.
select /*+ gather_plan_statistics leading(o) use_nl(oi) */ count(*)
from ord_list o, ord_item_list oi
where o.ord_ym between '201201' and '201212'
and o.shop_no='SH0001'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;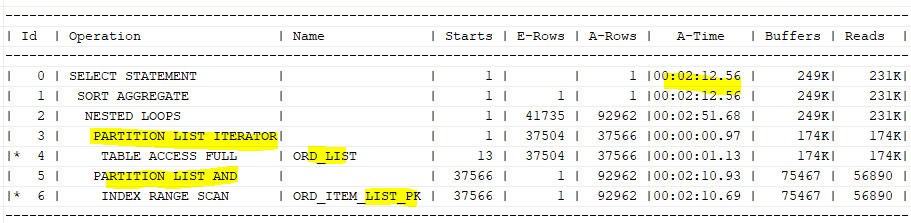
select /*+ gather_plan_statistics leading(o)
full(o) parallel(o 4) use_nl(oi) */ count(*)
from ord_list o, ord_item_list oi
where o.ord_ym between '201201' and '201212'
and o.shop_no='SH0001'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;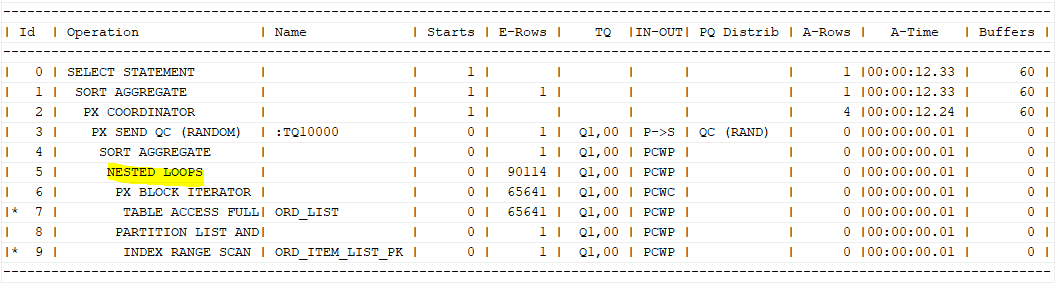
- 두 테이블 모두 대용량인 경우, 조회 조건이 한 쪽 테이블에 집중되어 있어 한 테이블에서
조회되는 건수가전체 대비 적고Inner 테이블로조인키 인덱스가 있다면 대안
=>한 테이블만병렬로 데이터를 읽어 각 프로세스가NL조인을 시도하도록 유도 - 병렬로
NL 조인수행 시,드라이빙 테이블(inner)의인덱스를 이용할 수 있다.
=> 드라이빙 테이블에 만들어진 인덱스는반드시 파티션 인덱스여야 함 PARALLEL_INDEX힌트는index힌트와 함께 사용하는 것이 좋음- 위의 힌트 사용 시
파티션 인덱스가 아니라면index_ffs에서만 동작
select /*+ gather_plan_statistics leading(o)
parallel_index(o ord_list_x02 4) index(o ord_list_x02) use_nl(oi) */ count(*)
from ord_list o, ord_item_list oi
where 1=1
and o.ord_ym between '201201' and '201212'
and o.shop_no='SH0001'
and o.ord_no=oi.ord_no
and oi.ord_ym=o.ord_ym;SQL을 통해 ord_list_x02 인덱스를 이용해 데이터를 추출한 후 nl조인을 수행
