📔설명
예상 실행계획, SQL 트레이스, 응답 시간 분석에 대해 알아보자
🍙예상 실행계획
실행계획 : 사용자가 요청한 SQL을 최적으로 수행하고자 DBMS 내부적으로 수립한 일련의 처리 절차
1. Oracle
Explain Plan
SQL 수행 전, 실행계획을 확인하고자 할 때 explain plan 명령어를 사용
=> plan_table을 생성해야 하며, 아래 스크립트 실행
--오라클 10g부터는 필요없음
@?/rdbms/admin/utlxplan.sql --?는 오라클 홈 디렉터리explain plan for 명령을 수행하고 나면 해당 SQL에 대한 실행계획이 plan_table에 저장
explain plan set statement_id='query1' for
select * from emp where empno=7900;
-- explained.오라클이 제공해주는 utlxpls.sql 또는 utlxplp.sql 스크립트를 이용하면 편리
@?/rdbms/admin/utlxpls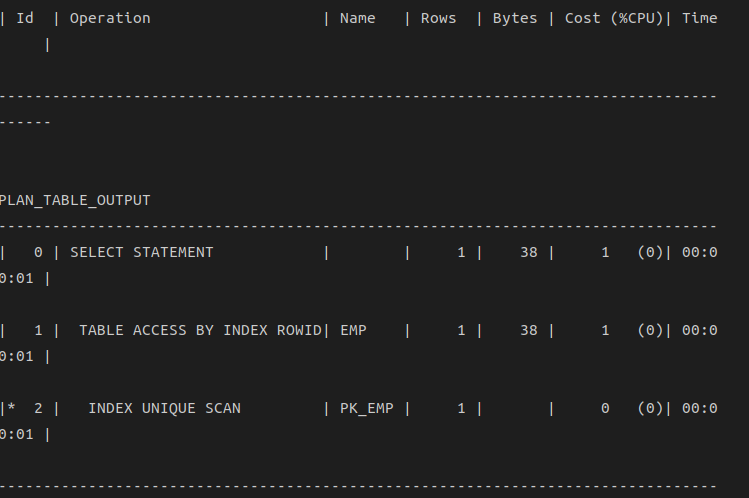
AutoTrace
AutoTrace를 이용하면 실행계획뿐만 아니라 여러 가지 유용한 실행통계 확인 가능
set autotrace on
select * from emp where empno=7900;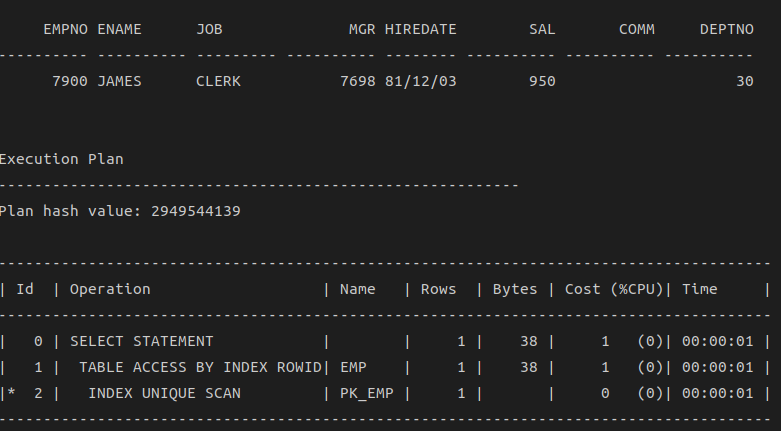
set autotrace on: SQL을실제 수행하고 그결과와 함께실행계획및실행통계출력set autotrace on explain: SQL을실제 수행하고 그결과와 함께실행계획출력set autotrace on statistics: SQL을실제 수행하고 그결과와 함께실행통계출력set autotrace traceonly: SQL을실제 수행하지만 결과는 출력하지 않고실행계획과통계만 출력set autotrace traceonly explain: SQL을 실제 수행하지 않고실행계획만 출력set autotrace traceonly statistics: SQL을실제 수행하지만 그 결과는 출력하지 않고실행통계만 출력
Autotrace를 실행계획 확인 용도로만 사용한다면 plan_table만 생성되면 됨
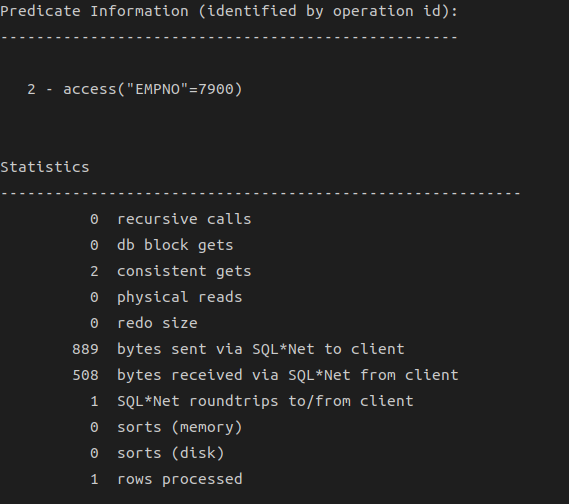
=> 실행통계까지 확인하려면 v_$sesstat, v_$statname, v_$mystat 뷰에 대한 읽기 권한 필요
=> plustrace 롤을 생성하고 필요한 사용자들에게 롤 부여
@?/sqlplus/admin/plustrace.sql
grant plustrace to scott;DBMS_XPLAN 패키지
앞에서 실행한 @?/rdbms/admin/utlxpls 스크립트를 열어 보면 내부적으로 dbms_xplan 패키지를 호출하고 있다.
