📔설명
오라클 아키텍처에 대해 알아보자!
🍔오라클 아키텍처
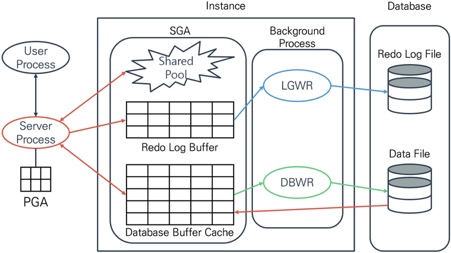
-
SELECT: 서버 프로세그가 처리 -
I/U/D: 백그라운드 프로세스가 처리 -
인스턴스=> 메모리, 프로세스 의미 -
데이터베이스=> 물리적인 파일
ex) INSERT
- SQL문
문법확인 - SQL문 테이블, 컬럼 검사
- SQL문 실행 계정 권한 검사
- SQL문 재사용을 위해
Shared pool에 저장 - 쿼리 실행 시 결과를
리두 로드 버퍼에 기록 --여기까지 서버프로세스 데이터베이스 버퍼 캐시에 저장commit시,LGWR가 리두 로그 버퍼 내용을 리두 로그 파일에 저장- DB 버퍼 캐시는
더티 버퍼로 상태가 변경되며,DBWR이 데이터 파일에 기록
ex) SELECT
- SQL문 문법 확인
- SQL문 테이블, 컬럼 검사
- SQL문 실행 계정 권한 검사
- SQL문 재사용을 위해
Shared Pool에 저장 - DB 버퍼 캐시에서 데이터 확인
- DB 버퍼 캐시에 없으면
디스크에서 해당테이블데이터를DB 버퍼 캐시로 복사 - SELECT 결과를 유저 프로세스로 전송
-- 서버 프로세스
🎁리두 로그 버퍼와 LGWR
LGWR이 리두 로그 버퍼의 내용을 로그 파일로 저장하는 경우
- 매 3초
- 리두 로그 버퍼가 1/3 채워진 경우
- 변경된 리두 로그 버퍼가 1MB 이상인 경우
- 사용자가 commit 명령 시
🎫DB 버퍼 캐시와 DBWR
Pinned Buffer: 어떤 사용자가 현재사용중인 버퍼로,데이터는변경되었으나, 아직commit XDirty Buffer: 어떤 사용자가commit을 하였으나, 아직데이터 파일에 저장 XFree Buffer: 사용되지 않거나 더티 버퍼의 데이터를 데이터 파일에 저장한 후 다시 사용 가능한 블록
DBWR이 동작하는 경우
- Checkpoint 신호 발생한 경우
-> DBWR에게 저장 가능한 버퍼를 저장하도록 신호를 줌
-> 즉시더티 버퍼의 내용을데이터 파일에 저장 - Direct Path Read/Write 발생한 경우
->대용량 데이터를 빠르게 처리하고자 할 경우, DB 버퍼 캐시를 경유하지 않고데이터 파일에 바로 저장하도록 유도 - DROP TABLE 또는 TRUNCATE TABLE 실행된 경우
->DELEETE와 다르게 롤백이 되지 않으므로, DB 버퍼 캐시는 바로 기록 후 처리
🎉 Shared pool
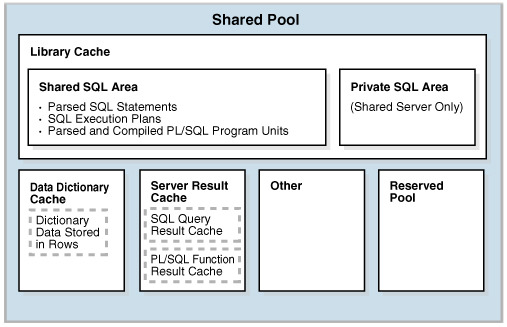
라이브러리 캐시
: 파싱된 SQL문과 실행계획을 매핑하여 저장
-이미 한 번 실행된 SQL문 재사용시, 라이브러리 캐시에 저장된 실행계획 찾아 최적의 경로 찾음
딕셔너리 캐시
: 오라클이 가진 모든 객체(테이블, 뷰, 인덱스 ,...)에 대한 정보
✨SQL문 처리 단계
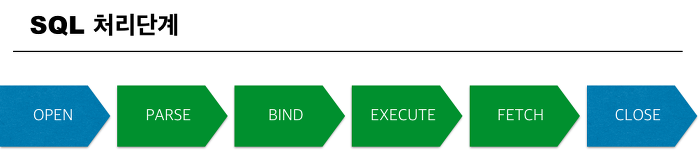
PARSE(구문분석)
: 서버 프로세스는 유저 프로세스를 통해 전송된 SQL문이 실행 가능한지 검사
-문법/의미/권한 검사
-검사 후 최적화 과정
-최적화 후 실행계획 생성
-한번 사용한 SQL문 재사용을 위해 Shared pool의 라이브러리 캐시에 SQL문과 실행계획 함께 저장
BIND(값 치환)
: 조건절에 있는 값을 변수를 통해 담음
select * from emp where mgr=:mgrEXECUTE(실행)
: 최적의 경로와 바인딩된 값이 있는 실제 데이터를 찾아, DB 버퍼 캐시를 찾아보고 없다면 디스크에 있는 데이터 파일을 DB 버퍼 캐시로 복사
FETCH(인출)
: 조건에 맞는 데이터를 걸러내는 작업
🎨데이터 저장 구조
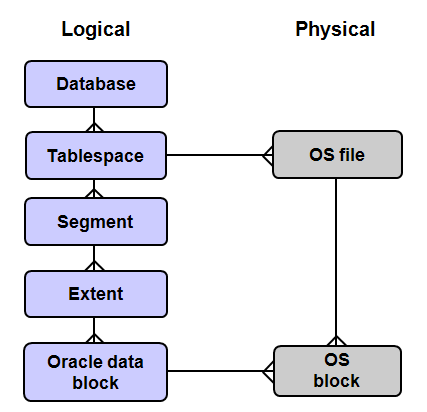
테이블스페이스
: 물리 구조의 데이터 파일을 1개 이상 가지고 있음
- 어떤 파일에 데이터가 저장되어 있는지 관리
- 의미상 논리적으로 연관성 있는 데이터 묶어주는 역할
ex) 책 제목 시리즈 - 테이블 스페이스 , 책 한권 한권 - 데이터 파일
세그먼트
: 테이블과 거의 일치하는 구조
- 테이블과 1:1 구조
익스텐트를1개 이상가질 때 데이터 저장 가능
익스텐트
: 오라클 블록을 논리적으로 인접한 블록으로 관리
- 물리적으로 최대한 인접한 공간을 만들려 함
- 물리적으로
저장할 수 있는 공간을 만드는 단위 논리적으로 연속된 오라클 블럭
블록
: 오라클의 가장 기본이 되는 I/O 단위
- 헤더/프리 스페이스/데이터 영역으로 나뉨
헤더: 어느 요청이 먼저 사용할지 결정 가능
ITL(Interested Transaction List)를 보고 다른 요청이 수정 중임을 확인 가능데이터 영역: 블록의 아래쪽 부터 저장하며, 전부 채우지 않고 빈 공간을 남겨둠
-> 데이터변경을 위해

MSSQL DBA 신입