📔설명
인덱스 스캔과 그 특징을 알아보자.
🍔인덱스의 특징
- 인덱스의 모든 컬럼이
NULL인 경우는, 인덱스를 만들지 않음
select /*+ gather_plan_statistics */ *
from item
where item_nm like '%버거%'
order by item_nm;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
정렬을 하기 위해 인덱스를 이용해서 INDEX FULL SCAN을 하였다.
select /*+ gather_plan_statistics */ *
from item
order by item_nm;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
item_nm 컬럼이 not null이 아니므로, 오라클은 null 데이터가 있다고 판단하며 인덱스 컬럼에 null 데이터가 있으면 인덱스를 이용해 데이터를 갖고 올 수 없기 때문에 인덱스로 정렬X
select /*+ gather_plan_statistics */ *
from item
where item_nm is not null
order by item_nm;위 처럼 not null을 넣어주어야 한다.
🎇ROWID
ROWID 구조
- 데이터 오브젝트 번호 (ex. 테이블)
- 데이터 파일 번호
- 블록 번호
- 로우 번호
ROWID를 알고 있으면, 인덱스를 통하지 않고 바로 데이터에 접근할 수 있으며 ROWID순으로 정렬하면 같은 블록끼리 모여 있어 버퍼 피닝 효과를 얻음
👑인덱스 스캔 방식
Index Unique Scan
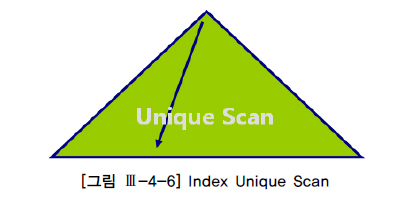
- 루트 블록에서 리프 블록까지 내려가서 최종 데이터가 저장된 테이블 블록을
단 한 건찾음
select /*+ gather_plan_statistics */ *
from item
where item_id=11;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
결합 인덱스의 경우, 인덱스 컬럼의일부 컬럼만 검색시Index Range Scan으로 바뀔 수 있음
--PK컬럼은 item_id+uitem_id
select /*+ gather_plan_statistics */ *
from uitem
where item_id=89;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
PK 컬럼또는Unique Index컬럼이 여러 컬럼으로 구성되어 있는데 이 중일부만 이용시Index Range Scan또는Index Full Scan으로 변형되기도 함
select /*+ gather_plan_statistics */ *
from uitem
where uitem_id=11;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));Index Range Scan
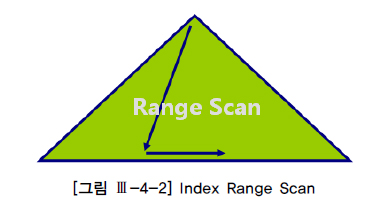
index_rs- 인덱스를 수직 탐색하다가, 리프 블록에 도달하여 시작 지점을 찾고,
필요한 만큼의 범위를순차적으로 탐색
select /*+ gather_plan_statistics */ *
from item
where item_nm like '밀크셰이크%';
--밀크셰이크로 시작하는 지점부터 밀크셰이크 바로 다음 지점까지 탐색
Index Full Scan
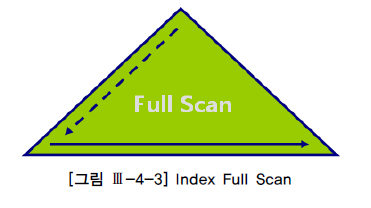
- 해당 인덱스의
첫번째 리프 블록부터마지막 리프 블록까지순차적으로 인덱스 탐색
select /*+ gather_plan_statistics */ *
from item
where item_nm is not null;Index Skip Scan
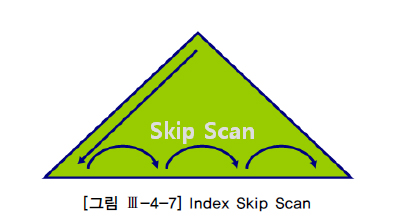
index_ss- 인덱스 스캔에 필요한
선두 컬럼(선행 컬럼)이조건절에 없을 때사용 가능
create index item_x01 on item(item_type_cd,item_nm);
select /*+ gather_plan_statistics */ *
from item
where item_nm like '한우%';
생략된 컬럼값의종류가적을 때는 유용하나, 종류가 많을 땐 느릴 수 있음
Index Fast Full Scan
- 인덱스 스캔 중 유일하게
멀티 블록 I/O방식으로 스캔 - 정렬 순서 보장 X
SQL문에 포함된모든 컬럼이인덱스에포함되어야 함
select /*+ gather_plan_statistics */ count(*)
from ord;
🎉인덱스 스캔 유도
-- T 테이블의 a,b,c 컬럼으로 구성된 인덱스 사용
select /*+ index(t (a,b,c)) */ *
from tmp t
where a=:a
and b=:b
and c=:c힌트를 인덱스명으로 사용하는 것에 비해 다양하게 이용

MSSQL DBA 신입
DB는 모든 개발에 필요하죠! 파이팅입니다 :)