select plan_table_output
from table(dbms_xplan.display('plan_table', null,'serial'));- 첫 번째 인자 : 실행계획이 저장된
plan table명 - 두 번째 인자 :
statement_id(null일 때는가장 마지막explain plan 명령에 사용했던 쿼리 실행계획 보여줌 - 세 번째 인자 : 다양한
포맷 옵션
병렬 쿼리에 대한 실행계획 수집시 @?/rdbms/admin/utlxplp 스크립트를 수행해 병렬 항목 정보도 볼 수 있음
explain plan set statement_id='SQL1' for
select *
from emp e, dept d
where d.deptno=e.deptno
and e.sal>=1000;
select * from table(dbms_xplan.display('PLAN_TABLE', 'SQL1', 'BASIC'));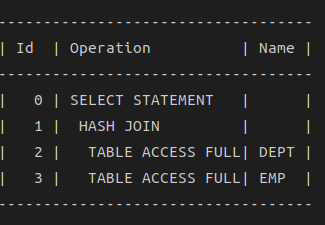
basic 옵션만 사용하면 ID, Operation, Name 칼럼만 보임
select * from table(dbms_xplan.display('PLAN_TABLE', 'SQL1', 'BASIC ROWS BYTES COST'));포맷 인자를 추가해주면 더 출력해준다.
ROWS, BYTES ,COST 이외에 추가 가능한 옵션
PARTITIONPARALLELPREDICATEPROJECTIONALIASREMOTENOTE
select * from table(dbms_xplan.display('PLAN_TABLE', 'SQL1', 'ALL'));모든 항목을 다 출력하려면 ALL 옵션을 사용하면 된다.
2. SQL Server
set showplan_text on 명령문을 먼저 실행한 후 SQL문을 실행하면 예상 실행계획을 보여줌
=> 쿼리를 실제로 수행X
use pubs
go
set showplan_text on
go
select a.*, b.*
from dbo.employee a,dbo.jobs b
where a.job_id=b.job_id
goset showplan_all on 명령문을 실행하면 PhysicalOp(물리 연산자), LogicalOp(논리 연산자), EstimateRows(예상 로우 수) 등을 포함해 좀 더 자세한 예상 실행계획 보여줌
set showplan_all on
go
select a.*, b.*
from dbo.employee a,dbo.jobs b
where a.job_id=b.job_id
go🍚SQL 트레이스
예상 실행계획만으로 문제점을 파악할 수 없을 때 트레이스를 통해 SQL의 실제 수행 과정을 분석
1. Oracle
SQL 트레이스 수집
--자신이 접속해 있는 세션에만 트레이스를 설정
alter session set sql_trace=true;
select * from emp where empno=7900;
select * from dual;
alter session set sql_trace=false;user_dump_dest 파라미터로 지정된 서버 디렉터리 밑에 트레이스 파일(.trc)이 생성
-- 가장 최근에 생성되거나 수정된 파일을 찾아 분석
select r.value || '/' || lower(t.instance_name) || '_ora_' ||
ltrim(to_char(p.spid)) || '.trc' trace_file
from v$process p, v$session s, v$parameter r, v$instance t
where p.addr=s.paddr
and r.name='user_dump_dest'
and s.sid=(select sid from v$mystat where rownum=1);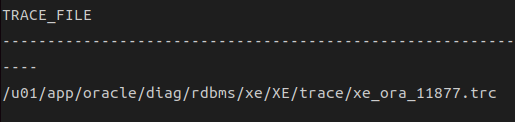
SQL 트레이스 포맷팅
TKProf 유틸리티를 사용하면 트레이스 파일을 보기 쉽게 포맷팅 해줌

$ tkprof 트레이스파일명.trc report.prf sys=no
# sys=no 옵션 : SQL을 파싱하는 과정에서 내부적으로 수행되는 SQL 문장 제외자꾸 오류가 발생했었는데 xe를 XE로 고쳐줘야 tkprof가 작동한다.
$ vi report.prf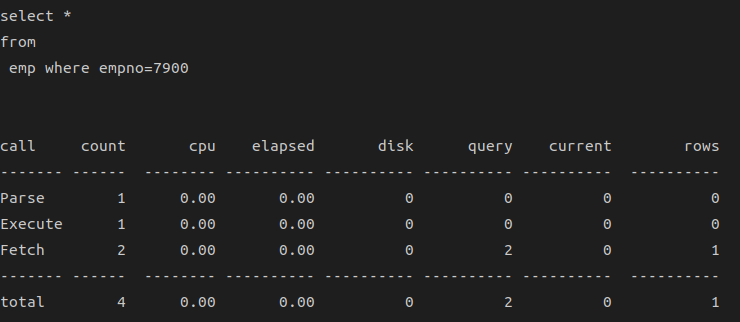
SQL 트레이스 분석
Call 통계(Statistics) 칼럼의 의미
| 항목 | 설명 |
|---|---|
| call | 커서 상태에 따라 Parse, Execute, Fecth 세 개의 Call로 나누어 각각에 대한 통계정보 보여줌 - Parse : 커서를 파싱하고 실행계획을 생성하는 것의 통계 - Execute : 커서의 실행 단계에 대한 통계 - Fetch : 레코드를 실제로 Fetch하는 것의 통계 |
| count | Parse, Execute, Fetch 각 단계가 수행된 횟수 |
| cpu | 현재 커서가 각 단계에서 사용한 cpu time |
| elapsed | 현재 커서가 각 단계를 수행하는 데 소요된 시간 |
| disk | 디스크로부터 읽은 블록 수 |
| query | Consistent 모드에서 읽은 블록 수 |
| current | Current 모드에서 읽은 블록 수 |
| rows | 각 단계에서 읽거나 갱신한 처리 건수 |
AutoTrace 실행통계 항목과 비교
db block gets=currentconsistent gets=queryphysical reads=diskSQL*Net roundtrips to/from client=fetch countrows processed=fetch rows
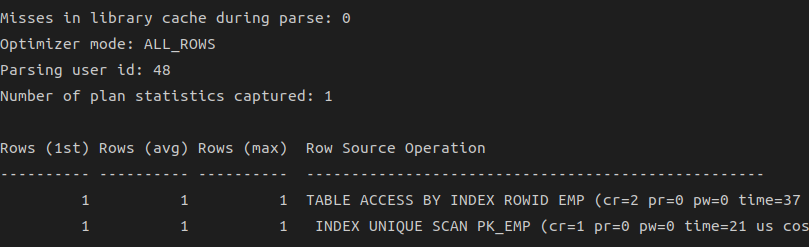
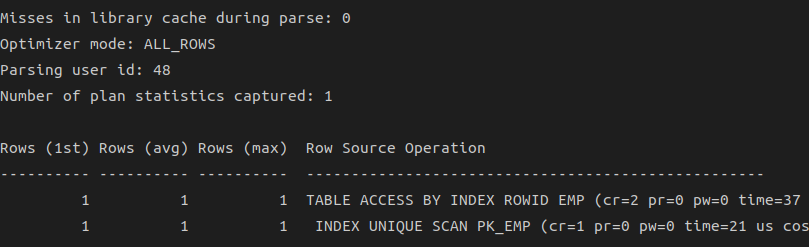
Row Source Operation
Rows: 각 수행 단계에서출력된 로우 수cr:Consistent 모드블록 읽기pr:디스크블록 읽기pw:디스크블록 쓰기time:소요 시간
부모는 자식 노드의 값을 누적한 값을 갖는다
=> emp 테이블 액세스단계에서 cr=2이고, 그 자식 노드인 emp_pk 인덱스 액세스 단계에서는 cr=1이므로 인덱스 읽고, 테이블 액세스 단계에서 순수하게 일어난 cr개수는 1
DBMS_XPLAN 패키지
sql_trace 파라미터를 변경해서 SQL 트레이스를 수집하면 트레이스 파일이 DBMS 서버에 저장된다
=> SGA 메모리에 남기는 방식을 채택하기로 함
사용 방법은 세션 레벨에서 statistics_level 파라미터를 all로 설정하거나, 분석 대상 SQL 문에 gather_plan_statistics 힌트를 사용
=> 수집된 정보는 dbms_xplan.display_cursor 함수로 확인
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS'));--예제
select /*+ gather_plan_statistics */ *
from emp e, dept d
where d.deptno=e.deptno
and e.sal>=1000;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS'));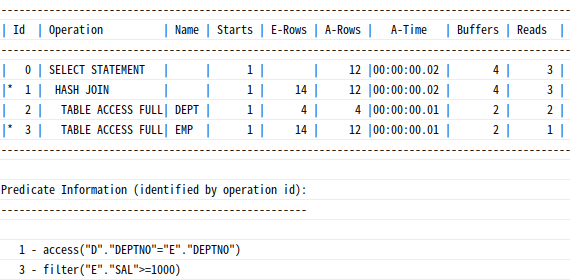
Starts: 각 오퍼레이션 단계를몇 번실행했는지E-Rows: SQL 트레이스에 없는 정보, SQL 수행 전옵티마이저가 실행단계별로예상했던 로우 수
| DBMS_XPLAN | SQL 트레이스 | 설명 |
|---|---|---|
| A-Rows | rows | 각 단계에서 읽거나 갱신한 건수 |
| A-Time | time | 각 단계별 소요시간 |
| Buffers | cr | 캐시에서 읽은 버퍼 블록 수 |
| Reads | pr | 디스크로부터 읽은 블록 수 |
각 항목은 기본적으로 누적값, format 옵션에 last 추가시 마지막 수행했을 때의 일량을 보여줌
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));2. SQL Server
SQL 트레이스를 설정하려면 statistics profile, statistics io, statistics time을 on으로 설정하면 됨
=> showplan_text 또는 showplan_all 옵션을 on 으로 설정한 상태라면, 이 옵션을 먼저 off로 해야함
use Northwind
go
set statistics profile on
set statistics io on
set statistics time on
goset statistics profile on: 각 쿼리가 일반 결과 집합을 반환하고 그 뒤에는쿼리 실행 프로필을 보여주는 추가 결과 집합 반환. 출력에는 다양한 연산자에서처리한 행 수및연산자 실행 횟수정보 포함set statistics io on:Transact-SQL문이 실행되고 나서 해당 문에서 만들어진디스크 동작 양에 대한 정보 표시set statistics time on: 각 Transact-SQL문을구문 분석,컴파일및실행하는 데 사용한시간을 밀리초 단위로 표시
| 항목 | 설명 |
|---|---|
| 테이블 검색 수 | 실행된 검색(=읽기, 액세스) 수 (해당 테이블에 속한 인덱스를 액세스한 횟수도 포함) |
| 논리적 읽기 수 | '데이터 캐시'(=버퍼 캐시)로부터 읽어 들인 페이지 수 |
| 물리적 읽기 수 | 디스크로부터 읽어 들인 페이지 수 |
| 미리 읽기 수 | 쿼리에 의해 캐시에 넣어진 페이지 수 (쿼리를 수행하는 데 필요한 데이터 및 인덱스 페이지를 예상하고, 이들 페이지가 쿼리에서 실제로 사용되기 전에 해당 페이지를 버퍼 캐시로 가져온다.) |
| Rows | 해당 연산자에서 처리된 실제 로우 수(출력 로우 수) |
| Executes | 해당 연산자가 실행된 횟수 |
🍛응답 시간 분석
1. 대기 이벤트
수많은 프로세스 간에는 상호작용이 필요하며, 다른 프로세스가 일을 마칠 때 까지 기다려야만 하는 상황 발생
=> 해당 프로세스는 자신이 일을 계속 진행할 수 있는 조건이 충족될 때까지 수면(sleep) 상태로 대기
=> 그 기간에 정해진 간격으로 각 대기 유형별 상태와 시간 정보가 공유 메모리 영역에 저장됨
=> 대기 이벤트(Wait Event)/대기 유형(Wait Type) : 대기 정보
라이브러리 캐시 부하
라이브러리 캐시에서 SQL 커서를 찾고 최적화하는 과정에서 경합 발생시 나타나는 대기 이벤트
latch:shared poollatch:library cache
라이브러리 캐시와 관련해 자주 발생하는 대기 이벤트
=> 수행 중인 SQL이 참조하는 오브젝트에 다른 사용자가 DDL 문장을 수행시 나타남
library cache locklibrary cache pin
데이터베이스 Call과 네트워크 부하
애플리케이션과 네트워크 구간에서 소모된 시간
SQL*Net message from client- 데이터베이스 경합과는 관련X, 클라이언트로부터 다음 명령이 올 때 까지Idle상태로 기다릴 때 발생하기 때문SQL*Net message to clientSQL*Net more data to clientSQL*Net more data from client
SQL*Net message to client와 SQL*Net more data to client : 클라이언트에게 메시지를 보냈는데 메시지를 잘 받았다는 신호가 정해진 시간보다 늦게 도착하는 경우에 나타나며, 클라이언트가 너무 바쁜 경우일 수 있음
SQL*Net more data from client : 클라이언트로부터 더 받을 데이터가 있는데 지연이 발생하는 경우
디스크 I/O 부하
디스크 I/O가 발생할 때마다 나타나는 대기 이벤트
db file sequential read-Single Block I/O수행 시 나타남db file scattered read-Multiblock I/O수행 시 나타남direct path readdirect path writedirect path write tempdirect path read tempdb file parallel read
버퍼 캐시 경합
버퍼 캐시에서 블록을 읽는 과정에 경합이 발생
latch:cache buffers chainlatch:cache buffers lru chainbuffer busy waitsfree buffers waits
Lock 관련 대기 이벤트
enq로 시작되는 대기 이벤트는 Lock과 관련된 것
enq: TM - contentionenq: TX - row lock contentionenq: TX - index contentionenq: TX - allocate ITL entryenq: TX - contentionlatch free-특정 자원에 대한래치를 여러 차례 요청했으나 해당 자원이 계속 사용 중이어서잠시 대기 상태로 빠질 때 발생
Lock : 사용자 데이터 보호
래치(latch) : SGA에 공유된 갖가지 자료구조 보호
=> 큐(Queueing) 메커니즘 사용 X, 특정 자원에 액세스 하려는 프로세스는 래치 획득에 성공할 때 까지 시도 반복할 뿐, 우선권 부여X
그 외에 자주 발생하는 대기 이벤트
log file synccheckpoint completedlog file switch completionlog buffer space
2. 응답 시간 분석
응답 시간 분석(Response Time Analysis) 성능관리 방법론 : 대기 이벤트 기반
=> 세션 또는 시스템 전체에 발생하는 병목 현상과 그 원인을 찾아 문제를 해결
=> 데이터베이스 서버 응답 시간을 서비스 시간과 대기 시간의 합으로 정의
Response Time = Service Time + Wait Time
= CPU Time + Queue Time서비스 시간(Service Time): 프로세스가정상적으로 동작하며, 일을수행한 시간 (=CPU Time)대기 시간(Wait Time): 프로세스가 잠시 수행을 멈추고대기한 시간(=Queue Time)
3. AWR
AWR(Automatic Workload Repository) : 응답 시간 분석 방법론을 지원하는 Oracle 표준 도구
=> 아래의 동적 성능 뷰(Dynamic Performance View)를 주기적으로 특정 저장소에 저장하고 분석함으로써 DBMS 전반의 건강 상태를 체크하고, 병목원인과 튜닝대상을 식별해 내는 방법 제공
v$segstatv$undostatv$latchv$latch_childrenv$sgastatv$pgastatv$sysstatv$system_eventv$waitstatv$sqlv$sql_planv$sqlstatsv$active_session_historyv$osstat
Statspack : SQL을 이용한 딕셔너리 조회 방식
AWR : DMA(Direct Memory Access) 방식으로, SGA 공유 메모리를 직접 액세스해 좀 더 빠름
AWR 기본 사용법
SYS계정 믿에 'dba_hist_로 시작하는 뷰 이용
-- 표준화한 보고서 출력
@?/rdbms/admin/awrrpt측정 구간(interval), 즉 시작 스냅샷 ID와 종료 스냅샷 ID가 중요
=> peak 시간대 또는 장애가 발생한 시점을 전후해 가능한 짧은 구간을 선택
=> 그렇지 않으면 보고서상으로는 전혀 문제가 없다는 진단이 내려질 수 있음
AWR 리포트 분석
요약보고서 (Report Summary)는 부하 프로필(Load Profile), 인스턴스 효율성(Instance Efficiency), 공유 풀(Shared Pool) 통계, 최상위 5개 대기 이벤트(Top 5 Timed Events) 등으로 구성
부하 프로필
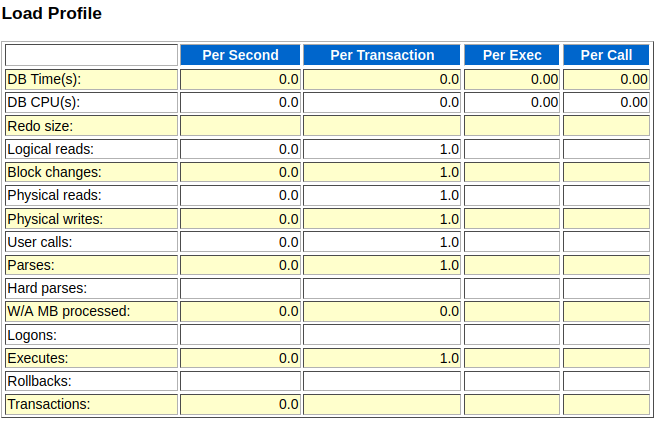
Per Second: 각 측정 지표값들을측정 시간(Interval)로 나눈 것, 즉초당 부하 발생량의미Per Transaction: 각 측정 지표값들을트랜잭션 개수로 나눈 것
=>한 트랜잭션 내에서 평균적으로 얼만큼의부하가 발생하는지 보여줌
=>트랜잭션 개수:commit또는rollback수행 횟수 더한 값
인스턴스 효율성
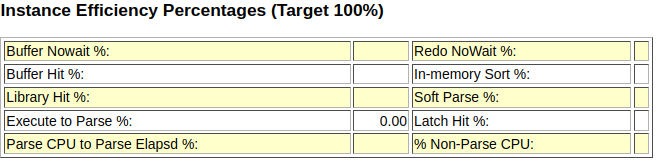
Execute to Parse % 항목 제외 모두 100%에 가까운 수치를 보여야 정상
공유 풀 통계

AWR 리포트 구간 시작 시점의 공유 풀 메모리 상황과 종료 시점에서의 메모리 상황 보여줌
최상위 5개 대기 이벤트
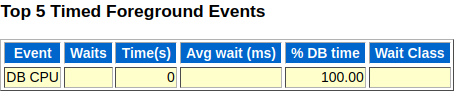
AWR 리포트 구간 동안 누적 대기 시간이 가장 컸던 대기 이벤트 5개를 보여줌 (Idle 이벤트 제외)
CPU time: 대기 이벤트가 아니며, 원할하게 일을 수행했던서비스 time이지만, 가장 오래 대기를 발생시킨 이벤트와의점유율 비교를 위해Top 5에 포함
=>Top 1에 위치한다면 DB 건강상태 양호래치나Lock 관련 대기 이벤트가 상위 순위로 매겨진다면 문제가 발생했음을 나타내는 위험 신호일 가능성이 높으나,래치의 경우CPU 사용률까지 같이 분석해야 함
=>래치 경합은CPU 사용률을 높이는 주원인으로,CPU 사용률이 높지 않았다면 그냥 상대적으로 많이 발생한 것에 불과트랜잭션 처리 위주의 시스템이라면log file sync대기 이벤트가 포함되어도 이상 징후로 보기 어려움
=>이벤트가 많이 발생한 것만으로 불필요한 커밋을 자주 날렸다고 판단하면 안됨I/O 관련 대기 이벤트가 상위로 올라오는 것은 상황에 따라 다르게 해석
=>db file sequential read,db file scattered read대기 이벤트가 상위에 매겨지는 게 정상 (데이터베이스는I/O 집약적인 시스템)
=>CPU time보다높은 점유율을 차지하고,CPU 사용률도매우 높은상황 지속시 I/O 튜닝 필요
